因为以上的问题,目前/或者之前用过的一些hook框架或多或少都有些较大的bug(hookzz之前的某个版本应该是可以的),而对其进行修复成本较高,还不如自己写一个。
首先统一一些概念。把覆盖被hook函数的指令称为跳板0,因为这部分指令越短越好,所以其大多数情况下只是一个跳板,跳到真正的用于hook指令处,这部分指令称为shellcode(shellcode不是必须的,比如跳板0直接跳到hook函数去执行,那么就不需要shellcode)。
这里假设都有一些arm指令的基础了,或者对hook已经有些理解了。后来我想了下我这篇更偏向于怎么写一个稳定可用hook框架,更偏向设计、编程,所以适合已经有些基础的,不是从0讲述hook到实现,虽然接下来的部分也会有很细节的部分,但是是针对一些特定的点。建议可以先看下其他人,比如ele7enxxh、GToad写的一些文章。
inline hook这种东西,我是感觉当你掌握汇编、自己有需求的情况下,不经过学习也是可以从0写出一个hook框架的,确实是原理很简单的。
最容易想到的一种实现方式,使用跳板0覆盖一个函数的指令,当执行到这个函数的时候其实就是执行跳板0,跳板0在不修改寄存器的情况跳到执行hook函数。如果在hook函数内不需要执行原函数是最简单的,到这hook就是一个完整的hook。
如果需要执行原函数,那么在跳板0覆盖指令之前先备份指令,执行原函数之前把备份的指令再覆盖回去,执行之后再覆盖回跳板0。确实是最简单的方法、也确实可以,但是也有一个很大的问题,就是多线程的问题,在把备份的指令覆盖回去之后,其他线程执行到这里不就hook不到了,甚至crash。
因为无法加锁(真正有效的锁),而暂停所有线程的太重了,所以基本上只有自己确定某个函数不存在多线程问题或者无需调用原函数才可用。写个demo,熟悉下hook还行,真的实际使用是不行的。
也是因为这个问题,基本上目前的inline hook都会避免再次覆盖指令。不能覆盖回去,那么就直接执行备份的指令,执行后再跳到跳板0之后再继续执行。
也确实是可行的,大部分指令是可以这么做的,但是也有例外。比如备份的指令中有b/bl指令跳到一个偏移地址,跳转到的地址等于当前地址+偏移。而备份后的指令取得当前地址肯定是不等于原来的当前地址的,所以就跳到错误的地址去执行了。
好在我们可以进行修复,计算出原来要跳到的绝对地址,把这条b指令替换成ldr pc指令。其他指令的一些修复也是类似的道理。
Android_Inline_Hook就是这样的实现,只能接收读写寄存器和堆栈,原函数还运行。那么其实这种方式主要作用就是读写参数寄存器、栈,不能读写函数返回值,如果是不受参数控制流程的函数就无能为力了(当然是可以逆向分析,在已经得到返回值的指令处hook,但是应用场景太小了)。
那么实现的核心就是,跳板0->dumpshellcode。dumpshellcode把寄存器以数组的形式存放(栈就是天然的数组),把这个数组传递给dump函数,dump函数接收处理寄存器(未生效)。dump函数返回shellcode,恢复数组数据到寄存器,完成恢复或者修改。执行backupshellcode(备份的原函数的开头部分,修复pc,跳回原函数之后的部分)完成原函数的执行流程。
最常用、最符合使用习惯的的方式。 实现的核心,跳板0->funshellcode。funshellcode可以在上面的dumpshellcode基础上实现也可以全新实现。
在dumpshellcode基础上可以取巧一些,前面的保存dump寄存器保留,把后面的执行backupshellcode换成执行hook函数。
全新实现就是不保存寄存器,那么就可以把hook函数放在跳板shellcode中,直接跳到hook函数;也可以跳板0->funshellcode,funshellcode中再跳转到hook函数。
之后就进入hook函数,如果不调用原函数,直接返回一个返回值或者void函数什么都不做即可(如果是参数也做返回值的情况就修改参数)。如果调用原函数,就通过一个结构体/map等查询被hook函数地址对应的backupshellcode,把backupshellcode转成函数指针,传参调用,即可完成原函数的调用、或者返回值。
在dump的基础上,执行backupshellcode(备份的原函数的开头部分,修复pc,跳回原函数之后的部分)完成原函数的执行流程之后返回到dumpshellcode,调用另一个dump函数,读写返回值(r0/x0,r1/x1寄存器)。不同于dump的地方在于如果要返回到dumpshellcode,那么在调用backupshellcode之前应该备份原来的lr寄存器。考虑到多线程的问题,肯定是不能用一个固定的变量/地址去存储lr寄存器的,可能被覆盖,同一个线程哪怕是递归调用函数也是有顺序的,所以每个线程的被hook函数使用一个顺序的容器保存lr,后进先出。
在dump的基础上,不执行backupshellcode(备份的原函数的开头部分,修复pc,跳回原函数之后的部分),直接修改r0/x0、r1/x1寄存器,返回。和dump函数很多地方是一致的,应用于只需要返回值,并不需要原函数执行的情况。
以上四种场景应该是足够满足hook的需要了。
因为无法直接操作pc,那么实现跳转(通用情况)需要占用一个寄存器。要么使用一个不会被使用的寄存器(哪有绝对不会被使用的寄存器),要么先保存这个寄存器,通过栈保存(之前就是忽略了这个问题在固定地址保存寄存器,那么多线程情况下就可能被覆盖),跳过去之后先恢复这个寄存器。例如:
stp X1, X0, [SP, #-0x10];//保存寄存器
...
ldr x0, [sp, #-0x8];//恢复x0寄存器
对应shellcode我们很容易实现,但是如果是c/c++函数(我们的hook函数)就麻烦了,直接在函数开头插代码肯定是不行的。在源码中函数第一行内嵌汇编恢复寄存器?很可惜,这种只在无参、无返回值(空实现)、只有内嵌汇编的情况会成功,其他情况下源码中的第一行并不是汇编中的第一行。。。
所以似乎陷入了无解的状态,在llvm中函数开头插指令?似乎太重了。所以回到原点了,就要考虑真的没有不使用寄存器跳转的可能吗?其实还是有的,b或者bl到偏移
ARM64:
B:0x17向前跳转,0x14向后跳转
BL:0x97向前跳转 0x94向后跳转
偏移地址计算过程:
(目标地址 - 指令地址)/ 4 = 偏移
// 减8,指令流水造成。
// 除4,因为指令定长,存储指令个数差,而不是地址差。
完整指令:
.text:000000000008CC84 8D B3 FF 97 BL je_arena_malloc_hard
.text:0000000000079AB8 je_arena_malloc_hard
计算偏移:
(79AB8-8CC84) / 4 = FFFFFFFFFFFFB38D
FFB38D | 0x97000000 = 97FFB38D
所以理论上,如果被hook的函数和hook函数/跳板/shellcode的距离在正负67108860/64m的范围内,64m=67108864,还有0,比如BL 0=00000094。那么这样就可以省一个寄存器了,针对arm64不能直接操作pc的问题,这应该是一个解决方案。
那么单指令hook除了异常的方式是不是就是指的这种方式呢?只需要覆盖一条指令,关键是怎么确保被hook函数和hook函数地址在正负64m内呢。怎么能申请到这块地址的内存呢。
也许可以查看proc/pid/maps,在要hook的so附近寻找未使用的空间,然后使用mmap申请,不确定是否可行。
暂时可用的一些方式如下(最终未采用):
实际上到内存中还是被和代码段放在一起都是可读可执行,没有写的权限。
.section ".my_sec", "awx"
.global _myopen_start
//.text
_myopen_start:
ldr x0, [sp, #-0x8];
b my_open;
.end
//用于手动生成蹦床代码,因为hook代码和这个蹦床一起编译的,所以基本上不会超出加减64m,那么就可以使用b跳转
//到偏移,就不用占用一个寄存器了。需要每增加一个hook函数,就加一个蹦床,相应的生成shellcode中跳转到hook
//函数的地方都要改成这个蹦床的地址。难就难在这个不好通过内嵌汇编实现,因为b跟的是个偏移值,在汇编中可以使用
//函数名称,编译器替换,但是内嵌汇编中不行。而自己计算
shellcode如下,
//用于演示,因为不是最终方案,不写完整代码了。
//修改trampoline指向蹦床即可
.data
replace_start:
ldr x0, trampoline; //如果每一个函数都在源码中新建一个shellcode的话,而不是动态复制生成,那么这个shellcode和蹦床可以合为一个。
br x0; //不能改变lr寄存器
trampoline: //蹦床的地址
.double 0xffffffffffffffff
replace_end:
awx指定读写执行,在elf中(ida查看)确实是读写执行。如果这个section中仅包含变量,那么在内存中放在可读写的段;如果存在代码或者代码和变量均存在,都是和代码段一样仅可读执行。那么在单独的section中存放蹦床代码意义也不大了,还是需要调用mprotect修改内存权限。不过考虑到如果放在仅可读写的段中,那么万一映射后的rw-p和r-xp超过了64m,不就白瞎了,所以还是以代码或者至少这个section中存在一个函数,保证和被hook的函数都在r-xp。
77c5545000-77c557c000 r-xp 00000000 103:37 533353 /data/app/com.zhuotong.myinhk-TRvqt0ReHRjQeeAnpXDnFQ==/lib/arm64/libInlineHook.so
77c558b000-77c558e000 r--p 00036000 103:37 533353 /data/app/com.zhuotong.myinhk-TRvqt0ReHRjQeeAnpXDnFQ==/lib/arm64/libInlineHook.so
77c558e000-77c558f000 rw-p 00039000 103:37 533353 /data/app/com.zhuotong.myinhk-TRvqt0ReHRjQeeAnpXDnFQ==/lib/arm64/libInlineHook.so
而如果直接和.text一起,主要是怕对这块内存修改权限引发什么异常,不确定如果代码正在执行,修改权限是否会出问题,所以最好能仅修改蹦床的区间。而且不确定是否有只能修改为读写和读执行的系统,所以可能要先修改成读写,写了之后再修改成读执行?这样会不会也有几率触发问题,但是如果每个蹦床都分配一个页的内存也不现实。。。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fVHXd8zK-1577937079577)(https://i.imgur.com/PKlzeyq.png)]
这样定义一个无参无返回的函数,倒是可以使这个函数就是内嵌汇编,但是不确定如果ollvm混淆等是否会被拆分、加入垃圾代码等。
而且问题在于怎么自动生成一个蹦床函数。宏定义?那这个宏要在函数之外,不太容易自动化实现,包括蹦床的函数名称、b后面的函数名称。和上面的汇编中添加一个蹦床一样的问题,除非自己实现预处理之类的自动插入汇编代码、宏等,似乎不太现实。。。
似乎很难实现自动化,手动写代码太麻烦且和arm的部分接口、行为不一致。但是如果自己简单测试、不在乎这些也是可以的。
unsigned int hkArry[256*2] __attribute__ ((section(".my_sec")));
//下面为伪代码,通过这样也可以实现不修改/保存寄存器、不修改hook函数,动态生成蹦床完成hook。
//优点是不用保存寄存器,缺点是因为正负64m的限制,hook函数应该和hook库是一起编译成动态库/可执行文件的。不能单独使用hook库。
//256个蹦床,实际使用可能要考虑这个hkArry内存对齐的问题(如果编译器未做内存对齐)。
//unsigned int hkArry[256 * 2] __attribute__ ((section(".my_sec")));
//void test_trampoline(){
//仅用于演示,应该先设置内存为可读写/执行,
// hkArry[0] = 0xf85f83e0;//或者memcpy, ldr x0, [sp, #-0x8];
//例如这样计算偏移,组合b指令。
// unsigned long offset = (unsigned long) my_open - ((unsigned long) hkArry + 1 * 4);
// hkArry[1] = 0x14000000;//计算偏移,生成指令,b 0;
//}
256个蹦床。动态生成蹦床代码,第一条指令固定,第二条指令计算生成。需要hkArry修改为读写执行。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H3VXRUg4-1577937079577)(https://i.imgur.com/1dNxFJm.png)]](https://img-blog.csdnimg.cn/20200102121157812.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0Rhb0RpdkRpRmFuZw==,size_16,color_FFFFFF,t_70)
so的r-xp中应该是有未使用的多余的内存的,为了对齐、页面等,所以怎么确定多余的空间大小和位置,然后蹦床代码存放其中。
因为种种限制,所以最后采用的还是保存一个寄存器,而使用哪个寄存器呢,我是选的lr寄存器。为什么不用x16、x17等不用保存的寄存器?这里就涉及到一个标准和规范的问题。
理论上编译器编译的c/c++函数是遵守这个规范的,要么不使用x16、x17寄存器,要么只是临时中转,不会在调用其他函数之后再从x16、x17寄存器取值(因为其他函数可能改变x16、x17),但是内嵌汇编(虽然指定不使用x16、x17寄存器,但还是被编译器使用了)或者人工写的汇编,虽然不常见,但确实存在。而最常见的是plt函数内都是使用x16、x17做中转。所以使用一个不一定会被保存的寄存器不如使用一个会被保存的寄存器。而因为lr寄存器的特殊性,一般使用的话都会先压栈保存,结束恢复(32位不一定恢复,64位是会恢复lr寄存器的,因为不能直接操作pc,多数都是恢复lr,再ret)
所以其实主要还是兼容性考虑,尽量采用一些绕弯的方式不改变任何寄存器,实在没办法的情况下或者标准c/c++函数、非函数任意位置hook的情况下才使用x16、x17寄存器。
难点在于: 1、不知道参数个数、参数类型。 2、需要确定各种类型参数占几个寄存器、可变参数等
其实在源码中定义hook函数的时候是有函数原型的,但是运行时拿不到。忽然想到"c++"函数名的规则,里面包含参数、返回值类型,似乎可行,但是很多情况并不希望导出函数,而且也并不一定都是c++实现的。
那么如果定义一个接口,传入函数原型也不是不行,基本类型就用相应的字符或者枚举标识,其他所有的都是void*指针。可还是怕碰见可变参数函数,不确定参数个数,参数类型,只有接收/实现函数才知道。所以似乎不太可行。
而libffi似乎不太适合这个情况,也是需要明确指令参数和返回类型,还要传输参数。
目前的实现没有经过自己解析参数,只是中转,通过定义一致的函数原型,让编译器帮助我们解析参数。
因为arm64限制条件最多,那么应该先实现arm64,这样才能更好的保证api的通用/一致性,因为arm64不能操作pc不得不这么做,arm32同样也可以这么做,但是如果先实现arm32,可能就先入为主的设计一些arm32可用的api。这算是一种架构思维吧,或者多思考一下就明白了。
STP X1, X0, [SP, #-0x10];//因为要使用一个寄存器,所以先保存,当然不一定是x0
LDR X0, 8; //把shellcode/hook函数地址存到x0
BR X0; //执行shellcode/hook函数
ADDR(64)
LDR X0, [SP, -0x8];//因为不能操作pc,所以跳回来的时候免不了也要使用一个寄存器
其实很简单,注释基本都说明了,使用了24字节,所以如果能确定要hook的函数是标准的c/c++函数,不会使用x16、x17去保存值的话也可以这样,使用16字节,降低被hook函数太短失败的概率。
LDR X17, 8;
BR x17;
ADDR(64)
.include "../../asm/base.s"
//.extern _dump_start
//.extern _dump_end
//.extern _hk_info
//.set _dump_start, r_dump_start
//.set _dump_end, r__dump_end
//.set _hk_info, r__hk_info
//.global _dump_start
//.global _dump_end
//.global _hk_info
//.hidden _dump_start
//.hidden _dump_end
//.hidden _hk_info
//可用于标准的c/c++函数、非标准函数、函数的一部分(用于读写寄存器),前提都是字节长度足够
//非标准函数即非c/c++编译的函数,那么手写汇编可能存在并不遵守约定的情况,比如我们使用了sp寄存器,并在未使用的栈上保存寄存器
//但是可能不是满递减而是反过来满递增,或者不遵守栈平衡,往栈上写数据,但是并不改变sp寄存器。当然应该是很少见的。
.data
_dump_start: //用于读写寄存器/栈,需要自己解析参数,不能读写返回值,不能阻止原函数(被hook函数)的执行
//从行为上来我觉得更偏向dump,所以起名为dump。
sub sp, sp, #0x20; //跳板在栈上存储了x0、x1,但是未改变sp的值
mrs x0, NZCV
str x0, [sp, #0x10]; //覆盖跳板存储的x1,存储状态寄存器
str x30, [sp]; //存储x30
add x30, sp, #0x20
str x30, [sp, #0x8]; //存储真实的sp
ldr x0, [sp, #0x18]; //取出跳板存储的x0
save_x0_x29://保存寄存器x0-x29
sub sp, sp, #0xf0; //分配栈空间
stp X0, X1, [SP]; //存储x0-x29
stp X2, X3, [SP,#0x10]
stp X4, X5, [SP,#0x20]
stp X6, X7, [SP,#0x30]
stp X8, X9, [SP,#0x40]
stp X10, X11, [SP,#0x50]
stp X12, X13, [SP,#0x60]
stp X14, X15, [SP,#0x70]
stp X16, X17, [SP,#0x80]
stp X18, X19, [SP,#0x90]
stp X20, X21, [SP,#0xa0]
stp X22, X23, [SP,#0xb0]
stp X24, X25, [SP,#0xc0]
stp X26, X27, [SP,#0xd0]
stp X28, X29, [SP,#0xe0]
call_onPreCallBack://调用onPreCallBack函数,第一个参数是sp,第二个参数是STR_HK_INFO结构体指针
mov x0, sp; //x0作为第一个参数,那么操作x0=sp,即操作栈读写保存的寄存器
ldr x1, _hk_info;
ldr x3, [x1]; //onPreCallBack
bl get_lr_pc; //lr为下条指令
add lr, lr, #8; //lr为blr x3的地址
str lr, [sp, #0x108]; //lr当作pc,覆盖栈上的x0
blr x3
restore_regs://恢复寄存器
ldr x0, [sp, #0x100]; //取出状态寄存器
msr NZCV, x0
ldp X0, X1, [SP]; //恢复x0-x29寄存器
ldp X2, X3, [SP,#0x10]
ldp X4, X5, [SP,#0x20]
ldp X6, X7, [SP,#0x30]
ldp X8, X9, [SP,#0x40]
ldp X10, X11, [SP,#0x50]
ldp X12, X13, [SP,#0x60]
ldp X14, X15, [SP,#0x70]
ldp X16, X17, [SP,#0x80]
ldp X18, X19, [SP,#0x90]
ldp X20, X21, [SP,#0xa0]
ldp X22, X23, [SP,#0xb0]
ldp X24, X25, [SP,#0xc0]
ldp X26, X27, [SP,#0xd0]
ldp X28, X29, [SP,#0xe0]
add sp, sp, #0xf0
ldr x30, [sp]; //恢复x30
add sp, sp, #0x20; //恢复为真实sp
call_oriFun:
stp X1, X0, [SP, #-0x10]; //因为跳转还要占用一个寄存器,所以保存
ldr x0, _hk_info;
ldr x0, [x0, #8]; //pOriFuncAddr
br x0
get_lr_pc:
ret; //仅用于获取LR/PC
_hk_info: //结构体STR_HK_INFO
.double 0xffffffffffffffff
_dump_end:
.end
基本上注释已经说明了。_hk_inf为如下结构体的指针,onPreCallBack函数原型如下。
//hook信息
typedef struct STR_HK_INFO{
void (*onPreCallBack)(struct my_pt_regs *, struct STR_HK_INFO *pInfo); //回调函数,在执行原函数之前获取参数/寄存器的函数
void * pOriFuncAddr; //存放备份/修复后原函数的地址
void (*pre_callback)(struct my_pt_regs *, struct STR_HK_INFO *pInfo); //pre_callback,内部做保存lr的操作,之后回调onPreCallBack,不能被用户操作
void (*onCallBack)(struct my_pt_regs *, struct STR_HK_INFO *pInfo); //回调函数,执行原函数之后获取返回值/寄存器的函数
void (*aft_callback)(struct my_pt_regs *, struct STR_HK_INFO *pInfo); //aft_callback,内部做恢复lr的操作,之后回调onCallBack,不能被用户操作
void *pHkFunAddr; //hook函数,即自定义按照被hook的函数原型构造,处理参数/返回值的函数
//以上为在shellcode中通过偏移直接或间接用到的,所以如果有变动,相应的shellcode也要跟着变动
void **ppHkFunAddr; //上面pHkFunAddr函数在shellcode中的地址,已废弃;
void **hk_infoAddr; //shellcode中HK_INFO的地址
void *pBeHookAddr; //被hook的地址/函数
void *pStubShellCodeAddr; //跳过去的shellcode stub的地址
size_t shellCodeLength; //上面pStubShellCodeAddr的字节数
void ** ppOriFuncAddr; //shellcode 中存放备份/修复后原函数的地址,已废弃,待去除;改成上面pHkFunAddr函数的指针,应用于解除hook
void *pNewEntryForOriFuncAddr; //和pOriFuncAddr一致
BYTE szbyBackupOpcodes[OPCODEMAXLEN]; //原来的opcodes
int backUpLength; //备份代码的长度,arm64模式下为24
int backUpFixLengthList[BACKUP_CODE_NUM_MAX]; //保存
const char* methodName;
} HK_INFO;
#if defined(__aarch64__)
struct my_pt_regs {
__u64 uregs[31];
__u64 sp;
__u64 pstate; //有时间应该修复,pc在前,但是涉及到栈和生成shellcode都要改,先这么用吧,和系统结构体有这点不同
__u64 pc;
};
#define ARM_lr uregs[30]
#define ARM_sp sp
//#define SP (__u64*)sp
//#define SP_32(i) *(__u32*)((__u64)(regs->sp) + i*4)
//#define SP_32(i) *((__u32*)regs->sp+i)
//#define SP_32(i) *((__u64*)regs->sp+i)
#define SP(i) *((__u64*)regs->sp+i)
#elif defined(__arm__)
struct my_pt_regs {
long uregs[18];
};
#ifndef __ASSEMBLY__
#define ARM_cpsr uregs[16]
#define ARM_pc uregs[15]
#define ARM_lr uregs[14]
#define ARM_sp uregs[13]
#define ARM_ip uregs[12]
#define ARM_fp uregs[11]
#define ARM_r10 uregs[10]
#define ARM_r9 uregs[9]
#define ARM_r8 uregs[8]
#define ARM_r7 uregs[7]
#define ARM_r6 uregs[6]
#define ARM_r5 uregs[5]
#define ARM_r4 uregs[4]
#define ARM_r3 uregs[3]
#define ARM_r2 uregs[2]
#define ARM_r1 uregs[1]
#define ARM_r0 uregs[0]
#define ARM_ORIG_r0 uregs[17]
#define ARM_VFPREGS_SIZE (32 * 8 + 4)
#endif
#define SP(i) *((__u32*)regs->ARM_sp+i)
#endif
my_pt_regs对应在栈上存放的寄存器。这里面其他寄存器都容易保存,pc寄存器因为不能直接操作,所以要取巧一些。我是利用bl跳转之前会把下一条指令的地址存放到lr寄存器,那么再跳回读取lr寄存器即可。
bl get_lr_pc; //lr为下条指令
add lr, lr, #8; //lr为blr x3的地址
str lr, [sp, #0x108]; //lr当作pc,覆盖栈上的x0
blr x3
...
get_lr_pc:
ret; //仅用于获取LR/PC
当然这里保存pc寄存器其实也不是必须的。
/**
* 用户自定义的stub函数,嵌入在hook点中,可直接操作寄存器等
* @param regs 寄存器结构,保存寄存器当前hook点的寄存器信息
* @param pInfo 保存了被hook函数、hook函数等的结构体
*/
void onPreCallBack(my_pt_regs *regs, HK_INFO *pInfo) //参数regs就是指向栈上的一个数据结构,由第二部分的mov r0, sp所传递。
{
const char* name = "null";
if (pInfo) {
if (pInfo->methodName) {
name = pInfo->methodName;
} else {
char buf[20];
sprintf(buf, "%p", pInfo->pBeHookAddr);
name = buf;
}
}
// LE("tid=%d onPreCallBack:%s", gettid(), name);
#if defined(__aarch64__)
LE("tid=%d, onPreCallBack:%s, "
"x0=0x%llx, x1=0x%llx, x2=0x%llx, x3=0x%llx, x4=0x%llx, x5=0x%llx, x6=0x%llx, x7=0x%llx, x8=0x%llx, x9=0x%llx, x10=0x%llx,"
" x11=0x%llx, x12=0x%llx, x13=0x%llx, x14=0x%llx, x15=0x%llx, x16=0x%llx, x17=0x%llx, x18=0x%llx, x19=0x%llx, x20=0x%llx, "
"x21=0x%llx, x22=0x%llx, x23=0x%llx, x24=0x%llx, x25=0x%llx, x26=0x%llx, x27=0x%llx, x28=0x%llx, x29/FP=0x%llx, x30/LR=0x%llx, "
"cur_sp=%p, ori_sp=%p, ori_sp/31=0x%llx, NZCV/32=0x%llx, x0/pc/33=0x%llx, cur_pc=%llx, arg8=%x, arg9=%x, arg10=%x, arg11=%x, "
"arg12=%x, arg13=%x;"
, gettid(), name,
regs->uregs[0], regs->uregs[1], regs->uregs[2], regs->uregs[3], regs->uregs[4], regs->uregs[5],
regs->uregs[6], regs->uregs[7], regs->uregs[8], regs->uregs[9], regs->uregs[10], regs->uregs[11],
regs->uregs[12], regs->uregs[13], regs->uregs[14], regs->uregs[15], regs->uregs[16], regs->uregs[17],
regs->uregs[18], regs->uregs[19], regs->uregs[20], regs->uregs[21], regs->uregs[22], regs->uregs[23],
regs->uregs[24], regs->uregs[25], regs->uregs[26], regs->uregs[27], regs->uregs[28], regs->uregs[29], regs->uregs[30],
regs, ((char*)regs + 0x110), regs->uregs[31], regs->uregs[32], regs->uregs[33], regs->pc,
SP(0), SP(1), SP(2), SP(3), SP(4), SP(5)
);
#elif defined(__arm__)
LE("tid=%d, onPreCallBack:%s, "
"r0=0x%lx, r1=0x%lx, r2=0x%lx, r3=0x%lx, r4=0x%lx, r5=0x%lx, r6=0x%lx, r7=0x%lx, r8=0x%lx, r9=0x%lx, r10=0x%lx, r11=0x%lx, r12=0x%lx, "
"cur_sp=%p, ori_sp=%p, ori_sp/13=0x%lx, lr=0x%lx, cur_pc=0x%lx, cpsr=0x%lx, "
"arg4=0x%lx, arg5=0x%lx, arg4=0x%lx, arg5=0x%lx;"
, gettid(), name,
regs->uregs[0], regs->uregs[1], regs->uregs[2], regs->uregs[3], regs->uregs[4], regs->uregs[5],
regs->uregs[6], regs->uregs[7], regs->uregs[8], regs->uregs[9], regs->uregs[10], regs->uregs[11],
regs->uregs[12],
regs, ((char*)regs + 0x44), regs->uregs[13], regs->uregs[14], regs->uregs[15], regs->uregs[16],
regs->uregs[17], regs->uregs[18], SP(0), SP(1)
);
#endif
if (pInfo) {
LE("onPreCallBack: HK_INFO=%p", pInfo);
if (pInfo->pBeHookAddr == open && regs->uregs[0]) {
const char* name = (const char *)(regs->uregs[0]);
LE("onPreCallBack: open: %s , %o, %o", name, regs->uregs[1], (mode_t)regs->uregs[2]);
}
}
}
void test_dump(){
LE("open=%p, callback=%p", open, onPreCallBack);
if (dump((void *)(open), onPreCallBack, NULL, "open") != success) {
LE("hook open error");
}
int fd = open("/system/lib/libc.so", O_RDONLY);
LE("open /system/lib/libc.so, fd=%d", fd);
}
自定义onPreCallBack修改寄存器即可。如果是一个函数,那么能控制的是参数,不能阻止原函数的调用。
//.include "../../asm/base.s"
.global r_dump_start
.global r_dump_end
.global r_hk_info
.hidden r_dump_start
.hidden r_dump_end
.hidden r_hk_info
.data
r_dump_start: //用于读写寄存器/栈,需要自己解析参数,不能读写返回值,不能阻止原函数(被hook函数)的执行
//从行为上来我觉得更偏向dump,所以起名为dump。
sub sp, sp, #0x20; //跳板在栈上存储了x0、x1,但是未改变sp的值
mrs x0, NZCV
str x0, [sp, #0x10]; //覆盖跳板存储的x1,存储状态寄存器
str x30, [sp]; //存储x30
add x30, sp, #0x20
str x30, [sp, #0x8]; //存储真实的sp
ldr x0, [sp, #0x18]; //取出跳板存储的x0
save_x0_x29://保存寄存器x0-x29
sub sp, sp, #0xf0; //分配栈空间
stp X0, X1, [SP]; //存储x0-x29
stp X2, X3, [SP,#0x10]
stp X4, X5, [SP,#0x20]
stp X6, X7, [SP,#0x30]
stp X8, X9, [SP,#0x40]
stp X10, X11, [SP,#0x50]
stp X12, X13, [SP,#0x60]
stp X14, X15, [SP,#0x70]
stp X16, X17, [SP,#0x80]
stp X18, X19, [SP,#0x90]
stp X20, X21, [SP,#0xa0]
stp X22, X23, [SP,#0xb0]
stp X24, X25, [SP,#0xc0]
stp X26, X27, [SP,#0xd0]
stp X28, X29, [SP,#0xe0]
call_onPreCallBack://调用onPreCallBack函数,第一个参数是sp,第二个参数是STR_HK_INFO结构体指针
mov x0, sp; //x0作为第一个参数,那么操作x0=sp,即操作栈读写保存的寄存器
ldr x1, r_hk_info;
ldr x3, [x1, #0x10]; //pre_callback
bl get_lr_pc; //lr为下条指令
add lr, lr, 8; //lr为blr x3的地址
str lr, [sp, #0x108]; //lr当作pc,覆盖栈上的x0
blr x3
to_call_oriFun:
ldr x0, [sp, #0x100]; //取出状态寄存器
msr NZCV, x0
ldp X0, X1, [SP]; //恢复x0-x29寄存器
ldp X2, X3, [SP,#0x10]
ldp X4, X5, [SP,#0x20]
ldp X6, X7, [SP,#0x30]
ldp X8, X9, [SP,#0x40]
ldp X10, X11, [SP,#0x50]
ldp X12, X13, [SP,#0x60]
ldp X14, X15, [SP,#0x70]
ldp X16, X17, [SP,#0x80]
ldp X18, X19, [SP,#0x90]
ldp X20, X21, [SP,#0xa0]
ldp X22, X23, [SP,#0xb0]
ldp X24, X25, [SP,#0xc0]
ldp X26, X27, [SP,#0xd0]
ldp X28, X29, [SP,#0xe0]
add sp, sp, #0xf0
ldr x30, [sp]; //恢复x30
add sp, sp, #0x20; //恢复为真实sp
stp X1, X0, [SP, #-0x10]; //因为跳转还要占用一个寄存器,所以保存
ldr x0, r_hk_info;
ldr x0, [x0, #8]; //pOriFuncAddr
blr x0;
to_aft_callback: //有时间再把这部分代码优化掉,是可以再跳转到开头的,因为这部分代码都是一样的,判断lr可以区分出来的
STP X1, X0, [SP, #-0x10]
sub sp, sp, #0x20; //跳板在栈上存储了x0、x1,但是未改变sp的值
mrs x0, NZCV
str x0, [sp, #0x10]; //覆盖跳板存储的x1,存储状态寄存器
str x30, [sp]; //存储x30
add x30, sp, #0x20
str x30, [sp, #0x8]; //存储真实的sp
ldr x0, [sp, #0x18]; //取出跳板存储的x0
sub sp, sp, #0xf0; //分配栈空间
stp X0, X1, [SP]; //存储x0-x29
stp X2, X3, [SP,#0x10]
stp X4, X5, [SP,#0x20]
stp X6, X7, [SP,#0x30]
stp X8, X9, [SP,#0x40]
stp X10, X11, [SP,#0x50]
stp X12, X13, [SP,#0x60]
stp X14, X15, [SP,#0x70]
stp X16, X17, [SP,#0x80]
stp X18, X19, [SP,#0x90]
stp X20, X21, [SP,#0xa0]
stp X22, X23, [SP,#0xb0]
stp X24, X25, [SP,#0xc0]
stp X26, X27, [SP,#0xd0]
stp X28, X29, [SP,#0xe0]
mov x0, sp; //x0作为第一个参数,那么操作x0=sp,即操作栈读写保存的寄存器
ldr x1, r_hk_info;
ldr x3, [x1, #0x20]; //aft_callback
bl get_lr_pc; //lr为下条指令
add lr, lr, 8; //lr为blr x3的地址
str lr, [sp, #0x108]; //lr当作pc,覆盖栈上的x0
blr x3; //执行aft_callback
to_popreg:
ldr x0, [sp, #0x100]; //取出状态寄存器
msr NZCV, x0
ldp X0, X1, [SP]; //恢复x0-x29寄存器
ldp X2, X3, [SP,#0x10]
ldp X4, X5, [SP,#0x20]
ldp X6, X7, [SP,#0x30]
ldp X8, X9, [SP,#0x40]
ldp X10, X11, [SP,#0x50]
ldp X12, X13, [SP,#0x60]
ldp X14, X15, [SP,#0x70]
ldp X16, X17, [SP,#0x80]
ldp X18, X19, [SP,#0x90]
ldp X20, X21, [SP,#0xa0]
ldp X22, X23, [SP,#0xb0]
ldp X24, X25, [SP,#0xc0]
ldp X26, X27, [SP,#0xd0]
ldp X28, X29, [SP,#0xe0]
add sp, sp, #0xf0
ldr x30, [sp]; //恢复x30
add sp, sp, #0x20; //恢复为真实sp
//巧的是下条指令也是ret或者br lr,共用一条指令。
get_lr_pc:
ret; //仅用于获取LR/PC
r_hk_info: //结构体STR_HK_INFO
.double 0xffffffffffffffff
r_dump_end:
.end
和dump不同,在原函数执行后可以对返回值进行读写,且可以只处理参数或者只处理返回值。
因为要读写返回值,所以执行原函数之前需要修改lr寄存器,而读写返回值之后还要恢复正常的流程,那么lr寄存器是需要保存的。在这个shellcode或者结构体的一个字段存储lr都存在多线程覆盖的问题,所以使用和线程绑定的容器存储。那么何时保存呢?考虑到代码复用和最小的更改,那么可以在调用onPreCallBack函数内保存,但是这个函数是用户创建的,不应该让用户参与保存,而且这个onPreCallBack不一定存在。所以做一次中转,shellcode中先跳到一个一定存在的函数preCallBack,preCallBack内保存lr,并调用onPreCallBack(如果存在)。恢复lr也是同样的思路。
//头文件
#include <map>
#include <pthread.h>
#include <vector>
typedef std::vector<unsigned long> LRS;
//static LRS lrs;
struct STR_LR {
};
typedef std::map<const void*, LRS*> LR_MAP;
//typedef std::map<pid_t, LR_MAP*> TID_MAP;
typedef std::map<pid_t, LR_MAP*> TID_MAP;
static TID_MAP * getTid_map();
static void saveLR(void* key_fun, unsigned long lr);
static unsigned long getLR(void* key_fun);
#endif
#ifdef __cplusplus
extern "C" {
#endif
#include "mhk.h"
//因为会被导出,所以两个静态库中存在两个同名函数,另一个被覆盖了。
//extern void pre_callback(struct my_pt_regs *regs, HK_INFO* info);
static void pre_callback(struct my_pt_regs *regs, HK_INFO* info);
//extern void aft_callback(struct my_pt_regs *regs, HK_INFO* info);
static void aft_callback(struct my_pt_regs *regs, HK_INFO* info);
typedef void (*callback)(struct my_pt_regs *regs, HK_INFO* info);
extern callback d_pre_callback;// = pre_callback;
extern callback d_aft_callback;// = aft_callback;
#ifdef __cplusplus
}
#endif
//头文件结束
static TID_MAP* tid_map;
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
TID_MAP * getTid_map(){
// pthread_mutex_init(&mutex, NULL);
pthread_mutex_lock(&mutex);
if (tid_map == NULL) {
tid_map = new TID_MAP;
}
pthread_mutex_unlock(&mutex);
return tid_map;
}
//因为不清楚tid分配机制,是否存在已死亡线程的tid重新分配给新建线程,所以可以ls -la /proc/8205/task/根据线程时间
//判断是不是一个新线程,若是使用旧tid的新线程可以清空map,不过其实使用的栈结构存数据,理论上不区分也应该没问题的。
void saveLR(void* key_fun, unsigned long lr){
pid_t tid = gettid();
TID_MAP *map = getTid_map();
pthread_mutex_lock(&mutex);
auto it = map->find(tid);
if (it == map->end()) {
auto lr_map = new LR_MAP;
auto ls = new LRS;
ls->push_back(lr);
lr_map->insert(std::make_pair(key_fun, ls));
map->insert(std::make_pair(tid, lr_map));
} else {
auto lr_map = it->second;
auto it_vt = lr_map->find(key_fun);
if (it_vt == lr_map->end()) {
auto ls = new LRS;
ls->push_back(lr);
lr_map->insert(std::make_pair(key_fun, ls));
} else {
std::vector<unsigned long> *vt = it_vt->second;
vt->push_back(lr);
}
}
pthread_mutex_unlock(&mutex);
}
unsigned long getLR(void* key_fun){
unsigned long lr = 0;
pid_t tid = gettid();
TID_MAP *map = getTid_map();
pthread_mutex_lock(&mutex);
auto it = map->find(tid);
if (it == map->end()) {
LE("what's happened ? not found tid=%d", tid);//理论上不应该出现
} else {
auto lr_map = it->second;
auto it_vt = lr_map->find(key_fun);
if (it_vt == lr_map->end()) {
LE("what's happened ? not found LR for=%p in tid=%d", key_fun, tid);//理论上不应该出现
} else {
std::vector<unsigned long> *vt = it_vt->second;
if (!vt || /*vt->size() <= 0*/ vt->empty()) {
LE("what's happened ? null LR for=%p in tid=%d", key_fun, tid);
} else {
unsigned long size = vt->size();
lr = (*vt)[size - 1];
vt->pop_back();
}
}
}
pthread_mutex_unlock(&mutex);
return lr;
}
void pre_callback(struct my_pt_regs *regs, HK_INFO* info){
LE("dump_with_ret pre_callback");
saveLR(info->pBeHookAddr, regs->ARM_lr);
if (info->onPreCallBack)
info->onPreCallBack(regs, info);
}
void aft_callback(struct my_pt_regs *regs, HK_INFO* info){
LE("dump_with_ret aft_callback");
unsigned long lr = getLR(info->pBeHookAddr);
regs->ARM_lr = lr;
if (info->onCallBack)
info->onCallBack(regs, info);
}
callback d_pre_callback = pre_callback;
callback d_aft_callback = aft_callback;
目前是使用"c++"容器实现的,考虑到有些项目可能不能用c++,有时间再用c实现map、vector。
void test_dump_with_ret(){
LE("open=%p, callback=%p", open, onPreCallBack);
if (dump((void *)(open), onPreCallBack, onCallBack, "open") != success) {
LE("hook open error");
}
int fd = open("/system/lib/libc.so", O_RDONLY);
LE("open /system/lib/libc.so, fd=%d", fd);
}
void test_dump_ret(){
LE("open=%p, callback=%p", open, onPreCallBack);
if (dump((void *)(open), NULL, onCallBack, "open") != success) {
LE("hook open error");
}
int fd = open("/system/lib/libc.so", O_RDONLY);
LE("open /system/lib/libc.so, fd=%d", fd);
}
.global j_dump_start
.global j_dump_end
.global j_hk_info
.hidden j_dump_start
.hidden j_dump_end
.hidden j_hk_info
.data
j_dump_start:
sub sp, sp, #0x20; //跳板在栈上存储了x0、x1,但是未改变sp的值
mrs x0, NZCV
str x0, [sp, #0x10]; //覆盖跳板存储的x1,存储状态寄存器
str x30, [sp]; //存储x30
add x30, sp, #0x20
str x30, [sp, #0x8]; //存储真实的sp
ldr x0, [sp, #0x18]; //取出跳板存储的x0
sub sp, sp, #0xf0; //分配栈空间
stp X0, X1, [SP]; //存储x0-x29
stp X2, X3, [SP,#0x10]
stp X4, X5, [SP,#0x20]
stp X6, X7, [SP,#0x30]
stp X8, X9, [SP,#0x40]
stp X10, X11, [SP,#0x50]
stp X12, X13, [SP,#0x60]
stp X14, X15, [SP,#0x70]
stp X16, X17, [SP,#0x80]
stp X18, X19, [SP,#0x90]
stp X20, X21, [SP,#0xa0]
stp X22, X23, [SP,#0xb0]
stp X24, X25, [SP,#0xc0]
stp X26, X27, [SP,#0xd0]
stp X28, X29, [SP,#0xe0]
mov x0, sp; //x0作为第一个参数,那么操作x0=sp,即操作栈读写保存的寄存器
ldr x1, j_hk_info;
ldr x3, [x1]; //onPreCallBack
bl get_lr_pc; //lr为下条指令
add lr, lr, 8; //lr为blr x3的地址
str lr, [sp, #0x108]; //lr当作pc,覆盖栈上的x0
blr x3
to_popreg:
ldr x0, [sp, #0x100]; //取出状态寄存器
msr NZCV, x0
ldp X0, X1, [SP]; //恢复x0-x29寄存器
ldp X2, X3, [SP,#0x10]
ldp X4, X5, [SP,#0x20]
ldp X6, X7, [SP,#0x30]
ldp X8, X9, [SP,#0x40]
ldp X10, X11, [SP,#0x50]
ldp X12, X13, [SP,#0x60]
ldp X14, X15, [SP,#0x70]
ldp X16, X17, [SP,#0x80]
ldp X18, X19, [SP,#0x90]
ldp X20, X21, [SP,#0xa0]
ldp X22, X23, [SP,#0xb0]
ldp X24, X25, [SP,#0xc0]
ldp X26, X27, [SP,#0xd0]
ldp X28, X29, [SP,#0xe0]
add sp, sp, #0xf0
ldr x30, [sp]; //恢复x30
add sp, sp, #0x20; //恢复为真实sp
get_lr_pc:
ret; //仅用于获取LR/PC
j_hk_info: //结构体STR_HK_INFO
.double 0xffffffffffffffff
j_dump_end:
.end
和dump不同,不再执行原函数,可以直接修改x0、x1寄存器返回值或者什么都不做。这是四种方式中最简单的一种。
void test_dump_just_ret(){
LE("open=%p, callback=%p", open, onPreCallBack);
if (dumpRet((void *)(open), onCallBack, "open") != success) {
LE("hook open error");
}
int fd = open("/system/lib/libc.so", O_RDONLY);
LE("open /system/lib/libc.so, fd=%d", fd);
}
.global replace_start
.global replace_end
.global p_hk_info
.hidden replace_start
.hidden replace_end
.hidden p_hk_info
.data
//这种方式尽量用于标准的c/c++函数,因为通过hook函数再调用原函数,只能保证参数寄存器和lr寄存器是一致的,其他寄存器可能被修改。
replace_start: //如果只是替换/跳到hook函数,其实是不用保存寄存器的,只是重新写比较麻烦,所以在之前的基础上
sub sp, sp, #0x20; //跳板在栈上存储了x0、x1,但是未改变sp的值
mrs x0, NZCV
str x0, [sp, #0x10]; //覆盖跳板存储的x1,存储状态寄存器
str x30, [sp]; //存储x30
add x30, sp, #0x20
str x30, [sp, #0x8]; //存储真实的sp
ldr x0, [sp, #0x18]; //取出跳板存储的x0
sub sp, sp, #0xf0; //分配栈空间
stp X0, X1, [SP]; //存储x0-x29
stp X2, X3, [SP,#0x10]
stp X4, X5, [SP,#0x20]
stp X6, X7, [SP,#0x30]
stp X8, X9, [SP,#0x40]
stp X10, X11, [SP,#0x50]
stp X12, X13, [SP,#0x60]
stp X14, X15, [SP,#0x70]
stp X16, X17, [SP,#0x80]
stp X18, X19, [SP,#0x90]
stp X20, X21, [SP,#0xa0]
stp X22, X23, [SP,#0xb0]
stp X24, X25, [SP,#0xc0]
stp X26, X27, [SP,#0xd0]
stp X28, X29, [SP,#0xe0]
mov x0, sp; //x0作为第一个参数,那么操作x0=sp,即操作栈读写保存的寄存器
ldr x1, p_hk_info;
ldr x3, [x1, #0x10]; //pre_callback,保存lr
bl get_lr_pc; //lr为下条指令
add lr, lr, 8; //lr为blr x3的地址
str lr, [sp, #0x108]; //lr当作pc,覆盖栈上的x0
blr x3
to_call_hkFun:
ldr x0, [sp, #0x100]; //取出状态寄存器
msr NZCV, x0
ldp X0, X1, [SP]; //恢复x0-x29寄存器
ldp X2, X3, [SP,#0x10]
ldp X4, X5, [SP,#0x20]
ldp X6, X7, [SP,#0x30]
ldp X8, X9, [SP,#0x40]
ldp X10, X11, [SP,#0x50]
ldp X12, X13, [SP,#0x60]
ldp X14, X15, [SP,#0x70]
ldp X16, X17, [SP,#0x80]
ldp X18, X19, [SP,#0x90]
ldp X20, X21, [SP,#0xa0]
ldp X22, X23, [SP,#0xb0]
ldp X24, X25, [SP,#0xc0]
ldp X26, X27, [SP,#0xd0]
ldp X28, X29, [SP,#0xe0]
add sp, sp, #0xf0
ldr x30, [sp]; //恢复x30
add sp, sp, #0x20; //恢复为真实sp
ldr lr, p_hk_info;
ldr lr, [lr, #0x28]; //pHkFunAddr
blr lr; //既跳到pHkFunAddr执行,也设置了lr
to_aft_callback: //其实这里可能存在问题,即如果hook函数或者其调用了原函数,非标准函数(非c/c++)未实现栈平衡
//比如手写的精心构造的汇编函数,可能存在覆盖栈上数据
STP X1, X0, [SP, #-0x10]
sub sp, sp, #0x20; //跳板在栈上存储了x0、x1,但是未改变sp的值
mrs x0, NZCV
str x0, [sp, #0x10]; //覆盖跳板存储的x1,存储状态寄存器
str x30, [sp]; //存储x30
add x30, sp, #0x20
str x30, [sp, #0x8]; //存储真实的sp
ldr x0, [sp, #0x18]; //取出跳板存储的x0
sub sp, sp, #0xf0; //分配栈空间
stp X0, X1, [SP]; //存储x0-x29
stp X2, X3, [SP,#0x10]
stp X4, X5, [SP,#0x20]
stp X6, X7, [SP,#0x30]
stp X8, X9, [SP,#0x40]
stp X10, X11, [SP,#0x50]
stp X12, X13, [SP,#0x60]
stp X14, X15, [SP,#0x70]
stp X16, X17, [SP,#0x80]
stp X18, X19, [SP,#0x90]
stp X20, X21, [SP,#0xa0]
stp X22, X23, [SP,#0xb0]
stp X24, X25, [SP,#0xc0]
stp X26, X27, [SP,#0xd0]
stp X28, X29, [SP,#0xe0]
mov x0, sp; //x0作为第一个参数,那么操作x0=sp,即操作栈读写保存的寄存器
ldr x1, p_hk_info;
ldr x3, [x1, #0x20]; //aft_callback, 恢复lr寄存器
bl get_lr_pc; //lr为下条指令
add lr, lr, 8; //lr为blr x3的地址
str lr, [sp, #0x108]; //lr当作pc,覆盖栈上的x0
blr x3; //执行aft_callback
to_popreg:
ldr x0, [sp, #0x100]; //取出状态寄存器
msr NZCV, x0
ldp X0, X1, [SP]; //恢复x0-x29寄存器
ldp X2, X3, [SP,#0x10]
ldp X4, X5, [SP,#0x20]
ldp X6, X7, [SP,#0x30]
ldp X8, X9, [SP,#0x40]
ldp X10, X11, [SP,#0x50]
ldp X12, X13, [SP,#0x60]
ldp X14, X15, [SP,#0x70]
ldp X16, X17, [SP,#0x80]
ldp X18, X19, [SP,#0x90]
ldp X20, X21, [SP,#0xa0]
ldp X22, X23, [SP,#0xb0]
ldp X24, X25, [SP,#0xc0]
ldp X26, X27, [SP,#0xd0]
ldp X28, X29, [SP,#0xe0]
add sp, sp, #0xf0
ldr x30, [sp]; //恢复x30
add sp, sp, #0x20; //恢复为真实sp
get_lr_pc:
br lr; //仅用于获取LR/PC,最后相当于br lr
nop;
p_hk_info: //结构体STR_HK_INFO
.double 0xffffffffffffffff
replace_end:
.end
和dump_with_ret大部分是一致的,执行原函数换成执行hook函数。因为这个hook函数不是shellcode,所以没有好办法在开头加入恢复寄存器的指令,那么就要使用一个无关的寄存器,因为要返回所以lr寄存器被保存了也改变了,所以这里就使用lr寄存器即可,blr lr,既跳到lr保存的地址去执行,也会把下条指令的地址存到lr。
typedef int (*old_open)(const char* pathname,int flags,/*mode_t mode*/...);
typedef int (*old__open)(const char* pathname,int flags,int mode);
typedef int (*old__openat)(int fd, const char *pathname, int flags, int mode);
typedef FILE* (*old_fopen)(const char* __path, const char* __mode);
old_open *ori_open;
old__open *ori__open;
//可变参数的函数,需要自己按照被hook函数的逻辑,解析出参数再传递给原函数。
//因为并不清楚参数个数/类型,如果不改变参数的情况下还有方法不解析参数调用原函数。
//但是如果改变了参数,比如printf中的fmt,那么理论上后面的参数类型个数也应该改变,这种情况下应该是使用者
//已经清楚共用多少参数和类型,应该自己调用,而如果只改fmt,应该会出bug的。
//所以如果只是想打印明确类型的参数,不改变参数直接调用原函数的情况,应该实现下参数的解析重组/传递,待实现
int my_open(const char* pathname,int flags, .../*int mode*/){
mode_t mode = 0;
if (needs_mode(flags)) {
va_list args;
va_start(args, flags);
mode = static_cast<mode_t>(va_arg(args, int));
va_end(args);
}
LE("hk: open %s , %d, %d", pathname ? pathname : "is null", flags, mode);
//测试解除hook
// HK_INFO *pInfo = isHookedByHkFun((void *) (my_open));
// unHook(pInfo);
int fd = -1;
if (!ori_open) {//理论上只有粗心没有给ori_open赋值。
LE("ori_open null !");
exit(1);
}
if (!(*ori_open)) {//理论上应该是hook取消了,但是如果是自己忘了给ori_open赋值或者赋值为NULL,那就是自己的锅了,太粗心了,会陷入死循环。
LE("unhook open");
old_open tmp = open;
ori_open = &tmp;
}
fd = (*ori_open)(pathname, flags, mode);
LE("ori: open %s , fd=%d", pathname ? pathname : "is null", fd);
return fd;
}
void test_replace(){
LE("open=%p, callback=%p", open, onPreCallBack);
const RetInfo info = dump_replace((void *) (open), (void *) (my_open), onPreCallBack,
onCallBack, "open");
if (info.status != success) {
LE("hook open error");
} else {
//考虑到解除hook的问题,不能用getOriFun直接获取备份的函数,应该获取函数的指针
//不然直接返回函数,free函数后无法知道。建议不用自己保存原函数,使用api获取,当然如果没有unhook的情况,就不需要考虑这些问题。
ori_open = (old_open*)(getPoriFun(info.info));
}
int fd = open("/system/lib/libc.so", O_RDONLY);
LE("open /system/lib/libc.so, fd=%d", fd);
unHook(info.info);
}
FILE* my_fopen(const char* pathname,const char* mode){
LE("hk: fopen %s , %s", pathname ? pathname : "is null", mode);
FILE* fd = NULL;
//理论上有可能存在取消hook了,但是hook函数还要执行,所以应该可以再回调原函数了。
//所以如果要绝对安全,那么hook和取消hook时暂停线程,检查函数调用栈是必须的。
auto ori_open = (old_fopen)(getOriFunByHkFun((void *)(my_fopen)));
if (!ori_open) {
ori_open = (old_fopen)fopen;
}
fd = ori_open(pathname, mode);
LE("ori: fopen %s , fd=%p", pathname ? pathname : "is null", fd);
return fd;
}
//9.0上arm64未导出__open函数,而arm下实现为:
//.text:0006FEDC
//.text:0006FEDC EXPORT __open
//.text:0006FEDC __open ; DATA XREF: LOAD:0000254C↑o
//.text:0006FEDC ; __unwind {
//.text:0006FEDC PUSH {R7,LR}
//.text:0006FEDE BLX j_abort
//.text:0006FEDE ; } // starts at 6FEDC
//.text:0006FEDE ; End of function __open
//open函数不再走__open,而是__openat,9.0上arm64未导出__openat函数(只是隐藏了符号,可以自己根据字符串解析出地址),arm导出。
void test_justReplace(){
LE("open=%p, callback=%p", open, onPreCallBack);
// const RetInfo info = dump_replace(dlsym(RTLD_DEFAULT, "__openat"), (void *) (my__open), NULL,
// NULL, "__open");
//android高版本没有__open了,__openat也隐藏符号了(只有64位隐藏了)
// const RetInfo info = dump_replace(dlsym(RTLD_DEFAULT, "__openat"), (void *) (my__openat), NULL,
// NULL, "__openat");
const RetInfo info = dump_replace((void*)fopen, (void *) (my_fopen), NULL,
NULL, "fopen");
if (info.status != success) {
LE("hook fopen error=%d", info.status);
}
FILE *pFile = fopen("/system/lib/libc.so", "re");
LE("fopen /system/lib/libc.so, fd=%p", pFile);
unHook(info.info);
}
以上就是4种hook方式和对应的实现。提供给用户的api接口如下:
#ifdef __cplusplus
#include <map>
#include <pthread.h>
#include <vector>
typedef std::vector<HK_INFO*> INFOS;
//typedef std::map<const void*, HK_INFO*> LR_MAP;
#endif
enum hk_status{
success, hooked, error
};
struct RetInfo {
enum hk_status status;
HK_INFO *info;
};
//打印寄存器
/**
* 用户自定义的stub函数,嵌入在hook点中,可直接操作寄存器等
* @param regs 寄存器结构,保存寄存器当前hook点的寄存器信息
* @param pInfo 保存了被hook函数、hook函数等的结构体
*/
void default_onPreCallBack(my_pt_regs *regs, HK_INFO *pInfo);
/**
* 用户自定义的stub函数,嵌入在hook点中,可直接操作寄存器等
* @param regs 寄存器结构,保存寄存器当前hook点的寄存器信息
* @param pInfo 保存了被hook函数、hook函数等的结构体
*/
void default_onCallBack(my_pt_regs *regs, HK_INFO *pInfo);
/**
* 真实函数执行前调用onPreCallBack,执行后调用onCallBack,通过onPreCallBack控制参数,通过onCallBack控制返回值
* @param pBeHookAddr 要hook的地址,必须
* @param onPreCallBack 要插入的回调函数(读写参数寄存器), 可以为NULL(onCallBack不为空),当和onCallBack都为NULL的情况使用默认的打印寄存器的函数default_onPreCallBack,因为什么都不做为什么hook?
* @param onCallBack 要插入的回调函数(读写返回值寄存器),可以为NULL,如果只关心函数执行后的结果
* @param methodName 被hook的函数名称,可以为NULL。
* @return success:成功;error:错误;hooked:已被hook;
*/
hk_status dump(void *pBeHookAddr, void (*onPreCallBack)(struct my_pt_regs *, HK_INFO *pInfo), void (*onCallBack)(struct my_pt_regs *, struct STR_HK_INFO *pInfo) = NULL, const char* methodName = NULL);
/**
* 不执行真实函数,直接操作寄存器,之后恢复寄存器返回,理论上也是可以在onCallBack其中执行真实函数的,但是需要自己封装参数,调用后自己解析寄存器
* @param pBeHookAddr 要hook的地址,必须
* @param onCallBack 要插入的回调函数(读写参数寄存器),必须
* @param methodName 被hook的函数名称,可以为NULL。
* @return success:成功;error:错误;hooked:已被hook;
*/
hk_status dumpRet(void *pBeHookAddr, void (*onCallBack)(struct my_pt_regs *, HK_INFO *pInfo), const char* methodName = NULL);
/**
* 针对标准函数,最常用的hook接口。定义一个和被hook函数原型一致的函数接收处理参数,可直接返回或者调用被备份/修复的原函数
* @param pBeHookAddr 要hook的地址,必须
* @param pHkFunAddr 和被hook函数原型一致的函数,接收处理参数,可直接返回或者调用被备份/修复的原函数,必须
* @param onPreCallBack 要插入的回调函数(读写参数寄存器), 可以为NULL
* @param onCallBack 要插入的回调函数(读写返回值寄存器),可以为NULL,如果只关心函数执行后的结果
* @param methodName 被hook的函数名称,可以为NULL
* @return 因为既要区分三种状态,还存在返回备份/修复的原函数的情况,使用结构体存储两个字段,参考demo。
*/
RetInfo dump_replace(void *pBeHookAddr, void*pHkFunAddr, void (*onPreCallBack)(struct my_pt_regs *, HK_INFO *pInfo) = NULL, void (*onCallBack)(struct my_pt_regs *, struct STR_HK_INFO *pInfo) = NULL, const char* methodName = NULL);
/**
* 通过被hook函数获取数据结构体
* @param pBeHookAddr 被hook函数
* @return 返回HK_INFO结构体
*/
HK_INFO *isHooked(void* pBeHookAddr);
/**
* 通过hook函数获取数据结构体
* @param hkFun hook函数
* @return 返回HK_INFO结构体
*/
HK_INFO *isHookedByHkFun(void* hkFun);
/**
* 获取备份/修复的被hook函数,主要是不清楚结构体字段的用户或者透明指针的情况
* @param info
* @return 返回备份/修复的被hook函数
*/
void* getOriFun(HK_INFO* info);
/**
* 获取备份/修复的被hook函数的指针,二级指针;可用于自己保存,推荐存在取消hook的情况下调用getOriFunByHkFun函数
* @param info
* @return 返回指向存储备份/修复的被hook函数的指针
*/
void** getPoriFun(HK_INFO* info);
/**
* 通过hook函数获取被hook的函数
* @param hkFun hook函数
* @return 返回被hook函数,如果被取消hook或者未被hook返回NULL
*/
void* getOriFunByHkFun(void* hkFun);
/**
* 取消hook,释放shellcode/备份的原方法占用的空间并还原原方法
* @param info 如果成功会释放这个结构体,所以之后这个结构体/指针不能再用
* @return 取消成功true,否则false
*/
bool unHook(HK_INFO* info);
/**
* 取消所有的hook
* @return
*/
bool unHookAll();
以上就是arm64的实现和定义的api接口。arm的只需要依葫芦画瓢即可,比arm64简单多了。
shellcode理论上是arm还是thumb都没有关系,而且Android的编译链中的汇编器不支持大部分的32位Thumb-2指令(默认情况下),
.code 16
//.thumb //和上面效果一致
//.force_thumb //强制thumb
shell_code:
push {r0, r1, r2, r3} //r0=r0, r1=sp(push之前的sp), r2=r14/lr, r3=cpsr
mrs r0, cpsr
str r0, [sp, #0xC]
str r14, [sp, #8]
第四条指令编译报错: Error: lo register required -- `str r14,[sp,#8]'
因为thumb16中能直接操作的寄存器是r0-r7;r8-r12、r14寄存器不能被str、ldr等,ldr pc寄存器也不行,但是可以ldr到r0-r7,再mov到sp寄存器。而thumb模式下的跳板0也是LDR PC, [PC, #0],是32位的thumb32/thumb-2指令,所以理论上armv5和以下的cpu应该是不支持指令的。
因为shellcode中汇编指令超出了thumb16的寄存器范围,使用thumb32/thumb-2指令,汇编器不支持:
Error: unexpected character `w' in type specifier
Error: bad instruction `str.w r14,[sp,#8]'
所以不用在Android.mk中指定LOCAL_ARM_MODE := arm,因为这样整个module都是arm指令、4字节,浪费了空间,所以默认就行。奇怪的是编译出的文件包含arm和thumb32,混合的。没有细看是什么情况,编译c/c++使用的汇编器不一致吗?
呃,后来看到:经过Google工程师的提醒,对于ARM GCC的汇编器,在汇编文件最上面加入.syntax unified之后,Thumb-2 T3 encoding汇编也能正常使用了,比如:
.syntax unified
.text
.align 4
.globl helloThumb
.thumb
.thumb_func
helloThumb:
add.w r0, r0, r1, lsl #2
bx lr
所以在汇编文件中加入
.syntax unified
.force_thumb
可以把操作r0-r7寄存器之外的指令写成,ldr.w、str.w、add.w等,也可以不修改,编译器会自动转成thumb32/thumb-2指令。
编译后就是thumb32/thumb-2指令了,

所以hook arm函数也可以构建thumb的跳板,同样的thumb函数也可以构建arm的跳板。但是为了方便、不考虑四字节对齐,干脆还是都用arm的跳板吧,只要不指定为thumb(默认可能就是)、不指定.syntax unified就始终编译出来的就是arm的跳板。毕竟没有那么严重的强迫症,跳板也占不了多少空间。
LDR PC, [PC, #0]/hook thumb函数或者LDR PC, [PC, #-4]/hook arm函数,理论上在armv5及以上就可以,所以无论是arm到thumb还是thumb到thumb,LDR到PC的地址+1就可以了。同样到arm就保证是非奇数的地址即可。

至于这个shellcode编译到.text还是.data都可以。不同的就是.data中是数据,.text中为函数。
只要cpu是armv5以上就行,因为目前很少armv5及以下的cpu了,所以不考虑支持问题。 ldr pc, [pc, #0/#4],可被编译成arm或者thumb32/thumb-2指令。这里可能有人会有些误解,比如我们要hook的一个so是armeabi的,那么thumb函数只支持thumb16,所以是没有ldr pc这样的指令的,那么对于这样的函数还能使用ldr pc覆盖吗?其实是可以的,因为这条指令能不能被正确解析执行是取决于cpu,只要cpu支持thumb32/thumb-2指令(armv5以上的cpu)即可。thumb32/thumb-2指令更像是thumb16的一个超集(16位的指令应该都是相同的,32位的指令会不同),所以不影响后面的thumb16的指令的解析执行。
所以这里我们不是对当前函数的thumb做兼容性适配而是针对cpu的,而如果要适配armv5以下,就多绕一下好了。
arm:
LDR PC, [PC, #-4];流水线,pc为addr下面的指令,所以-4
addr:0x12345678
thumb32/thumb-2:
LDR PC, [PC, #0];流水线,pc为addr指令
addr:0x12345678
都是占用8条指令,如果thumb函数地址不是4字节对齐的话就加nop或者bx #-2占用10字节。
.global _dump_start
.global _dump_end
.global _hk_info
.global _oriFuc
.hidden _dump_start
.hidden _dump_end
.hidden _hk_info
.hidden _oriFuc
//可用于标准的c/c++函数、非标准函数、函数的一部分(用于读写寄存器),前提都是字节长度足够
//非标准函数即非c/c++编译的函数,那么手写汇编可能存在并不遵守约定的情况,比如我们使用了sp寄存器,并在未使用的栈上保存寄存器
//但是可能不是满递减而是反过来满递增,或者不遵守栈平衡,往栈上写数据,但是并不改变sp寄存器。当然应该是很少见的。
.data
_dump_start: //用于读写寄存器/栈,需要自己解析参数,不能读写返回值,不能阻止原函数(被hook函数)的执行
//从行为上来我觉得更偏向dump,所以起名为dump。
push {r0-r4} //r0=r0,中转用 r1=sp(push之前的sp), r2=r14/lr, r3=pc, r4=cpsr
mrs r0, cpsr
str r0, [sp, #0x10] //r4的位置存放cpsr
str r14, [sp, #8] //r2的位置存放lr
add r14, sp, #0x14
str r14, [sp, #4] //r1的位置存放真实sp
pop {r0} //恢复r0
push {r0-r12} //保存r-r12,之后是r13-r16/cpsr
mov r0, sp
ldr r1, _hk_info;
ldr r3, [r1]; //onPreCallBack
str pc, [sp, #0x3c]; //存储pc,arm模式,所以pc+8,指向ldr r0, [sp, #0x40]
blx r3
ldr r0, [sp, #0x40] //cpsr
msr cpsr, r0
ldmfd sp!, {r0-r12} //恢复r0-r12
ldr r14, [sp, #4] //恢复r14/lr
ldr sp, [r13] //恢复sp(push之前的sp)
ldr pc, _oriFuc
_oriFuc: //备份/修复的原方法
.word 0x12345678
_hk_info: //结构体STR_HK_INFO
.word 0x12345678
_dump_end:
.end
这里和arm64比有点不同的是多了一个标号/4个字节存放_oriFuc/原函数的地址,这么做的原因是比较无奈的,因为_hk_info取到的是HK_INFO,还需要再计算一次才能得到pOriFuncAddr,这样就需要占用一个寄存器去计算,pc寄存器是不能这么用的,所以还是在shellcode中存储吧。当然其实还可以让_hk_info存放的是pOriFuncAddr这个变量的地址,那么可以一次取到pc寄存器中,但是其他shellcode都要变且不如原来的直观/简单了,同样的方式还可以把pOriFuncAddr放在结构体头部,然后_hk_info存放pOriFuncAddr变量的地址/HK_INFO结构体的地址,也是可以的,但是也是要变动太多。而且其实只有这一个shellcode需要多定义一个_oriFuc,其他是不需要的,所以折衷后就这样了。
demo和arm64一致,api也是一致的。arm和thumb共用这一个shellcode,注意的一点就是如果被hook的函数是thumb,那么_oriFuc存放的地址+1即可。
.global r_dump_start
.global r_dump_end
.global r_hk_info
.hidden r_dump_start
.hidden r_dump_end
.hidden r_hk_info
.data
r_dump_start: //用于读写寄存器/栈,需要自己解析参数,不能读写返回值,不能阻止原函数(被hook函数)的执行
//从行为上来我觉得更偏向dump,所以起名为dump。
push {r0-r4} //r0=r0,中转用 r1=sp(push之前的sp), r2=r14/lr, r3=pc, r4=cpsr
mrs r0, cpsr
str r0, [sp, #0x10] //r4的位置存放cpsr
str r14, [sp, #8] //r2的位置存放lr
add r14, sp, #0x14
str r14, [sp, #4] //r1的位置存放真实sp
pop {r0} //恢复r0
push {r0-r12} //保存r-r12,之后是r13-r16/cpsr
mov r0, sp
ldr r1, r_hk_info;
ldr r3, [r1, #8]; //pre_callback
str pc, [sp, #0x3c]; //存储pc
blx r3
to_call_oriFun:
ldr r0, [sp, #0x40] //cpsr
msr cpsr, r0
ldmfd sp!, {r0-r12} //恢复r0-r12
ldr r14, [sp, #4] //恢复r14/lr
ldr sp, [r13] //恢复sp(push之前的sp)
ldr lr, r_hk_info
ldr lr, [lr, #4]; //pOriFuncAddr
blx lr;
to_aft_callback:
push {r0-r4} //r0=r0,中转用 r1=sp(push之前的sp), r2=r14/lr, r3=pc, r4=cpsr
mrs r0, cpsr
str r0, [sp, #0x10] //r4的位置存放cpsr
str r14, [sp, #8] //r2的位置存放lr
add r14, sp, #0x14
str r14, [sp, #4] //r1的位置存放真实sp
pop {r0} //恢复r0
push {r0-r12} //保存r-r12,之后是r13-r16/cpsr
mov r0, sp
ldr r1, r_hk_info;
ldr r3, [r1, #0x10]; //aft_callback
str pc, [sp, #0x3c]; //存储pc
blx r3
to_popreg:
ldr r0, [sp, #0x40] //cpsr
msr cpsr, r0
ldmfd sp!, {r0-r12} //恢复r0-r12
ldr r14, [sp, #4] //恢复r14/lr
ldr sp, [r13] //恢复sp(push之前的sp)
mov pc, lr;
r_hk_info: //结构体STR_HK_INFO
.word 0x12345678
r_dump_end:
.end
demo和arm64一致,这里不用多定义一个_oriFuc,因为保存了lr,不是必须使用pc寄存器了。也是让lr寄存器做了很多事情。
.global j_dump_start
.global j_dump_end
.global j_hk_info
.hidden j_dump_start
.hidden j_dump_end
.hidden j_hk_info
.data
j_dump_start:
push {r0-r4} //r0=r0,中转用 r1=sp(push之前的sp), r2=r14/lr, r3=pc, r4=cpsr
mrs r0, cpsr
str r0, [sp, #0x10] //r4的位置存放cpsr
str r14, [sp, #8] //r2的位置存放lr
add r14, sp, #0x14
str r14, [sp, #4] //r1的位置存放真实sp
pop {r0} //恢复r0
push {r0-r12} //保存r-r12,之后是r13-r16/cpsr
mov r0, sp
ldr r1, j_hk_info;
ldr r3, [r1]; //onPreCallBack
str pc, [sp, #0x3c]; //存储pc
blx r3
ldr r0, [sp, #0x40] //cpsr
msr cpsr, r0
ldmfd sp!, {r0-r12} //恢复r0-r12
ldr r14, [sp, #4] //恢复r14/lr
ldr sp, [r13] //恢复sp(push之前的sp)
mov pc, lr
j_hk_info: //结构体STR_HK_INFO
.word 0x12345678
j_dump_end:
.end
demo和arm64一致。
.global replace_start
.global replace_end
.global p_hk_info
.hidden replace_start
.hidden replace_end
.hidden p_hk_info
.data
//这种方式尽量用于标准的c/c++函数,因为通过hook函数再调用原函数,只能保证参数寄存器和lr寄存器是一致的,其他寄存器可能被修改。
replace_start: //如果只是替换/跳到hook函数,其实是不用保存寄存器的,只是重新写比较麻烦,所以在之前的基础上
push {r0-r4} //r0=r0,中转用 r1=sp(push之前的sp), r2=r14/lr, r3=pc, r4=cpsr
mrs r0, cpsr
str r0, [sp, #0x10] //r4的位置存放cpsr
str r14, [sp, #8] //r2的位置存放lr
add r14, sp, #0x14
str r14, [sp, #4] //r1的位置存放真实sp
pop {r0} //恢复r0
push {r0-r12} //保存r-r12,之后是r13-r16/cpsr
mov r0, sp
ldr r1, p_hk_info;
ldr r3, [r1, #8]; //pre_callback,保存lr
str pc, [sp, #0x3c]; //存储pc
blx r3
to_call_oriFun:
ldr r0, [sp, #0x40] //cpsr
msr cpsr, r0
ldmfd sp!, {r0-r12} //恢复r0-r12
ldr r14, [sp, #4] //恢复r14/lr
ldr sp, [r13] //恢复sp(push之前的sp)
ldr lr, p_hk_info
ldr lr, [lr, #0x14]; //pHkFunAddr
blx lr;
to_aft_callback:
push {r0-r4} //r0=r0,中转用 r1=sp(push之前的sp), r2=r14/lr, r3=pc, r4=cpsr
mrs r0, cpsr
str r0, [sp, #0x10] //r4的位置存放cpsr
str r14, [sp, #8] //r2的位置存放lr
add r14, sp, #0x14
str r14, [sp, #4] //r1的位置存放真实sp
pop {r0} //恢复r0
push {r0-r12} //保存r-r12,之后是r13-r16/cpsr
mov r0, sp
ldr r1, p_hk_info;
ldr r3, [r1, #0x10]; //aft_callback
str pc, [sp, #0x3c]; //存储pc
blx r3
to_popreg:
ldr r0, [sp, #0x40] //cpsr
msr cpsr, r0
ldmfd sp!, {r0-r12} //恢复r0-r12
ldr r14, [sp, #4] //恢复r14/lr
ldr sp, [r13] //恢复sp(push之前的sp)
mov pc, lr;
p_hk_info: //结构体STR_HK_INFO
.word 0x12345678
replace_end:
.end
demo和arm64一致。
框架已经搭好了且已经可以运行了,接下来就是一些细节的优化。
shellcode、备份/修复的原函数不能使用malloc等非内存对齐的函数,原因在下面的Android_Inline_Hook中较严重的一些bug有提到。但是每个shellcode都占用一页内存也太浪费了,理想情况是一页用完或者放不下一个shellcode再申请,但是考虑到解除hook释放shellcode等问题,这么做实现起来很复杂,要监听整个流程,暂时没精力写这么完美,所以就把shellcode和备份/修复的原函数放在同一页内存,当然还是用不满,但是至少节约了一些,这样解除hook直接释放这页内存都可以,当然还可以进一步把HK_INFO这个结构体也放在这一页内,但是不确定是否确实有些系统只允许内存权限为rw或者rp,暂时没有把HK_INFO混在一起。
void test_args_11(int a0, int a1, int a2, int a3, int a4, int a5, int a6, int a7, int a8, int a9, int a10, int a11){
LE("a0=%d, a1=%d, a2=%d, a3=%d, a4=%d, a5=%d,"
" a6=%d, a7=%d, a8=%d, a9=%d, a10=%d. a11=%d",
a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11);
}
void nullCallBack(my_pt_regs *regs, HK_INFO *pInfo){
}
void test_args_for_cache(){
//测试多参数传递情况
dump((void *)(test_args_11), nullCallBack, /*onCallBack*/NULL);
// dumpRet((void *) (test_args_11), onPreCallBack, "test_args_11");
test_args_11(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11);
HK_INFO *pInfo = isHooked((void*)test_args_11);
// unHook(pInfo);
}
//拷贝回原指令后不刷新缓存。机器不同、cpu性能、缓存大小不同等,这个阈值需要自己测试。
//性能好的机器,循环100次基本都可以100%复现,差的机器200次也只有几次复现。
void test_cache(){
test_args_for_cache();
LE("test_args_11=%p", test_args_11);
for (int i = 0; i < 188; ++i) {
if (i == 178) {
HK_INFO *pInfo = isHooked((void *) test_args_11);
unHook(pInfo);
}
test_args_11(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11);
LE("i=%d", i);
// usleep(1);
}
LE("end test cache");
}
为了测试不刷新缓存的情况,使用了循环,因为实测发现想触发缓存不刷新crash概率太低了。我能想到的就是循环执行一段指令,触发jit,提高指令被缓存的概率。然后修改指令后不刷新缓存,触发crash。关于如何刷新缓存在下面的Android_Inline_Hook中较严重的一些bug有提到。
只是确认下,因为代码写的没问题,所以应该是不会有问题的。
int (*ori__system_property_get)(const char *name, char *value);
//注意操作参数之前最好都检查参数是否为null,如果原函数也是crash处理还行,如果不是就改变了函数逻辑、进程中断等
//所以细节都要注意,参数和返回值也有对应关系
int my__system_property_get(const char *name, char *value){
LE("hk: __system_property_get(%s, %p)", name ? name : "is null", value);
ori__system_property_get = (int (*)(const char *, char *))(getOriFunByHkFun(
(void *) (my__system_property_get)));
if (!ori__system_property_get) {
ori__system_property_get = __system_property_get;
}
int ret = ori__system_property_get(name, value);
LE("ori: __system_property_get(%s, %s)=%d", name ? name : "is null", ret > 0 ? value : "is null", ret);
if (name && !strncmp("ro.serialno", name, strlen("ro.serialno"))) {
strcpy(value, "12345678");
return (int)(strlen("12345678"));
}
return ret;
}
//测试既是参数也做返回值的函数
void test__system_property_get() {
const RetInfo info = dump_replace((void*)__system_property_get, (void *) (my__system_property_get), NULL,
NULL, "__system_property_get");
if (info.status != success) {
LE("hook __system_property_get error=%d", info.status);
}
char sn[256];
int ret = __system_property_get("ro.serialno", sn);
LE("serialno=%s", ret > 0 ? sn : "is null");
//2019-12-23 17:10:14.810 22213-22213/? E/zhuo: hk: __system_property_get(ro.serialno, 0x7fd55a2088)
//2019-12-23 17:10:14.810 22213-22213/? E/zhuo: ori: __system_property_get(ro.serialno, 8acd10de)=8
//2019-12-23 17:10:14.810 22213-22213/? E/zhuo: lr aft_callback
//2019-12-23 17:10:14.810 22213-22213/? E/zhuo: serialno=12345678
}
测试不存在hookzz的问题。
基本上上面已经是大部分的框架和部分细节,剩下的对用户api的具体实现都是很灵活的,只要保持和api函数原型和定义行为一致即可(已实现)。
跳板、shellcode、api都实现了,还剩下一个对备份的原函数进行修复。还没有重新开始写,暂时用的Android_Inline_Hook修复pc相关的指令。在写arm的vmp,到时抽取出指令解析和生成的代码就好了,加一些简单的语义分析。
线程暂停的问题,抽时间加上,因为一般自己常用的场景是fork一个进程还未执行应用代码的时候,基本上不会出现多线程导致的crach,不过还是应该提供接口,毕竟有些场景需要,但是怕是也不能百分百解决线程问题,还需要用户自己判断函数行为。
可变参数的传递,如果不修改只是调用原函数倒是有思路了,但是如果是对明确的参数进行修改了,还是要抽时间写解析构造参数的部分。
1、arm64指令修复
.text:0000000000000EF8 dlopen ; DATA XREF: LOAD:0000000000000508↑o
.text:0000000000000EF8
.text:0000000000000EF8 var_s0 = 0
.text:0000000000000EF8
.text:0000000000000EF8 ; __unwind {
.text:0000000000000EF8 STP X29, X30, [SP,#-0x10+var_s0]!
.text:0000000000000EFC MOV X29, SP
.text:0000000000000F00 MOV X2, X30
.text:0000000000000F04 BL .__loader_dlopen
.text:0000000000000F08 LDP X29, X30, [SP+var_s0],#0x10
.text:0000000000000F0C RET
.text:0000000000000F0C ; } // starts at EF8
.text:0000000000000F0C ; End of function dlopen
例如其中的BL指令并未修复,这个其实还容易修复,可以替换成LDR LR, 8(应该放到最后);BLR LR;因为既然是BL指令那么LR寄存器肯定是会被修改,那就说明LR寄存器已经保存了,所以我们就使用LR寄存器也是没有关系的。
如果是B指令才麻烦,因为不能操作pc,那么就要至少使用一个寄存器且还不能是LR,只能使用x16、x17了。
后面看了下Android_Inline_Hook写了B指令的修复(是错的),BL指令未实现,后来自己写了BL指令的实现,只是暂时用,不准备在这个基础上再写了,缺少的待修复的指令还有不少,且已实现的也有一些错误,待重构。

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bidLFS27-1577937079578)(https://i.imgur.com/tqVxVK2.png)]](https://img-blog.csdnimg.cn/2020010212290735.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0Rhb0RpdkRpRmFuZw==,size_16,color_FFFFFF,t_70)
修复之后Android9.0 arm64的dlopen可以hook了。
2、arm64从备份/修复的原方法跳回跳板0之后执行,采用的方式是在备份/修复的原方法后面加入:
STP X1, X0, [SP, #-0x10]
LDR X0, 8
BR X0
ADDR(64)
LDR X0, [SP, -0x8]
和跳板0是一样的,但是跳板0是一个函数的开头的概率很大,所以一般都是会栈平衡的,sp指向栈顶,所以暂时存放寄存器不会被覆盖。而放在后面就不太确定能保证sp指向栈顶了,所以可能要考虑解析前几条指令是否有操作sp,或者尽可能的把寄存器储存在sp-较大的值,或者使用x16、x17寄存器。。。 当然这个可能概率较小,可以先不管。
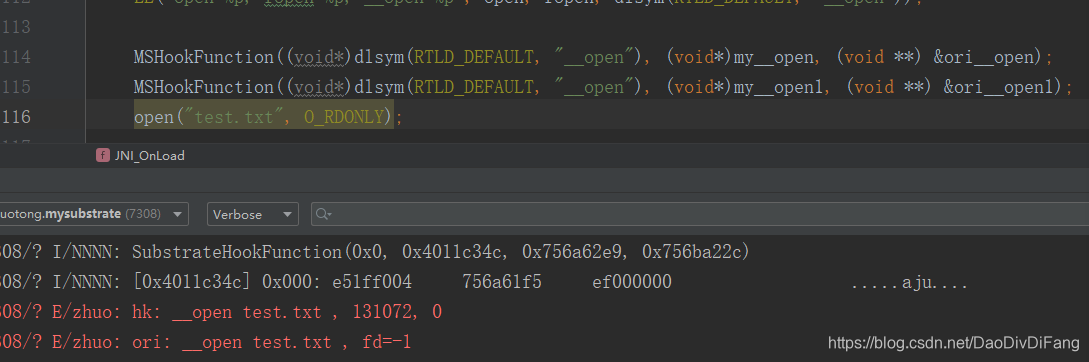
3、无法重复hook一个函数,当然这个是说在其他框架或者本框架的另一个版本(或者无法维护保存hook的容器,如果是本框架内是可以重复hook同一个函数的,比如解除hook再hook,或者再扩展成链表的形式,依次调用hook/dump函数),其实就是指令修复不完整,arm的应该是ldr pc没有正确修复,这个事情排在后面,不是特别重要。
也可以参考Cydia Substrate框架,不过有点坑,只处理thumb的情况,thumb可以多次hook,arm下第二次hook不生效。直接判断第一条指令是不是ldr pc, [pc, #-4];是的话就认为是已经被hook过的,直接返回。
if (result != NULL) {
if (backup[0] == A$ldr_rd_$rn_im$(A$pc, A$pc, 4 - 8)) {
*result = reinterpret_cast<void *>(backup[1]);
return;
}
可见只有第一次hook生效。
而thumb模式,把上次的shellcode赋给result,再把跳板中的地址替换为新的地址。
f (
(align == 0 || area[0] == T$nop) &&
thumb[0] == T$bx(A$pc) &&
thumb[1] == T$nop &&
arm[0] == A$ldr_rd_$rn_im$(A$pc, A$pc, 4 - 8)
) {
if (result != NULL)
*result = reinterpret_cast<void *>(arm[1]);
SubstrateHookMemory code(process, arm + 1, sizeof(uint32_t) * 1);
arm[1] = reinterpret_cast<uint32_t>(replace);
return sizeof(arm[0]);
}

{kind=link}
感觉是不是写代码的忘了处理arm的,因为arm也是可以同样处理的,呃,无语的bug。
例如这么修复即可,前面再加一行SubstrateHookMemory code(process, symbol, used);修改权限/刷新缓存。

其实以上bug根本原因还是指令的修复,这是最麻烦的,也是暂时没办法达到百分百修复的,尤其是arm64,只能抽时间逐步完善了。
1、在init_arry函数和普通函数引用vector,但其实不是同一个vector的,导致无法保存已hook的信息,应该用指针,不能直接引用vector。属于代码逻辑bug。
2、内存权限问题 虽然mprotect的时候取一页内存,但是因为使用的malloc申请的内存可能是夹缝中内存,前后被使用了?也可能是申请后剩余的被其他占用更改了权限?虽然mprotect不报错,修改权限成功了,但是有几率signal 11 (SIGSEGV), code 2 (SEGV_ACCERR)。还要一种可能是malloc返回的地址是奇数的,未测试,理论上如果是奇数的也会crash的,因为内存没有对齐。 所以使用
long pagesize = sysconf(_SC_PAGE_SIZE);
void *pNewShellCode = NULL;// = malloc(sShellCodeLength);
int code = posix_memalign(&pNewShellCode,pagesize, pagesize);
或者
mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_ANONYMOUS | MAP_PRIVATE, 0, 0);
申请一整页的内存,但是这样肯定是浪费的,所以之后应该在这个内存上填充,占满之后再申请新的一页内存。
3、修改内存权限,ChangePageProperty中如果超过一页的内存,第二页和之后的都没有设置权限,属于代码逻辑bug,但是没有超过2页的情况,所以不会触发。
4、arm刷新缓存错误/未生效,arm64未刷新缓存。 //通过测试:cacheflush无法刷新缓存,不过不确定是不是第三个参数的问题,ICACHE, DCACHE, or BCACHE,抽时间再看吧, //不过gtoad的把地址转成无符号指针再取值肯定是不正确的。 // cacheflush(((uint32_t)(info->pBeHookAddr)), info->backUpLength, 0);//测试也无法刷新缓存 // cacheflush(PAGE_START((uintptr_t)info->pBeHookAddr), PAGE_SIZE, 0);//测试也无法刷新缓存 // cacheflush(info->pBeHookAddr, info->backUpLength, 0);//测试也无法刷新缓存
//而确实有效的刷新缓存的是:可以直接传地址和结束地址,也可以刷新一页,效果来看都成功了。 // if(TEST_BIT0((uint32_t)info->pBeHookAddr)){ // __builtin___clear_cache((char*)info->pBeHookAddr - 1, (char*)info->pBeHookAddr - 1 + info->backUpLength); // } else { // __builtin___clear_cache((char *) info->pBeHookAddr, // (char *) info->pBeHookAddr + info->backUpLength); // } // __builtin___clear_cache(PAGE_START((uintptr_t)info->pBeHookAddr), PAGE_END((uintptr_t)info->pBeHookAddr + info->backUpLength));
//后记: //测试cacheflush可以,但是和int cacheflush(long __addr, long __nbytes, long __cache);不一致的是,从命名来看第二个参数应该是大小,不应该是 //结束地址,而且linux man中Some or all of the address range addr to (addr+nbytes-1) is not accessible。哎奇怪,抽时间再逆向看看吧。 /if(TEST_BIT0((uint32_t)info->pBeHookAddr)){ cacheflush((char)info->pBeHookAddr - 1, (char*)info->pBeHookAddr - 1 + info->backUpLength, 0); } else { cacheflush((char *) info->pBeHookAddr, (char ) info->pBeHookAddr + info->backUpLength, 0); }/
//目前来看使用__builtin___clear_cache吧,应该是都实现了且确实可用,如果某些系统不生效在抠出系统调用吧,先使用函数吧。
为了避免不必要的纠纷,前面列举的框架只是为了引出为什么在写一个的原因,没有其他的意思。只是想写一个让大多数人更容易使用、了解实现细节、能更容易参与开发完善的Android inline hook项目。所以暂时不考虑代码的艺术,而尽量的写成易懂的代码,且代码写了较多、完整的注释。
也是希望不止是为了使用,而能让使用者能自己了解原理,自己就能解决错误,这方面感谢下Android_Inline_Hook。之前也写过一些自己个人用的临时hook,但是时间久了代码都找不到了,且也都是最简单的实现,临时用下的,所以也打算重新实现下,没时间一直拖着,看到Android_Inline_Hook,发现很多思路和我之前是一样的,代码也易懂,看一下就全明白了,所以一开始在Android_Inline_Hook上面修了一些bug凑合用,不过后来修的多了发现不如重新实现,因为很多地方不兼容、架构有冲突了。
整理下,最近开源了,希望各位大佬多参与,完善修复bug,多谢!