Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
ReentrantLock: wakeup a single task on unlock and add a short spin (J…
…uliaLang#56814) I propose a change in the implementation of the `ReentrantLock` to improve its overall throughput for short critical sections and fix the quadratic wake-up behavior where each unlock schedules **all** waiting tasks on the lock's wait queue. This implementation follows the same principles of the `Mutex` in the [parking_lot](https://github.com/Amanieu/parking_lot/tree/master) Rust crate which is based on the Webkit [WTF::ParkingLot](https://webkit.org/blog/6161/locking-in-webkit/) class. Only the basic working principle is implemented here, further improvements such as eventual fairness will be proposed separately. The gist of the change is that we add one extra state to the lock, essentially going from: ``` 0x0 => The lock is not locked 0x1 => The lock is locked by exactly one task. No other task is waiting for it. 0x2 => The lock is locked and some other task tried to lock but failed (conflict) ``` To: ``` ``` In the current implementation we must schedule all tasks to cause a conflict (state 0x2) because on unlock we only notify any task if the lock is in the conflict state. This behavior means that with high contention and a short critical section the tasks will be effectively spinning in the scheduler queue. With the extra state the proposed implementation has enough information to know if there are other tasks to be notified or not, which means we can always notify one task at a time while preserving the optimized path of not notifying if there are no tasks waiting. To improve throughput for short critical sections we also introduce a bounded amount of spinning before attempting to park. Not spinning on the scheduler queue greatly reduces the CPU utilization of the following example: ```julia function example() lock = ReentrantLock() @sync begin for i in 1:10000 Threads.@Spawn begin @lock lock begin sleep(0.001) end end end end end @time example() ``` Current: ``` 28.890623 seconds (101.65 k allocations: 7.646 MiB, 0.25% compilation time) ``` 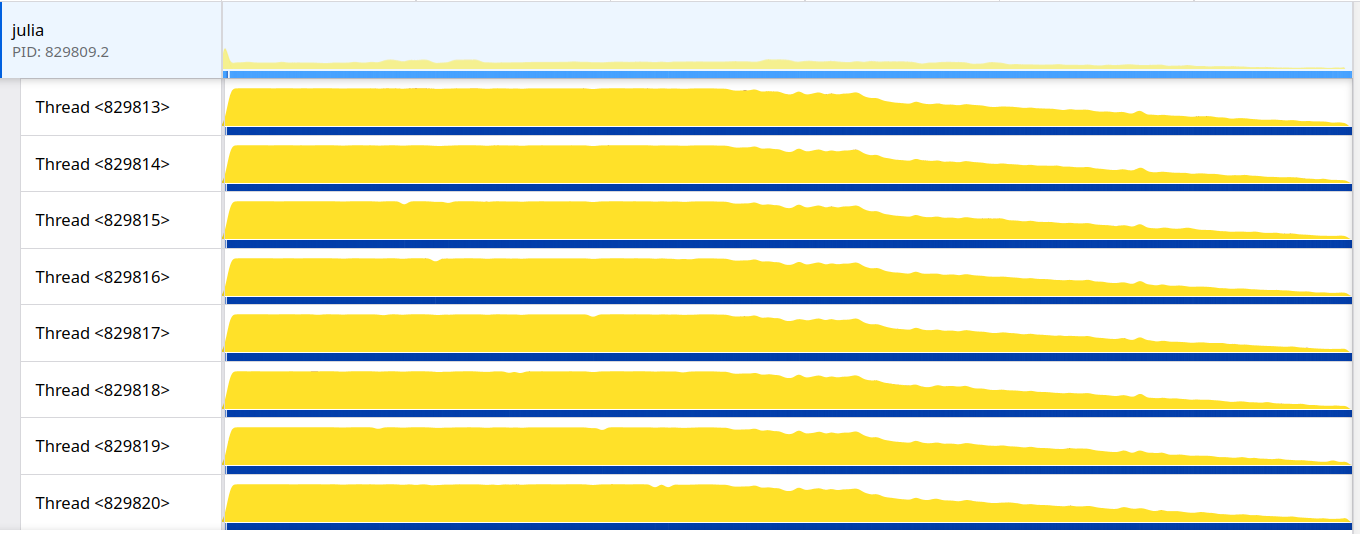 Proposed: ``` 22.806669 seconds (101.65 k allocations: 7.814 MiB, 0.35% compilation time) ```  In a micro-benchmark where 8 threads contend for a single lock with a very short critical section we see a ~2x improvement. Current: ``` 8-element Vector{Int64}: 6258688 5373952 6651904 6389760 6586368 3899392 5177344 5505024 Total iterations: 45842432 ``` Proposed: ``` 8-element Vector{Int64}: 12320768 12976128 10354688 12845056 7503872 13598720 13860864 11993088 Total iterations: 95453184 ``` ~~In the uncontended scenario the extra bookkeeping causes a 10% throughput reduction:~~ EDIT: I reverted _trylock to the simple case to recover the uncontended throughput and now both implementations are on the same ballpark (without hurting the above numbers). In the uncontended scenario: Current: ``` Total iterations: 236748800 ``` Proposed: ``` Total iterations: 237699072 ``` Closes JuliaLang#56182
- Loading branch information
1 parent
ce667bc
commit 627cdee