Druid 26.0.0
Apache Druid 26.0.0 contains over 390 new features, bug fixes, performance enhancements, documentation improvements, and additional test coverage from 65 contributors.
See the complete set of changes for additional details.
Review the upgrade notes and incompatible changes before you upgrade to Druid 26.0.0.
# Highlights
# Auto type column schema (experimental)
A new "auto" type column schema and indexer has been added to native ingestion as the next logical iteration of the nested column functionality. This automatic type column indexer that produces the most appropriate column for the given inputs, producing either STRING, ARRAY<STRING>, LONG, ARRAY<LONG>, DOUBLE, ARRAY<DOUBLE>, or COMPLEX<json> columns, all sharing a common 'nested' format.
All columns produced by 'auto' have indexes to aid in fast filtering (unlike classic LONG and DOUBLE columns) and use cardinality based thresholds to attempt to only utilize these indexes when it is likely to actually speed up the query (unlike classic STRING columns).
COMPLEX<json> columns produced by this 'auto' indexer store arrays of simple scalar types differently than their 'json' (v4) counterparts, storing them as ARRAY typed columns. This means that the JSON_VALUE function can now extract entire arrays, for example JSON_VALUE(nested, '$.array' RETURNING BIGINT ARRAY). There is no change with how arrays of complex objects are stored at this time.
This improvement also adds a completely new functionality to Druid, ARRAY typed columns, which unlike classic multi-value STRING columns behave with ARRAY semantics. These columns can currently only be created via the 'auto' type indexer when all values are an arrays with the same type of elements.
An array data type is a data type that allows you to store multiple values in a single column of a database table. Arrays are typically used to store sets of related data that can be easily accessed and manipulated as a group.
This release adds support for storing arrays of primitive values such as ARRAY<STRING>, ARRAY<LONG>, and ARRAY<DOUBLE> as specialized nested columns instead of breaking them into separate element columns.
These changes affect two additional new features available in 26.0: schema auto-discovery and unnest.
# Schema auto-discovery (experimental)
We’re adding schema-auto discovery with type inference to Druid. With this feature, the data type of each incoming field is detected when schema is available. For incoming data which may contain added, dropped, or changed fields, you can choose to reject the nonconforming data (“the database is always correct - rejecting bad data!”), or you can let schema auto-discovery alter the datasource to match the incoming data (“the data is always right - change the database!”).
Schema auto-discovery is recommend for new use-cases and ingestions. For existing use-cases be careful switching to schema auto-discovery because Druid will ingest array-like values (e.g. ["tag1", "tag2]) as ARRAY<STRING> type columns instead of multi-value (MV) strings, this could cause issues in downstream apps replying on MV behavior. Hold off switching until an official migration path is available.
To use this feature, set spec.dataSchema.dimensionsSpec.useSchemaDiscovery to true in your task or supervisor spec or, if using the data loader in the console, uncheck the Explicitly define schema toggle on the Configure schema step. Druid can infer the entire schema or some of it if you explicitly list dimensions in your dimensions list.
Schema auto-discovery is available for native batch and streaming ingestion.
# UNNEST arrays (experimental)
Part of what’s cool about UNNEST is how it allows a wider range of operations that weren’t possible on Array data types. You can unnest arrays with either the UNNEST function (SQL) or the unnest datasource (native).
Unnest converts nested arrays or tables into individual rows. The UNNEST function is particularly useful when working with complex data types that contain nested arrays, such as JSON.
For example, suppose you have a table called "orders" with a column called "items" that contains an array of products for each order. You can use unnest to extract the individual products ("each_item") like in the following SQL example:
SELECT order_id, each_item FROM orders, UNNEST(items) as unnested(each_item)This produces a result set with one row for each item in each order, with columns for the order ID and the individual item
Note the comma after the left table/datasource (orders in the example). It is required.
#13268 #13943 #13934 #13922 #13892 #13576 #13554 #13085
# Sort-merge join and hash shuffle join for MSQ
We can now perform shuffle joins by setting by setting the context parameter sqlJoinAlgorithm to sortMerge for the sort-merge algorithm or omitting it to perform broadcast joins (default).
Multi-stage queries can use a sort-merge join algorithm. With this algorithm, each pairwise join is planned into its own stage with two inputs. This approach is generally less performant but more scalable, than broadcast.
Set the context parameter sqlJoinAlgorithm to sortMerge to use this method.
Broadcast hash joins are similar to how native join queries are executed.
# Storage improvements on dictionary compression
Switching to using frontcoding dictionary compression (experimental) can save up to 30% with little to no impact to query performance.
This release further improves the frontCoded type of stringEncodingStrategy on indexSpec with a new segment format version, which typically has faster read speeds and reduced segment size. This improvement is backwards incompatible with Druid 25.0. Added a new formatVersion option, which defaults to the the current version 0. Set formatVersion to 1 to start using the new version.
Additionally, overall storage size, particularly with using larger buckets, has been improved.
# Additional features and improvements
# MSQ task engine
# Array-valued parameters for SQL queries
Added support for array-valued parameters for SQL queries using. You can now reuse the same SQL for every ingestion, only passing in a different set of input files as query parameters.
# EXTEND clause for the EXTERN functions
You can now use an EXTEND clause to provide a list of column definitions for your source data in standard SQL format.
The web console now defaults to using the EXTEND clause syntax for all queries auto-generated in the web console. This means that SQL-based ingestion statements generated by the web console in Druid 26 (such as from the SQL based data loader) will not work in earlier versions of Druid.
# MSQ fault tolerance
Added the ability for MSQ controller task to retry worker task in case of failures. To enable, pass faultTolerance:true in the query context.
-
Connections to S3 for fault tolerance and durable shuffle storage are now more resilient. #13741
-
Improved S3 connector #13960
- Added retries and max fetch size.
- Implemented S3utils for interacting with APIs.
# Use tombstones when running REPLACE operations
REPLACE for SQL-based ingestion now generates tombstones instead of marking segments as unused.
If you downgrade Druid, you can only downgrade to a version that also supports tombstones.
# Better ingestion splits
The MSQ task engine now considers file size when determining splits. Previously, file size was ignored; all files were treated as equal weight when determining splits.
Also applies to native batch.
# Enabled composed storage for Supersorter intermediate data
Druid now supports composable storage for intermediate data. This allows the data to be stored on multiple storage systems through local disk and durable storage. Behavior is enabled when the runtime config druid.indexer.task.tmpStorageBytesPerTask is set and the query context parameter durableShuffleStorage is set to true.
# Other MSQ improvements
- Added a check to prevent the collector from downsampling the same bucket indefinitely. #13663
- Druid now supports composable storage for SuperSorter intermediate data. This allows the data to be stored on multiple storage systems through fallbacks. #13368
- When MSQ throws a
NOT_ENOUGH_MEMORY_FAULTerror, the error message now suggests a JVMXmxsetting to provide. #13846 - Add a new fault "QueryRuntimeError" to MSQ engine to capture native query errors. #13926
maxResultsSizehas been removed from the S3OutputConfig and a defaultchunkSizeof 100MiB is now present. This change primarily affects users who wish to use durable storage for MSQ jobs.
# Ingestion
# Indexing on multiple disks
You can now use multiple disks for indexing tasks. In the runtime properties for the MiddleManager/Indexer, use the following property to set the disks and directories:
druid.worker.baseTaskDirs=[\"PATH1\",\"PATH2\",...]
# Improved default fetch settings for Kinesis
Updated the following fetch settings for the Kinesis indexing service:
fetchThreads: Twice the number of processors available to the task.fetchDelayMillis: 0 (no delay between fetches).recordsPerFetch: 100 MB or an estimated 5% of available heap, whichever is smaller, divided byfetchThreads.recordBufferSize: 100 MB or an estimated 10% of available heap, whichever is smaller.maxRecordsPerPoll: 100 for regular records, 1 for aggregated records.
# Added fields in the sampler API response
The response from /druid/indexer/v1/sampler now includes the following:
logicalDimension: list of the most restrictive typed dimension schemasphysicalDimension: list of dimension schemas actually used to sample the datalogicalSegmentSchema: full resulting segment schema for the set of rows sampled
# Multi-dimensional range partitioning for Hadoop-based ingestion
Hadoop-based ingestion now supports multi-dimensional range partitioning. #13303
# Other ingestion improvements
- Improved performance when ingesting JSON data. #13545
- Added
contextmap toHadoopIngestionSpec. You can set thecontextmap directly inHadoopIngestionSpecusing the command line (non-task) version or in thecontextmap forHadoopIndexTaskwhich is then automatically added toHadoopIngestionSpec. #13624
# Querying
Many of the querying improvements for Druid 26.0 are discussed in the highlights section. This section describes additional improvements to querying in Druid.
# New post aggregators for Tuple sketches
You can now do the following operations with Tuple sketches using post aggregators:
- Get the sketch output as Base64 String.
- Provide a constant Tuple sketch in a post aggregation step that can be used in set operations.
- Estimate the sum of summary/metrics objects associated with Tuple sketches.
# Support for SQL functions on Tuple sketches
Added SQL functions for creating and operating on Tuple sketches.
# Improved nested column performance
Improve nested column performance by adding cardinality based thresholds for range and predicate indexes to choose to skip using bitmap indexes. #13977
# Improved logs for query errors
Logs for query errors now include more information about the exception that occurred, such as error code and class.
# Improve performance of SQL operators NVL and COALESCE
SQL operators NVL and COALESCE with 2 arguments now plan to a native NVL expression, which supports the vector engine. Multi-argument COALESCE still plans into a case_searched, which is not vectorized.
# Improved performance for composite key joins
Composite key joins are now faster.
# Other querying improvements
- Improved exception logging of queries during planning. Previously, a class of
QueryExceptionwould throw away the causes making it hard to determine what failed in the SQL planner. #13609
- Added function equivalent to Math.pow to support square, cube, square root. #13704
- Enabled merge-style operations that combine multiple streams. This means that query operators are now pausable. #13694
- Various improvements to improve query performance and logic. #13902
# Metrics
# New server view metrics
The following metrics are now available for Brokers:
| Metrics | Description | Normal value |
|---|---|---|
init/serverview/time |
Time taken to initialize the broker server view. Useful to detect if brokers are taking too long to start. | Depends on the number of segments. |
init/metadatacache/time |
Time taken to initialize the broker segment metadata cache. Useful to detect if brokers are taking too long to start | Depends on the number of segments. |
The following metric is now available for Coordinators:
| Metrics | Description | Normal value |
|---|---|---|
init/serverview/time |
Time taken to initialize the coordinator server view. | Depends on the number of segments |
# Additional metadata for native ingestion metrics
You can now add additional metadata to the ingestion metrics emitted from the Druid cluster. Users can pass a map of metadata in the ingestion spec context parameters. These get added to the ingestion metrics. You can then tag these metrics with other metadata besides the existing tags like taskId. For more information, see General native ingestion metrics.
# Peon monitor override when using MiddleManager-less ingestion
You can now override druid.monitoring.monitors if you don't want to inherit monitors from the Overlord. Use the following property: druid.indexer.runner.peonMonitors.
# Cluster management
# Enabled round-robin segment assignment and batch segment allocation by default
Round-robin segment assignment greatly speeds up Coordinator run times and is hugely beneficial to all clusters. Batch segment allocation works extremely well when you have multiple concurrent real-time tasks for a single supervisor.
# Improved client change counter in HTTP Server View
The client change counter is now more efficient and resets in fewer situations.
# Enabled configuration of ZooKeeper connection retries
You can now override the default ZooKeeper connection retry count. In situations where the underlying k8s node loses network connectivity or is no longer able to talk to ZooKeeper, configuring a fast fail can trigger pod restarts which can then reassign the pod to a healthy k8s node.
# Improve memory usage on Historicals
Reduced segment heap footprint.
# MiddleManager-less extension
# Better sidecar support
The following property has been added to improve support for sidecars:
druid.indexer.runner.primaryContainerName=OVERLORD_CONTAINER_NAME: Set this to the name of your Druid container, such asdruid-overlord. The default setting is the first container in thepodSpeclist.
Use this property when Druid is not the first container, such as when you're using Istio and the istio-proxy sidecar gets injected as the first container.
# Other improvements for MiddleManager-less extension
- The
druid-kubernetes-overlord-extensionscan now be loaded in any Druid service. #13872 - You can now add files to the common configuration directory when deploying on Kubernetes. #13795
- You can now specify a Kubernetes pod spec per task type. #13896
- You can now override
druid.monitoring.monitors. If you don't want to inherit monitors from the Overlord, you can override the monitors with the following config:druid.indexer.runner.peonMonitors.#14028 - Added live reports for
KubernetesTaskRunner. #13986
# Compaction
# Added a new API for compaction configuration history
Added API endpoint CoordinatorCompactionConfigsResource#getCompactionConfigHistory to return the history of changes to automatic compaction configuration history. If the datasource does not exist or it has no compaction history, an empty list is returned
# Security
# Support for the HTTP Strict-Transport-Security response header
Added support for the HTTP Strict-Transport-Security response header.
Druid does not include this header by default. You must enable it in runtime properties by setting druid.server.http.enableHSTS to true.
# Add JWT authenticator support for validating ID Tokens #13242
Expands the OIDC based auth in Druid by adding a JWT Authenticator that validates ID Tokens associated with a request. The existing pac4j authenticator works for authenticating web users while accessing the console, whereas this authenticator is for validating Druid API requests made by Direct clients. Services already supporting OIDC can attach their ID tokens to the Druid requests
under the Authorization request header.
# Allow custom scope when using pac4j
Updated OpenID Connect extension configuration with scope information.
Applications use druid.auth.pac4j.oidc.scope during authentication to authorize access to a user's details.
# Web console
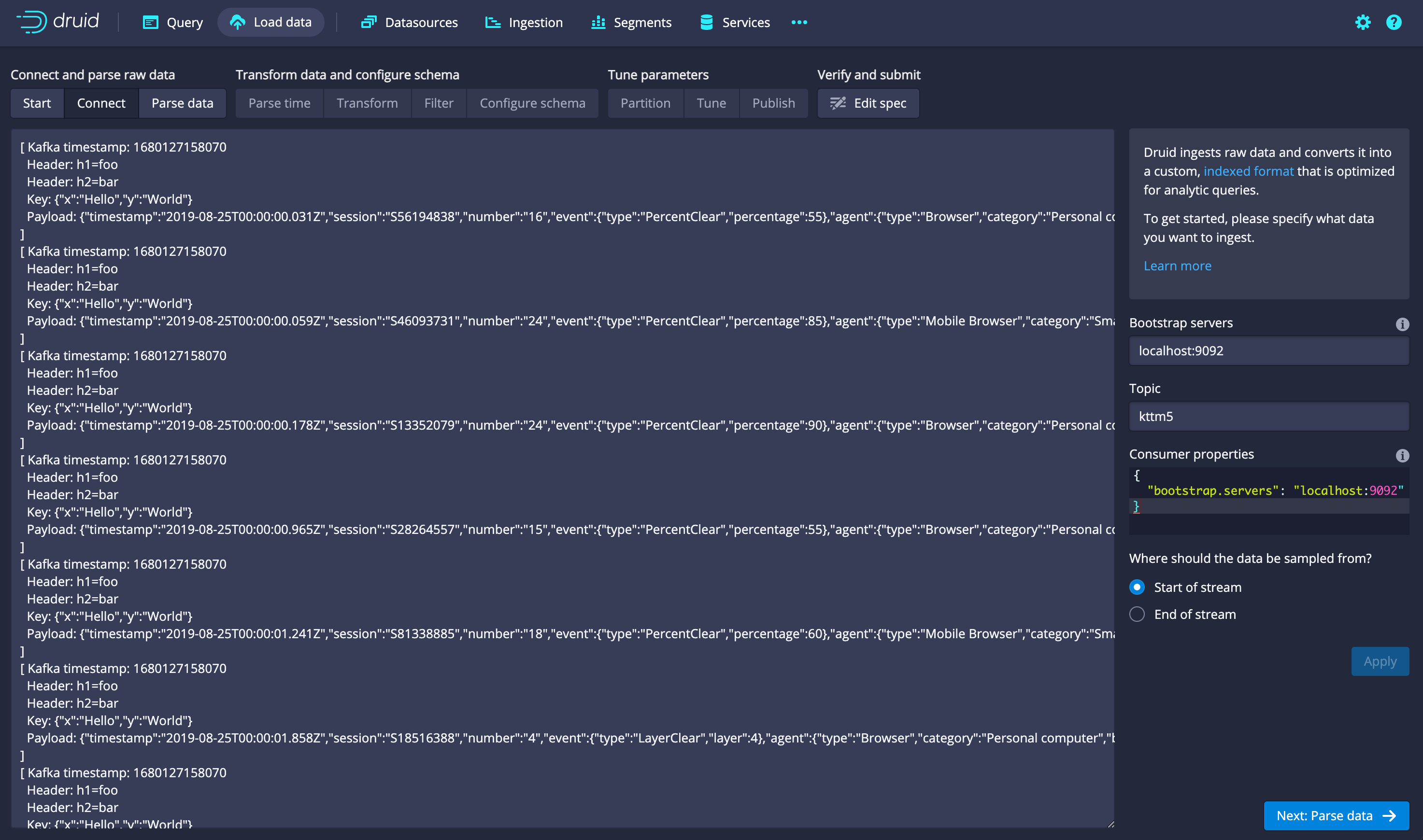
# Kafka metadata is included by default when loading Kafka streams with the data loader
The streaming data loader in the console added support for the Kafka input format, which gives you access to the Kafka metadata fields like the key and the Kafka timestamp. This is used by default when you choose a Kafka stream as the data source.

# Overlord dynamic config
Added a form with JSON fallback to the Overlord dynamic config dialog.

# Other web console improvements:
- Added view to see compaction history. #13861
- Added segment writing progress indicator. #13929
- Added icons for SQL
NULLdatatype. #13786 - Improved error reporting. #13636
- Improved the look of Group by totals in the Services view. #13631
- Improved the autocompletion when typing queries. #13830
- Improved cell rendering to show
"". #13786 - Changed views to only be enabled if they work. #13786
# Docs
# SQL tutorial using Jupyter notebook
Added a new tutorial to our collection of Jupyter Notebook-based Druid tutorials.
This interactive tutorial introduces you to the unique aspects of Druid SQL with the primary focus on the SELECT statement. For more information, see Learn the basics of Druid SQL.
# Python Druid API
Added a Python API for use in Jupyter notebooks.
# Updated Docker Compose
This release includes several improvements to the docker-compose.yml file that Druid tutorials reference:
- Added configuration to bind Postgres instance on the default port ("5432") to the
docker-compose.ymlfile. - Updated Broker, Historical, MiddleManager, and Router instances to use Druid 24.0.1 on the
docker-compose.ymlfile. - Removed trailing space on the
docker-compose.ymlfile.
# Bug fixes
Druid 26.0.0 contains 80 bug fixes, the complete list is available here.
# Dependency updates
The following dependencies have had their versions bumped:
- Apache Kafka to version 3.4.0 #13802
- Apache Zookeeper to version 3.5.10 #13715
- Joda-Time to version 2.12.4 #13999
- Kubernetes Java Client to 6.4.1 #14028
The full list is available here.
# Upgrade notes and incompatible changes
# Upgrade notes
# Real-time tasks
Optimized query performance by lowering the default maxRowsInMemory for real-time ingestion, which might lower overall ingestion throughput #13939
# Incompatible changes
# Firehose ingestion removed
The firehose/parser specification used by legacy Druid streaming formats is removed.
Firehose ingestion was deprecated in version 0.17, and support for this ingestion was removed in version 24.0.
# Information schema now uses numeric column types
The Druid system table (INFORMATION_SCHEMA) now uses SQL types instead of Druid types for columns. This change makes the INFORMATION_SCHEMA table behave more like standard SQL. You may need to update your queries in the following scenarios in order to avoid unexpected results if you depend either of the following:
- Numeric fields being treated as strings.
- Column numbering starting at 0. Column numbering is now 1-based.
# frontCoded segment format change
The frontCoded type of stringEncodingStrategy on indexSpec with a new segment format version, which typically has faster read speeds and reduced segment size. This improvement is backwards incompatible with Druid 25.0.
For more information, see the frontCoded string encoding strategy highlight.
# Developer notes
# Null value coercion moved out of expression processing engine
Null values input to and created by the Druid native expression processing engine no longer coerce null to the type appropriate 'default' value if druid.generic.useDefaultValueForNull=true. This should not impact existing behavior since this has been shifted onto the consumer and internally operators will still use default values in this mode. However, there may be subtle behavior changes around the handling of null values. Direct callers can get default values by using the new valueOrDefault() method of ExprEval, instead of value().
# Simplified dependencies
druid-core, extendedset, and druid-hll modules have been consolidated into druid-processing to simplify dependencies. Any extensions referencing these should be updated to use druid-processing instead. Existing extension binaries should continue to function normally when used with newer versions of Druid.
This change does not impact end users. It does impact anyone who develops extensions for Druid.
# Credits
Thanks to everyone who contributed to this release!
@317brian
@a2l007
@abhagraw
@abhishekagarwal87
@abhishekrb19
@adarshsanjeev
@AdheipSingh
@amaechler
@AmatyaAvadhanula
@anshu-makkar
@ApoorvGuptaAi
@asdf2014
@benkrug
@capistrant
@churromorales
@clintropolis
@cryptoe
@dependabot[bot]
@dongjoon-hyun
@drudi-at-coffee
@ektravel
@EylonLevy
@findingrish
@frankgrimes97
@g1y
@georgew5656
@gianm
@hqx871
@imply-cheddar
@imply-elliott
@isandeep41
@jaegwonseo
@jasonk000
@jgoz
@jwitko
@kaijianding
@kfaraz
@LakshSingla
@maytasm
@nlippis
@p-
@paul-rogers
@pen4
@raboof
@rohangarg
@sairamdevarashetty
@sergioferragut
@somu-imply
@soullkk
@suneet-s
@SurajKadam7
@techdocsmith
@tejasparbat
@tejaswini-imply
@tijoparacka
@TSFenwick
@varachit
@vogievetsky
@vtlim
@winminsoe
@writer-jill
@xvrl
@yurmix
@zachjsh
@zemin-piao