[SPARK-25332][SQL] select broadcast join instead of sortMergeJoin for the small size table even query fired via new session/context #22758
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -193,6 +193,16 @@ private[hive] class HiveMetastoreCatalog(sparkSession: SparkSession) extends Log | |
| None) | ||
| val logicalRelation = cached.getOrElse { | ||
| val updatedTable = inferIfNeeded(relation, options, fileFormat) | ||
| // Intialize the catalogTable stats if its not defined.An intial value has to be defined | ||
| // so that the hive statistics will be updated after each insert command. | ||
| val withStats = { | ||
| if (updatedTable.stats == None) { | ||
|
Member
Contributor
Author
There was a problem hiding this comment.
|
||
| val sizeInBytes = HiveUtils.getSizeInBytes(updatedTable, sparkSession) | ||
| updatedTable.copy(stats = Some(CatalogStatistics(sizeInBytes = BigInt(sizeInBytes)))) | ||
| } else { | ||
| updatedTable | ||
| } | ||
| } | ||
| val created = | ||
| LogicalRelation( | ||
| DataSource( | ||
|
|
@@ -202,7 +212,7 @@ private[hive] class HiveMetastoreCatalog(sparkSession: SparkSession) extends Log | |
| bucketSpec = None, | ||
| options = options, | ||
| className = fileType).resolveRelation(), | ||
| table = withStats) | ||
|
|
||
| catalogProxy.cacheTable(tableIdentifier, created) | ||
| created | ||
|
|
||
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I don't quite understand why table must have stats. For both file sources and hive tables, we will estimate the data size with files, if the table doesn't have stats.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Thanks for your valuable feedback.
My observations :
but after create table command, when we do insert command within the same session Hive statistics is not getting updated due to below validation where condition expects stats to be non-empty as below
But if we re-launch spark-shell and trying to do insert command the Hivestatistics will be saved and now onward the stats will be taken from HiveStats and the flow will never try to estimate the data size with file .
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
This is the thing I don't understand. Like I said before, even if table has no stats, Spark will still get a stats via the
DetermineTableStatsrule.There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
@sujith71955 What if
spark.sql.statistics.size.autoUpdate.enabled=falseorhive.stats.autogather=false? It still update stats?There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Yes its default setting which means false. but i think it should be fine to keep default setting in this scenario .
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Right,but i DefaultStatistics will return default value for the stats
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
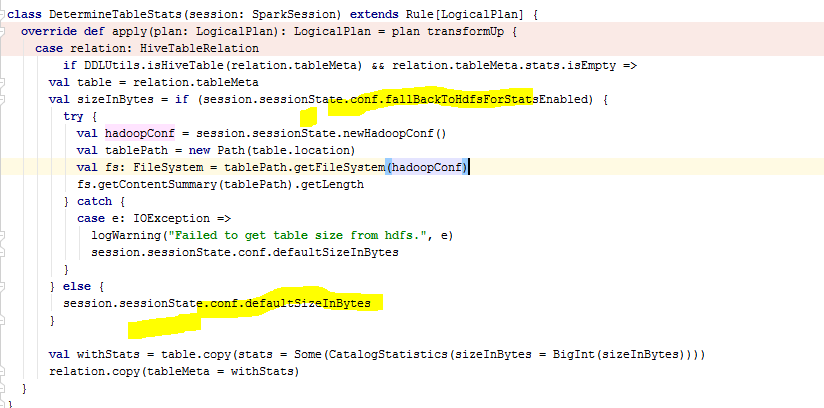
The table created in the current session does not have stats. In this situation. It gets
sizeInBytesfromspark/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/LogicalRelation.scala
Lines 42 to 46 in 1ff4a77
spark/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/HadoopFsRelation.scala
Lines 88 to 91 in 25c2776
.
It's realy size, that why it's
broadcast join. In fact, we should invalidate this table to let Spark use theDetermineTableStatsto take effect. I am doing it here: #22721There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
You are right its about considering the default size, but i am not very sure whether we shall invalidate the cache, i will explain my understanding below.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
@cloud-fan DetermineStats is just initializing the stats if the stats is not set, only if session.sessionState.conf.fallBackToHdfsForStatsEnabled is true then the rule is deriving the stats from file system and updating the stats as shown below code snippet. In insert flow this condition never gets executed, so the stats will be still none.