[SPARK-41191] [SQL] Cache Table is not working while nested caches exist #38703
Conversation
|
Can one of the admins verify this patch? |
|
ping @cloud-fan |
| outerAttrs.map(_.canonicalized), | ||
| ExprId(0), | ||
| childOutputs.map(_.canonicalized.asInstanceOf[Attribute]), | ||
| plan.canonicalized.output, |
There was a problem hiding this comment.
This looks correct, but I don't know how is this related to the cache problem. Can you elaborate?
There was a problem hiding this comment.
The premise of using cache is that canonicalized of two plans is equals.
canonicalized of plan of two ListQuery is equals, but canonicalized of childOutputs is different because their exprIds are different.
In the end, the cache did not take effect.
plan to be executed:
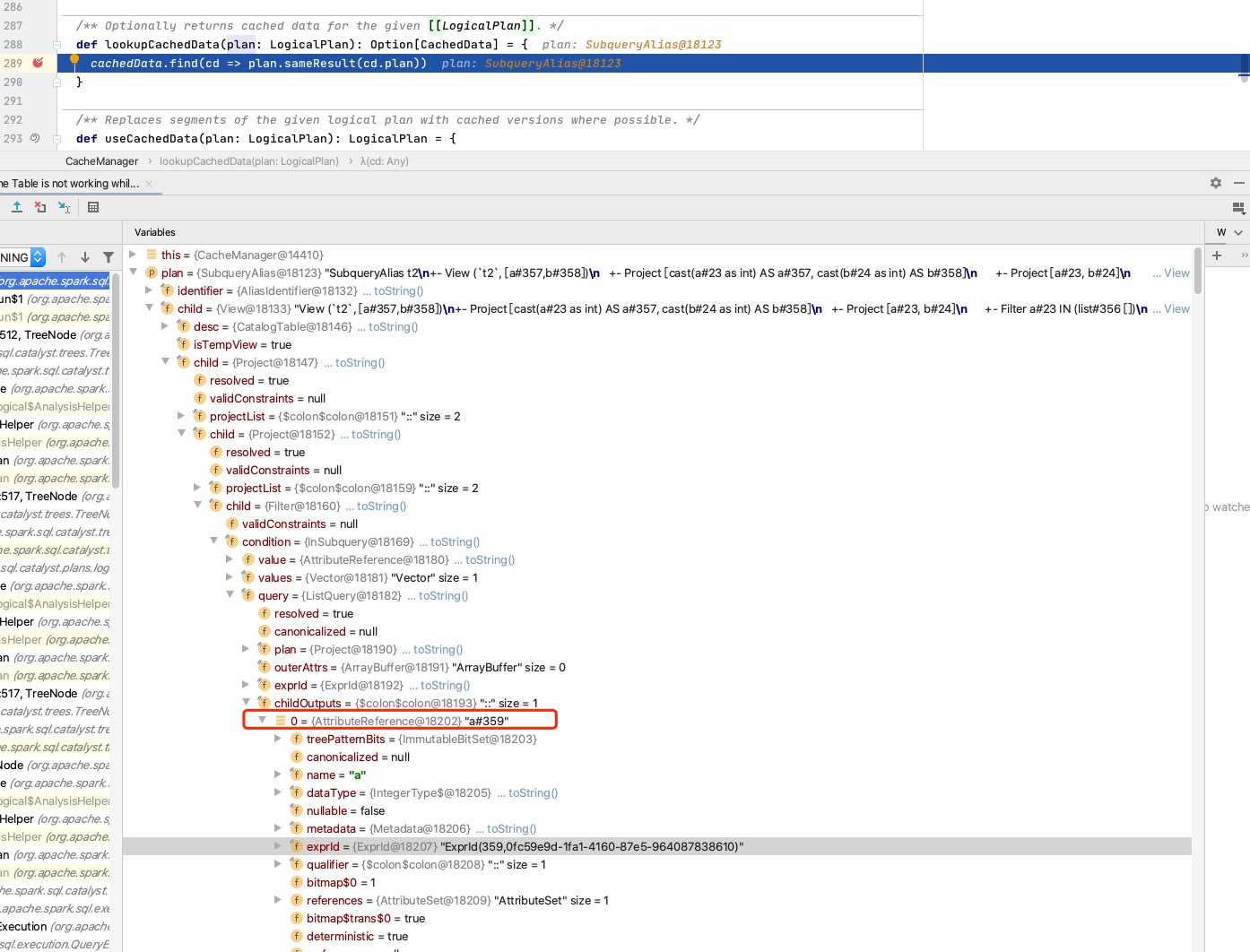
Plan that have been cached:
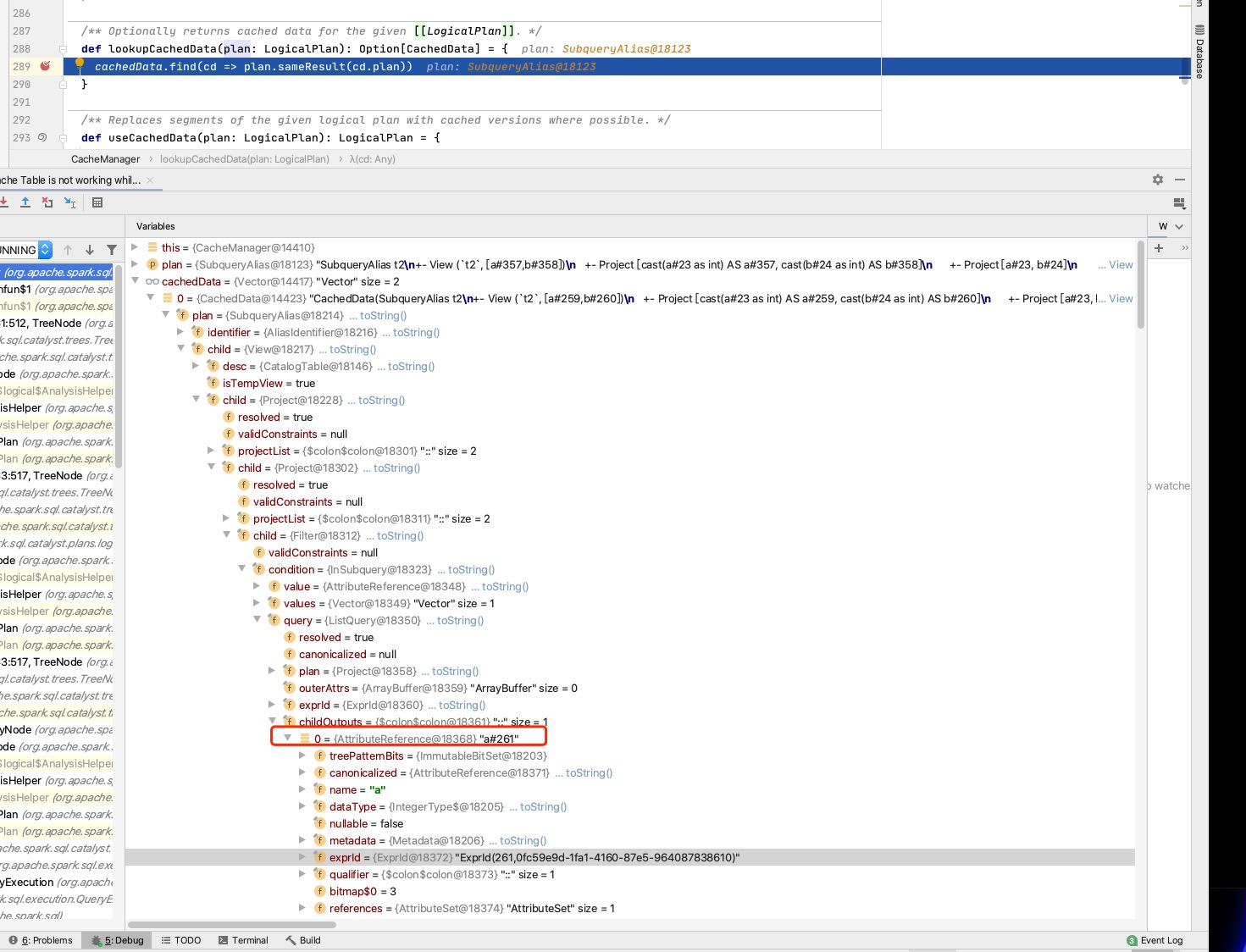
There was a problem hiding this comment.
@allisonwang-db do you know why we have childOutputs? It seems to be child.output most of the time
There was a problem hiding this comment.
Or should we delete childOutputs?
There was a problem hiding this comment.
I'm experiencing the similar issue after upgrading Spark version from 3.2 to 3.3 when updating AWS EMR version from 6.7.0 to 6.9.0. May I ask which Spark version this issue starts with? And I'm wondering if Spark has any plan on pushing this fix?
|
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
What changes were proposed in this pull request?
For example the following statement:
The cached t2 is not used in the third statement
before pr:
after pr:
Why are the changes needed?
performance improvement
Does this PR introduce any user-facing change?
No
How was this patch tested?
added test