-
Notifications
You must be signed in to change notification settings - Fork 29k
[SPARK-41191] [SQL] Cache Table is not working while nested caches exist #38703
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
Closed
Closed
Changes from all commits
Commits
Show all changes
2 commits
Select commit
Hold shift + click to select a range
File filter
Filter by extension
Conversations
Failed to load comments.
Loading
Jump to
Jump to file
Failed to load files.
Loading
Diff view
Diff view
There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
This looks correct, but I don't know how is this related to the cache problem. Can you elaborate?
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
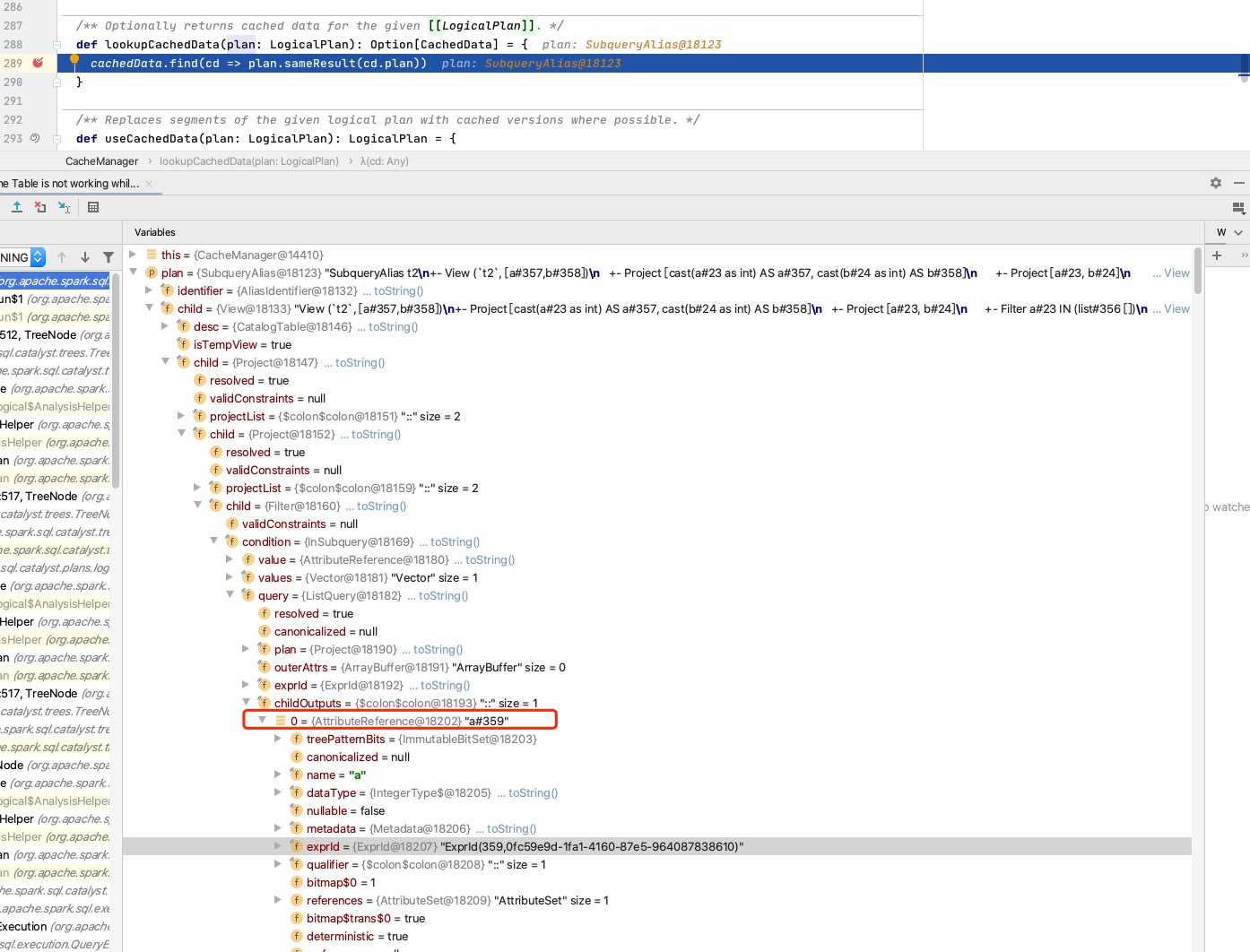
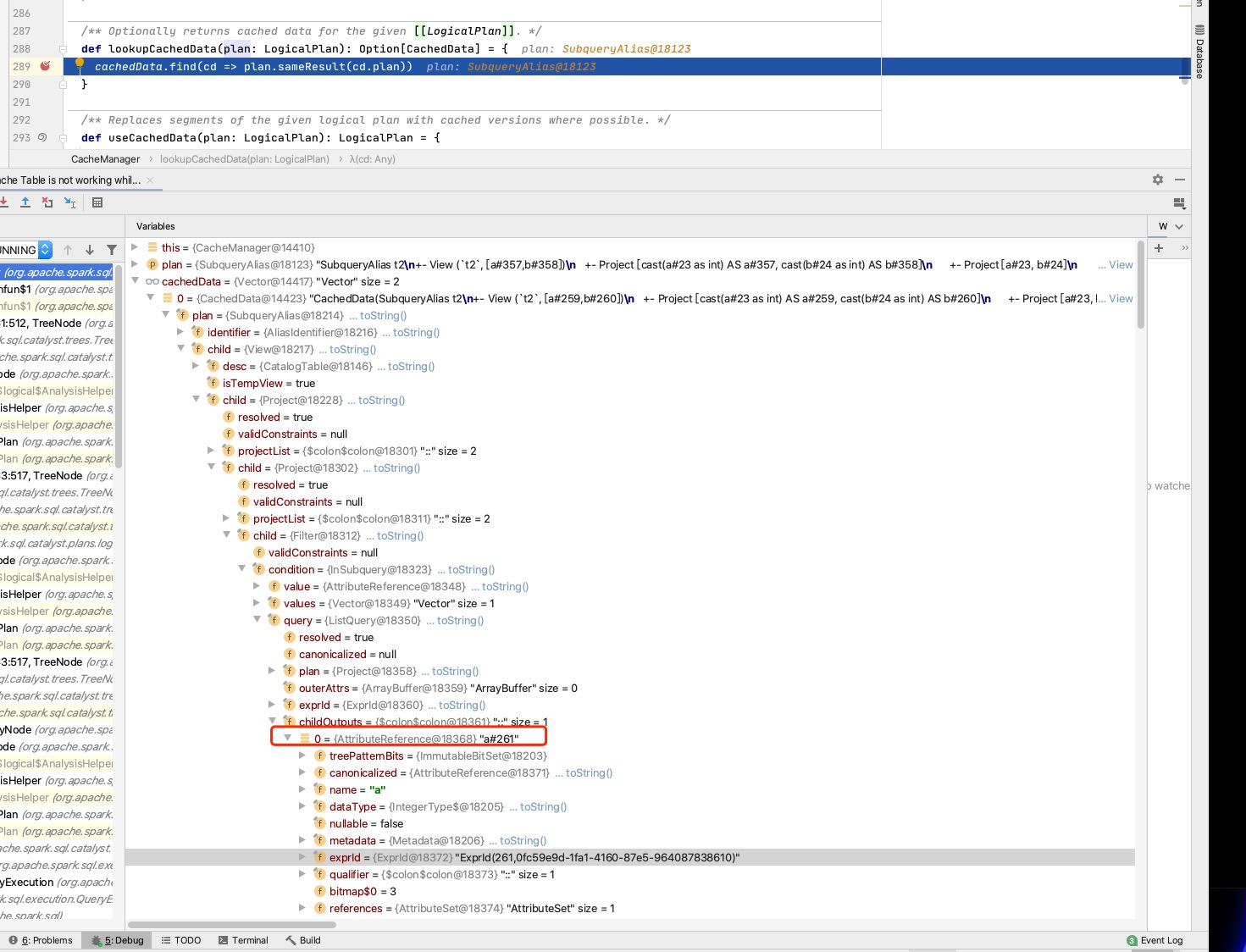
The premise of using cache is that
canonicalizedof two plans is equals.canonicalizedofplanof twoListQueryis equals, butcanonicalizedof childOutputs is different because their exprIds are different.In the end, the cache did not take effect.
plan to be executed:
Plan that have been cached:
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
@allisonwang-db do you know why we have
childOutputs? It seems to bechild.outputmost of the timeThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Or should we delete childOutputs?
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
I'm experiencing the similar issue after upgrading Spark version from 3.2 to 3.3 when updating AWS EMR version from 6.7.0 to 6.9.0. May I ask which Spark version this issue starts with? And I'm wondering if Spark has any plan on pushing this fix?