[SPARK-42172][CONNECT] Scala Client Mima Compatibility Tests #39712
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -33,6 +33,7 @@ | |
| <properties> | ||
| <sbt.project.name>connect-client-jvm</sbt.project.name> | ||
| <guava.version>31.0.1-jre</guava.version> | ||
| <mima.version>1.1.0</mima.version> | ||
| </properties> | ||
|
|
||
| <dependencies> | ||
|
|
@@ -92,6 +93,13 @@ | |
| <artifactId>mockito-core</artifactId> | ||
| <scope>test</scope> | ||
| </dependency> | ||
| <!-- Use mima to perform the compatibility check --> | ||
|
||
| <dependency> | ||
| <groupId>com.typesafe</groupId> | ||
| <artifactId>mima-core_${scala.binary.version}</artifactId> | ||
| <version>${mima.version}</version> | ||
| <scope>test</scope> | ||
| </dependency> | ||
| </dependencies> | ||
| <build> | ||
| <testOutputDirectory>target/scala-${scala.binary.version}/test-classes</testOutputDirectory> | ||
|
|
||
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -19,6 +19,7 @@ package org.apache.spark.sql | |
| import scala.collection.JavaConverters._ | ||
|
|
||
| import org.apache.spark.connect.proto | ||
| import org.apache.spark.internal.Logging | ||
| import org.apache.spark.sql.Column.fn | ||
| import org.apache.spark.sql.connect.client.unsupported | ||
| import org.apache.spark.sql.functions.lit | ||
|
|
@@ -44,7 +45,7 @@ import org.apache.spark.sql.functions.lit | |
| * | ||
| * @since 3.4.0 | ||
| */ | ||
| class Column private[sql] (private[sql] val expr: proto.Expression) extends Logging { | ||
|
||
|
|
||
| /** | ||
| * Sum of this expression and another expression. | ||
|
|
@@ -80,7 +81,7 @@ class Column private[sql] (private[sql] val expr: proto.Expression) { | |
| } | ||
| } | ||
|
|
||
| private[sql] object Column { | ||
|
||
|
|
||
| def apply(name: String): Column = Column { builder => | ||
| name match { | ||
|
|
||
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,22 @@ | ||
| /* | ||
| * Licensed to the Apache Software Foundation (ASF) under one or more | ||
| * contributor license agreements. See the NOTICE file distributed with | ||
| * this work for additional information regarding copyright ownership. | ||
| * The ASF licenses this file to You under the Apache License, Version 2.0 | ||
| * (the "License"); you may not use this file except in compliance with | ||
| * the License. You may obtain a copy of the License at | ||
| * | ||
| * http://www.apache.org/licenses/LICENSE-2.0 | ||
| * | ||
| * Unless required by applicable law or agreed to in writing, software | ||
| * distributed under the License is distributed on an "AS IS" BASIS, | ||
| * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| * See the License for the specific language governing permissions and | ||
| * limitations under the License. | ||
| */ | ||
|
|
||
| package org.apache.spark | ||
|
|
||
| package object sql { | ||
| type DataFrame = Dataset[Row] | ||
| } |
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,153 @@ | ||
| /* | ||
| * Licensed to the Apache Software Foundation (ASF) under one or more | ||
| * contributor license agreements. See the NOTICE file distributed with | ||
| * this work for additional information regarding copyright ownership. | ||
| * The ASF licenses this file to You under the Apache License, Version 2.0 | ||
| * (the "License"); you may not use this file except in compliance with | ||
| * the License. You may obtain a copy of the License at | ||
| * | ||
| * http://www.apache.org/licenses/LICENSE-2.0 | ||
| * | ||
| * Unless required by applicable law or agreed to in writing, software | ||
| * distributed under the License is distributed on an "AS IS" BASIS, | ||
| * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| * See the License for the specific language governing permissions and | ||
| * limitations under the License. | ||
| */ | ||
| package org.apache.spark.sql.connect.client | ||
|
|
||
| import java.io.File | ||
| import java.net.URLClassLoader | ||
| import java.util.regex.Pattern | ||
|
|
||
| import com.typesafe.tools.mima.core._ | ||
| import com.typesafe.tools.mima.lib.MiMaLib | ||
| import org.scalatest.funsuite.AnyFunSuite // scalastyle:ignore funsuite | ||
| import org.apache.spark.sql.connect.client.util.IntegrationTestUtils._ | ||
|
|
||
| /** | ||
| * This test checks the binary compatibility of the connect client API against the spark SQL API | ||
| * using MiMa. We did not write this check using a SBT build rule as the rule cannot provide the | ||
| * same level of freedom as a test. With a test we can: | ||
| * 1. Specify any two jars to run the compatibility check. | ||
| * 1. Easily make the test automatically pick up all new methods added while the client is being | ||
| * built. | ||
| * | ||
| * The test requires the following artifacts built before running: | ||
| * {{{ | ||
| * spark-sql | ||
| * spark-connect-client-jvm | ||
| * }}} | ||
| * To build the above artifact, use e.g. `sbt package` or `mvn clean install -DskipTests`. | ||
| * | ||
| * When debugging this test, if any changes to the client API, the client jar need to be built | ||
| * before running the test. An example workflow with SBT for this test: | ||
| * 1. Compatibility test has reported an unexpected client API change. | ||
| * 1. Fix the wrong client API. | ||
| * 1. Build the client jar: `sbt package` | ||
| * 1. Run the test again: `sbt "testOnly | ||
| * org.apache.spark.sql.connect.client.CompatibilitySuite"` | ||
| */ | ||
| class CompatibilitySuite extends AnyFunSuite { // scalastyle:ignore funsuite | ||
|
|
||
| private lazy val clientJar: File = | ||
| findJar( | ||
| "connector/connect/client/jvm", | ||
| "spark-connect-client-jvm-assembly", | ||
| "spark-connect-client-jvm") | ||
|
|
||
| private lazy val sqlJar: File = findJar("sql/core", "spark-sql", "spark-sql") | ||
|
|
||
| /** | ||
| * MiMa takes an old jar (sql jar) and a new jar (client jar) as inputs and then reports all | ||
| * incompatibilities found in the new jar. The incompatibility result is then filtered using | ||
| * include and exclude rules. Include rules are first applied to find all client classes that | ||
| * need to be checked. Then exclude rules are applied to filter out all unsupported methods in | ||
| * the client classes. | ||
| */ | ||
| test("compatibility MiMa tests") { | ||
| val mima = new MiMaLib(Seq(clientJar, sqlJar)) | ||
|
||
| val allProblems = mima.collectProblems(sqlJar, clientJar, List.empty) | ||
| val includedRules = Seq( | ||
| IncludeByName("org.apache.spark.sql.Column"), | ||
| IncludeByName("org.apache.spark.sql.Column$"), | ||
| IncludeByName("org.apache.spark.sql.Dataset"), | ||
| // TODO(SPARK-42175) Add the Dataset object definition | ||
| // IncludeByName("org.apache.spark.sql.Dataset$"), | ||
| IncludeByName("org.apache.spark.sql.DataFrame"), | ||
| IncludeByName("org.apache.spark.sql.SparkSession"), | ||
| IncludeByName("org.apache.spark.sql.SparkSession$")) ++ includeImplementedMethods(clientJar) | ||
| val excludeRules = Seq( | ||
| // Filter unsupported rules: | ||
| // Two sql overloading methods are marked experimental in the API and skipped in the client. | ||
| ProblemFilters.exclude[Problem]("org.apache.spark.sql.SparkSession.sql"), | ||
| // Skip all shaded dependencies in the client. | ||
| ProblemFilters.exclude[Problem]("org.sparkproject.*"), | ||
| ProblemFilters.exclude[Problem]("org.apache.spark.connect.proto.*")) | ||
| val problems = allProblems | ||
| .filter { p => | ||
| includedRules.exists(rule => rule(p)) | ||
| } | ||
| .filter { p => | ||
| excludeRules.forall(rule => rule(p)) | ||
| } | ||
|
|
||
| if (problems.nonEmpty) { | ||
| fail( | ||
| s"\nComparing client jar: $clientJar\nand sql jar: $sqlJar\n" + | ||
| problems.map(p => p.description("client")).mkString("\n")) | ||
| } | ||
| } | ||
|
|
||
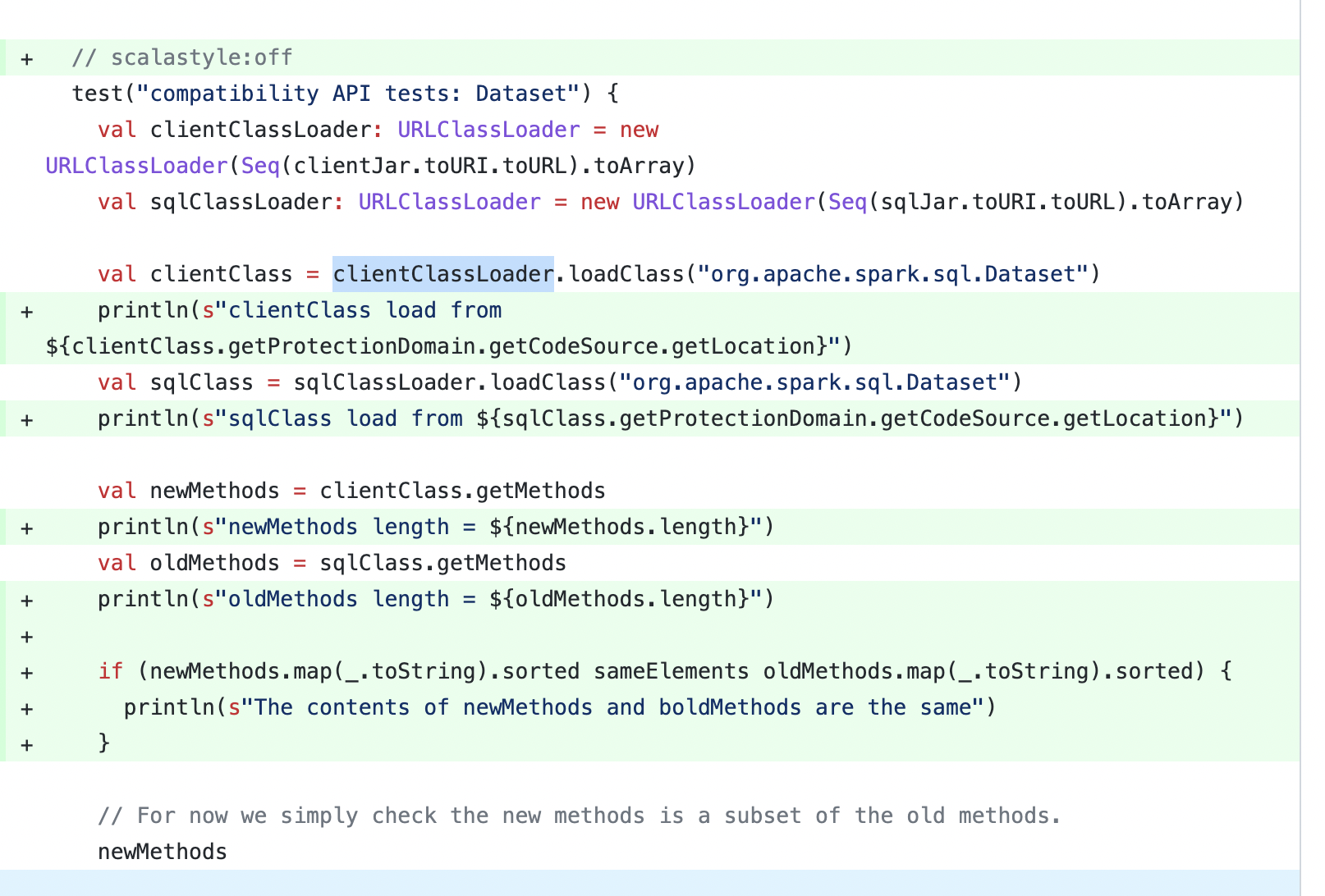
| test("compatibility API tests: Dataset") { | ||
| val clientClassLoader: URLClassLoader = new URLClassLoader(Seq(clientJar.toURI.toURL).toArray) | ||
| val sqlClassLoader: URLClassLoader = new URLClassLoader(Seq(sqlJar.toURI.toURL).toArray) | ||
|
|
||
| val clientClass = clientClassLoader.loadClass("org.apache.spark.sql.Dataset") | ||
|
Contributor
There was a problem hiding this comment. HI ~ @zhenlineo @HyukjinKwon , there may be some problems with this test case, I add some logs as follows:
From the log, I found that both
Contributor
There was a problem hiding this comment. At present, using this way to check, at least 4 apis should be incompatible: Because when using Java reflection, the above 4 methods will be identified as public apis, even though three of them are
Contributor
Author
There was a problem hiding this comment. Thanks so much for looking into this. The dataset test is not as important as Mima test. I will check if we can fix the issue you found. Otherwise it should be safe to delete as the test is already covered by mima.
Contributor
There was a problem hiding this comment. Thanks @zhenlineo, If it has been covered, we can delete it :) |
||
| val sqlClass = sqlClassLoader.loadClass("org.apache.spark.sql.Dataset") | ||
|
|
||
| val newMethods = clientClass.getMethods | ||
| val oldMethods = sqlClass.getMethods | ||
|
|
||
| // For now we simply check the new methods is a subset of the old methods. | ||
| newMethods | ||
| .map(m => m.toString) | ||
| .foreach(method => { | ||
| assert(oldMethods.map(m => m.toString).contains(method)) | ||
| }) | ||
| } | ||
|
|
||
| /** | ||
| * Find all methods that are implemented in the client jar. Once all major methods are | ||
| * implemented we can switch to include all methods under the class using ".*" e.g. | ||
| * "org.apache.spark.sql.Dataset.*" | ||
| */ | ||
| private def includeImplementedMethods(clientJar: File): Seq[IncludeByName] = { | ||
| val clsNames = Seq( | ||
| "org.apache.spark.sql.Column", | ||
| // TODO(SPARK-42175) Add all overloading methods. Temporarily mute compatibility check for \ | ||
| // the Dataset methods, as too many overload methods are missing. | ||
| // "org.apache.spark.sql.Dataset", | ||
| "org.apache.spark.sql.SparkSession") | ||
|
|
||
| val clientClassLoader: URLClassLoader = new URLClassLoader(Seq(clientJar.toURI.toURL).toArray) | ||
| clsNames | ||
| .flatMap { clsName => | ||
| val cls = clientClassLoader.loadClass(clsName) | ||
| // all distinct method names | ||
| cls.getMethods.map(m => s"$clsName.${m.getName}").toSet | ||
| } | ||
| .map { fullName => | ||
| IncludeByName(fullName) | ||
| } | ||
| } | ||
|
|
||
| private case class IncludeByName(name: String) extends ProblemFilter { | ||
| private[this] val pattern = | ||
| Pattern.compile(name.split("\\*", -1).map(Pattern.quote).mkString(".*")) | ||
|
|
||
| override def apply(problem: Problem): Boolean = { | ||
| pattern.matcher(problem.matchName.getOrElse("")).matches | ||
| } | ||
| } | ||
| } | ||

There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
The latest version is 1.1.1
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Yes, there is a bug in 1.1.1, where the MiMa will not be able to check the class methods if the object is marked
private. Thus I used the same one that our SBT build uses, which is 1.1.0.