[SPARK-42172][CONNECT] Scala Client Mima Compatibility Tests #39712
Conversation
|
Can one of the admins verify this patch? |
2ed597b to
8a79ffd
Compare
There was a problem hiding this comment.
https://issues.apache.org/jira/browse/SPARK-42175 This was skipped as I do not want to include too much API impl with the compatibility test PR.
There was a problem hiding this comment.
Let's add this jira id to the TODO, like
TODO(SPARK-42175): Add the Dataset object definition
There was a problem hiding this comment.
Seems like we're not using this Logging
There was a problem hiding this comment.
The logging is needed for the binary compatibility: class type shall be exactly the same.
There was a problem hiding this comment.
should we delete private[sql] here?
There was a problem hiding this comment.
My poor Scala knowledge indicate this only marks one constructor private. The intension is to mark the current constructor private. For more constructor methods, we will add in follow up PRs.
There was a problem hiding this comment.
Hmm....why is it not consistent with spark.sql.Column?
There was a problem hiding this comment.
Our type is proto.Expression, it is not the same as Expression. I leave it to later PRs to decide how to support Expression.
There was a problem hiding this comment.
I mean, why not
class Column(val expr: proto.Expression) extends Logging { ...
There was a problem hiding this comment.
Because I am not certain if we should expose constructor this(expr: proto.Expression) and val expr:proto.Expression.
They are not the same type as this(expr: Expression) and val expr: Expression.
Our type proto.Expression is some grpc class and Expression is in sql package. They are different types from the binary code point of view.
There was a problem hiding this comment.
Let's keep it private[sql] for now.
connector/connect/client/jvm/pom.xml
Outdated
There was a problem hiding this comment.
Can we use SBT to check this instead of Maven? We have one place for MiMa so far in SBT (See also project/MimaBuild.scala, and dev/mima)
There was a problem hiding this comment.
The SBT MiMa check has some limitations to run as a SBT rule:
It is the best for a stable API. e.g. current vs previous. It is not very friendly to configure to test e.g. scala-client vs sql while we are actively working on the scala-client API.
To be more specific, the problems I hit were:
- I cannot configure the MiMa rule to find the current SQL SNAPSHOT jar.
- I cannot use ClassLoader correctly in the SBT rule to load all methods in the client API.
As a result, I end up this test where we have more freedom to grow the API test coverage with the client API.
There was a problem hiding this comment.
Gotya. Let's probably add a couple of comments here and there to make it clear .. I am sure this is confusing to other developers.
There was a problem hiding this comment.
cc @dongjoon-hyun , also cc @pan3793 Do you have any suggestions for this?
There was a problem hiding this comment.
You can check out the MiMa SBT impl I did here: zhenlineo#6
I marked the two problems in the PR code. Unless we can fix the two problems. I do not feel it is a better solution than this PR: calling MiMa directly in a test.
be1954c to
8f30d76
Compare
There was a problem hiding this comment.
Both Column and Column$ are private[sql] access scope with this pr, so this is not an API for users?
Seem users cannot create a Column in their own package with this pr, for example:
package org.apache.spark.test
import org.scalatest.funsuite.AnyFunSuite // scalastyle:ignore funsuite
import org.apache.spark.sql.Column
class MyTestSuite
extends AnyFunSuite // scalastyle:ignore funsuite
{
test("new column") {
val a = Column("a") // Symbol apply is inaccessible from this place
val b = new Column(null) // No constructor accessible from here
}There was a problem hiding this comment.
I think org.apache.spark.sql.Column#apply was a public api before. If private[sql] is added to object Column, it may require more code refactoring work
There was a problem hiding this comment.
Thanks for your inputs.
Looking the current Column class, the SQL API give two public APIs to construct the Column:
class Column(val expr: Expression) extends Logging {
def this(name: String) = this(name match {
case "*" => UnresolvedStar(None)
case _ if name.endsWith(".*") =>
val parts = UnresolvedAttribute.parseAttributeName(name.substring(0, name.length - 2))
UnresolvedStar(Some(parts))
case _ => UnresolvedAttribute.quotedString(name)
})
...
Right now the client API is very far from completion. We will add new methods in coming PRs. I am sure there will be a Column(name: String) for users to use. But it is out the scope of this PR to include all public constructors needed for the client.
The compatibility check added with this PR will grow the check coverage when more and more methods are added in the client. The current check ensures when a new method are added, the new method should be binary compatible with the existing SQL API. When the client API coverage is up (~80%) we can switch to a more aggressive check to ensure we did not miss any methods by mistake.
There was a problem hiding this comment.
OK, I see what you mean. It seems that this is just an intermediate state. So it really doesn't need to consider users' use now.
connector/connect/client/jvm/pom.xml
Outdated
There was a problem hiding this comment.
The latest version is 1.1.1
There was a problem hiding this comment.
Yes, there is a bug in 1.1.1, where the MiMa will not be able to check the class methods if the object is marked private. Thus I used the same one that our SBT build uses, which is 1.1.0.
There was a problem hiding this comment.
Like above TODO, need create a jira and add the corresponding jira id to TODO
|
@zhenlineo Manual test as follows: and test failed |
|
@LuciferYang Thanks so much to look into this PR, I added instructions to run this PR on the top of the test class In short, we need first run |
|
Maven test has some problems: run GA didn't fail because GA didn't test this |
|
@zhenlineo So we need package sql module and connect-client-jvm first, then test? |
|
@LuciferYang yes. As the test compares the binary jars. Let me know if there is some good way to enforce to build the jars first. |
|
local test The test still failed, did I execute the commands incorrectly? Can you give me a correct? |
|
"It worked on my computer." 😂 Did you get the same error? Do you have any jars under the folder |
|
Yes, the same error and the jar package exists:
|

|
Oh, you have to do a global |
|
@LuciferYang I verified the path for SBT and maven again. All are able to run the test successfully. For maven, we can build the two package separately and then run the maven test correctly. The reason your sbt command did not work is that the command I am all up to improve the test flow if you can advise? |
Thanks @zhenlineo when I change But I think this is not friendly to developers, for maven users, the full modules build and test can be through I don't have any good suggestions now, need more time to think about it. cc @srowen @dongjoon-hyun @JoshRosen FYI |
|
@LuciferYang I have another Note to all reviewers: All scala client changes need to be merged into |
|
Let's see what others think :) |
|
I am fine w/ doing it separately. @LuciferYang's suggestion makes a lot of sense to me. |
 HyukjinKwon
left a comment
HyukjinKwon
left a comment
There was a problem hiding this comment.
Approving it but let's make sure to address @LuciferYang's suggestions. I do have the same concern about different way of testing which makes other developers hard to test, validate the change, etc.
|
If we are sure that there will be further work to solve the problem, I have no objection to merge it now, but I must stress again that this merge will make |
|
Hi @LuciferYang, I added the ability to skip the client integration tests with maven: |
|
@LuciferYang Let me know if there is any other blockers to merge this PR. Thanks a lot for the review. |
connector/connect/client/jvm/pom.xml
Outdated
There was a problem hiding this comment.
No need to add this profile, We can use -Dtest.exclude.tags=org.apache.spark.sql.connect.client.util.ClientIntegrationTest directly.
There was a problem hiding this comment.
I did similar work a few days ago:
#39768
The test case CompatibilitySuite was not added at that time, so @dongjoon-hyun suggested not to add this Tag
Need @HyukjinKwon or @dongjoon-hyun for double check for this
There was a problem hiding this comment.
The test Tag should be uniformly added to the tag module(The current naming rule is ExtendedXXX) and please update the pr description to explain why this Tag is added @zhenlineo
There was a problem hiding this comment.
@LuciferYang I've reverted the last commit to skip the e2e tests. As it will not make the build worse (as it doing the same as E2E suite). Let's fix the build issue do it in another PR. We might have better solutions.
| f.getName.startsWith(sbtName) && f.getName.endsWith(".jar")) || | ||
| // Maven Jar | ||
| (f.getParent.endsWith("target") && | ||
| f.getName.startsWith(mvnName) && f.getName.endsWith(".jar")) |
There was a problem hiding this comment.
I fixed a bad case for maven find Jar in #39810
There was a problem hiding this comment.
Thanks for the fix. Added back.
### What changes were proposed in this pull request? The Spark Connect Scala Client should provide the same API as the existing SQL API. This PR adds the tests to ensure the generated binaries of two modules are compatible using MiMa. The covered APIs are: * `Dataset`, * `SparkSession` with all implemented methods, * `Column` with all implemented methods, * `DataFrame` ### Why are the changes needed? Ensures the binary compatibility of the two APIs. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Integration tests. Note: This PR need to be merged into 3.4 too. Closes #39712 from zhenlineo/cp-test. Authored-by: Zhen Li <zhenlineo@users.noreply.github.com> Signed-off-by: Herman van Hovell <herman@databricks.com> (cherry picked from commit 15971a0) Signed-off-by: Herman van Hovell <herman@databricks.com>
| val clientClassLoader: URLClassLoader = new URLClassLoader(Seq(clientJar.toURI.toURL).toArray) | ||
| val sqlClassLoader: URLClassLoader = new URLClassLoader(Seq(sqlJar.toURI.toURL).toArray) | ||
|
|
||
| val clientClass = clientClassLoader.loadClass("org.apache.spark.sql.Dataset") |
There was a problem hiding this comment.
HI ~ @zhenlineo @HyukjinKwon , there may be some problems with this test case, I add some logs as follows:
https://github.com/apache/spark/compare/master...LuciferYang:spark:CompatibilitySuite?expand=1
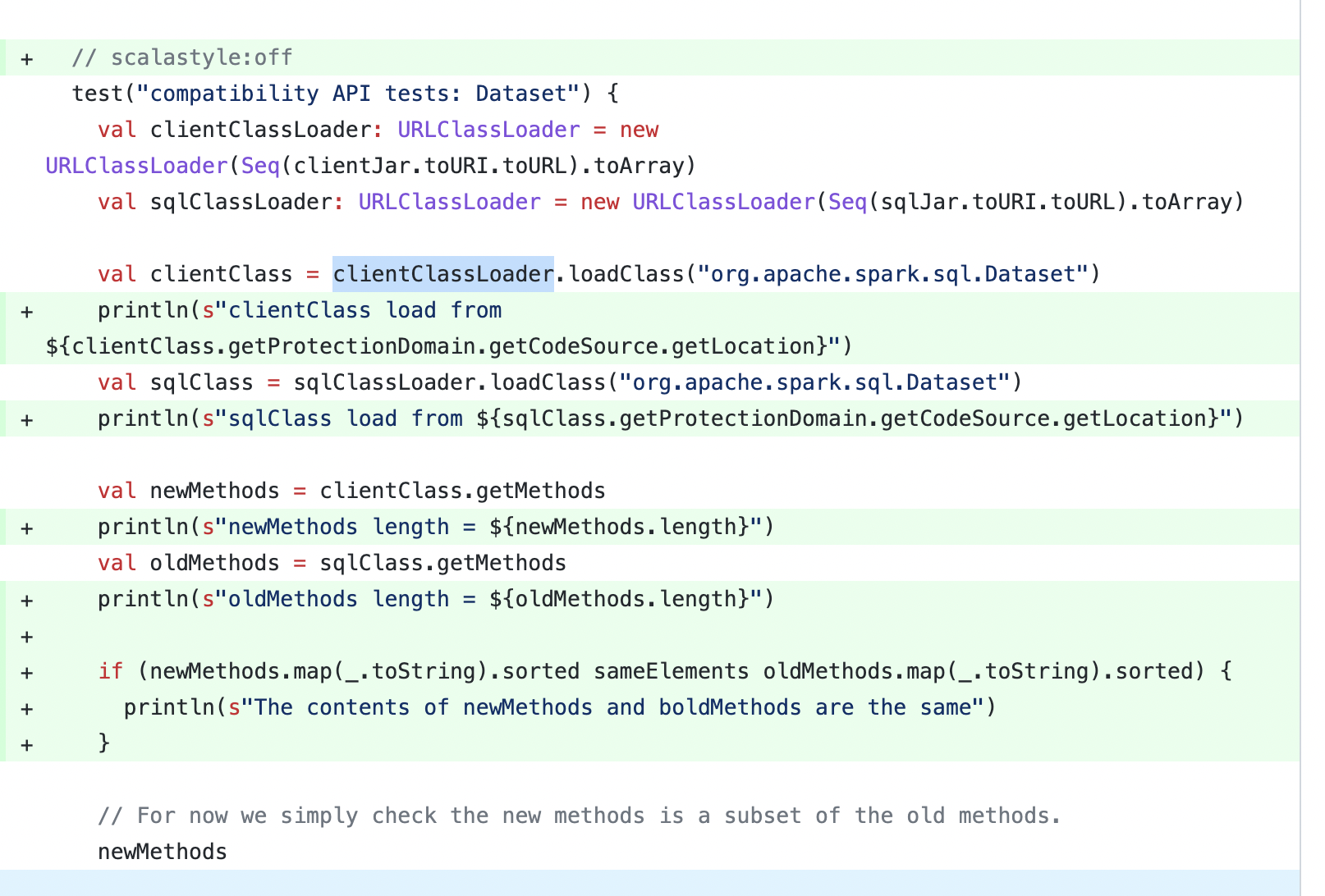
From the log, I found that both clientClass and sqlClass are loaded from file:/home/runner/work/spark/spark/connector/connect/client/jvm/target/scala-2.12/spark-connect-client-jvm_2.12-3.5.0-SNAPSHOT.jar, and the contents of newMethods and oldMethods are the same ...

There was a problem hiding this comment.
At present, using this way to check, at least 4 apis should be incompatible:
private[sql] def withResult[E](f: SparkResult => E): E
def collectResult(): SparkResult
private[sql] def analyze: proto.AnalyzePlanResponse
private[sql] val plan: proto.Plan
Because when using Java reflection, the above 4 methods will be identified as public apis, even though three of them are private [sql], and these four apis do not exist in the Dataset of the sql module:
public java.lang.Object org.apache.spark.sql.Dataset.withResult(scala.Function1)$
public org.apache.spark.sql.connect.client.SparkResult org.apache.spark.sql.Dataset.collectResult()$
public org.apache.spark.connect.proto.AnalyzePlanResponse org.apache.spark.sql.Dataset.analyze()$
public org.apache.spark.connect.proto.Plan org.apache.spark.sql.Dataset.plan()$
There was a problem hiding this comment.
Thanks so much for looking into this. The dataset test is not as important as Mima test. I will check if we can fix the issue you found. Otherwise it should be safe to delete as the test is already covered by mima.
There was a problem hiding this comment.
Thanks @zhenlineo, If it has been covered, we can delete it :)
### What changes were proposed in this pull request? The Spark Connect Scala Client should provide the same API as the existing SQL API. This PR adds the tests to ensure the generated binaries of two modules are compatible using MiMa. The covered APIs are: * `Dataset`, * `SparkSession` with all implemented methods, * `Column` with all implemented methods, * `DataFrame` ### Why are the changes needed? Ensures the binary compatibility of the two APIs. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Integration tests. Note: This PR need to be merged into 3.4 too. Closes apache#39712 from zhenlineo/cp-test. Authored-by: Zhen Li <zhenlineo@users.noreply.github.com> Signed-off-by: Herman van Hovell <herman@databricks.com> (cherry picked from commit 15971a0) Signed-off-by: Herman van Hovell <herman@databricks.com>
What changes were proposed in this pull request?
The Spark Connect Scala Client should provide the same API as the existing SQL API. This PR adds the tests to ensure the generated binaries of two modules are compatible using MiMa.
The covered APIs are:
Dataset,SparkSessionwith all implemented methods,Columnwith all implemented methods,DataFrameWhy are the changes needed?
Ensures the binary compatibility of the two APIs.
Does this PR introduce any user-facing change?
No
How was this patch tested?
Integration tests.
Note: This PR need to be merged into 3.4 too.