[Merged by Bors] - Clean up Fetch code #4800
Conversation
|
Did a quick round of benchmarks. Generally looks to be unchanged, though there are some regressions, particularly with The other thing to point out is the giant speedup in Bar the aforementioned regressions, assuming the benchmarks here are consistent, this seems like a workable change. |
|
I'd consider taking those changes to the performance characteristics as is. Query::get is in the hot path for a lot of things too, and those are awesome improvements. That said, I'm excited to see how your mitigation ideas work. |
|
Attempted to merge the entities and rows into one Vec to make it easier for sparse iteration. It seems to address the sparse iteration issues. |
|
@james7132 are the Todo comments from the PR description addressed now? |
Yep more or less ready now. |
|
@bevyengine/ecs-team reviews please! |
|
Can we do some iter/get/frag_iter benchmarks of larger / more complicated queries? This (potentially) adds a branch to each Fetch impl, instead of branching once for the entire query. These redundant branches might get optimized out, but I intentionally moved that branch out to remove the (logical) O(FETCHED_ITEMS) branches. It will be hard to compare that vs main though, given the other optimizations in this pr. |
|
bors r+ |
# Objective Clean up code surrounding fetch by pulling out the common parts into the iteration code. ## Solution Merge `Fetch::table_fetch` and `Fetch::archetype_fetch` into a single API: `Fetch::fetch(&mut self, entity: &Entity, table_row: &usize)`. This provides everything any fetch requires to internally decide which storage to read from and get the underlying data. All of these functions are marked as `#[inline(always)]` and the arguments are passed as references to attempt to optimize out the argument that isn't being used. External to `Fetch`, Query iteration has been changed to keep track of the table row and entity outside of fetch, which moves a lot of the expensive bookkeeping `Fetch` structs had previously done internally into the outer loop. ~~TODO: Benchmark, docs~~ Done. --- ## Changelog Changed: `Fetch::table_fetch` and `Fetch::archetype_fetch` have been merged into a single `Fetch::fetch` function. ## Migration Guide TODO Co-authored-by: Brian Merchant <bhmerchang@gmail.com> Co-authored-by: Saverio Miroddi <saverio.pub2@gmail.com>
# Objective As a part of evaluating bevyengine#4800, at the behest of @cart, it was noted that the ECS microbenchmarks all focus on singular component queries, whereas in reality most systems will have wider queries with multiple components in each. ## Solution Use const generics to add wider variants of existing benchmarks.
|
Pull request successfully merged into main. Build succeeded:
|
…4927) # Objective Archetype is a deceptively large type in memory. It stores metadata about which components are in which storage in multiple locations, which is only used when creating new Archetypes while moving entities. ## Solution Remove the redundant `Box<[ComponentId]>`s and iterate over the sparse set of component metadata instead. Reduces Archetype's size by 4 usizes (32 bytes on 64-bit systems), as well as the additional allocations for holding these slices. It'd seem like there's a downside that the origin archetype has it's component metadata iterated over twice when creating a new archetype, but this change also removes the extra `Vec<ArchetypeComponentId>` allocations when creating a new archetype which may amortize out to a net gain here. This change likely negatively impacts creating new archetypes with a large number of components, but that's a cost mitigated by the fact that these archetypal relationships are cached in Edges and is incurred only once for each edge created. ## Additional Context There are several other in-flight PRs that shrink Archetype: - #4800 merges the entities and rows Vecs together (shaves off 24 bytes per archetype) - #4809 removes unique_components and moves it to it's own dedicated storage (shaves off 72 bytes per archetype) --- ## Changelog Changed: `Archetype::table_components` and `Archetype::sparse_set_components` return iterators instead of slices. `Archetype::new` requires iterators instead of parallel slices/vecs. ## Migration Guide Do I still need to do this? I really hope people were not relying on the public facing APIs changed here.
…4927) # Objective Archetype is a deceptively large type in memory. It stores metadata about which components are in which storage in multiple locations, which is only used when creating new Archetypes while moving entities. ## Solution Remove the redundant `Box<[ComponentId]>`s and iterate over the sparse set of component metadata instead. Reduces Archetype's size by 4 usizes (32 bytes on 64-bit systems), as well as the additional allocations for holding these slices. It'd seem like there's a downside that the origin archetype has it's component metadata iterated over twice when creating a new archetype, but this change also removes the extra `Vec<ArchetypeComponentId>` allocations when creating a new archetype which may amortize out to a net gain here. This change likely negatively impacts creating new archetypes with a large number of components, but that's a cost mitigated by the fact that these archetypal relationships are cached in Edges and is incurred only once for each edge created. ## Additional Context There are several other in-flight PRs that shrink Archetype: - #4800 merges the entities and rows Vecs together (shaves off 24 bytes per archetype) - #4809 removes unique_components and moves it to it's own dedicated storage (shaves off 72 bytes per archetype) --- ## Changelog Changed: `Archetype::table_components` and `Archetype::sparse_set_components` return iterators instead of slices. `Archetype::new` requires iterators instead of parallel slices/vecs. ## Migration Guide Do I still need to do this? I really hope people were not relying on the public facing APIs changed here.
…evyengine#4927) # Objective Archetype is a deceptively large type in memory. It stores metadata about which components are in which storage in multiple locations, which is only used when creating new Archetypes while moving entities. ## Solution Remove the redundant `Box<[ComponentId]>`s and iterate over the sparse set of component metadata instead. Reduces Archetype's size by 4 usizes (32 bytes on 64-bit systems), as well as the additional allocations for holding these slices. It'd seem like there's a downside that the origin archetype has it's component metadata iterated over twice when creating a new archetype, but this change also removes the extra `Vec<ArchetypeComponentId>` allocations when creating a new archetype which may amortize out to a net gain here. This change likely negatively impacts creating new archetypes with a large number of components, but that's a cost mitigated by the fact that these archetypal relationships are cached in Edges and is incurred only once for each edge created. ## Additional Context There are several other in-flight PRs that shrink Archetype: - bevyengine#4800 merges the entities and rows Vecs together (shaves off 24 bytes per archetype) - bevyengine#4809 removes unique_components and moves it to it's own dedicated storage (shaves off 72 bytes per archetype) --- ## Changelog Changed: `Archetype::table_components` and `Archetype::sparse_set_components` return iterators instead of slices. `Archetype::new` requires iterators instead of parallel slices/vecs. ## Migration Guide Do I still need to do this? I really hope people were not relying on the public facing APIs changed here.
# Objective `Query::get` and other random access methods require looking up `EntityLocation` for every provided entity, then always looking up the `Archetype` to get the table ID and table row. This requires 4 total random fetches from memory: the `Entities` lookup, the `Archetype` lookup, the table row lookup, and the final fetch from table/sparse sets. If `EntityLocation` contains the table ID and table row, only the `Entities` lookup and the final storage fetch are required. ## Solution Add `TableId` and table row to `EntityLocation`. Ensure it's updated whenever entities are moved around. To ensure `EntityMeta` does not grow bigger, both `TableId` and `ArchetypeId` have been shrunk to u32, and the archetype index and table row are stored as u32s instead of as usizes. This should shrink `EntityMeta` by 4 bytes, from 24 to 20 bytes, as there is no padding anymore due to the change in alignment. This idea was partially concocted by @BoxyUwU. ## Performance This should restore the `Query::get` "gains" lost to #6625 that were introduced in #4800 without being unsound, and also incorporates some of the memory usage reductions seen in #3678. This also removes the same lookups during add/remove/spawn commands, so there may be a bit of a speedup in commands and `Entity{Ref,Mut}`. --- ## Changelog Added: `EntityLocation::table_id` Added: `EntityLocation::table_row`. Changed: `World`s can now only hold a maximum of 2<sup>32</sup>- 1 archetypes. Changed: `World`s can now only hold a maximum of 2<sup>32</sup> - 1 tables. ## Migration Guide A `World` can only hold a maximum of 2<sup>32</sup> - 1 archetypes and tables now. If your use case requires more than this, please file an issue explaining your use case.
# Objective Fix #4647. If any child is changed, or even reordered, `Changed<Children>` is true, which causes transform propagation to propagate changes to all siblings of a changed child, even if they don't need to be. ## Solution As `Parent` and `Children` are updated in tandem in hierarchy commands after #4800. `Changed<Parent>` is true on the child when `Changed<Children>` is true on the parent. However, unlike checking children, checking `Changed<Parent>` is only localized to the current entity and will not force propagation to the siblings. Also took the opportunity to change propagation to use `Query::iter_many` instead of repeated `Query::get` calls. Should cut a bit of the overhead out of propagation. This means we won't panic when there isn't a `Parent` on the child, just skip over it. The tests from #4608 still pass, so the change detection here still works just fine under this approach.
…evyengine#4927) # Objective Archetype is a deceptively large type in memory. It stores metadata about which components are in which storage in multiple locations, which is only used when creating new Archetypes while moving entities. ## Solution Remove the redundant `Box<[ComponentId]>`s and iterate over the sparse set of component metadata instead. Reduces Archetype's size by 4 usizes (32 bytes on 64-bit systems), as well as the additional allocations for holding these slices. It'd seem like there's a downside that the origin archetype has it's component metadata iterated over twice when creating a new archetype, but this change also removes the extra `Vec<ArchetypeComponentId>` allocations when creating a new archetype which may amortize out to a net gain here. This change likely negatively impacts creating new archetypes with a large number of components, but that's a cost mitigated by the fact that these archetypal relationships are cached in Edges and is incurred only once for each edge created. ## Additional Context There are several other in-flight PRs that shrink Archetype: - bevyengine#4800 merges the entities and rows Vecs together (shaves off 24 bytes per archetype) - bevyengine#4809 removes unique_components and moves it to it's own dedicated storage (shaves off 72 bytes per archetype) --- ## Changelog Changed: `Archetype::table_components` and `Archetype::sparse_set_components` return iterators instead of slices. `Archetype::new` requires iterators instead of parallel slices/vecs. ## Migration Guide Do I still need to do this? I really hope people were not relying on the public facing APIs changed here.
# Objective `Query::get` and other random access methods require looking up `EntityLocation` for every provided entity, then always looking up the `Archetype` to get the table ID and table row. This requires 4 total random fetches from memory: the `Entities` lookup, the `Archetype` lookup, the table row lookup, and the final fetch from table/sparse sets. If `EntityLocation` contains the table ID and table row, only the `Entities` lookup and the final storage fetch are required. ## Solution Add `TableId` and table row to `EntityLocation`. Ensure it's updated whenever entities are moved around. To ensure `EntityMeta` does not grow bigger, both `TableId` and `ArchetypeId` have been shrunk to u32, and the archetype index and table row are stored as u32s instead of as usizes. This should shrink `EntityMeta` by 4 bytes, from 24 to 20 bytes, as there is no padding anymore due to the change in alignment. This idea was partially concocted by @BoxyUwU. ## Performance This should restore the `Query::get` "gains" lost to bevyengine#6625 that were introduced in bevyengine#4800 without being unsound, and also incorporates some of the memory usage reductions seen in bevyengine#3678. This also removes the same lookups during add/remove/spawn commands, so there may be a bit of a speedup in commands and `Entity{Ref,Mut}`. --- ## Changelog Added: `EntityLocation::table_id` Added: `EntityLocation::table_row`. Changed: `World`s can now only hold a maximum of 2<sup>32</sup>- 1 archetypes. Changed: `World`s can now only hold a maximum of 2<sup>32</sup> - 1 tables. ## Migration Guide A `World` can only hold a maximum of 2<sup>32</sup> - 1 archetypes and tables now. If your use case requires more than this, please file an issue explaining your use case.
…ne#6870) # Objective Fix bevyengine#4647. If any child is changed, or even reordered, `Changed<Children>` is true, which causes transform propagation to propagate changes to all siblings of a changed child, even if they don't need to be. ## Solution As `Parent` and `Children` are updated in tandem in hierarchy commands after bevyengine#4800. `Changed<Parent>` is true on the child when `Changed<Children>` is true on the parent. However, unlike checking children, checking `Changed<Parent>` is only localized to the current entity and will not force propagation to the siblings. Also took the opportunity to change propagation to use `Query::iter_many` instead of repeated `Query::get` calls. Should cut a bit of the overhead out of propagation. This means we won't panic when there isn't a `Parent` on the child, just skip over it. The tests from bevyengine#4608 still pass, so the change detection here still works just fine under this approach.
# Objective As a part of evaluating bevyengine#4800, at the behest of @cart, it was noted that the ECS microbenchmarks all focus on singular component queries, whereas in reality most systems will have wider queries with multiple components in each. ## Solution Use const generics to add wider variants of existing benchmarks.
# Objective Clean up code surrounding fetch by pulling out the common parts into the iteration code. ## Solution Merge `Fetch::table_fetch` and `Fetch::archetype_fetch` into a single API: `Fetch::fetch(&mut self, entity: &Entity, table_row: &usize)`. This provides everything any fetch requires to internally decide which storage to read from and get the underlying data. All of these functions are marked as `#[inline(always)]` and the arguments are passed as references to attempt to optimize out the argument that isn't being used. External to `Fetch`, Query iteration has been changed to keep track of the table row and entity outside of fetch, which moves a lot of the expensive bookkeeping `Fetch` structs had previously done internally into the outer loop. ~~TODO: Benchmark, docs~~ Done. --- ## Changelog Changed: `Fetch::table_fetch` and `Fetch::archetype_fetch` have been merged into a single `Fetch::fetch` function. ## Migration Guide TODO Co-authored-by: Brian Merchant <bhmerchang@gmail.com> Co-authored-by: Saverio Miroddi <saverio.pub2@gmail.com>
…evyengine#4927) # Objective Archetype is a deceptively large type in memory. It stores metadata about which components are in which storage in multiple locations, which is only used when creating new Archetypes while moving entities. ## Solution Remove the redundant `Box<[ComponentId]>`s and iterate over the sparse set of component metadata instead. Reduces Archetype's size by 4 usizes (32 bytes on 64-bit systems), as well as the additional allocations for holding these slices. It'd seem like there's a downside that the origin archetype has it's component metadata iterated over twice when creating a new archetype, but this change also removes the extra `Vec<ArchetypeComponentId>` allocations when creating a new archetype which may amortize out to a net gain here. This change likely negatively impacts creating new archetypes with a large number of components, but that's a cost mitigated by the fact that these archetypal relationships are cached in Edges and is incurred only once for each edge created. ## Additional Context There are several other in-flight PRs that shrink Archetype: - bevyengine#4800 merges the entities and rows Vecs together (shaves off 24 bytes per archetype) - bevyengine#4809 removes unique_components and moves it to it's own dedicated storage (shaves off 72 bytes per archetype) --- ## Changelog Changed: `Archetype::table_components` and `Archetype::sparse_set_components` return iterators instead of slices. `Archetype::new` requires iterators instead of parallel slices/vecs. ## Migration Guide Do I still need to do this? I really hope people were not relying on the public facing APIs changed here.
# Objective `Query::get` and other random access methods require looking up `EntityLocation` for every provided entity, then always looking up the `Archetype` to get the table ID and table row. This requires 4 total random fetches from memory: the `Entities` lookup, the `Archetype` lookup, the table row lookup, and the final fetch from table/sparse sets. If `EntityLocation` contains the table ID and table row, only the `Entities` lookup and the final storage fetch are required. ## Solution Add `TableId` and table row to `EntityLocation`. Ensure it's updated whenever entities are moved around. To ensure `EntityMeta` does not grow bigger, both `TableId` and `ArchetypeId` have been shrunk to u32, and the archetype index and table row are stored as u32s instead of as usizes. This should shrink `EntityMeta` by 4 bytes, from 24 to 20 bytes, as there is no padding anymore due to the change in alignment. This idea was partially concocted by @BoxyUwU. ## Performance This should restore the `Query::get` "gains" lost to bevyengine#6625 that were introduced in bevyengine#4800 without being unsound, and also incorporates some of the memory usage reductions seen in bevyengine#3678. This also removes the same lookups during add/remove/spawn commands, so there may be a bit of a speedup in commands and `Entity{Ref,Mut}`. --- ## Changelog Added: `EntityLocation::table_id` Added: `EntityLocation::table_row`. Changed: `World`s can now only hold a maximum of 2<sup>32</sup>- 1 archetypes. Changed: `World`s can now only hold a maximum of 2<sup>32</sup> - 1 tables. ## Migration Guide A `World` can only hold a maximum of 2<sup>32</sup> - 1 archetypes and tables now. If your use case requires more than this, please file an issue explaining your use case.
…ne#6870) # Objective Fix bevyengine#4647. If any child is changed, or even reordered, `Changed<Children>` is true, which causes transform propagation to propagate changes to all siblings of a changed child, even if they don't need to be. ## Solution As `Parent` and `Children` are updated in tandem in hierarchy commands after bevyengine#4800. `Changed<Parent>` is true on the child when `Changed<Children>` is true on the parent. However, unlike checking children, checking `Changed<Parent>` is only localized to the current entity and will not force propagation to the siblings. Also took the opportunity to change propagation to use `Query::iter_many` instead of repeated `Query::get` calls. Should cut a bit of the overhead out of propagation. This means we won't panic when there isn't a `Parent` on the child, just skip over it. The tests from bevyengine#4608 still pass, so the change detection here still works just fine under this approach.
commit a85b740f242cb0a239082fcfb8c1eceb23a266df
Author: James Liu <contact@jamessliu.com>
Date: Sun Jan 22 00:21:55 2023 +0000
Support recording multiple CommandBuffers in RenderContext (#7248)
# Objective
`RenderContext`, the core abstraction for running the render graph, currently only supports recording one `CommandBuffer` across the entire render graph. This means the entire buffer must be recorded sequentially, usually via the render graph itself. This prevents parallelization and forces users to only encode their commands in the render graph.
## Solution
Allow `RenderContext` to store a `Vec<CommandBuffer>` that it progressively appends to. By default, the context will not have a command encoder, but will create one as soon as either `begin_tracked_render_pass` or the `command_encoder` accesor is first called. `RenderContext::add_command_buffer` allows users to interrupt the current command encoder, flush it to the vec, append a user-provided `CommandBuffer` and reset the command encoder to start a new buffer. Users or the render graph will call `RenderContext::finish` to retrieve the series of buffers for submitting to the queue.
This allows users to encode their own `CommandBuffer`s outside of the render graph, potentially in different threads, and store them in components or resources.
Ideally, in the future, the core pipeline passes can run in `RenderStage::Render` systems and end up saving the completed command buffers to either `Commands` or a field in `RenderPhase`.
## Alternatives
The alternative is to use to use wgpu's `RenderBundle`s, which can achieve similar results; however it's not universally available (no OpenGL, WebGL, and DX11).
---
## Changelog
Added: `RenderContext::new`
Added: `RenderContext::add_command_buffer`
Added: `RenderContext::finish`
Changed: `RenderContext::render_device` is now private. Use the accessor `RenderContext::render_device()` instead.
Changed: `RenderContext::command_encoder` is now private. Use the accessor `RenderContext::command_encoder()` instead.
Changed: `RenderContext` now supports adding external `CommandBuffer`s for inclusion into the render graphs. These buffers can be encoded outside of the render graph (i.e. in a system).
## Migration Guide
`RenderContext`'s fields are now private. Use the accessors on `RenderContext` instead, and construct it with `RenderContext::new`.
commit 603cb439d9ec9eba62de3493eb0a2553d25a7c55
Author: Marco Buono <thecoreh@gmail.com>
Date: Sat Jan 21 21:46:53 2023 +0000
Standard Material Blend Modes (#6644)
# Objective
- This PR adds support for blend modes to the PBR `StandardMaterial`.
<img width="1392" alt="Screenshot 2022-11-18 at 20 00 56" src="https://user-images.githubusercontent.com/418473/202820627-0636219a-a1e5-437a-b08b-b08c6856bf9c.png">
<img width="1392" alt="Screenshot 2022-11-18 at 20 01 01" src="https://user-images.githubusercontent.com/418473/202820615-c8d43301-9a57-49c4-bd21-4ae343c3e9ec.png">
## Solution
- The existing `AlphaMode` enum is extended, adding three more modes: `AlphaMode::Premultiplied`, `AlphaMode::Add` and `AlphaMode::Multiply`;
- All new modes are rendered in the existing `Transparent3d` phase;
- The existing mesh flags for alpha mode are reorganized for a more compact/efficient representation, and new values are added;
- `MeshPipelineKey::TRANSPARENT_MAIN_PASS` is refactored into `MeshPipelineKey::BLEND_BITS`.
- `AlphaMode::Opaque` and `AlphaMode::Mask(f32)` share a single opaque pipeline key: `MeshPipelineKey::BLEND_OPAQUE`;
- `Blend`, `Premultiplied` and `Add` share a single premultiplied alpha pipeline key, `MeshPipelineKey::BLEND_PREMULTIPLIED_ALPHA`. In the shader, color values are premultiplied accordingly (or not) depending on the blend mode to produce the three different results after PBR/tone mapping/dithering;
- `Multiply` uses its own independent pipeline key, `MeshPipelineKey::BLEND_MULTIPLY`;
- Example and documentation are provided.
---
## Changelog
### Added
- Added support for additive and multiplicative blend modes in the PBR `StandardMaterial`, via `AlphaMode::Add` and `AlphaMode::Multiply`;
- Added support for premultiplied alpha in the PBR `StandardMaterial`, via `AlphaMode::Premultiplied`;
commit ff5e4fd1ec27ce4b6d4ad9f02562d889a4f4a7fe
Author: targrub <targrub@gmail.com>
Date: Sat Jan 21 17:55:39 2023 +0000
Use `Time` `resource` instead of `Extract`ing `Time` (#7316)
# Objective
- "Fixes #7308".
## Solution
- Use the `Time` `Resource` instead of `Extract<Res<Time>>`
commit cb4e8c832c0ee33ea0b28a6f79971955643055fb
Author: Boxy <supbscripter@gmail.com>
Date: Sat Jan 21 00:55:23 2023 +0000
Update milestone section in `contributing.md` (#7213)
Current info is not up to date as we are now using a train release model and frequently end up with PRs and issues in the milestone that are not resolved before release. As the release milestone is now mostly used for prioritizing what work gets done I updated this section to be about prioritizing PRs/issues instead of preparing releases.
commit cef56a0d4782f50daef32d6c21d140510afe26d3
Author: Molot2032 <117271367+Molot2032@users.noreply.github.com>
Date: Sat Jan 21 00:17:11 2023 +0000
Allow users of Text/TextBundle to choose from glyph_brush_layout's BuiltInLineBreaker options. (#7283)
# Objective
Currently, Text always uses the default linebreaking behaviour in glyph_brush_layout `BuiltInLineBreaker::Unicode` which breaks lines at word boundaries. However, glyph_brush_layout also supports breaking lines at any character by setting the linebreaker to `BuiltInLineBreaker::AnyChar`. Having text wrap character-by-character instead of at word boundaries is desirable in some cases - consider that consoles/terminals usually wrap this way.
As a side note, the default Unicode linebreaker does not seem to handle emergency cases, where there is no word boundary on a line to break at. In that case, the text runs out of bounds. Issue #1867 shows an example of this.
## Solution
Basically just copies how TextAlignment is exposed, but for a new enum TextLineBreakBehaviour.
This PR exposes glyph_brush_layout's two simple linebreaking options (Unicode, AnyChar) to users of Text via the enum TextLineBreakBehaviour (which just translates those 2 aforementioned options), plus a method 'with_linebreak_behaviour' on Text and TextBundle.
## Changelog
Added `Text::with_linebreak_behaviour`
Added `TextBundle::with_linebreak_behaviour`
`TextPipeline::queue_text` and `GlyphBrush::compute_glyphs` now need a TextLineBreakBehaviour argument, in order to pass through the new field.
Modified the `text2d` example to show both linebreaking behaviours.
## Example
Here's what the modified example looks like

commit a94830f0c9627a58fb1fff858b230444848ce677
Author: François <mockersf@gmail.com>
Date: Sat Jan 21 00:01:28 2023 +0000
break feedback loop when moving cursor (#7298)
# Objective
- Fixes #7294
## Solution
- Do not trigger change detection when setting the cursor position from winit
When moving the cursor continuously, Winit sends events:
- CursorMoved(0)
- CursorMoved(1)
- => start of Bevy schedule execution
- CursorMoved(2)
- CursorMoved(3)
- <= End of Bevy schedule execution
if Bevy schedule runs after the event 1, events 2 and 3 would happen during the execution but would be read only on the next system run. During the execution, the system would detect a change on cursor position, and send back an order to winit to move it back to 1, so event 2 and 3 would be ignored. By bypassing change detection when setting the cursor from winit event, it doesn't trigger sending back that change to winit out of order.
commit 1be3b6d59294e02cd8608451e565720417aa8637
Author: IceSentry <c.giguere42@gmail.com>
Date: Fri Jan 20 23:10:37 2023 +0000
fix shader_instancing (#7305)
# Objective
- The changes to the MeshPipeline done for the prepass broke the shader_instancing example. The issue is that the view_layout changes based on if MSAA is enabled or not, but the example hardcoded the view_layout.
## Solution
- Don't overwrite the bind_group_layout of the descriptor since the MeshPipeline already takes care of this in the specialize function.
Closes https://github.com/bevyengine/bevy/issues/7285
commit eda3ffb0af66d9af3bebb7427841e75939b4d5b8
Author: Jonah Henriksson <33059163+JonahPlusPlus@users.noreply.github.com>
Date: Fri Jan 20 19:08:04 2023 +0000
Added `resource_id` and changed `init_resource` and `init_non_send_resource` to return `ComponentId` (#7284)
# Objective
- `Components::resource_id` doesn't exist. Like `Components::component_id` but for resources.
## Solution
- Created `Components::resource_id` and added some docs.
---
## Changelog
- Added `Components::resource_id`.
- Changed `World::init_resource` to return the generated `ComponentId`.
- Changed `World::init_non_send_resource` to return the generated `ComponentId`.
commit 02637b609e8c9371e8f8b54deae5ee8594fb76c1
Author: Jakob Hellermann <jakob.hellermann@protonmail.com>
Date: Fri Jan 20 14:25:25 2023 +0000
fix clippy (#7302)
# Objective
- `cargo clippy` should work (except for clippy::type_complexity)
## Solution
- fix new clippy lints
commit 0804136dcd10c8bfdf7a1099a3a0cb72f6ce2059
Author: François <mockersf@gmail.com>
Date: Fri Jan 20 14:25:24 2023 +0000
expose cursor position with scale (#7297)
# Objective
- Fixes #7288
- Do not expose access directly to cursor position as it is the physical position, ignoring scale
## Solution
- Make cursor position private
- Expose getter/setter on the window to have access to the scale
commit efa2c6edadb598b67015500ae933bc792962379b
Author: François <mockersf@gmail.com>
Date: Fri Jan 20 14:25:23 2023 +0000
revert stage changed for window closing (#7296)
# Objective
- Fix #7287
## Solution
- Revert stage changed in windows as entities PR for window closing systems
how it was before:
https://github.com/bevyengine/bevy/blob/f0c504947ce653068a424979faf226c1e990818d/crates/bevy_window/src/lib.rs#L92-L100
commit 06ada2e93decba7d1df1b12503655773ab6136f4
Author: Sjael <nathanielcasey2552@gmail.com>
Date: Fri Jan 20 14:25:21 2023 +0000
Changed Msaa to Enum (#7292)
# Objective
Fixes #6931
Continues #6954 by squashing `Msaa` to a flat enum
Helps out #7215
# Solution
```
pub enum Msaa {
Off = 1,
#[default]
Sample4 = 4,
}
```
# Changelog
- Modified
- `Msaa` is now enum
- Defaults to 4 samples
- Uses `.samples()` method to get the sample number as `u32`
# Migration Guide
```
let multi = Msaa { samples: 4 }
// is now
let multi = Msaa::Sample4
multi.samples
// is now
multi.samples()
```
Co-authored-by: Sjael <jakeobrien44@gmail.com>
commit 5d5a50468535ada3d504cc5f15c66c080a86cda7
Author: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Date: Fri Jan 20 13:39:23 2023 +0000
Revise `SystemParam` docs (#7274)
# Objective
Increase clarity in a few places for the `SystemParam` docs.
commit f024bce2b8f59f212435cdfc3d8dd6a91743492b
Author: Pascal Hertleif <pascal@technocreatives.com>
Date: Fri Jan 20 13:20:28 2023 +0000
Demand newer async-channel version (#7301)
After #6503, bevy_render uses the `send_blocking` method introduced in async-channel 1.7, but depended only on ^1.4.
I saw this after pulling main without running cargo update.
# Objective
- Fix minimum dependency version of async-channel
## Solution
- Bump async-channel version constraint to ^1.8, which is currently the latest version.
NOTE: Both bevy_ecs and bevy_tasks also depend on async-channel but they didn't use any newer features.
commit dfea88c64d6ac96c73cf1d6e200ea507fb6b4477
Author: James Liu <contact@jamessliu.com>
Date: Fri Jan 20 08:47:20 2023 +0000
Basic adaptive batching for parallel query iteration (#4777)
# Objective
Fixes #3184. Fixes #6640. Fixes #4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
commit cab065bad4302e4df427ffbafcdb112e755321ce
Author: ickshonpe <david.curthoys@googlemail.com>
Date: Fri Jan 20 01:05:30 2023 +0000
remove the image loaded check for nodes without images in extract_uinodes (#7280)
## Problem
`extract_uinodes` checks if an image is loaded for nodes without images
## Solution
Move the image loading skip check so that it is only performed for nodes with a `UiImage` component.
commit 2027af4c54082007fed2091f112a11cb0bc5fc08
Author: Mike <mike.hsu@gmail.com>
Date: Thu Jan 19 23:45:46 2023 +0000
Pipelined Rendering (#6503)
# Objective
- Implement pipelined rendering
- Fixes #5082
- Fixes #4718
## User Facing Description
Bevy now implements piplelined rendering! Pipelined rendering allows the app logic and rendering logic to run on different threads leading to large gains in performance.

*tracy capture of many_foxes example*
To use pipelined rendering, you just need to add the `PipelinedRenderingPlugin`. If you're using `DefaultPlugins` then it will automatically be added for you on all platforms except wasm. Bevy does not currently support multithreading on wasm which is needed for this feature to work. If you aren't using `DefaultPlugins` you can add the plugin manually.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new()
// whatever other plugins you need
.add_plugin(RenderPlugin)
// needs to be added after RenderPlugin
.add_plugin(PipelinedRenderingPlugin)
.run();
}
```
If for some reason pipelined rendering needs to be removed. You can also disable the plugin the normal way.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new.add_plugins(DefaultPlugins.build().disable::<PipelinedRenderingPlugin>());
}
```
### A setup function was added to plugins
A optional plugin lifecycle function was added to the `Plugin trait`. This function is called after all plugins have been built, but before the app runner is called. This allows for some final setup to be done. In the case of pipelined rendering, the function removes the sub app from the main app and sends it to the render thread.
```rust
struct MyPlugin;
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
}
// optional function
fn setup(&self, app: &mut App) {
// do some final setup before runner is called
}
}
```
### A Stage for Frame Pacing
In the `RenderExtractApp` there is a stage labelled `BeforeIoAfterRenderStart` that systems can be added to. The specific use case for this stage is for a frame pacing system that can delay the start of main app processing in render bound apps to reduce input latency i.e. "frame pacing". This is not currently built into bevy, but exists as `bevy`
```text
|-------------------------------------------------------------------|
| | BeforeIoAfterRenderStart | winit events | main schedule |
| extract |---------------------------------------------------------|
| | extract commands | rendering schedule |
|-------------------------------------------------------------------|
```
### Small API additions
* `Schedule::remove_stage`
* `App::insert_sub_app`
* `App::remove_sub_app`
* `TaskPool::scope_with_executor`
## Problems and Solutions
### Moving render app to another thread
Most of the hard bits for this were done with the render redo. This PR just sends the render app back and forth through channels which seems to work ok. I originally experimented with using a scope to run the render task. It was cuter, but that approach didn't allow render to start before i/o processing. So I switched to using channels. There is much complexity in the coordination that needs to be done, but it's worth it. By moving rendering during i/o processing the frame times should be much more consistent in render bound apps. See https://github.com/bevyengine/bevy/issues/4691.
### Unsoundness with Sending World with NonSend resources
Dropping !Send things on threads other than the thread they were spawned on is considered unsound. The render world doesn't have any nonsend resources. So if we tell the users to "pretty please don't spawn nonsend resource on the render world", we can avoid this problem.
More seriously there is this https://github.com/bevyengine/bevy/pull/6534 pr, which patches the unsoundness by aborting the app if a nonsend resource is dropped on the wrong thread. ~~That PR should probably be merged before this one.~~ For a longer term solution we have this discussion going https://github.com/bevyengine/bevy/discussions/6552.
### NonSend Systems in render world
The render world doesn't have any !Send resources, but it does have a non send system. While Window is Send, winit does have some API's that can only be accessed on the main thread. `prepare_windows` in the render schedule thus needs to be scheduled on the main thread. Currently we run nonsend systems by running them on the thread the TaskPool::scope runs on. When we move render to another thread this no longer works.
To fix this, a new `scope_with_executor` method was added that takes a optional `TheadExecutor` that can only be ticked on the thread it was initialized on. The render world then holds a `MainThreadExecutor` resource which can be passed to the scope in the parallel executor that it uses to spawn it's non send systems on.
### Scopes executors between render and main should not share tasks
Since the render world and the app world share the `ComputeTaskPool`. Because `scope` has executors for the ComputeTaskPool a system from the main world could run on the render thread or a render system could run on the main thread. This can cause performance problems because it can delay a stage from finishing. See https://github.com/bevyengine/bevy/pull/6503#issuecomment-1309791442 for more details.
To avoid this problem, `TaskPool::scope` has been changed to not tick the ComputeTaskPool when it's used by the parallel executor. In the future when we move closer to the 1 thread to 1 logical core model we may want to overprovide threads, because the render and main app threads don't do much when executing the schedule.
## Performance
My machine is Windows 11, AMD Ryzen 5600x, RX 6600
### Examples
#### This PR with pipelining vs Main
> Note that these were run on an older version of main and the performance profile has probably changed due to optimizations
Seeing a perf gain from 29% on many lights to 7% on many sprites.
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | 27.01% | 27.34% | -47.09% | 1.58 | 1.55 | -1.78 | 5.85 | 5.67 | 3.78 | 4.27 | 4.12 | 5.56
many lights | 29.35% | 29.94% | -10.84% | 3.02 | 3.03 | -0.57 | 10.29 | 10.12 | 5.26 | 7.27 | 7.09 | 5.83
many animated sprites | 13.97% | 15.69% | 14.20% | 3.79 | 4.17 | 1.41 | 27.12 | 26.57 | 9.93 | 23.33 | 22.4 | 8.52
3d scene | 25.79% | 26.78% | 7.46% | 0.49 | 0.49 | 0.15 | 1.9 | 1.83 | 2.01 | 1.41 | 1.34 | 1.86
many cubes | 11.97% | 11.28% | 14.51% | 1.93 | 1.78 | 1.31 | 16.13 | 15.78 | 9.03 | 14.2 | 14 | 7.72
many sprites | 7.14% | 9.42% | -85.42% | 1.72 | 2.23 | -6.15 | 24.09 | 23.68 | 7.2 | 22.37 | 21.45 | 13.35
<!--EndFragment-->
</body>
</html>
#### This PR with pipelining disabled vs Main
Mostly regressions here. I don't think this should be a problem as users that are disabling pipelined rendering are probably running single threaded and not using the parallel executor. The regression is probably mostly due to the switch to use `async_executor::run` instead of `try_tick` and also having one less thread to run systems on. I'll do a writeup on why switching to `run` causes regressions, so we can try to eventually fix it. Using try_tick causes issues when pipeline rendering is enable as seen [here](https://github.com/bevyengine/bevy/pull/6503#issuecomment-1380803518)
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR no pipelining | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | -3.72% | -4.42% | -1.07% | -0.21 | -0.24 | -0.04 | 5.64 | 5.43 | 3.74 | 5.85 | 5.67 | 3.78
many lights | 0.29% | -0.30% | 4.75% | 0.03 | -0.03 | 0.25 | 10.29 | 10.12 | 5.26 | 10.26 | 10.15 | 5.01
many animated sprites | 0.22% | 1.81% | -2.72% | 0.06 | 0.48 | -0.27 | 27.12 | 26.57 | 9.93 | 27.06 | 26.09 | 10.2
3d scene | -15.79% | -14.75% | -31.34% | -0.3 | -0.27 | -0.63 | 1.9 | 1.83 | 2.01 | 2.2 | 2.1 | 2.64
many cubes | -2.85% | -3.30% | 0.00% | -0.46 | -0.52 | 0 | 16.13 | 15.78 | 9.03 | 16.59 | 16.3 | 9.03
many sprites | 2.49% | 2.41% | 0.69% | 0.6 | 0.57 | 0.05 | 24.09 | 23.68 | 7.2 | 23.49 | 23.11 | 7.15
<!--EndFragment-->
</body>
</html>
### Benchmarks
Mostly the same except empty_systems has got a touch slower. The maybe_pipelining+1 column has the compute task pool with an extra thread over default added. This is because pipelining loses one thread over main to execute systems on, since the main thread no longer runs normal systems.
<details>
<summary>Click Me</summary>
```text
group main maybe-pipelining+1
----- ------------------------- ------------------
busy_systems/01x_entities_03_systems 1.07 30.7±1.32µs ? ?/sec 1.00 28.6±1.35µs ? ?/sec
busy_systems/01x_entities_06_systems 1.10 52.1±1.10µs ? ?/sec 1.00 47.2±1.08µs ? ?/sec
busy_systems/01x_entities_09_systems 1.00 74.6±1.36µs ? ?/sec 1.00 75.0±1.93µs ? ?/sec
busy_systems/01x_entities_12_systems 1.03 100.6±6.68µs ? ?/sec 1.00 98.0±1.46µs ? ?/sec
busy_systems/01x_entities_15_systems 1.11 128.5±3.53µs ? ?/sec 1.00 115.5±1.02µs ? ?/sec
busy_systems/02x_entities_03_systems 1.16 50.4±2.56µs ? ?/sec 1.00 43.5±3.00µs ? ?/sec
busy_systems/02x_entities_06_systems 1.00 87.1±1.27µs ? ?/sec 1.05 91.5±7.15µs ? ?/sec
busy_systems/02x_entities_09_systems 1.04 139.9±6.37µs ? ?/sec 1.00 134.0±1.06µs ? ?/sec
busy_systems/02x_entities_12_systems 1.05 179.2±3.47µs ? ?/sec 1.00 170.1±3.17µs ? ?/sec
busy_systems/02x_entities_15_systems 1.01 219.6±3.75µs ? ?/sec 1.00 218.1±2.55µs ? ?/sec
busy_systems/03x_entities_03_systems 1.10 70.6±2.33µs ? ?/sec 1.00 64.3±0.69µs ? ?/sec
busy_systems/03x_entities_06_systems 1.02 130.2±3.11µs ? ?/sec 1.00 128.0±1.34µs ? ?/sec
busy_systems/03x_entities_09_systems 1.00 195.0±10.11µs ? ?/sec 1.00 194.8±1.41µs ? ?/sec
busy_systems/03x_entities_12_systems 1.01 261.7±4.05µs ? ?/sec 1.00 259.8±4.11µs ? ?/sec
busy_systems/03x_entities_15_systems 1.00 318.0±3.04µs ? ?/sec 1.06 338.3±20.25µs ? ?/sec
busy_systems/04x_entities_03_systems 1.00 82.9±0.63µs ? ?/sec 1.02 84.3±0.63µs ? ?/sec
busy_systems/04x_entities_06_systems 1.01 181.7±3.65µs ? ?/sec 1.00 179.8±1.76µs ? ?/sec
busy_systems/04x_entities_09_systems 1.04 265.0±4.68µs ? ?/sec 1.00 255.3±1.98µs ? ?/sec
busy_systems/04x_entities_12_systems 1.00 335.9±3.00µs ? ?/sec 1.05 352.6±15.84µs ? ?/sec
busy_systems/04x_entities_15_systems 1.00 418.6±10.26µs ? ?/sec 1.08 450.2±39.58µs ? ?/sec
busy_systems/05x_entities_03_systems 1.07 114.3±0.95µs ? ?/sec 1.00 106.9±1.52µs ? ?/sec
busy_systems/05x_entities_06_systems 1.08 229.8±2.90µs ? ?/sec 1.00 212.3±4.18µs ? ?/sec
busy_systems/05x_entities_09_systems 1.03 329.3±1.99µs ? ?/sec 1.00 319.2±2.43µs ? ?/sec
busy_systems/05x_entities_12_systems 1.06 454.7±6.77µs ? ?/sec 1.00 430.1±3.58µs ? ?/sec
busy_systems/05x_entities_15_systems 1.03 554.6±6.15µs ? ?/sec 1.00 538.4±23.87µs ? ?/sec
contrived/01x_entities_03_systems 1.00 14.0±0.15µs ? ?/sec 1.08 15.1±0.21µs ? ?/sec
contrived/01x_entities_06_systems 1.04 28.5±0.37µs ? ?/sec 1.00 27.4±0.44µs ? ?/sec
contrived/01x_entities_09_systems 1.00 41.5±4.38µs ? ?/sec 1.02 42.2±2.24µs ? ?/sec
contrived/01x_entities_12_systems 1.06 55.9±1.49µs ? ?/sec 1.00 52.6±1.36µs ? ?/sec
contrived/01x_entities_15_systems 1.02 68.0±2.00µs ? ?/sec 1.00 66.5±0.78µs ? ?/sec
contrived/02x_entities_03_systems 1.03 25.2±0.38µs ? ?/sec 1.00 24.6±0.52µs ? ?/sec
contrived/02x_entities_06_systems 1.00 46.3±0.49µs ? ?/sec 1.04 48.1±4.13µs ? ?/sec
contrived/02x_entities_09_systems 1.02 70.4±0.99µs ? ?/sec 1.00 68.8±1.04µs ? ?/sec
contrived/02x_entities_12_systems 1.06 96.8±1.49µs ? ?/sec 1.00 91.5±0.93µs ? ?/sec
contrived/02x_entities_15_systems 1.02 116.2±0.95µs ? ?/sec 1.00 114.2±1.42µs ? ?/sec
contrived/03x_entities_03_systems 1.00 33.2±0.38µs ? ?/sec 1.01 33.6±0.45µs ? ?/sec
contrived/03x_entities_06_systems 1.00 62.4±0.73µs ? ?/sec 1.01 63.3±1.05µs ? ?/sec
contrived/03x_entities_09_systems 1.02 96.4±0.85µs ? ?/sec 1.00 94.8±3.02µs ? ?/sec
contrived/03x_entities_12_systems 1.01 126.3±4.67µs ? ?/sec 1.00 125.6±2.27µs ? ?/sec
contrived/03x_entities_15_systems 1.03 160.2±9.37µs ? ?/sec 1.00 156.0±1.53µs ? ?/sec
contrived/04x_entities_03_systems 1.02 41.4±3.39µs ? ?/sec 1.00 40.5±0.52µs ? ?/sec
contrived/04x_entities_06_systems 1.00 78.9±1.61µs ? ?/sec 1.02 80.3±1.06µs ? ?/sec
contrived/04x_entities_09_systems 1.02 121.8±3.97µs ? ?/sec 1.00 119.2±1.46µs ? ?/sec
contrived/04x_entities_12_systems 1.00 157.8±1.48µs ? ?/sec 1.01 160.1±1.72µs ? ?/sec
contrived/04x_entities_15_systems 1.00 197.9±1.47µs ? ?/sec 1.08 214.2±34.61µs ? ?/sec
contrived/05x_entities_03_systems 1.00 49.1±0.33µs ? ?/sec 1.01 49.7±0.75µs ? ?/sec
contrived/05x_entities_06_systems 1.00 95.0±0.93µs ? ?/sec 1.00 94.6±0.94µs ? ?/sec
contrived/05x_entities_09_systems 1.01 143.2±1.68µs ? ?/sec 1.00 142.2±2.00µs ? ?/sec
contrived/05x_entities_12_systems 1.00 191.8±2.03µs ? ?/sec 1.01 192.7±7.88µs ? ?/sec
contrived/05x_entities_15_systems 1.02 239.7±3.71µs ? ?/sec 1.00 235.8±4.11µs ? ?/sec
empty_systems/000_systems 1.01 47.8±0.67ns ? ?/sec 1.00 47.5±2.02ns ? ?/sec
empty_systems/001_systems 1.00 1743.2±126.14ns ? ?/sec 1.01 1761.1±70.10ns ? ?/sec
empty_systems/002_systems 1.01 2.2±0.04µs ? ?/sec 1.00 2.2±0.02µs ? ?/sec
empty_systems/003_systems 1.02 2.7±0.09µs ? ?/sec 1.00 2.7±0.16µs ? ?/sec
empty_systems/004_systems 1.00 3.1±0.11µs ? ?/sec 1.00 3.1±0.24µs ? ?/sec
empty_systems/005_systems 1.00 3.5±0.05µs ? ?/sec 1.11 3.9±0.70µs ? ?/sec
empty_systems/010_systems 1.00 5.5±0.12µs ? ?/sec 1.03 5.7±0.17µs ? ?/sec
empty_systems/015_systems 1.00 7.9±0.19µs ? ?/sec 1.06 8.4±0.16µs ? ?/sec
empty_systems/020_systems 1.00 10.4±1.25µs ? ?/sec 1.02 10.6±0.18µs ? ?/sec
empty_systems/025_systems 1.00 12.4±0.39µs ? ?/sec 1.14 14.1±1.07µs ? ?/sec
empty_systems/030_systems 1.00 15.1±0.39µs ? ?/sec 1.05 15.8±0.62µs ? ?/sec
empty_systems/035_systems 1.00 16.9±0.47µs ? ?/sec 1.07 18.0±0.37µs ? ?/sec
empty_systems/040_systems 1.00 19.3±0.41µs ? ?/sec 1.05 20.3±0.39µs ? ?/sec
empty_systems/045_systems 1.00 22.4±1.67µs ? ?/sec 1.02 22.9±0.51µs ? ?/sec
empty_systems/050_systems 1.00 24.4±1.67µs ? ?/sec 1.01 24.7±0.40µs ? ?/sec
empty_systems/055_systems 1.05 28.6±5.27µs ? ?/sec 1.00 27.2±0.70µs ? ?/sec
empty_systems/060_systems 1.02 29.9±1.64µs ? ?/sec 1.00 29.3±0.66µs ? ?/sec
empty_systems/065_systems 1.02 32.7±3.15µs ? ?/sec 1.00 32.1±0.98µs ? ?/sec
empty_systems/070_systems 1.00 33.0±1.42µs ? ?/sec 1.03 34.1±1.44µs ? ?/sec
empty_systems/075_systems 1.00 34.8±0.89µs ? ?/sec 1.04 36.2±0.70µs ? ?/sec
empty_systems/080_systems 1.00 37.0±1.82µs ? ?/sec 1.05 38.7±1.37µs ? ?/sec
empty_systems/085_systems 1.00 38.7±0.76µs ? ?/sec 1.05 40.8±0.83µs ? ?/sec
empty_systems/090_systems 1.00 41.5±1.09µs ? ?/sec 1.04 43.2±0.82µs ? ?/sec
empty_systems/095_systems 1.00 43.6±1.10µs ? ?/sec 1.04 45.2±0.99µs ? ?/sec
empty_systems/100_systems 1.00 46.7±2.27µs ? ?/sec 1.03 48.1±1.25µs ? ?/sec
```
</details>
## Migration Guide
### App `runner` and SubApp `extract` functions are now required to be Send
This was changed to enable pipelined rendering. If this breaks your use case please report it as these new bounds might be able to be relaxed.
## ToDo
* [x] redo benchmarking
* [x] reinvestigate the perf of the try_tick -> run change for task pool scope
commit b3224e135bd82b445fa506e6b68c71cb13a4e7be
Author: IceSentry <c.giguere42@gmail.com>
Date: Thu Jan 19 22:11:13 2023 +0000
Add depth and normal prepass (#6284)
# Objective
- Add a configurable prepass
- A depth prepass is useful for various shader effects and to reduce overdraw. It can be expansive depending on the scene so it's important to be able to disable it if you don't need any effects that uses it or don't suffer from excessive overdraw.
- The goal is to eventually use it for things like TAA, Ambient Occlusion, SSR and various other techniques that can benefit from having a prepass.
## Solution
The prepass node is inserted before the main pass. It runs for each `Camera3d` with a prepass component (`DepthPrepass`, `NormalPrepass`). The presence of one of those components is used to determine which textures are generated in the prepass. When any prepass is enabled, the depth buffer generated will be used by the main pass to reduce overdraw.
The prepass runs for each `Material` created with the `MaterialPlugin::prepass_enabled` option set to `true`. You can overload the shader used by the prepass by using `Material::prepass_vertex_shader()` and/or `Material::prepass_fragment_shader()`. It will also use the `Material::specialize()` for more advanced use cases. It is enabled by default on all materials.
The prepass works on opaque materials and materials using an alpha mask. Transparent materials are ignored.
The `StandardMaterial` overloads the prepass fragment shader to support alpha mask and normal maps.
---
## Changelog
- Add a new `PrepassNode` that runs before the main pass
- Add a `PrepassPlugin` to extract/prepare/queue the necessary data
- Add a `DepthPrepass` and `NormalPrepass` component to control which textures will be created by the prepass and available in later passes.
- Add a new `prepass_enabled` flag to the `MaterialPlugin` that will control if a material uses the prepass or not.
- Add a new `prepass_enabled` flag to the `PbrPlugin` to control if the StandardMaterial uses the prepass. Currently defaults to false.
- Add `Material::prepass_vertex_shader()` and `Material::prepass_fragment_shader()` to control the prepass from the `Material`
## Notes
In bevy's sample 3d scene, the performance is actually worse when enabling the prepass, but on more complex scenes the performance is generally better. I would like more testing on this, but @DGriffin91 has reported a very noticeable improvements in some scenes.
The prepass is also used by @JMS55 for TAA and GTAO
discord thread: <https://discord.com/channels/691052431525675048/1011624228627419187>
This PR was built on top of the work of multiple people
Co-Authored-By: @superdump
Co-Authored-By: @robtfm
Co-Authored-By: @JMS55
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
commit 519f6f45de0fc16592c7adcf40748f174569f807
Author: Aceeri <conmcclusk@gmail.com>
Date: Thu Jan 19 06:05:39 2023 +0000
Remove unnecessary windows.rs file (#7277)
# Objective
Accidentally re-added this old file at some point during the Windows as Entities PR apparently
## Solution
Removed the file, its unused
commit 884ebbf4b7a61d8748b2b309ab0bcdf02b51abbf
Author: Mike <mike.hsu@gmail.com>
Date: Thu Jan 19 05:08:55 2023 +0000
min version of fixedbitset was changed (#7275)
# Objective
- schedule v3 is using is_clear which was added in 0.4.2, so bump the version
commit fe382acfd09870992c0516173360fd7da8c108a8
Author: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Date: Thu Jan 19 04:35:46 2023 +0000
Fix a typo on `Window::set_minimized` (#7276)
# Objective
There is a typo on the method `Window::set_minimized`.
## Solution
fix it
commit 629cfab135e5f4087ad2a481a4a9be8921d13b83
Author: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Date: Thu Jan 19 03:04:39 2023 +0000
Improve safety for `CommandQueue` internals (#7039)
# Objective
- Safety comments for the `CommandQueue` type are quite sparse and very imprecise. Sometimes, they are right for the wrong reasons or use circular reasoning.
## Solution
- Document previously-implicit safety invariants.
- Rewrite safety comments to actually reflect the specific invariants of each operation.
- Use `OwningPtr` instead of raw pointers, to encode an invariant in the type system instead of via comments.
- Use typed pointer methods when possible to increase reliability.
---
## Changelog
+ Added the function `OwningPtr::read_unaligned`.
commit ddfafab971e335ce5a47d4e4b3fcf51f124d999f
Author: Aceeri <conmcclusk@gmail.com>
Date: Thu Jan 19 00:38:28 2023 +0000
Windows as Entities (#5589)
# Objective
Fix https://github.com/bevyengine/bevy/issues/4530
- Make it easier to open/close/modify windows by setting them up as `Entity`s with a `Window` component.
- Make multiple windows very simple to set up. (just add a `Window` component to an entity and it should open)
## Solution
- Move all properties of window descriptor to ~components~ a component.
- Replace `WindowId` with `Entity`.
- ~Use change detection for components to update backend rather than events/commands. (The `CursorMoved`/`WindowResized`/... events are kept for user convenience.~
Check each field individually to see what we need to update, events are still kept for user convenience.
---
## Changelog
- `WindowDescriptor` renamed to `Window`.
- Width/height consolidated into a `WindowResolution` component.
- Requesting maximization/minimization is done on the [`Window::state`] field.
- `WindowId` is now `Entity`.
## Migration Guide
- Replace `WindowDescriptor` with `Window`.
- Change `width` and `height` fields in a `WindowResolution`, either by doing
```rust
WindowResolution::new(width, height) // Explicitly
// or using From<_> for tuples for convenience
(1920., 1080.).into()
```
- Replace any `WindowCommand` code to just modify the `Window`'s fields directly and creating/closing windows is now by spawning/despawning an entity with a `Window` component like so:
```rust
let window = commands.spawn(Window { ... }).id(); // open window
commands.entity(window).despawn(); // close window
```
## Unresolved
- ~How do we tell when a window is minimized by a user?~
~Currently using the `Resize(0, 0)` as an indicator of minimization.~
No longer attempting to tell given how finnicky this was across platforms, now the user can only request that a window be maximized/minimized.
## Future work
- Move `exit_on_close` functionality out from windowing and into app(?)
- https://github.com/bevyengine/bevy/issues/5621
- https://github.com/bevyengine/bevy/issues/7099
- https://github.com/bevyengine/bevy/issues/7098
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
commit f0c504947ce653068a424979faf226c1e990818d
Author: Stephen Martindale <stephenmartindale@users.noreply.github.com>
Date: Wed Jan 18 23:02:38 2023 +0000
Docs: App::run() might never return; effect of WinitSettings::return_from_run. (#7228)
# Objective
See:
- https://github.com/bevyengine/bevy/issues/7067#issuecomment-1381982285
- (This does not fully close that issue in my opinion.)
- https://discord.com/channels/691052431525675048/1063454009769340989
## Solution
This merge request adds documentation:
1. Alert users to the fact that `App::run()` might never return and code placed after it might never be executed.
2. Makes `winit::WinitSettings::return_from_run` discoverable.
3. Better explains why `winit::WinitSettings::return_from_run` is discouraged and better links to up-stream docs. on that topic.
4. Adds notes to the `app/return_after_run.rs` example which otherwise promotes a feature that carries caveats.
Furthermore, w.r.t `winit::WinitSettings::return_from_run`:
- Broken links to `winit` docs are fixed.
- Links now point to BOTH `EventLoop::run()` and `EventLoopExtRunReturn::run_return()` which are the salient up-stream pages and make more sense, taken together.
- Collateral damage: "Supported platforms" heading; disambiguation of "run" → `App::run()`; links.
## Future Work
I deliberately structured the "`run()` might not return" section under `App::run()` to allow for alternative patterns (e.g. `AppExit` event, `WindowClosed` event) to be listed or mentioned, beneath it, in the future.
commit f8feec6ef1a47a6c8a562399b883d92198f02222
Author: targrub <targrub@gmail.com>
Date: Wed Jan 18 17:20:27 2023 +0000
Fix tiny clippy issue for upcoming Rust version (#7266)
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
commit e0b921fbd99dffb612860ac9684f800b472a66ec
Author: harudagondi <giogdeasis@gmail.com>
Date: Wed Jan 18 17:20:26 2023 +0000
AudioOutput is actually a normal resource now, not a non-send resource (#7262)
# Objective
- Fixes #7260
## Solution
- #6649 used `init_non_send_resource` for `AudioOutput`, but this is before #6436 was merged.
- Use `init_resource` instead.
commit 46293ce1e4c61421e353dc0b0431da67af6b7568
Author: Rob Parrett <robparrett@gmail.com>
Date: Wed Jan 18 17:06:08 2023 +0000
Fix init_non_send_resource overwriting previous values (#7261)
# Objective
Repeated calls to `init_non_send_resource` currently overwrite the old value because the wrong storage is being checked.
## Solution
Use the correct storage. Add some tests.
## Notes
Without the fix, the new test fails with
```
thread 'world::tests::init_non_send_resource_does_not_overwrite' panicked at 'assertion failed: `(left == right)`
left: `1`,
right: `0`', crates/bevy_ecs/src/world/mod.rs:2267:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
test world::tests::init_non_send_resource_does_not_overwrite ... FAILED
```
This was introduced by #7174 and it seems like a fairly straightforward oopsie.
commit d6bfd44f8f48af92c727a42ca7fe43f32a2ab747
Author: Charles Bournhonesque <cbournhonesque@snapchat.com>
Date: Wed Jan 18 14:26:07 2023 +0000
update doc comment for new_archetype in query-state (#7241)
# Objective
I was reading through the bevy_ecs code, trying to understand how everything works.
I was getting a bit confused when reading the doc comment for the `new_archetype` function; it looks like it doesn't create a new archetype but instead updates some internal state in the SystemParam to facility QueryIteration.
(I still couldn't find where a new archetype was actually created)
## Solution
- Adding a doc comment with a more correct explanation.
If it's deemed correct, I can also update the doc-comment for the other `new_archetype` calls
commit 88b353c4b1665625d5aabe6149e184ec5ba5984c
Author: James Liu <contact@jamessliu.com>
Date: Wed Jan 18 02:19:19 2023 +0000
Reduce the use of atomics in the render phase (#7084)
# Objective
Speed up the render phase of rendering. An extension of #6885.
`SystemState::get` increments the `World`'s change tick atomically every time it's called. This is notably more expensive than a unsynchronized increment, even without contention. It also updates the archetypes, even when there has been nothing to update when it's called repeatedly.
## Solution
Piggyback off of #6885. Split `SystemState::validate_world_and_update_archetypes` into `SystemState::validate_world` and `SystemState::update_archetypes`, and make the later `pub`. Then create safe variants of `SystemState::get_unchecked_manual` that still validate the `World` but do not update archetypes and do not increment the change tick using `World::read_change_tick` and `World::change_tick`. Update `RenderCommandState` to call `SystemState::update_archetypes` in `Draw::prepare` and `SystemState::get_manual` in `Draw::draw`.
## Performance
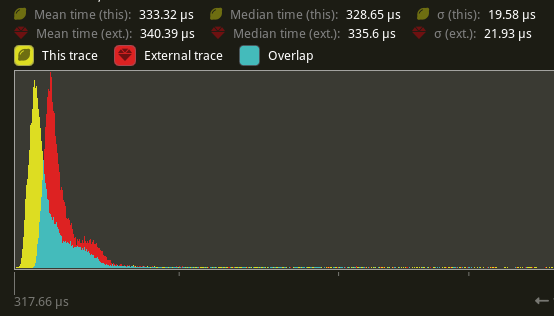
There's a slight perf benefit (~2%) for `main_opaque_pass_3d` on `many_foxes` (340.39 us -> 333.32 us)
## Alternatives
We can change `SystemState::get` to not increment the `World`'s change tick. Though this would still put updating the archetypes and an atomic read on the hot-path.
---
## Changelog
Added: `SystemState::get_manual`
Added: `SystemState::get_manual_mut`
Added: `SystemState::update_archetypes`
commit 9eefd7c022efe572ffd2840cfc7a8b9eee982428
Author: ickshonpe <david.curthoys@googlemail.com>
Date: Wed Jan 18 02:19:17 2023 +0000
Remove VerticalAlign from TextAlignment (#6807)
# Objective
Remove the `VerticalAlign` enum.
Text's alignment field should only affect the text's internal text alignment, not its position. The only way to control a `TextBundle`'s position and bounds should be through the manipulation of the constraints in the `Style` components of the nodes in the Bevy UI's layout tree.
`Text2dBundle` should have a separate `Anchor` component that sets its position relative to its transform.
Related issues: #676, #1490, #5502, #5513, #5834, #6717, #6724, #6741, #6748
## Changelog
* Changed `TextAlignment` into an enum with `Left`, `Center`, and `Right` variants.
* Removed the `HorizontalAlign` and `VerticalAlign` types.
* Added an `Anchor` component to `Text2dBundle`
* Added `Component` derive to `Anchor`
* Use `f32::INFINITY` instead of `f32::MAX` to represent unbounded text in Text2dBounds
## Migration Guide
The `alignment` field of `Text` now only affects the text's internal alignment.
### Change `TextAlignment` to TextAlignment` which is now an enum. Replace:
* `TextAlignment::TOP_LEFT`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_LEFT` with `TextAlignment::Left`
* `TextAlignment::TOP_CENTER`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_CENTER` with `TextAlignment::Center`
* `TextAlignment::TOP_RIGHT`, `TextAlignment::CENTER_RIGHT`, `TextAlignment::BOTTOM_RIGHT` with `TextAlignment::Right`
### Changes for `Text2dBundle`
`Text2dBundle` has a new field 'text_anchor' that takes an `Anchor` component that controls its position relative to its transform.
commit 4ff50f6b5062145592575c98d9cc85f04a23ec82
Author: IceSentry <c.giguere42@gmail.com>
Date: Wed Jan 18 02:07:26 2023 +0000
fix load_internal_binary_asset with debug_asset_server (#7246)
# Objective
- Enabling the `debug_asset_server` feature doesn't compile when using it with `load_internal_binary_asset!()`. The issue is because it assumes the loader takes an `&'static str` as a parameter, but binary assets loader expect `&'static [u8]`.
## Solution
- Add a generic type for the loader and use a different type in `load_internal_asset` and `load_internal_binary_asset`
commit 0df67cdaae30becd35447c6767d5e30afeee17f1
Author: dis-da-moe <moe.uraijah@gmail.com>
Date: Tue Jan 17 22:42:00 2023 +0000
Add `AddAudioSource` trait and improve `Decodable` docs (#6649)
# Objective
- Fixes #6361
- Fixes #6362
- Fixes #6364
## Solution
- Added an example for creating a custom `Decodable` type
- Clarified the documentation on `Decodable`
- Added an `AddAudioSource` trait and implemented it for `App`
Co-authored-by: dis-da-moe <84386186+dis-da-moe@users.noreply.github.com>
commit 7d0edbc4d65c483d3e73c574b93a4a36560c0d07
Author: James Liu <contact@jamessliu.com>
Date: Tue Jan 17 22:26:51 2023 +0000
Improve change detection behavior for transform propagation (#6870)
# Objective
Fix #4647. If any child is changed, or even reordered, `Changed<Children>` is true, which causes transform propagation to propagate changes to all siblings of a changed child, even if they don't need to be.
## Solution
As `Parent` and `Children` are updated in tandem in hierarchy commands after #4800. `Changed<Parent>` is true on the child when `Changed<Children>` is true on the parent. However, unlike checking children, checking `Changed<Parent>` is only localized to the current entity and will not force propagation to the siblings.
Also took the opportunity to change propagation to use `Query::iter_many` instead of repeated `Query::get` calls. Should cut a bit of the overhead out of propagation. This means we won't panic when there isn't a `Parent` on the child, just skip over it.
The tests from #4608 still pass, so the change detection here still works just fine under this approach.
commit 0ca9c618e1dedecfe737d9a1a23748192e348441
Author: Boxy <supbscripter@gmail.com>
Date: Tue Jan 17 21:11:26 2023 +0000
Update "Classifying PRs" section to talk about `D-Complex` (#7216)
The current section does not talk about `D-Complex` and lists things like "adds unsafe code" as a reason to mark a PR `S-Controversial`. This is not how `D-Complex` and `S-Controversial` are being used at the moment.
This PR lists what classifies a PR as `D-Complex` and what classifies a PR as `S-Controversial`. It also links to some PRs with each combination of labels to help give an idea for what this means in practice.
cc #7211 which is doing a similar thing
commit 63a291c6a800a12e8beb3dbad8f64927380493ca
Author: Mike <mike.hsu@gmail.com>
Date: Tue Jan 17 17:54:53 2023 +0000
add tests for change detection and conditions for stageless (#7249)
# Objective
- add some tests for how change detection and run criteria interact in stageless
commit 45dfa71e032fef2827f154f60928da84e11cc92d
Author: robtfm <50659922+robtfm@users.noreply.github.com>
Date: Tue Jan 17 17:39:28 2023 +0000
fix bloom viewport (#6802)
# Objective
fix bloom when used on a camera with a viewport specified
## Solution
- pass viewport into the prefilter shader, and use it to read from the correct section of the original rendered screen
- don't apply viewport for the intermediate bloom passes, only for the final blend output
commit 1cc663f2909e8d8a989668383bb0c3c5f034a816
Author: wyhaya <hi@wyhaya.com>
Date: Tue Jan 17 13:26:43 2023 +0000
Improve `Color::hex` performance (#6940)
# Objective
Improve `Color::hex` performance
#### Bench
```bash
running 2 tests
test bench_color_hex_after ... bench: 4 ns/iter (+/- 0)
test bench_color_hex_before ... bench: 14 ns/iter (+/- 0)
```
## Solution
Use `const fn` decode hex value.
---
## Changelog
Rename
```rust
HexColorError::Hex(FromHexError) -> HexColorError::Char(char)
```
commit 16ff05acdf2f04c37059c76dc87457d36f78c2f8
Author: 2ne1ugly <chattermin@gmail.com>
Date: Tue Jan 17 04:20:42 2023 +0000
Add `World::clear_resources` & `World::clear_all` (#3212)
# Objective
- Fixes #3158
## Solution
- clear columns
My implementation of `clear_resources` do not remove the components itself but it clears the columns that keeps the resource data. I'm not sure if the issue meant to clear all resources, even the components and component ids (which I'm not sure if it's possible)
Co-authored-by: 2ne1ugly <47616772+2ne1ugly@users.noreply.github.com>
commit b5893e570d2a68471d2f3d147751dcc33bac32e0
Author: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Date: Tue Jan 17 03:29:08 2023 +0000
Add a missing impl of `ReadOnlySystemParam` for `Option<NonSend<>>` (#7245)
# Objective
The trait `ReadOnlySystemParam` is not implemented for `Option<NonSend<>>`, even though it should be.
Follow-up to #7243. This fixes another mistake made in #6919.
## Solution
Add the missing impl.
commit 0efe66b081e0e8ea5bf089b7d2394598a9774993
Author: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Date: Tue Jan 17 01:39:19 2023 +0000
Remove an incorrect impl of `ReadOnlySystemParam` for `NonSendMut` (#7243)
# Objective
The trait `ReadOnlySystemParam` is implemented for `NonSendMut`, when it should not be. This mistake was made in #6919.
## Solution
Remove the incorrect impl.
commit 684f07595f2f440556cd26a3d8fb5af0d809f872
Author: Cameron <51241057+maniwani@users.noreply.github.com>
Date: Tue Jan 17 01:39:17 2023 +0000
Add `bevy_ecs::schedule_v3` module (#6587)
# Objective
Complete the first part of the migration detailed in bevyengine/rfcs#45.
## Solution
Add all the new stuff.
### TODO
- [x] Impl tuple methods.
- [x] Impl chaining.
- [x] Port ambiguity detection.
- [x] Write docs.
- [x] ~~Write more tests.~~(will do later)
- [ ] Write changelog and examples here?
- [x] ~~Replace `petgraph`.~~ (will do later)
Co-authored-by: james7132 <contact@jamessliu.com>
Co-authored-by: Michael Hsu <mike.hsu@gmail.com>
Co-authored-by: Mike Hsu <mike.hsu@gmail.com>
commit 6b4795c428f694a332f0a4710df1ba9b5499bc26
Author: ira <JustTheCoolDude@gmail.com>
Date: Mon Jan 16 23:13:11 2023 +0000
Add `Camera::viewport_to_world_2d` (#6557)
# Objective
Add a simpler and less expensive 2D variant of `viewport_to_world`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
commit 39e14a4a40014fe5f14bef9cf39916ed3e799b2e
Author: Alice Cecile <alice.i.cecile@gmail.com>
Date: Mon Jan 16 22:10:51 2023 +0000
Make `EntityRef::new` unsafe (#7222)
# Objective
- We rely on the construction of `EntityRef` to be valid elsewhere in unsafe code. This construction is not checked (for performance reasons), and thus this private method must be unsafe.
- Fixes #7218.
## Solution
- Make the method unsafe.
- Add safety docs.
- Improve safety docs slightly for the sibling `EntityMut::new`.
- Add debug asserts to start to verify these assumptions in debug mode.
## Context for reviewers
I attempted to verify the `EntityLocation` more thoroughly, but this turned out to be more work than expected. I've spun that off into #7221 as a result.
commit e44990a48d97fe73aef8f53d2016bd05b260e1ba
Author: ld000 <voidd247@outlook.com>
Date: Mon Jan 16 21:24:15 2023 +0000
Add ReplaceChildren and ClearChildren EntityCommands (#6035)
# Objective
Fixes #5859
## Solution
- Add `ClearChildren` and `ReplaceChildren` commands in the `crates/bevy_hierarchy/src/child_builder.rs`
---
## Changelog
- Added `ClearChildren` and `ReplaceChildren` struct
- Added `clear_children(&mut self) -> &mut Self` and `replace_children(&mut self, children: &[Entity]) -> &mut Self` function in `BuildChildren` trait
- Changed `PushChildren` `write` function body to a `push_children ` function to reused in `ReplaceChildren`
- Added `clear_children` function
- Added `push_and_replace_children_commands` and `push_and_clear_children_commands` test
Co-authored-by: ld000 <lidong9144@163.com>
Co-authored-by: lidong63 <lidong63@meituan.com>
commit d4e3fcdfbf306c10cd28cb914e228cc0a24c2336
Author: Elbert Ronnie <elbert.ronniep@gmail.com>
Date: Mon Jan 16 21:09:24 2023 +0000
Fix incorrect behavior of `just_pressed` and `just_released` in `Input<GamepadButton>` (#7238)
# Objective
- Fixes a bug where `just_pressed` and `just_released` in `Input<GamepadButton>` might behave incorrectly due calling `clear` 3 times in a single frame through these three different systems: `gamepad_button_event_system`, `gamepad_axis_event_system` and `gamepad_connection_system` in any order
## Solution
- Call `clear` only once and before all the above three systems, i.e. in `gamepad_event_system`
## Additional Info
- Discussion in Discord: https://discord.com/channels/691052431525675048/768253008416342076/1064621963693273279
commit addc36fe297bce3325cf1fa110a67692ac09d232
Author: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Date: Mon Jan 16 20:35:15 2023 +0000
Add safety comments to usages of `byte_add` (`Ptr`, `PtrMut`, `OwningPtr`) (#7214)
# Objective
The usages of the unsafe function `byte_add` are not properly documented.
Follow-up to #7151.
## Solution
Add safety comments to each call-site.
commit 5fd628ebd32aea9a38882dfc38cc3160cf4c82f7
Author: ira <JustTheCoolDude@gmail.com>
Date: Mon Jan 16 20:20:37 2023 +0000
Fix Alien Cake Addict example despawn warnings (#7236)
# Problem
The example's `teardown` system despawns all entities besides the camera using `despawn_recursive` causing it to despawn child entities multiple times which logs a warning.

# Solution
Use `despawn` instead.
Co-authored-by: Devil Ira <justthecooldude@gmail.com>
commit 2f4cf768661839079f49fe5ef9527248a9131b95
Author: Nicola Papale <nico@nicopap.ch>
Date: Mon Jan 16 18:13:04 2023 +0000
Fix axis settings constructor (#7233)
# Objective
Currently, the `AxisSettings::new` function is unusable due to
an implementation quirk. It only allows `AxisSettings` where
the bounds that are supposed to be positive are negative!
## Solution
- We fix the bound check
- We add a test to make sure the method is usable
Seems like the error slipped through because of the relatively
verbose code style. With all those `if/else`, very long names,
range syntax, the bound check is actually hard to spot. I first
refactored a lot of code, but I left out the refactor because the
fix should be integrated independently.
---
## Changelog
- Fix `AxisSettings::new` only accepting invalid bounds
commit 83028994d17842e975b17bd849ab76c3ef6e5fbb
Author: Thierry Berger <contact@thierryberger.com>
Date: Mon Jan 16 17:36:09 2023 +0000
Optional BEVY_ASSET_ROOT to find assets directory (#5346)
# Objective
Fixes #5345
## Changelog
- Support optional env variable `BEVY_ASSET_ROOT` to explicitly specify root assets directory.
commit a792f37040f5edb62a6a13166c72978e1cbc9c9c
Author: Dawid Piotrowski <dawidekpe@gmail.com>
Date: Mon Jan 16 17:17:45 2023 +0000
Relative cursor position (#7199)
# Objective
Add useful information about cursor position relative to a UI node. Fixes #7079.
## Solution
- Added a new `RelativeCursorPosition` component
---
## Changelog
- Added
- `RelativeCursorPosition`
- an example showcasing the new component
Co-authored-by: Dawid Piotrowski <41804418+Pietrek14@users.noreply.github.com>
commit 517deda215f58da2b6f27d373c42b97a93a95d58
Author: Daniel Chia <danstryder@gmail.com>
Date: Mon Jan 16 15:41:14 2023 +0000
Make PipelineCache internally mutable. (#7205)
# Objective
- Allow rendering queue systems to use a `Res<PipelineCache>` even for queueing up new rendering pipelines. This is part of unblocking parallel execution queue systems.
## Solution
- Make `PipelineCache` internally mutable w.r.t to queueing new pipelines. Pipelines are no longer immediately updated into the cache state, but rather queued into a Vec. The Vec of pending new pipelines is then later processed at the same time we actually create the queued pipelines on the GPU device.
---
## Changelog
`PipelineCache` no longer requires mutable access in order to queue render / compute pipelines.
## Migration Guide
* Most usages of `resource_mut::<PipelineCache>` and `ResMut<PipelineCache>` can be changed to `resource::<PipelineCache>` and `Res<PipelineCache>` as long as they don't use any methods requiring mutability - the only public method requiring it is `process_queue`.
commit 4b326fb4caed0bcad85954083f87846adface…
Objective
Clean up code surrounding fetch by pulling out the common parts into the iteration code.
Solution
Merge
Fetch::table_fetchandFetch::archetype_fetchinto a single API:Fetch::fetch(&mut self, entity: &Entity, table_row: &usize). This provides everything any fetch requires to internally decide which storage to read from and get the underlying data. All of these functions are marked as#[inline(always)]and the arguments are passed as references to attempt to optimize out the argument that isn't being used.External to
Fetch, Query iteration has been changed to keep track of the table row and entity outside of fetch, which moves a lot of the expensive bookkeepingFetchstructs had previously done internally into the outer loop.TODO: Benchmark, docsDone.Changelog
Changed:
Fetch::table_fetchandFetch::archetype_fetchhave been merged into a singleFetch::fetchfunction.Migration Guide
TODO