Upstream bump 1109 #2172
Merged
Upstream bump 1109 #2172
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
See pytorch#87969 or pytorch#86586 for the reasoning. Pull Request resolved: pytorch#87972 Approved by: https://github.com/mruberry
See pytorch#87969 or pytorch#86586 for the reasoning. Pull Request resolved: pytorch#87973 Approved by: https://github.com/mruberry
See pytorch#87969 or pytorch#86586 for the reasoning. Pull Request resolved: pytorch#87974 Approved by: https://github.com/mruberry
Fixes pytorch/torchdynamo#1708 Our FX subgraph partitioner works by taking all of the original output nodes from a subgraph, and replacing it with a new `call_module` node in the graph. If the original subgraph outputs had fake tensors and other metadata stored in their `.meta` attribute though, then this information was getting lost when we spliced in the subgraph. Losing metadata on an FX graph also seems like an easy trap to fall into, so I'm wondering if there are any better guardrails that we can add. I ended up fixing in this PR by adding an optional kwarg to propagate meta info directly in the `fx.Node.replace_all_uses_with`, just because propagating metadata seems like a pretty core thing. Pull Request resolved: pytorch#87255 Approved by: https://github.com/wconstab, https://github.com/SherlockNoMad
as_strided_scatter's derivative formula was broken - instead of making a "mask" of 1's and 0's, it would effectively make a mask of 1's and uninitialized memory. Fixes pytorch#88105 Pull Request resolved: pytorch#87646 Approved by: https://github.com/albanD
…#87874) * Wiring to allow user to pass event names to profiler and reflect the count to the chrometrace * If not used, the runtime and size overhead should be neglegible * For now, primary user will be KinetoEdgeCPUProfiler but the impl does not assume that * Not exposed to python yet Differential Revision: [D40238032](https://our.internmc.facebook.com/intern/diff/D40238032/) **NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D40238032/)! Pull Request resolved: pytorch#87874 Approved by: https://github.com/SS-JIA
…87876) * Add support in lite_predictor benchmark binary to select event lists * Uses Linux perf through Kineto profiler Differential Revision: [D39837216](https://our.internmc.facebook.com/intern/diff/D39837216/) **NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39837216/)! Pull Request resolved: pytorch#87876 Approved by: https://github.com/SS-JIA
…rch#87877) * Runs an existing model and checks an aten op if it gets perf events generated in the chrometrace * Doesn't check for exact values since that's harder to do in a hardware independent way Differential Revision: [D40474957](https://our.internmc.facebook.com/intern/diff/D40474957/) Pull Request resolved: pytorch#87877 Approved by: https://github.com/SS-JIA
Add a stack of start counter values, and attribute each disable to the last enable Differential Revision: [D40539212](https://our.internmc.facebook.com/intern/diff/D40539212/) Pull Request resolved: pytorch#87904 Approved by: https://github.com/SS-JIA
…87905) Reports total counts (includes time spent in all children), self counts can be calculated manully. Differential Revision: [D40282770](https://our.internmc.facebook.com/intern/diff/D40282770/) Pull Request resolved: pytorch#87905 Approved by: https://github.com/SS-JIA
Signed-off-by: Edward Z. Yang <ezyang@fb.com> Pull Request resolved: pytorch#88315 Approved by: https://github.com/soumith
Fixes pytorch#87313 Our ONNX pipelines do not run with BUILD_CAFFE2=0, so tests for operator_export_type ONNX_ATEN and ONNX_ATEN_FALLBACK will not be fully tested, allowing regressions to happen again. We need to run the same set of tests for both BUILD_CAFFE2=0 and 1 Pull Request resolved: pytorch#87735 Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
Pull Request resolved: pytorch#87212 Approved by: https://github.com/BowenBao
In attempt to mitigate OOMs, see pytorch#88309 Pull Request resolved: pytorch#88310 Approved by: https://github.com/albanD
Use `std::vector` to store tensor shapes and automatically free them when array goes out of scope Pull Request resolved: pytorch#88307 Approved by: https://github.com/kulinseth
Fixes #ISSUE_NUMBER Pull Request resolved: pytorch#88292 Approved by: https://github.com/awgu
Pull Request resolved: pytorch#87939 Approved by: https://github.com/zhaojuanmao
This reverts commit f9d7985. Reverted pytorch#87646 on behalf of https://github.com/huydhn due to Sorry for reverting your PR but I think this one or one of the PR in the stack break bionic-cuda11.7 on trunk https://hud.pytorch.org/pytorch/pytorch/commit/70782981f06a042796d4604df2ec1491f4f5b194
Pull Request resolved: pytorch#88158 Approved by: https://github.com/ngimel
This reverts commit 73379ac. Reverted pytorch#87610 on behalf of https://github.com/mehtanirav due to [Internal breakages](https://www.internalfb.com/intern/sandcastle/job/36028797828925790/insights)
Pull Request resolved: pytorch#87940 Approved by: https://github.com/mrshenli
After conda, consolidating all macos pip dependencies to cache every dependencies that macos CI needs. Two small issues are found along the way in `_mac-test-mps` workflow: * It didn't have `Install macOS homebrew dependencies` to install libomp like the regular `_mac-test` workflow * It didn't install `scipy`, thus silently skipping some `signal.windows` tests Both are fixed in this PR Pull Request resolved: pytorch#88071 Approved by: https://github.com/malfet
I'm not quite sure why GitHub starts to get flaky when we are trying to upload usage_log.txt to it (500 Internal server error). But we can live without it, so let's just ignore this for now, and follow up on this latter. The failures all come from M1 runner, so it seems to point to a connectivity issue between AWS and GitHub: * https://github.com/pytorch/pytorch/actions/runs/3373976793/jobs/5599310905 * https://github.com/pytorch/pytorch/actions/runs/3372858660/jobs/5597033598 * https://github.com/pytorch/pytorch/actions/runs/3371548201/jobs/5594274444 * https://github.com/pytorch/pytorch/actions/runs/3370877990/jobs/5592709210 * https://github.com/pytorch/pytorch/actions/runs/3370609384/jobs/5592008430 Pull Request resolved: pytorch#88288 Approved by: https://github.com/clee2000
Today, this doesn't work and dynamo errors out in a very non-obvious way (see: https://gist.github.com/suo/dde04830372ab51a4a34ea760f14200a). Here, we detect the error early and exit with a nicer msg. Also add a config option to just no-op dynamo (which need to unblock internal enablement). Pull Request resolved: pytorch#87797 Approved by: https://github.com/yf225, https://github.com/soumith, https://github.com/jansel
This calls `lspci`, `lsmod`, and `modinfo nvidia` before and after the installation to gather more data about the "No GPU available" transient issue on G5 runner, i.e. https://hud.pytorch.org/pytorch/pytorch/commit/59fe272c1e698989228af5ad197bdd2985e4e9b9 This also handles `nvidia-smi` call and tries to re-install the driver if the first call fails, i.e. `No devices were found` https://hud.pytorch.org/pytorch/pytorch/commit/8ea19c802e38c061e79176360c1ecaa81ce2088a Pull Request resolved: pytorch#88168 Approved by: https://github.com/clee2000, https://github.com/malfet
- Asserts for CUDA are enabled by default - Disabled for ROCm by default by setting `TORCH_DISABLE_GPU_ASSERTS` to `ON` - Can be enabled for ROCm by setting above variable to`OFF` during build or can be forcefully enabled by setting `ROCM_FORCE_ENABLE_GPU_ASSERTS:BOOL=ON` This is follow up changes as per comment in PR pytorch#81790, comment [link](pytorch#81790 (comment)) Pull Request resolved: pytorch#84190 Approved by: https://github.com/jeffdaily, https://github.com/malfet
…ytorch#87941) Pull Request resolved: pytorch#87941 Approved by: https://github.com/mrshenli
Fixes: pytorch#88205 The `CreationMeta::NO_GRAD_MODE` path in handle_view_on_rebase wrongly assumes that the tensor would be a leaf, because tensors created in no_grad are always leaf tensors. However, due to creation_meta propagation, a view of a view created in no_grad also has `CreationMeta::NO_GRAD_MODE`, but DOES have grad_fn. Pull Request resolved: pytorch#88243 Approved by: https://github.com/albanD
Previously the permute function was extended to behave like the `order` function for first-class dimensions. However, unlike `permute`, `order` doesn't have a keyword argment `dims`, and there is no way to add it in a way that makes both permute an order to continue to have the same behavior. So this change just removes the extra functionality of permute, which wasn't documented anyway. Fixes pytorch#88187 Pull Request resolved: pytorch#88226 Approved by: https://github.com/zou3519
This PR unifies and rationalizes some of the input representation in Result. The current approach of storing separate types in separate vectors is tedious for two types (Tensors and scalars), but would be even more annoying with the addition of TensorLists. A similar disconnection exists with sizes and strides which the user is also expected to zip with tensor_metadata. I simplified things by moving inputs to a variant and moving sizes and strides into TensorMetadata. This also forced collection of sizes and strides in python tracer which helps to bring it in line with op profiling. Collection of TensorLists is fairly straightforward; `InputOutputEncoder` already has a spot for them (I actually collected them in the original TorchTidy prototype) so it was just a matter of plumbing things through. Differential Revision: [D40734451](https://our.internmc.facebook.com/intern/diff/D40734451/) Pull Request resolved: pytorch#87825 Approved by: https://github.com/slgong-fb, https://github.com/chaekit
…torch#88690) Pull Request resolved: pytorch#88690 Approved by: https://github.com/cpuhrsch
…ytorch#88640) I think this is the final resolution to issue caused by pytorch#87797. The nvfuser issue that PR tripped up was because, even though we're correctly disabling torchdynamo via a `DisableContext`, the nested fx trace check was still firing. This PR properly narrows it to only fire if we're not disabled. Pull Request resolved: pytorch#88640 Approved by: https://github.com/yf225
…6802) There are multiple ways to indentify that a Tensor is a gradient. (A subset of which also give additional context.) So to start off I've made a utility to handle that determination. Differential Revision: [D39920730](https://our.internmc.facebook.com/intern/diff/D39920730/) Pull Request resolved: pytorch#86802 Approved by: https://github.com/chaekit
) Summary: X-link: pytorch/torchrec#759 Since the remove_duplicate flag was added to named_buffers in D39493161 (pytorch@c12f829), this adds the same flag to named_parameters Test Plan: python test/test_nn.py -k test_buffers_and_named_buffers OSS Tests Differential Revision: D40801899 Pull Request resolved: pytorch#88090 Approved by: https://github.com/albanD
…rs. (pytorch#88585) Summary: This diff modifies the implementation of the select operator so slices of the irregular dimension can be selected (e.g. nt[:,0,:]). Test Plan: Added new unit tests to test that the new functions work as intended (see them in diff). To test, `buck test mode/dev-nosan //caffe2/test:nested` Differential Revision: D41083993 Pull Request resolved: pytorch#88585 Approved by: https://github.com/cpuhrsch
) Pull Request resolved: pytorch#88610 Approved by: https://github.com/huydhn
…torch#88651) Summary: Today when we transform the captured graph in the last step in export(aten_graph=True), we construct a new graph which doesn't have the all the metadata to be preserved, for example, node.meta["val"]. meta["val"] is important for writing passes and analysis on the graph later in the pipeline, we may want to preserve that on placeholder nodes. Test Plan: test_export.py:test_export_meta_val Differential Revision: D41110864 Pull Request resolved: pytorch#88651 Approved by: https://github.com/tugsbayasgalan, https://github.com/jansel
Also, add an explicit cudart dependency to `torch_cuda` if Kineto is used with GPU support (it used to be somehow inherited from a wrong `gloo` setup) Pull Request resolved: pytorch#88530 Approved by: https://github.com/osalpekar
For some reason bernoulli uses legacy memory format, see linked issue. Signed-off-by: Edward Z. Yang <ezyang@fb.com> Pull Request resolved: pytorch#88676 Approved by: https://github.com/SherlockNoMad
Signed-off-by: Edward Z. Yang <ezyang@fb.com> Pull Request resolved: pytorch#88675 Approved by: https://github.com/SherlockNoMad
Also, handle non-default alpha correctly. Signed-off-by: Edward Z. Yang <ezyang@fb.com> Pull Request resolved: pytorch#88678 Approved by: https://github.com/SherlockNoMad, https://github.com/albanD
…h#88528) In pytorch/torch/_C/__init__.pyi, Graph.addInput has signature ```python def addInput(self, name: str) -> Value: ... ``` which doesn't match the corresponding function ```cpp Value* addInput(const std::string& name = "") { return block_->addInput(name); } ``` in python_ir.cpp. This PR aligns the bound function on both C++ and Python sides. Without this PR, mypy will compain whenever a change contains some calls to `addInput`; for example, 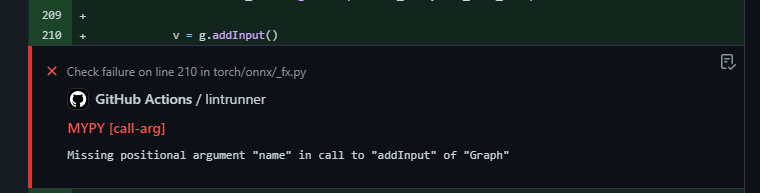 Pull Request resolved: pytorch#88528 Approved by: https://github.com/davidberard98
{kind=link}
Essentially a followup of pytorch#87436 CC @xwang233 @ptrblck Pull Request resolved: pytorch#87736 Approved by: https://github.com/xwang233, https://github.com/malfet
It allows one to SSH faster rather than having to wait for repo clone to finish. I.e. right now one usually have to wait for a few minutes fore PyTorch clone is finished, but with this change you can SSH ahead of time (thanks to `setup-ssh` being a composite action Pull Request resolved: pytorch#88715 Approved by: https://github.com/clee2000, https://github.com/izaitsevfb
## Description Support lowering of channel shuffle in FX by adding its module and functional op to `is_copy_node` list in `torch/ao/quantization/fx/_lower_to_native_backend.py` ## Validation UTs added to test - correctness of quantized `ChannelShuffle` module. - FX lowering of `ChannelShuffle` module and functional `channel_shuffle`. Pull Request resolved: pytorch#83731 Approved by: https://github.com/jerryzh168
…torch#87045) Fixes pytorch#87019. Pull Request resolved: pytorch#87045 Approved by: https://github.com/mruberry
It was previously CompositeExplicit but it was not really necessary. See discussion in pytorch#85405 Pull Request resolved: pytorch#85638 Approved by: https://github.com/ezyang, https://github.com/lezcano, https://github.com/malfet, https://github.com/jansel
…h#88298) Fixes pytorch#88201 Pull Request resolved: pytorch#88298 Approved by: https://github.com/jgong5, https://github.com/jansel
Merged
|
CI looks wrong.. let me remove those |
ac150d2
to
c48f0b3
Compare
c48f0b3
to
cfd8e5d
Compare
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Upstream bump to devel. merged upstream/viable/strict commit fca6ed0
Updated upstream/master in PR #2173