KEP: Support Device Monitoring #2454
Conversation
|
Does Who/what creates the
The |
Yes.
ResourceBinding is not an object that can be referenced. It is itself a reference to the object (Pod) it is binding resources to.
The controller performing the binding creates the ResourceBinding object. In the default case, this is the kubelet. ResourceBinding is the object that is passed to BindResource describing which resources (ComputeDevices) to bind to which object (Pod)
The |
|
/cc |
| In this document we will discuss the motivation and code changes required for introducing assigned device IDs information in the container API object. | ||
|
|
||
| ## Background | ||
| The [Pod API Object](https://github.com/kubernetes/api/blob/master/core/v1/types.go#L3072) contains the metadata, specification, and status of the smallest unit of computing that can be managed by kubernetes. In order to support Network Devices through the device plugin, it has been proposed (in [Network Devices Support Changes Proposal](https://docs.google.com/document/d/1TpYqgmJQOctm1oexQRo0cGNb9oyk0vozhmhr6myY99M/edit#heading=h.dp2sl8erwljy)) to add Pod UID to the `Allocate` call, and then have the CNI ask the Network Device Plugin for it to do network plumbing. This proposal takes a different approach that does not rely on adding the `PodUID` to the `Allocate` DPAPI call, and does not require explicit coordination between CNI and the Device Plugin. |
There was a problem hiding this comment.
cc @edwarnicke - do post your thoughts on consuming CNI without needing device IDs here if possible.
There was a problem hiding this comment.
@vishh I presented them to the Resource Management WG today using this deck and the recording is here.
The mechanism proposed is simple: rather than making users track specific devices and have some method to pick a specific device, Network Service Mesh represents the hardware resource of a NIC as providing a "Network Service". A 'Network Service' is some salient class of behaviors that are meaningful to the consuming Pod.
The NSM approach has a several advantages:
- No changes required to APIs: the NSM approach works perfectly fine with the current K8s APIs. It does not change the Pod spec, it does not change the Device Plugin API. This both minimizes work and maximizes the probability of not doing harm to the existing APIs.
- No Leaked Abstractions: DeviceId today appears to be an abstraction scoped between Kubelet and the DevicePlugin. NSM does not need to leak that abstraction up to the global level. Instead it uses the Network Service abstraction to represent the class of possible candidates to provide the desired resource. Since the Network Service abstration, and specifically the name field of that abstraction, already lives at the cluster level as a CRD, its appropriate that the NetworkService.name be used in the resource section of the Pod spec.
- Semantically Meaningful: The NSM approach allows the user in their Pod spec to ask for a semantically meaningful Network Service. Hardware NICs are not like GPUs and other hardware resources fully contained withing the Pod. Nobody cares about a hardware NIC. They care about what its connected to, and the Network Service being provided by that connection. That Network Service is a semantically meaningful thing, and the NSM approach lets you capture that.
- Simply Represents 'classes' of resources: By working with 'Network Services' rather than 'DeviceIDs', a user can request "give me a NIC that provides this Network Service" rather than "Give me this specific Device". Requiring users to name a DeviceId in their Pod spec is a heavy load.
- Adjustable granularity: A user could assign a distinct Network Service to each and every NIC in their cluster iff desirable to the user. But they don't have to. A user could assing every NIC in their cluster to a single Network Service. And any level of granularity in between.
- Generalizable: The pattern used by NSM should be generalizable to a wide assortment of other use cases that aren't networks.
There was a problem hiding this comment.
Excellent presentation! Plenty of things to chew on...
To clarify a misunderstanding, this proposal is not at all suggesting that users choose individual devices. This proposal seeks to make the device bound to a container by kubernetes observable for other components, and potentially allows a custom scheduler to pre-assign specific devices before assigning the pod to a node.
The ResourceName users place in their pod's requests and limits can still represent whatever semantically meaningful "thing" they want.
I have a few questions:
- How does the NSM track which hardware on the node is in-use? Or does the init container ask for a specific device?
- How easy is it to extend this model to new hardware devices and vendors? Do they each need to contribute to your project for k8s to support their device?
- Have you given any thought to how the user-experience can be improved? Needing to add an init-container + configmap seems less than ideal. Can this be accomplished with a mutating admission controller?
There was a problem hiding this comment.
+1 to the questions @dashpole raised. The presentation mentioned that currently a configMap is used to map individual deviceId to the resourceName that NSM wants to export. I think this model perhaps works well in a static environment where nodes in the cluster and their resources are mostly static. When we move to the more dynamic environments, this model may start to hit certain limitations. At that time, certain optimizations like a central controller that watches for devices and their properties, and automatically maps deviceId to the matching resourceName according to some abstract property constraints may become necessary. In that sense, the current new Resource API proposal may become relevant. Interestingly, we did consider the model of exporting matching resourceName through node.status capacity/allocatable to minimize the API change at the beginning of the new Resource API work. The exception is that we were considering to have Kubelet perform the matching since it has better knowledge on device allocation and pod life cycle, and so can handle matching changes more smoothly. The feedback we got at the time from @vishh was that resources exported through node.status should be based on actual hardware configurations, which I think is a very valid point. E.g., quite likely I think there are already some existing monitoring services that are making their monitoring/alerting decisions based on these fields, and it would be challenging for them to adapt to the model that node now exports resources based on some user-configured names.
There was a problem hiding this comment.
Ed and I spoke offline. The answers to the questions are:
- How does the NSM track which hardware on the node is in-use? Or does the init container ask for a specific device?
- The chosen device is passed to the init container using ENV variables set by the device plugin during
Allocate. This way, the accounting is done by the kubelet by choosing a valid device, and the init container + NSM just have to make the device available within the container.
- The chosen device is passed to the init container using ENV variables set by the device plugin during
- How easy is it to extend this model to new hardware devices and vendors? Do they each need to contribute to your project for k8s to support their device?
- Network devices are unlike GPUs in the sense that network devices from different vendors can all be covered by the same model. For example, a solution that works for one NIC should work for all NICs.
- Have you given any thought to how the user-experience can be improved? Needing to add an init-container + configmap seems less than ideal. Can this be accomplished with a mutating admission controller?
- They are looking into using Mutating Admission Controllers to put the init container in relevant pods. The configmap contains the Network Services required by the pod, and is used for the request sent from the init container to the NSM to specify the Network Services required. Note that Network Services are not exclusively physical devices backed by a device plugin. Many Network Services are cluster-level, or are not limited in the number of pods that can consume them. They do not put such services in requests and limits to avoid advertising tons of variations of virtual resources on each node. It is theoretically possible to not require a configmap for Network Services backed by a device plugin (as the device plugin could use ENV variables to pass this information), but they need the configmap for all other Network Services...
There was a problem hiding this comment.
@edwarnicke @vishh @vikaschoudhary16 I believe there are many open question and scenarios regarding NSM model. But I believe this forum is not a place to discuss on it. I am quite think, it is a complex model for the Kubernetes Networking person to just get a network attachment and use that for a services.
Architecture is getting the Pod Network namespace(using docker proccess) from Init container and give it as a the request connection and then attaching it back to pod network namespace.
Getting the network namespace from a Init container is not a ideal way of doing networking in Kubernetes.
There was a problem hiding this comment.
@rkamudhan I strongly agree that we should discuss about it in wider place because this discussion is not a review, architecture discussion of Kubernetes, I feel. In addition to this, this is very strongly related to NETWORK (for container users, not for network engineers) so we should bring this topic in another table as design/architecture discussion.
There was a problem hiding this comment.
i feel like this is tangential to the core use case which was monitoring.
@derekwaynecarr totally agree.
There was a problem hiding this comment.
@s1061123 I really don't want to get into model vs model conversation :). This won't help us. Because all the deployment model is not the same, architecture or design approach is different. Apart from the discussion on models, we want the standards and APIs are best approach going forward in Kubernetes. Without APIs, all will be a workaround to fix the things - "slackly"
There was a problem hiding this comment.
@vikaschoudhary16 @dashpole @vishh @derekwaynecarr @edwarnicke
From the conversation, I just got top 4 items, which is relevant to use case.
- Recording a device in the pod specific.
- Checkpoint file is only there to support node reboot and build local allocation state in the kubelet, In doing so, checkpoint file is causing some known issues. once there is some other way(may be this proposal) of doing this, checkpoint file will be deprecated - link for the Device plugin resource lifecycle improvement
- we want to expose these device information outside of kubernetes to get the metrics for operation of system, monitoring and telemetry (service assurance)
- we required one standard way of doing it.
In some sense, it has nothing to do with networking
NSM or CNI should not be conversation for this proposal
Networking should not be a scope for this proposal
Kubernetes Networking is hacked by multi-ways today(overkilled), better leave it to Kubernetes Network SIG group
|
|
||
| * To enable node monitoring agents to determine the set of devices that are in-use, and to obtain metadata about the container/pod using them. | ||
| * To enable consumption of network devices without direct coordination between CNI and Device Plugins. | ||
| * To enable pre-assignment of devices at scheduling time. |
There was a problem hiding this comment.
This is to allow custom scheduler to assign specific devices.
@dashpole would like to share you thoughts as well on this?
There was a problem hiding this comment.
I consolidated this and the networking objective in an "enable experimental out-of-tree use-cases" objective.
|
|
||
| ## Non-Objectives | ||
|
|
||
| * To define end-to-end model and user-story for network device plugins. Networks are pod-level objects but device assignment is container-level concept, therefore this requires further discussion outside the scope of this proposal. Though changes proposed here should be seen as a building block for designing and unblocking further innovations. |
There was a problem hiding this comment.
I find it an anti-pattern to introduce a core (v1) API change when the user-story for the feature (network device plugin) is still a WIP.
There was a problem hiding this comment.
I believe the main user story is to enable device plugin monitoring
There was a problem hiding this comment.
Then let's not mention this use case.
There was a problem hiding this comment.
Changes proposed in this proposal will help unblocking network device plugins as well. Therefore it is mentioned in the use-cases. But to have a nice complete solution for network device plugins, another problem that needs to be solved is pod-level resources which we dont have yet. However, this problem is still manageable and is not big enough to stop any experimentation or PoCs. This proposal partly solves network device plugins problem and provides a way to move further.
| * As a _Cluster Administrator_, I provide a set of devices from various vendors in my cluster. Each vendor independently maintains their own agent, so I run monitoring agents only for devices I provide. Each agent adheres to to the [node monitoring guidelines](https://docs.google.com/document/d/1_CdNWIjPBqVDMvu82aJICQsSCbh2BR-y9a8uXjQm4TI/edit?usp=sharing), so I can use a compatible monitoring pipeline to collect and analyze metrics from a variety of agents, even though they are maintained by different vendors. | ||
| * As a _Device Vendor_, I manufacture devices and I have deep domain expertise in how to run and monitor them. Because I maintain my own Device Plugin implementation, as well as Device Monitoring Agent, I can provide consumers of my devices an easy way to consume and monitor my devices without requiring open-source contributions. The Device Monitoring Agent doesn't have any dependencies on the Device Plugin, so I can decouple monitoring from device lifecycle management. My Device Monitoring Agent works by periodically querying the `/pods` endpoint to discover which devices are being used, and to get the container/pod metadata associated with the metrics: | ||
|
|
||
| 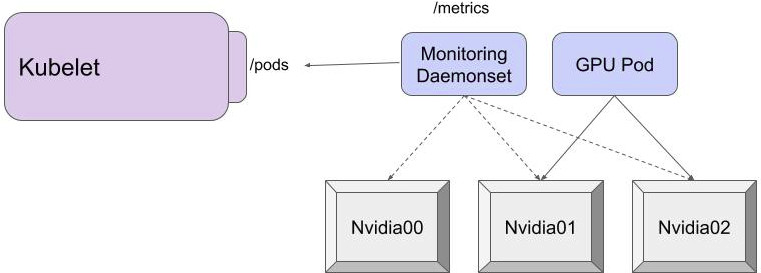 |
There was a problem hiding this comment.
The image seems to indicate that Nvidia GPUs are the only HW that would benefit from this feature. Is that the case?
Has Nvidia explored the viability of this feature?
What other alternatives have we considered that doesn't involve an API change?
There was a problem hiding this comment.
That is not the case. Since we expect devices to be identifiable by their device ID, this model will work for any device. I will update the image, and see if we can construct a more detailed example of how monitoring would work for other devices.
Ill let @RenaudWasTaken to speak on the viability of this feature.
Ill add an alternatives section and cc you in a comment.
There was a problem hiding this comment.
Has Nvidia explored the viability of this feature?
Yes, we are working on a POC using @dashpole's branch
|
|
||
| ### Guaranteed Device Scheduling | ||
|
|
||
| * As a _Cluster Admin and Application Developer_, I have a workload with strict requirements about the set of devices it is assigned that cannot be expressed with current kubernetes APIs (e.g. numa topology requirements). If my workload is assigned to a node that has the devices I need, but not in the correct configuration, my workloads performance suffers considerably. Thus, the node's best-effort attempt to provide a "good" set of devices is not enough to meet the needs of my workload. I can run a custom scheduler to assign devices to containers during scheduling, and can _guarantee_ that the set of devices the workload is assigned meets my requirements. |
There was a problem hiding this comment.
We explicitly do not want to expose users to NUMA and other HW intricacies (cc @thockin).
Our APIs do not differentiate between end user and system components. How would we prevent end users from asking for specific devices? This also feels like a slippery slope towards allowing users to request specific CPU sockets and/or NUMA banks.
If a custom scheduler is used, perhaps we need extensions to k'let's device scheduling policy as well to allow for topology aware scheduling?
There was a problem hiding this comment.
This proposal does not expose NUMA topology, or other HW intricacies any more than they are already exposed today. If anything, this proposal pushes any cluster-level topology solutions out-of-tree.
Users could, in theory, select a specific device for their pod, just as they could select a specific node. We should document that this is not recommended.
One assumption implicit in this proposal and in the current device plugin design is that devices are assumed to be stateful, and cannot be "swapped" to a different container after being assigned to the initial container. Thus, making a permanent binding between device and container does not limit us as long as this assumption holds. The fact that the binding is permanent is also the reason why cluster-level scheduling is appealing: if devices could be swapped, then we could (eventually) expect the kubelet to "shuffle" devices to ensure pods have a reasonable set of devices assigned at all times. CPUs and memory banks do not have this property, and thus should not be explicitly bound to a container.
My understanding is that topology awareness internal to the kubelet is something the kubernetes community plans to tackle in the future. I agree that performance gains from device topology awareness rely in part on the kubelet's ability to assign sensible CPUs (assuming they are using CPU pinning). Initially, this would likely only serve some of the lower-hanging-fruit use-cases, such as directly linked GPU cards.
There was a problem hiding this comment.
Why don't you place the Device ID in the pod Status then? A pod with no device ID specified can get attached to different nodes across node reboots and that change is OK if device ID is a "Status" property.
There was a problem hiding this comment.
I consider the fact that device ID cannot change to be a positive, rather than a downside, as it is a simplifying assumption for agents that consume the information. It would be more complicated to implement, for example, a GPU monitoring agent if had to assume each container could be re-bound to a different GPU.
I was not aware that pods could be reassigned to a different node if the node it is currently on reboots. Ill have to talk to @bsalamat about that and figure out what the correct behavior is.
I generally prefer spec over status (although I can add it as an alternative) because status should be observable from the node.
There was a problem hiding this comment.
A pod once bound to a node cannot move across nodes. But the node a pod is currently attached to can be reset and kubelet can assign new devices the set of pods that are already bound to that node as part of readmission. If the device is part of Spec then it is not possible to alter the assignment after a reboot. Perhaps you see device assignment being static as a feature?
Monitoring systems should ideally adapt to changes in device assignment. I don't see why monitoring agents would influence the design of Spec vs Status.
| } | ||
| ``` | ||
|
|
||
| To be able to initialize/update `ComputeDevices`, a new verb, `BindResource()`, will be defined for binding `ResourceBinding` objects with a pod object: |
There was a problem hiding this comment.
I assume this is a new verb to the pod API. Have you considered using a CRD instead?
There was a problem hiding this comment.
I have not considered it, but I am open to the idea. What are the advantages of using a CRD?
At first glance, it seems odd to me to have a CRD be used by core components (kubelet). It doesn't seem to fit with the description of a CRD in our docs either:
A custom resource is an extension of the Kubernetes API that is not necessarily available on every Kubernetes cluster. In other words, it represents a customization of a particular Kubernetes installation.
There was a problem hiding this comment.
Alpha fields seem to be having issues still (@thockin was talking about it earlier today). One of Tim's ideas was to create a CRD per pod that uses extended devices with the same name and namespace that includes device properties like Device ID.
There was a problem hiding this comment.
CRD per pod that uses extended devices -- What does it mean by CRD "uses" extended resources?
Just thinking loud, CRD object being proposed to create just to hold some pod metadata.
@vish can you please elaborate a bit more on what a CRD will look like and what it would hold?
There was a problem hiding this comment.
@vishh I think the CRD approach could be quite clean here without having to change existing APIs. A slight variation of the NSM pattern would do it for you (without the networky-ness).
You could have a CRD that has a 'CRDname' and represents (resourceName, deviceId). Your Device Plugin could advertise that 'CRDname' as a resource, and then scheduling etc would work out in the normal way. Note: in the absense of 'networky-ness' (or other late binding concern) you don't need an initContainer in this senario.
This approach also allows for much much more flexible experimentation, as you could put all kinds of other things in the CRD. For example (resourceName, DeviceId) as in this proposal is likely not unique at the cluster level. If you hit a use case where that's an issue, it becomes easy to add something to disambiguate to the CRD.
As to monitoring... your DevicePlugin could put monitoring data into a CRD as well. Given that what is interesting from a Monitoring approach is likely broader than (resourceName, DeviceID), this is likely to be a better approach as well.
Thoughts?
There was a problem hiding this comment.
@edwarnicke without init container how pod-id will be be updated at CRD object? How monitoring agent will figure out for a particular pod which CRD object is associated?
There was a problem hiding this comment.
i am not following the CRD approach. this introduces another resource that the kubelet needs to list/watch and update. we are already discussing a number of other resources that the kubelet would list/watch update, that i am starting to get concerned we will hit scale concerns.
There was a problem hiding this comment.
Here's a thread on sig-arch on a closely related topic - https://groups.google.com/forum/#!msg/kubernetes-sig-architecture/y9FulL9Uq6A/mCEKZpLyAQAJ
@derekwaynecarr the main question to answer is how do we add fields to existing v1 API objects with sub-field versioning. Alpha fields are the current guidance, but they have some limitations. shadow CRDs seem to work for use cases. A recent example is health checks.
@edwarnicke point was that a CRD might provide leeway to introduce more introspection fields in the future with minimal overhead.
I do see the drawbacks of kubelet writing to more and more objects.
I think one question that might help make decision here is if we foresee more attributes being exposed in addition to device ID in the future from the kubelet (or via it).
There was a problem hiding this comment.
@vishh One other thing to keep in mind... it sounds like we are dealing with a mix of two things:
- Checkpointing for Kubelet
- Operational Data for Monitoring things
Using the Pod.spec for checkpointing, while not unprecedented, does feel a bit wrong to me. Having a separate CRD also allows us to express what is essentially operational state more clearly. For example it could allow Kubelet to expressed checkpointing information and real operational status clearly. It also allows this to be a properly alpha thing, while we all gain operational experience with it and inevitably realize it needs to evolve as we learn.
There was a problem hiding this comment.
@edwarnicke seems you missed my query above, #2454 (comment) :)
|
|
||
| #### Updating `ComputeDevices` in the pod spec at api server | ||
|
|
||
| After pod admission but before starting the pod, from within `syncPod()`, Kubelet will invoke `GetResourceBindings` to get device allocation details from the device manager. Next, using `BindResource` subresource device assignment will be updated at apiserver: |
There was a problem hiding this comment.
This may considerably slow down pod startup latency. Think of QPS limitations on a large node with high churn of pods.
This limitation needs to be called out explicitly and possibly tested in a scale out scenario as well.
There was a problem hiding this comment.
I added a note here. If the proposal progresses, I'll do some scale testing.
There was a problem hiding this comment.
If this adds unacceptable latency, a workaround could be to preserve the on-disk checkpoint and batch the writes as part of the sync loop (e.g. track a dirty bit per pod).
|
/assign @jiayingz |
|
+1 for #2454 (comment) |
04b7dee to
f0ed7e9
Compare
| } | ||
| ``` | ||
|
|
||
| NOTE: Writing to the Api Server and waiting to observe the updated pod spec in the kubelet's pod watch may add significant latenct to pod startup. |
| ComputeDevices []ComputeDevice | ||
| } | ||
| ``` | ||
| `client-go` will be extended to support `BindResource` verb/subresource and also changes will be made in `pkg/registry/core` to handle `POST`ing of `ResourceBinding` object and eventually updating `ComputeDevices` in the pod spec's containers. |
There was a problem hiding this comment.
Just curious, what are the use cases for updating after the initial binding? This seems like something that may or may not work for various classes of compute device.
There was a problem hiding this comment.
Or does this update refer to the step of copying the compute resources from the binding to the container?
There was a problem hiding this comment.
This update refers to the step of copying the compute resources from the binding to the container. We should probably validate that devices cannot be removed (and thus cannot be changed to a different device).
|
@vishh I added a section on alternatives I considered, and detail which problems they solve, and which are left unsolved. |
|
I am fine with what is proposed. I think it solves the problem with the least amount of global impact. /lgtm |
|
I will let @vishh weigh in for final approve. |
|
|
||
| ## Alternatives Considered | ||
|
|
||
| ### Add a `ContainerConfig` function to the CRI, which returns the [CreateContainerRequest](https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/cri/runtime/v1alpha2/api.proto#L734) used to create the container. |
There was a problem hiding this comment.
How are devices being passed down from the kubelet to the runtimes today if CRi doesn't support specifying devices explicitly? If kubelet can expose to monitoring agents the config blob that it passes down to runtimes, that might be another alternate endpoint you can expose instead of manually curating a separate endpoint.
There was a problem hiding this comment.
CRI does support specifying devices directly: https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/cri/runtime/v1alpha2/api.proto#L670. But the kubelet doesn't keep that information around. We would have to persist (checkpoint) this in order to support such an endpoint. While it is nice not to need to curate another API, I personally prefer a more limited API that does not require checkpointing additional information.
There was a problem hiding this comment.
If the kubelet isn't checkpointing, then it presumably has some meant to determinisitically regenerate this data?
There was a problem hiding this comment.
True, we could regenerate this data.
There was a problem hiding this comment.
Ok. So in that case the rationale for exposing an alternate endpoint would be:
- Restrict what data plugins can access - the policy around this is unclear - what information is considered to be sensitive?
- Deluge of information on the plugin side - is that really a problem given you are embracing protobufs which should reduce the memory requirements on the plugin side?
- Virtual device IDs used by kubelet will not be available; instead logical character device file paths will be available which could potentially confuse plugin monitoring authors.
There was a problem hiding this comment.
I updated this section to take this into account. I still would rather define a new API, since the ContainerConfig doesn't have much of what we need outside of device information.
There was a problem hiding this comment.
I trust your instinct. Thanks for being precise about the design considerations.
There was a problem hiding this comment.
- It isn't about information, it is about the ability to create containers. Anyone with access to the CRI socket can create containers, which is effectively root on the node.
- Isn't an issue.
- More of a minor issue.
|
@derekwaynecarr this proposal LGTM. |
|
|
||
| ## Changes | ||
|
|
||
| Add a v1alpha1 Kubelet GRPC service, at `/var/lib/kubelet/pod-resources/kubelet.sock`, which returns information about the kubelet's assignment of devices to containers. It obtains this information from the internal state of the kubelet's Device Manager. The GRPC Service returns a single PodResourcesResponse, which is shown in proto below: |
There was a problem hiding this comment.
Is this a pattern we are following elsewhere - GRPC over UNIX socket via a named socket-file?
Is there an established pattern for "I want to talk to my local kubelet" ?
There was a problem hiding this comment.
The pattern thus far for components that talk to the kubelet is to use grpc over unix sockets, or to use the read-only port. The only examples I am aware of are all plugins (CRI, Device Plugin, CSI, etc), which are all grpc-based.
There was a problem hiding this comment.
The concern is that this requires hostPath which many would rather have disabled entirely. We should probably think about a first-class way of accessing "my kubelet" that doesn't rely on that. Maybe even a new volume type that exposes these UNIX files, or something.
I would love a volunteer to help drive that brainstorm...
| * Does not include any reference to resource names. Monitoring agentes must identify devices by the device or environment variables passed to the pod or container. | ||
|
|
||
| ### Add a field to Pod Status. | ||
| * Allows for observation of container to device bindings local to the node through the `/pods` endpoint |
|
As @guptaNswati, who is working on the NVidia monitoring daemonset, mentioned in Sig-node this week, using GRPC is difficult given their current implementation. I think we should consider an HTTP endpoint, as that would be easier for them to consume. I have updated the proposal to this effect, and you can see the implementation here. |
|
I think doing a HTTP endpoint will make it easier to consume this information for any device vendors and not just us. Adding a new GRPC server for just pod devices or volumes information seems unnecessary and would involve every vendor to write their own clients. |
How so? grpc has a built in client generator for many languages. Can you describe why an http API would be easier/preferred especially for metrics where serializing json metric field names repeatedly would be wasteful and potentially a noticeable resource overhead. |
Do you mind detailing a bit the performance gains that gRPC is allowing the Kubelet to save and provide some context on the limit we are trying to reach performance wise? To reword a bit, do we think this change will really be a performance sink for Kubelet? |
For many but not all :) especially doing gRPC from bash will be painful and on top of that we would have to write our own json converter. To give you more context, our monitoring solution dcgm-exporter is a shell script which calls NVIDIA DCGM and can be run inside or outside of k8s. |
e5f056f to
060a25c
Compare
|
I was able to use the |
|
Overall we support this feature and have no major issues with the KEP in it's current shape. The only point of contention we had was JSON over gRPC. However we don't have a strong opinion on this and in the interest of time and in the interest of making this feature available to end users, we support this KEP being merged. /lgtm |
|
/approve
…On Sat, Nov 10, 2018, 1:13 PM Renaud Gaubert ***@***.*** wrote:
Overall we support this feature and have no major issues with the KEP in
it's current shape. The only point of contention we had was JSON over gRPC.
However we don't have a strong opinion on this and in the interest of time
and in the interest of making this feature available to end users, we
support this KEP being merged.
/lgtm
—
You are receiving this because you were assigned.
Reply to this email directly, view it on GitHub
<#2454 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AFVgVPRLN2AKg0F0hm_iMfngaISqkH2aks5ut0FngaJpZM4VrsP0>
.
|
|
/approve |
|
[APPROVALNOTIFIER] This PR is APPROVED This pull-request has been approved by: derekwaynecarr, thockin, vishh The full list of commands accepted by this bot can be found here. The pull request process is described here
Needs approval from an approver in each of these files:
Approvers can indicate their approval by writing |
KEP: Support Device Monitoring
/cc @kubernetes/sig-node-api-reviews @kubernetes/sig-node-proposals @dashpole @derekwaynecarr @dchen1107 @jiayingz @thockin @vishh @sjenning @jeremyeder
/sig node