Engine Multi Display
Some video platforms support display management in terms of multiple displays and resolution switching, primarily available in video platforms that deal with lower-level interfaces e.g. egl-dri.
The following figure is an overview of the different layers and interfaces involved:
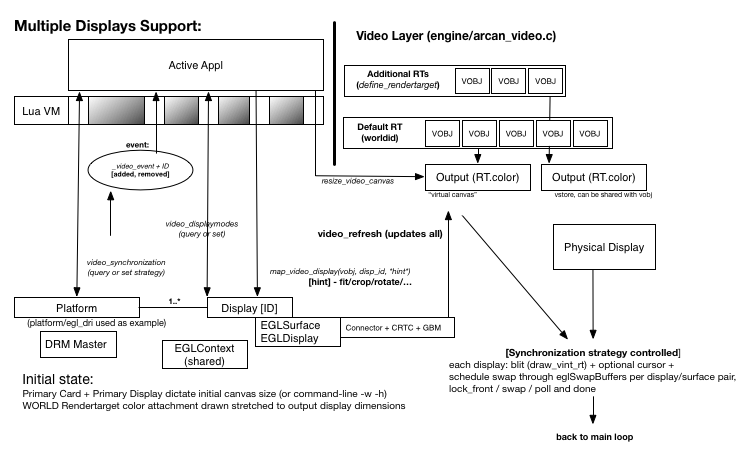
See durden/display source for an example on how it can be used in practice.
What is worth noting is the render-model and which parts of the engine that are responsible. The main render pipe draws to a primary rendertarget (projection matrix, output video storage, details on refresh rates, readback options, etc.) that we refer to as WORLDID. This rendering is done in src/engine/arcan_video.c but this is initiated and controlled by platform/activeplatform/video.c. Depending on the video platform and hardware, this is performed on an off-screen buffer and then forwarded to some output (scanout) buffer that the underlying hardware can deal with, or (if possible) drawn on the output buffer directly.
A rendertarget can be seen as an invisible canvas (in GL terms, a color
attachment in a FBO), where the primary rendertarget has dimensions that are
set to the options specified on the command-line using the -w and -h arguments
or, if those are set to invalid values, a video platform default. This canvas
can be resized by calling resize_video_canvas which do not have to match the
dimensions of the underlying display, giving us a lower or higher internal
resolution to work with.
The key is that the running appl can change which video object, rendertarget or
video storage that is being mapped to which display using map_video_display.
To do this it also needs to point out which display it is that should be the
recipient. The semantics of this ID is implementation defined in the video
platform, but there are two options for figuring it out:
-
writing a
display_eventhandler (which works similarly to input andclock_pulsein that you prefix the handler name with the name of the appl) -
by calling
list_video_outputs.
By calling video_displaymodes with no arguments, you initiate a scan of
available cards, connected monitors, supported solutions and refresh rates. In
this list are id fields used to address output displays individually and is a
required argument when calling map_video_display. These id fields can also be
used in additional calls to video_displaymodes in order to switch output
resolution. This manual polling approach with display modes is necessary as not
all multi-display capable video platforms support hotplug detection, or do so
using interfaces that are, politely put, pure garbage. Note that such a scan
may stall the video device for long periods (100-200+ ms) and should only be
used at the request of the user.
The platform layer extracts some EDID data, and others have to be extracted in-script, although there is nothing strictly enforcing that the reported screen density has to be used, partly thanks to bad KVMs, broken monitors and similar devices that make such reports very unreliable.
The API provides target_displayhint for telling a frameserver about the current display properties which, of course, don't have to match the active display. Note that density is expressed in PPCM rather than DPI. There is also target_fonthint which is used to provide fonts and suggest desired font size, hinting, fallbacks in case of missing glyphs and so on. These two features combined should make it possible for a client to correctly rasterises vectorized contents.
For the scripts running on Arcan itself, all created visual resources has a primary attachment (rendertarget). When text is updated or create, or when a vectorised source image is loaded, it will be rasterised according to the density properties of the currently active primary attachment. If the attachment changes via the rendertarget_attach or the rendertarget_detach calls, the resource will be re-rasterised to match the density of the new target, assuming there is enough available memory to do so. For the low-level multidisplay case, this means that you create a rendertarget per display, and simply set the density properties in according with the display.
A special case is contents that is supposed to exist on multiple outputs with different target densities. This case is currently only "supported" by picking the higher resolution one and let the engine scale accordingly, which is suboptimal. The other option that is being evaluated is to let the server force-push an alternate output segment, pushing the client to rasterise at both densities, with the added problem that layouting and so-on may well be different or incompatible.
The last key factor in display management is the rules that control the conditions for when the display and its mapped objects should be updated. This is a process where there does not exist a 'one size fits all' solution as they all involve trade-offs between parameters e.g. memory bandwidth consumption and latencies, where some scenarios (low power management) would favour sacrificing latency in order to reduce bandwidth and some (highly interactive or graphically intense applications and games) would favour latency over bandwidth, or sacrifice both in order to reduce energy consumption.
To approach this problem, we have opted for providing synchronization
strategies. The set of those that are available is defined by the active video
platform back-end, but they can also be probed and set dynamically using
video_synchronization (and statically from the command-line with -W). Not
many of these strategies have been defined at the moment, awaiting
experimentation with alternative hardware synchronization protocols e.g. G-Sync
and FreeSync.
When updating a display mapping, you can also specify a flag for making the display part of the primary synch group. This is to indicate which displays it is that we will wait for vblank on, and is particularly important when displays of widely varying refresh rates are being used.
Then we have the option of controlling when the actual frames are synched from a frameserver to the main arcan process, and when the corresponding rendertargets are being updated. For controlling frameserver behavior, we have:
For rendertargets, there is a clock argument (per n ticks, per n frames or manually) for when the rendertarget should be refreshed. For manually stepping frameservers, there is:
and for manually updating rendertargets, there is:
This part is still undergoing some necessary refactoring and preparation for handling all the different possible combinations of hotplugging, single- output multiple-producer, multiple-outputs multiple-producers, load balancing etc.
Going through the current (rough) state:
- Running multiple Arcan instances, one tied to each GPU, with distinct connection points [working]
This has the caveat of manually assigning which devices should go where (or have appls that can toggle input interpretation on/off, durden does this). They should not fight over the same ARCAN_CONNPATH either. Connected clients can be instructed to migrate between the different instances using target_devicehint(experimental).
- One Arcan instance, one GPU composites and manages displays, and others produce content.
This is partly working in that when arcan_lwa, afsrv_game and others access GPUs, you can specify which render node to use for each process. This can also be switched dynamically with the target_devicehint call. Caveats are that the output buffer handles from one GPU cannot easily be interpreted by the others. In those cases, handle passing can explicitly be disabled on a per-target basis, and the backend would readback into the shared memory page and re-stream to the compositing GPU (see target_flags)
- at a very high cost.
- One Arcan instance, switching from one active GPU to another.
This has many nasty edge conditions, since the capabilities of the different GPUs may vary wildly. For connected frameservers, the process is similar to 2, where we first hint the device as LOST. Then, in the main arcan process, we simulate an external suspend. This feature requires that the graphics layer (AGP, for GL etc.) is capable of completely serializing on-GPU stored assets and that there's space locally for that to succeed. Then we switch to the new GPU, rebuild the on-GPU store there. If that goes successful, we start re-activating frameservers with a displayhint to assign the new render node. Finally, propagate a display reset (similar to VT switch) event to the running appl.
The problem with the rendertarget- approach comes from some limitations on FBO that risk costing a full extra buffer/blit step or making the appl- layer code more expensive, this isn't acceptable in the long run.
What's missing for a lower bandwidth approach is the ability to specify coordinate spaces and mapping, then run the render-pass per GPU/display (possibly threaded, though there are some caching issues with that).
Since this is sensitive to the upcoming Vulkan AGP backend, it's better to wait for that step to finish.
There is a somewhat hidden way of experimenting with multiple monitor support
without having to physically have such a setup or repeatedly torturing it by
plugging monitors in and out, and that is by using arcan_lwa.
If the running appl explicitly pushes a new subsegment to a connected arcan_lwa process using target_alloc with the LWA- associated vid as argument, the new segment will be registered as a new monitor / display output. By running the interactive test mdispwm on a normal arcan session and connecting an arcan_lwa instance to it, you can use the mdispwm session to dynamically create and remove displays.