UniTAB: Unifying Text and Box Outputs for Grounded Vision-Language Modeling
by Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Faisal Ahmed, Zicheng Liu, Yumao Lu, Lijuan Wang
European Conference on Computer Vision, 2022, Oral Presentation
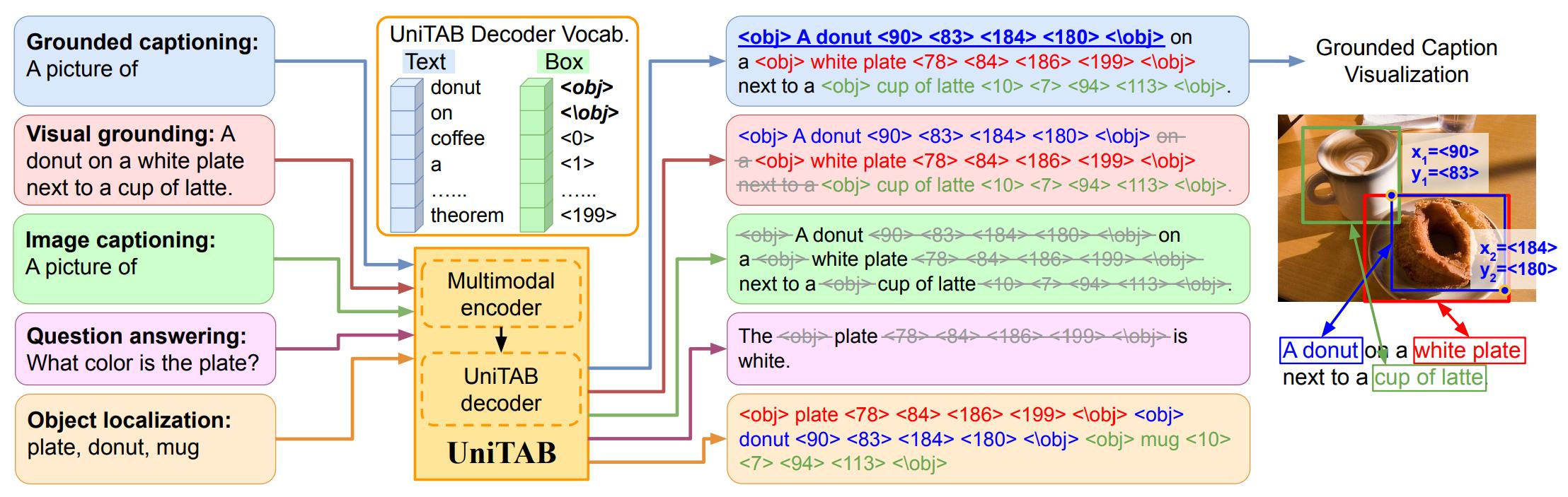
We propose UniTAB, a vision-language (VL) model that unifies text generation and bounding box prediction into a single architecture. For more details, please refer to our paper.
@inproceedings{yang2022unitab,
title={UniTAB: Unifying Text and Box Outputs for Grounded Vision-Language Modeling},
author={Yang, Zhengyuan and Gan, Zhe and Wang, Jianfeng and Hu, Xiaowei and Ahmed, Faisal and Liu, Zicheng and Lu, Yumao and Wang, Lijuan},
booktitle={ECCV},
year={2022}
}
Clone the repository:
git clone https://github.com/microsoft/UniTAB.git
cd UniTAB
New conda env:
conda create -n unitab python=3.8
conda activate unitab
Install packages in requirements.txt (separately install numpy and pytorch (LTS 1.8.2) if fails):
pip install -r requirements.txt
We recommend using the following AzCopy command to download. AzCopy executable tools can be downloaded here.
Example command:
path/to/azcopy copy <folder-link> <target-address> --resursive"
# For example:
path/to/azcopy copy https://unitab.blob.core.windows.net/data/data <local_path> --recursive
path/to/azcopy copy https://unitab.blob.core.windows.net/data/weights <local_path> --recursive
path/to/azcopy copy https://unitab.blob.core.windows.net/data/annotations <local_path> --recursive
We do not specify distributed training tool in the example commands below. Pytorch distributed python -m torch.distributed.launch --nproc_per_node=8 --use_env main.py or submitit supported. Or update util/dist.py/init_distributed_mode() to fit your cluster setting.
- Download the original Flickr30k image dataset from : Flickr30K webpage and update the
flickr_img_pathto the folder containing the images. - Download the original Flickr30k entities annotations from: Flickr30k annotations and update the
flickr_dataset_pathto the folder with annotations. - Download the gqa images at GQA images and update
vg_img_pathto point to the folder containing the images. - Download COCO images Coco train2014. Update the
coco_pathto the folder containing the downloaded images.
Or download the cached data (~77G) (use AzCopy with the link).
- Download our pre-processed annotations (~3.7G) (use AzCopy with the link, or zip file) and update the
flickr_ann_path,gqa_ann_pathandrefexp_ann_pathto this folder with pre-processed annotations.
The config file for pretraining is configs/pretrain.json. Optionally starting from MDETR pretrain with --load https://zenodo.org/record/4721981/files/pretrained_resnet101_checkpoint.pth. Weights availble here.
Example command (ngpu=64):
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/pretrain.json --batch_size 2 --lr_backbone 2e-5 --text_encoder_lr 2e-5 --lr 1e-4 --num_queries 200 --max_decoding_step 256 --do_caption --no_detection --unitab_pretrain --pretrain_seqcrop mixed --ema --output-dir weights/$exp_id --load https://zenodo.org/record/4721981/files/pretrained_resnet101_checkpoint.pth
The config file for pretraining is configs/multitask.json. Weights availble here.
Example command (ngpu=32):
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/multitask.json --batch_size 2 --lr_backbone 1e-5 --text_encoder_lr 1e-5 --lr 5e-5 --num_queries 200 --max_decoding_step 256 --load weights/pretrained_checkpoint.pth --ema --output-dir weights/$exp_id
Optionally, downloading all weights at once (~54G):
path/to/azcopy copy https://unitab.blob.core.windows.net/data/weights <local_path> --recursive
For model inference, use the input arguments --eval --test. For captioning tests (Flickr grounded captioning, COCO image captioning, VQAv2 visual question answering), the computed captioning metrics displayed is only for reference. For the final number, an output prediction json file will be automatically stored at weights/$exp_id/results/pred_dict_$CIDEr.json. Please follow the official evaluation for Flickr grounded captioning, COCO captioning, and VQAv2 evaluation. We will better intergrate the caption evaluations in future versions.
The config file for pretraining is configs/flickr_kp.json. For model inference, use the input arguments --eval --test.
For the final number, an output prediction json file will be automatically stored at weights/$exp_id/results/pred_dict_$CIDEr.json. Please follow the official evaluation for Flickr grounded captioning evaluation. We will better intergrate the caption evaluations in future versions.
Weights: Separate, Pre-finetuning.
| Model | CIDEr | F1_all |
|---|---|---|
| Separate | 65.6 | 11.46 |
| Pre-finetuning | 69.7 | 12.95 |
Example command (ngpu=8):
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/flickr_kp.json --batch_size 2 --lr_backbone 1e-5 --text_encoder_lr 1e-5 --lr 1e-4 --num_queries 200 --max_decoding_step 256 --do_caption --no_detection --ema --output-dir weights/$exp_id --load weights/pretrained_checkpoint.pth
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/flickr_kp.json --batch_size 2 --lr_backbone 1e-5 --text_encoder_lr 1e-5 --lr 1e-4 --num_queries 200 --max_decoding_step 256 --do_caption --no_detection --ema --output-dir weights/$exp_id --load weights/prefinetune_flickrcaptionKP_checkpoint.pth --eval --test
The config file for pretraining is configs/refcoco/+/g.json. For model inference, use the input arguments --eval --test --test_type testA/testB/test.
Weights: Separate, Pre-finetuning (refcoco/refcoco+/refcocog).
| Model | Refcoco | Refcoco+ | Refcocog |
|---|---|---|---|
| Separate | 86.32 | 78.70 | 79.96 |
| Pre-finetuning | 88.59 | 80.97 | 84.58 |
Example command (ngpu=8):
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/refcoco.json --batch_size 2 --lr_backbone 1e-5 --text_encoder_lr 5e-5 --lr 1e-4 --num_queries 200 --max_decoding_step 256 --ema --output-dir weights/$exp_id --load weights/pretrained_checkpoint.pth
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/refcoco.json --batch_size 2 --lr_backbone 1e-5 --text_encoder_lr 5e-5 --lr 1e-4 --num_queries 200 --max_decoding_step 256 --ema --output-dir weights/$exp_id --load weights/prefinetune_refcoco_checkpoint.pth --eval --test --test_type testA
The config file for pretraining is configs/flickr.json. For model inference, use the input arguments --eval --test.
Weights: Separate, Pre-finetuning.
| Model | Flickr |
|---|---|
| Separate | 79.39 |
| Pre-finetuning | 79.58 |
Example command (ngpu=8):
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/flickr.json --batch_size 2 --lr_backbone 1e-5 --text_encoder_lr 5e-5 --lr 1e-4 --num_queries 200 --max_decoding_step 256 --ema --do_flickrgrounding --output-dir weights/$exp_id --load weights/pretrained_checkpoint.pth
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/flickr.json --batch_size 2 --lr_backbone 1e-5 --text_encoder_lr 5e-5 --lr 1e-4 --num_queries 200 --max_decoding_step 256 --ema --do_flickrgrounding --output-dir weights/$exp_id --load weights/prefinetune_flickrGrounding_checkpoint.pth --eval --test
The config file for pretraining is configs/flickr_cococaption.json. For model inference, use the input arguments --eval --test.
For the final number, an output prediction json file will be automatically stored at weights/$exp_id/results/pred_dict_$CIDEr.json. Please follow the official evaluation for COCO captioning evaluation. We will better intergrate the caption evaluations in future versions.
Weights: Separate, Pre-finetuning.
| Model | CIDEr |
|---|---|
| Separate | 119.3 |
| Pre-finetuning | 119.8 |
Example command (ngpu=16):
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/flickr_cococaption.json --lr_backbone 2e-5 --text_encoder_lr 2e-5 --lr 1e-4 --num_queries 200 --max_decoding_step 256 --do_caption --no_detection --ema --output-dir weights/$exp_id --load weights/pretrained_checkpoint.pth
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/flickr_cococaption.json --lr_backbone 2e-5 --text_encoder_lr 2e-5 --lr 1e-4 --num_queries 200 --max_decoding_step 256 --do_caption --no_detection --ema --output-dir weights/$exp_id --load weights/prefinetune_MScococaption_checkpoint.pth --eval --test
The config file for pretraining is configs/flickr_vqav2caption.json and configs/flickr_vqav2captionKP.json. Adjust the GT_type between vqav2caption and vqav2captionKP for std and KP splits. For model inference, use the input arguments --eval --test.
For the final number, an output prediction json file will be automatically stored at weights/$exp_id/results/pred_dict_$CIDEr.json. Please follow the official evaluation for VQAv2 evaluation. We will better intergrate the caption evaluations in future versions.
Weights: Separate, Pre-finetuning. KP split: Separate, Pre-finetuning.
| Model | test-dev | KP-test |
|---|---|---|
| Separate | 69.9 | 66.6 |
| Pre-finetuning | 70.7 | 67.5 |
Example command (ngpu=16):
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/flickr_vqav2caption.json --lr_backbone 2e-5 --text_encoder_lr 2e-5 --lr 1e-4 --num_queries 200 --max_decoding_step 256 --do_caption --no_detection --ema --output-dir weights/$exp_id --load weights/pretrained_checkpoint.pth
CUBLAS_WORKSPACE_CONFIG=:4096:8 python main.py --dataset_config configs/flickr_vqav2caption.json --lr_backbone 2e-5 --text_encoder_lr 2e-5 --lr 1e-4 --num_queries 200 --max_decoding_step 256 --do_caption --no_detection --ema --output-dir weights/$exp_id --load weights/prefinetune_VQAv2_checkpoint.pth --eval --test
The project is built based on the following repository:
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.