
This introductory guide aims to provide collaborators with a comprehensive overview of some of the key features of the National Data Platform (NDP). The exploration is complemented by a sample exploratory data analysis and model training. By the end of this tutorial, we will accomplish the following:
- Navigate the data catalog
- Initiate a computing instance
- Perform an analysis using the JupyterHub environment in a high-performance computing instance.
NDP is a federated and extensible data ecosystem to promote collaboration, innovation and equitable use of data on top of existing Cyberinfrastructure (CI) capabilities.
NDP serves as an open-access platform with the goal of reducing barriers to data and technology access, especially for individuals lacking expertise or resources in the field of AI. The platform is designed to cater to both the scientific and academic communities, as well as non-experts interested in exploring AI training. By fostering inclusivity in its user base, NDP aims to enhance the significance of existing data repositories, contributing to advancements in science and education.
To start working with NDP, new contributors must register by clicking on the Log in/Register in the top right of the NDP's home page.
There are 2 ways in which contributors can register to NDP:
- Clicking on the Register link on the bottom of the log in window, and setting up the credentials. Take into consideration that registering with a commercial email account (i.e. Google, Outlook, Yahoo) will not provide access to JupyterHub nor any computing service.
- For users with institutional credentials, it is recommended to access via CI Logon, by clicking on the CI Logon button of the log in window. This will redirect to the CI Logon log in page, in which contributors can search for their institution, and access through ther institutional log in.
Once registered, the user will be redirected to the user dashboard, with the most recent updates and news around NDP.
One of the main features of NDP is the extensive data catalog, which encompasses a variety of datasets and data streams spanning diverse scientific domains. This comprehensive catalog is further enriched by collaboration with various organizations and researchers that contribute to making data accessible through the registration service. This accessibility empowers researchers and learners to engage with the data, fostering the development of innovative analysis, modeling techniques, and applications.

A list and description of the contributing organizations can be displayed by clicking on View Contributing Organizations.

Data location is facilitated through the incorporation of a search engine. There are two types of search the user can perform within data catalog:
- Substring search: This will return a list of datasets with the corresponding substring identified within the file name or the metadata.
- Annotated search: This will return a list of datasets with corresponding annotation, along with a series of statistics related to the matches of the term within the available Open Knowledge Networks.
Plus, users can also filter their results by the contributing organization.
As a starting point, we can type Uniform into the search engine, to locate the Uniform Fuels QUIC-Fire Simulation Runs Ensemble file, which is the data used for the demon project. Once the dataset is identified, clicking on View More will open a window with the following information:
- A comprehensive description detailing the content of the dataset.
- A list of all supplementary files along with metadata information.

Another feature is the incorporation of visualization tools for certain data formats. For example, you can search GrandCanyon and click on View More for the AZ_GrandCanyonNP_1_2019 file. You will see both a Potree visualization and a GeoJSON viewer for this Lidar scan.

The Open Knowledge Network catalog features the collection of Open Knowledge Networks available through NDP. These OKN's are meant to be a resource for the development of NDP services, such as data annotation and LLM training.

The services catalog the current and upcoming services within NDP

NDP allows users to explore and work on data by facilitating access to the NSF's cyberinfrastructure (CI) capabilities. For the case of our demonstration dataset, we are going to connect with Nautilus.
To connect with Nautilus and launch a computational instance, we will start by clicking at the JupyterHub button attached to our dataset, which will redirect us to the JupyterHub environment. To access it, you must provide institutional credentials via CI Logon. Once you log in, you will be redirected to the main site for resources reservation:

One of the main features of NDP is the provision of an user friendly interface which facilitates the creation of a pod. After providing the required specifications, the cluster (which works under the Kubernetes system) orchestrates the creation of a pod, which operates on the allocated hardware resources such as CPU cores, GPUs, and memory. The pod encapsulates the applications contained in the provisioned images, leveraging the specified hardware. Additionally, the server associates a 100GB persistent volume (PV) with the pod, ensuring that the work that we develop is seamlessly stored and persists across various sessions. The persistent volume is identified within the server as the data folder.
To initiate the creation of a pod, we begin by specifying the location, amount, and type of hardware (for the case of GPU). It's important to bear in mind that augmenting the quantity and intricacy of these resources can lead to an extended allocation waiting time. For real-time updates on the availability of resources, we can refer to the Available Resources Page. For the purposes of this tutorial, we set up the following specifications:
- Region: Any
- GPU's: 1
- Cores: 1
- RAM: 16GB
- GPU type: NVIDIA-GeForce-GTX-1080-Ti
Secondly, we have the choice to mount a shared memory folder into our pod, particularly for applications utilizing PyTorch. Since our model training involves the use of the PyTorch library, we must select the checkbox for this feature.
The next component we must select is an appropiate Docker Image tailored for the specific requirements of the project we are working on. This ensures that the server loads all the necessary libraries and dependencies crucial for the project's execution. For this sample tutorial, we have provided an image which will create a directory within JupyterLab with the data and our sample Jupyter Notebooks once will launch our instance. Make sure to select the Physics Guided Machine Learning Starter Code image.
The final aspect of our resource allocation involves selecting the processor architecture. In this case, due to the utilization of CUDA in our example, we must choose an amd64 architecture.
Once our server starts running, we will be redirected to JupyterLab, with our persisted workspace, which in this case includes the folder with our project. In this case, our workspace has set up the working files for our example:

We are going to execute the two notebooks provided in the example. The first one that we are going to open, is NDP_PGML_EDA.ipynb. This notebook provides a simple exploratory data analysis over the Uniform Fuels QUIC-Fire simulation data. The exploratory analysis takes the multiple prescribed fire simulations provided in the dataset, and highlights the evolution of one of the features (fuel moisture) defined under different conditions (wind speed, wind direction, surface moisture).

More details can be found in the notebook.
The second notebook NDP_PGML_UNet.ipynb, contains code to train a model, leveraging on predefined classes that you can explore on the unet directory. Running the notebook will perform the following tasks:
- Load the relevant libraries and sets up de directories to store our results.

- Set up the experiment, with the relevant metrics and parameters.

- Start an experiment session in MLflow to save our model specifications and results.
To facilitate the tracking and history of our training sessions, another important feature of NDP is the integration with MLflow. This integration enables the logging of various training iterations, saving each generated model, along with key hyperparameters, specified metrics and relevant visualitazionts. All this information can be consulted through the MLflow dashboard. In the following image, you will see on the left side the different experiments we have previously executed.

By clicking on the name of the run, we can see the information that we saved for our experiment:
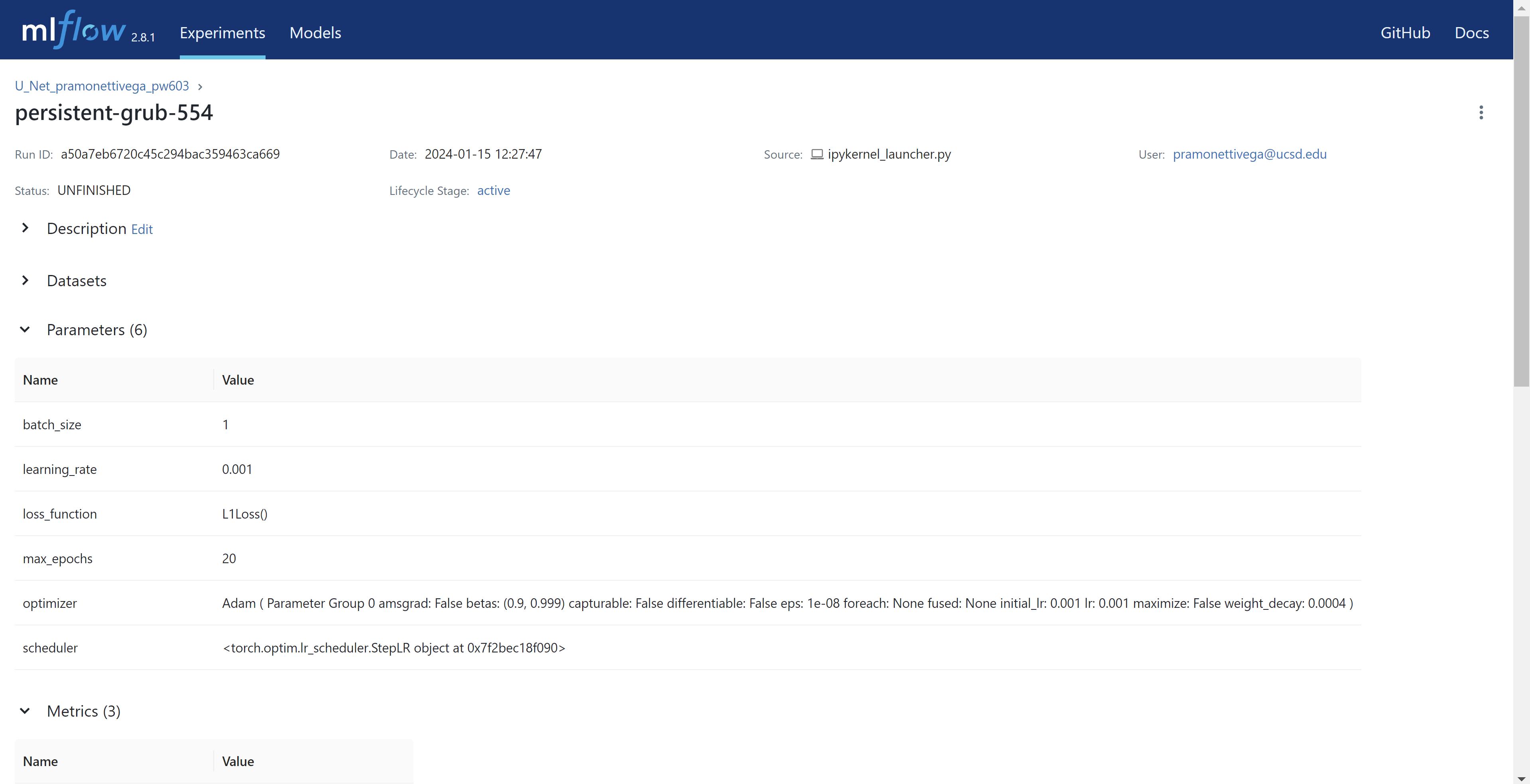
- Perform the training and testing of the model.

-
Produce the model and output images to store in the results directory.
-
Send the final products to MLflow.

NOTE: If decided to run the notebook, take into consideration that the full training under the hardware specifications defined previously might take up to three hours.
After finishing our work in JupyterLab, it is important to stop our server. To do this, go to the File window in JupyterLab and select Hub Control Panel. This will redirect you to JupyterHub and display your running servers (in case you have more than one). Click on Stop My Server to stop the current server.

- MLflow Getting Started Guide
- Introduction to Nautilus: This tutorial provides more details regarding the creation of pods and the execution of jobs in Nautilus.
This tutorial is part of the v0.1 alpha version of NDP, and as such, it may contain some misleading instructions or errors. We welcome all valuable feedback to assist us in refining the content, enhancing the structure, and improving overall clarity.
If you've spotted any glitches, bugs, or unexpected behaviors, kindly use this issue reporting form to contact us.