Vision: Redesign Event system #278
Comments
|
We could probably put events into their own child trie. The main problem I would see with this is the efficient removal, which would not work with a child trie. |
|
Why cant we have a merkle trie as a single storage item? And then just the root hash as a second item that is easy and small to read. |
|
We can not have a merkle trie as a single storage item. It would be too costly. It would require reading the entire trie, when we want to add a new event. However, we could add some sort of post-processing into |
|
But maybe we can also think again about child tries and how to speedup their deletion. |
|
This issue has been mentioned on Polkadot Forum. There might be relevant details there: https://forum.polkadot.network/t/redesign-event-system/625/1 |
|
I don't think events need to/should be "structured"; this would add a lot of conceptual, storage and implementation overhead. I do think we want a quick and easy means of proving that an event happened in a block, as well as proving the context in which it happened (I'm thinking especially an extrinsic index and possibly some call stack). Some form of secondary trie structure would be the obvious way to go, but child tries (as presently implemented) are needlessly persisting their contents, which we don't want/need. I think perhaps a specialist data-structure which gives a per-block non-persistent trie accumulator. It may or may not use a host call, depending on how fast it would be to do in wasm. Basically, you'd be able to append an item and eventually get the root of the trie of all items |
|
Currently it is very hard (if not impossible) to identify event-call association within a reasonably complicated call (e.g. multisig + proxy + batch). Nested event solves this. I can see a in memory accumulator can help with this and it also have many other use cases. Maybe we should also prioritize it as well. |
|
Indeed. |
|
One further requirement: O(1) for checkpointing/commit/reversion in transactional processing. |
RSA Accumulators almost meet all those requirements: Efficient to emit:
fn hash_to_prime<E: Codec>(element: &E) -> [u8;32] {
let mut hash = Blake2_256::hash(element.encode());
loop {
if is_prime(&hash) {
return hash;
}
hash = Blake2_256::hash(&hash);
}
}For static events, it can be pre-calculated at compile-time, but for an arbitrary element such implementation may not be safe to run on-chain once an adversary can craft an element which requires many iterations to find the prime. ✅ Efficient to proof:
✅ Efficient removal:
✅ O(1) for checkpointing/commit/reversion in transactional processing.
❓ Easy to query: Depends, I see a conflicting requirements here, which is check if an event is present looking at the storage key, but at the same time not storing the event in the block.. a possible solution here would be the same as ethereum and use bloom filters to tell if an event may be present in a block or not. |
|
Ok, I think I've found a more elegant design that meet all listed requirements, a specialized Cuckoo Filter Cuckoo filter is very similar to Bloom Filter, but store partial fingerprints, less false positives, very good space efficiency and supports deletions! 1 - Anyone can easily skip blocks that doesn't contains the events he is looking for with a small fraction of false positives. References |
|
Adding my two cents here. We are working on a cross-chain identity use case, and we need Having efficient proof-of-event capabilities would allow users to prove they funded the parachain account, without relying on XCM to send back such information. This would be possible by using state proofs and a more efficient way of proving that a specific event happened. |
When I read this months ago (November?), I read up on RSA Accumulators. I was completely horrified. Not only do they have a trusted setup, the idea of hashing to prime numbers seemed like a mess. I did see there was groups of unknown order proposed as an alternative to a trusted setup, yet it was still quite fringe. For completely unrelated reasons, I ended up working on threshold ECDSA and for that, implemented class groups of unknown order in Rust. With that, I implemented a hash to prime (and was again horrified). I ended up accepting it however for its role in removing cryptographic assumptions, having better understood them. Please note some prior works do rely on the Strong Root Assumption (not the Adaptive Root Assumption), and that'd void the need for a hash to prime. If anyone is interested in using my work, which is in pure Rust, for experiments: https://github.com/kayabaNerve/threshold-threshold-ecdsa/blob/develop/src/class_group.rs Please note I doubt my implementation is optimal. I believe Chia has made far more efficient reduction algorithms, and I know malachite is ~4x slower than gmp (though this would be a C dependency). Please note hashing to prime numbers is still messy to implement, and I don't doubt it can be adversarially bombed. I do still question what the worst case would be for an algorithm designed to be used as a hash to prime is. Please note the proposed brute force above can be replaced with a sieve of some form, such as https://eprint.iacr.org/2011/481 which intends to effect a uniform distribution. Such a proposal could use a single storage slot, and create an inclusion proof with a trivial algorithm using the accumulator of the prior block + an O(n) algorithm where all other events in the same block are included (leaving out the intended event). I'll also note there are trustless mechanisms to generate uniform elements in a class group, per https://eprint.iacr.org/2024/034. The above is solely to flesh out the cryptographic proposal of accumulators. My commentary on cuckoo filters is it doesn't sound to actually offer LC verification, solely efficient finding of where events may have been. Is that correct, or would the light client proof be all of the hashes in the filter (where the event's hash inclusion proved it occurred)? |
This includes a critical fix for debug release versions of litep2p (which are running in Kusama as validators). While at it, have stopped the oncall pain of alerts around `incoming_connections_total`. We can rethink the metric expose of litep2p in Q1. ## [0.8.2] - 2024-11-27 This release ensures that the provided peer identity is verified at the crypto/noise protocol level, enhancing security and preventing potential misuses. The release also includes a fix that caused `TransportService` component to panic on debug builds. ### Fixed - req-resp: Fix panic on connection closed for substream open failure ([#291](paritytech/litep2p#291)) - crypto/noise: Verify crypto/noise signature payload ([#278](paritytech/litep2p#278)) ### Changed - transport_service/logs: Provide less details for trace logs ([#292](paritytech/litep2p#292)) ## Testing Done This has been extensively tested in Kusama on all validators, that are now running litep2p. Deployed PR: #6638 ### Litep2p Dashboards 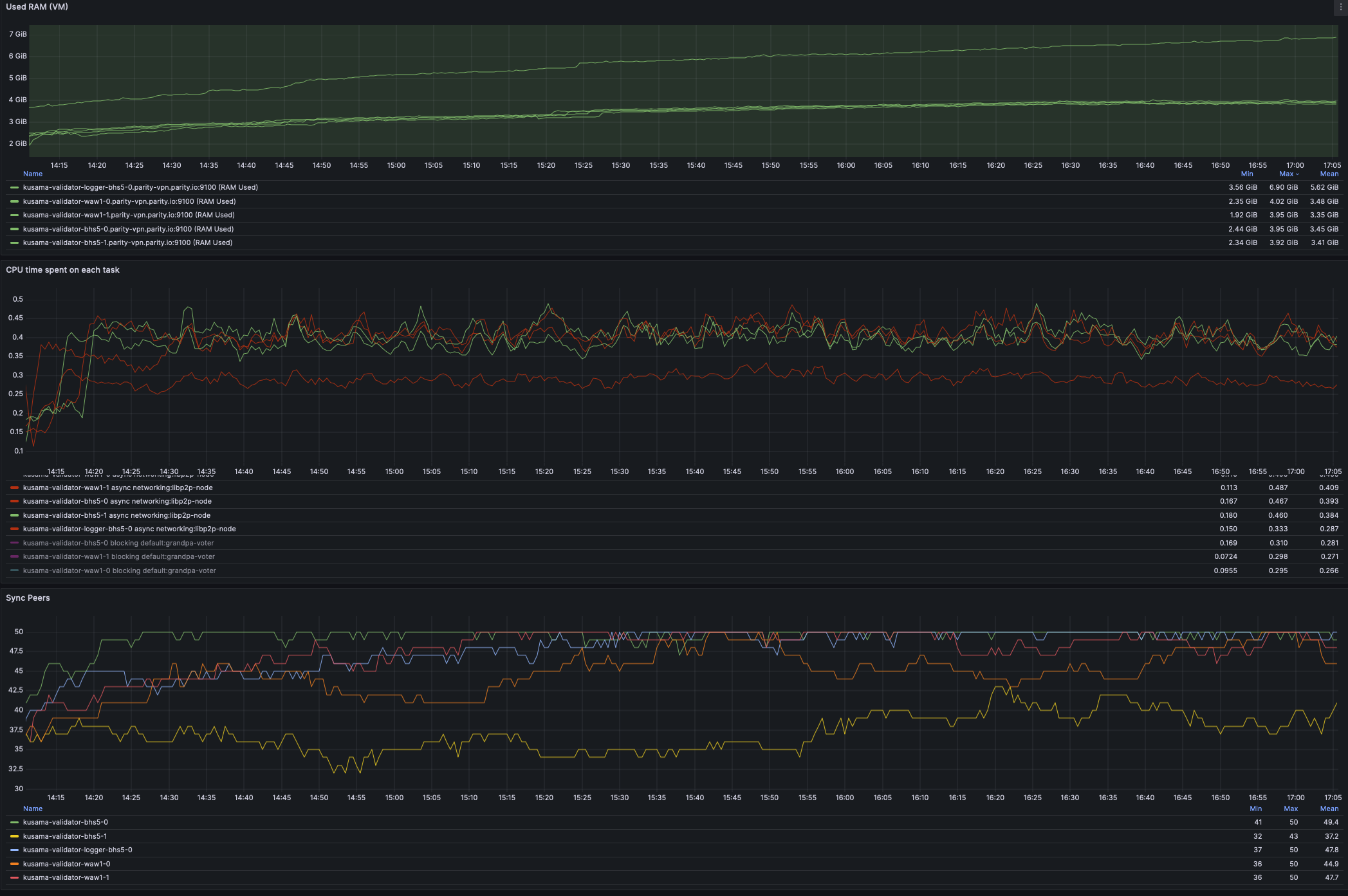 ### Libp2p vs Litep2p CPU usage After deploying litep2p we have reduced CPU usage from around 300-400% to 200%, this is a significant boost in performance, freeing resources for other subcomponents to function more optimally.  cc @paritytech/sdk-node --------- Signed-off-by: Alexandru Vasile <alexandru.vasile@parity.io> Co-authored-by: GitHub Action <action@github.com>
This includes a critical fix for debug release versions of litep2p (which are running in Kusama as validators). While at it, have stopped the oncall pain of alerts around `incoming_connections_total`. We can rethink the metric expose of litep2p in Q1. ## [0.8.2] - 2024-11-27 This release ensures that the provided peer identity is verified at the crypto/noise protocol level, enhancing security and preventing potential misuses. The release also includes a fix that caused `TransportService` component to panic on debug builds. ### Fixed - req-resp: Fix panic on connection closed for substream open failure ([#291](paritytech/litep2p#291)) - crypto/noise: Verify crypto/noise signature payload ([#278](paritytech/litep2p#278)) ### Changed - transport_service/logs: Provide less details for trace logs ([#292](paritytech/litep2p#292)) ## Testing Done This has been extensively tested in Kusama on all validators, that are now running litep2p. Deployed PR: #6638 ### Litep2p Dashboards  ### Libp2p vs Litep2p CPU usage After deploying litep2p we have reduced CPU usage from around 300-400% to 200%, this is a significant boost in performance, freeing resources for other subcomponents to function more optimally.  cc @paritytech/sdk-node --------- Signed-off-by: Alexandru Vasile <alexandru.vasile@parity.io> Co-authored-by: GitHub Action <action@github.com> (cherry picked from commit 51c3e95)
This includes a critical fix for debug release versions of litep2p (which are running in Kusama as validators). While at it, have stopped the oncall pain of alerts around `incoming_connections_total`. We can rethink the metric expose of litep2p in Q1. ## [0.8.2] - 2024-11-27 This release ensures that the provided peer identity is verified at the crypto/noise protocol level, enhancing security and preventing potential misuses. The release also includes a fix that caused `TransportService` component to panic on debug builds. ### Fixed - req-resp: Fix panic on connection closed for substream open failure ([paritytech#291](paritytech/litep2p#291)) - crypto/noise: Verify crypto/noise signature payload ([paritytech#278](paritytech/litep2p#278)) ### Changed - transport_service/logs: Provide less details for trace logs ([paritytech#292](paritytech/litep2p#292)) ## Testing Done This has been extensively tested in Kusama on all validators, that are now running litep2p. Deployed PR: paritytech#6638 ### Litep2p Dashboards  ### Libp2p vs Litep2p CPU usage After deploying litep2p we have reduced CPU usage from around 300-400% to 200%, this is a significant boost in performance, freeing resources for other subcomponents to function more optimally.  cc @paritytech/sdk-node --------- Signed-off-by: Alexandru Vasile <alexandru.vasile@parity.io> Co-authored-by: GitHub Action <action@github.com>
This includes a critical fix for debug release versions of litep2p (which are running in Kusama as validators). While at it, have stopped the oncall pain of alerts around `incoming_connections_total`. We can rethink the metric expose of litep2p in Q1. ## [0.8.2] - 2024-11-27 This release ensures that the provided peer identity is verified at the crypto/noise protocol level, enhancing security and preventing potential misuses. The release also includes a fix that caused `TransportService` component to panic on debug builds. ### Fixed - req-resp: Fix panic on connection closed for substream open failure ([paritytech#291](paritytech/litep2p#291)) - crypto/noise: Verify crypto/noise signature payload ([paritytech#278](paritytech/litep2p#278)) ### Changed - transport_service/logs: Provide less details for trace logs ([paritytech#292](paritytech/litep2p#292)) ## Testing Done This has been extensively tested in Kusama on all validators, that are now running litep2p. Deployed PR: paritytech#6638 ### Litep2p Dashboards  ### Libp2p vs Litep2p CPU usage After deploying litep2p we have reduced CPU usage from around 300-400% to 200%, this is a significant boost in performance, freeing resources for other subcomponents to function more optimally.  cc @paritytech/sdk-node --------- Signed-off-by: Alexandru Vasile <alexandru.vasile@parity.io> Co-authored-by: GitHub Action <action@github.com>
Related issues: paritytech/substrate#9480 paritytech/substrate#11132
Currently all the events are stored in a single array. This means while we can emit events in the runtime, we can never be able to process them in runtime or light client efficiently and safely. This prevents people from using foreign events during cross chain interactions and basically makes many async multi chain operations impossible.
We also have supports event topic that is incomplete (#371) and unused at all.
We should redesign the event system to meet at least those requirements:
The text was updated successfully, but these errors were encountered: