信息抽取(Information Extraction, IE)旨在从大规模非结构或半结构的自然语言文本中抽取结构化信息。关系抽取(Relation Extraction, RE)是其中的重要子任务之一,主要目的是从文本中识别实体并抽取实体之间的语义关系,是自然语言处理(NLP)中的一项基本任务。比如,我们可以从下面的一段话中,
鸿海集团董事长郭台铭25日表示,阿里巴巴集团董事局主席马云提的新零售、新制造中的「新制造」,是他给加上的。网易科技报导,郭台铭在2018深圳IT领袖峰会谈到工业互联网时表示,眼睛看的、脑筋想的、嘴巴吃的、耳朵听的,都在随着互联网的发展而蓬勃发展,当然互联网不是万能的,比如说刚才李小加要水喝,在手机上一按就能出一瓶水吗?当然做不到,还是得有实体经济。
可以抽取出如下三元组,用来表示实体之间的关系:
['鸿海集团', '董事长', '郭台铭']
['阿里巴巴集团', '主席', '马云']
并且能够形成如下的简单的知识图谱(Knowledge Graph)。
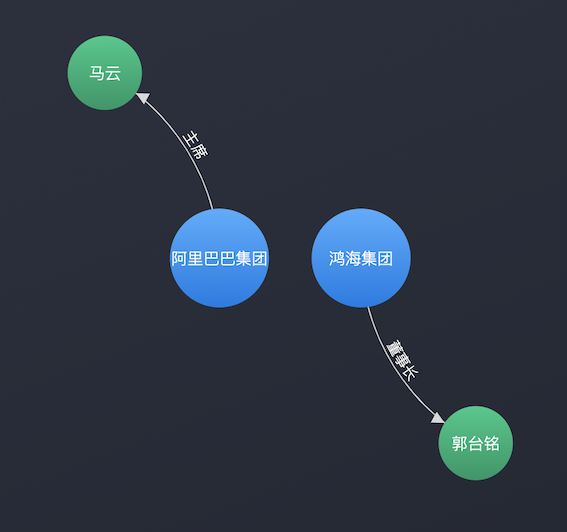
关于知识图谱,笔者已经在文章SPARQL入门(一)SPARQL简介与简单使用中给出了一些介绍,而利用关系抽取,我们可以从一些非结构化数据中,提取出实体之间的关系,形成知识图谱,这在很大程度上可以帮助我们减轻构建知识图谱的成本。非结构化数据越多,关系抽取效果越好,我们构建的知识图谱就会越庞大,实体之间的关系也会越丰富。
目前,网络上有许多与关系抽取相关的公开比赛,比如:
- CCKS 2019 人物关系抽取,网址为:https://biendata.com/competition/ccks_2019_ipre/ ;
- 2019语言与智能技术竞赛信息抽取:http://lic2019.ccf.org.cn/kg 。
常用的关系抽取语料如下:
- MUC关系抽取任务数据集;
- ACE关系抽取任务数据集;
- TAC-KBP数据集。
现阶段,关系抽取的办法主要如下:
- 基于规则的模式匹配;
- 基于监督学习的方法;
- 半监督和无监督学习方法;
- 远程监督的方法;
- 深度学习模型。
接着,笔者想说下,为什么最近会研究关系抽取。在一个偶然的机会,笔者看到了这个网站:https://www.wisers.ai/zh-cn/browse/relation-extraction/demo/ ,截图如下:
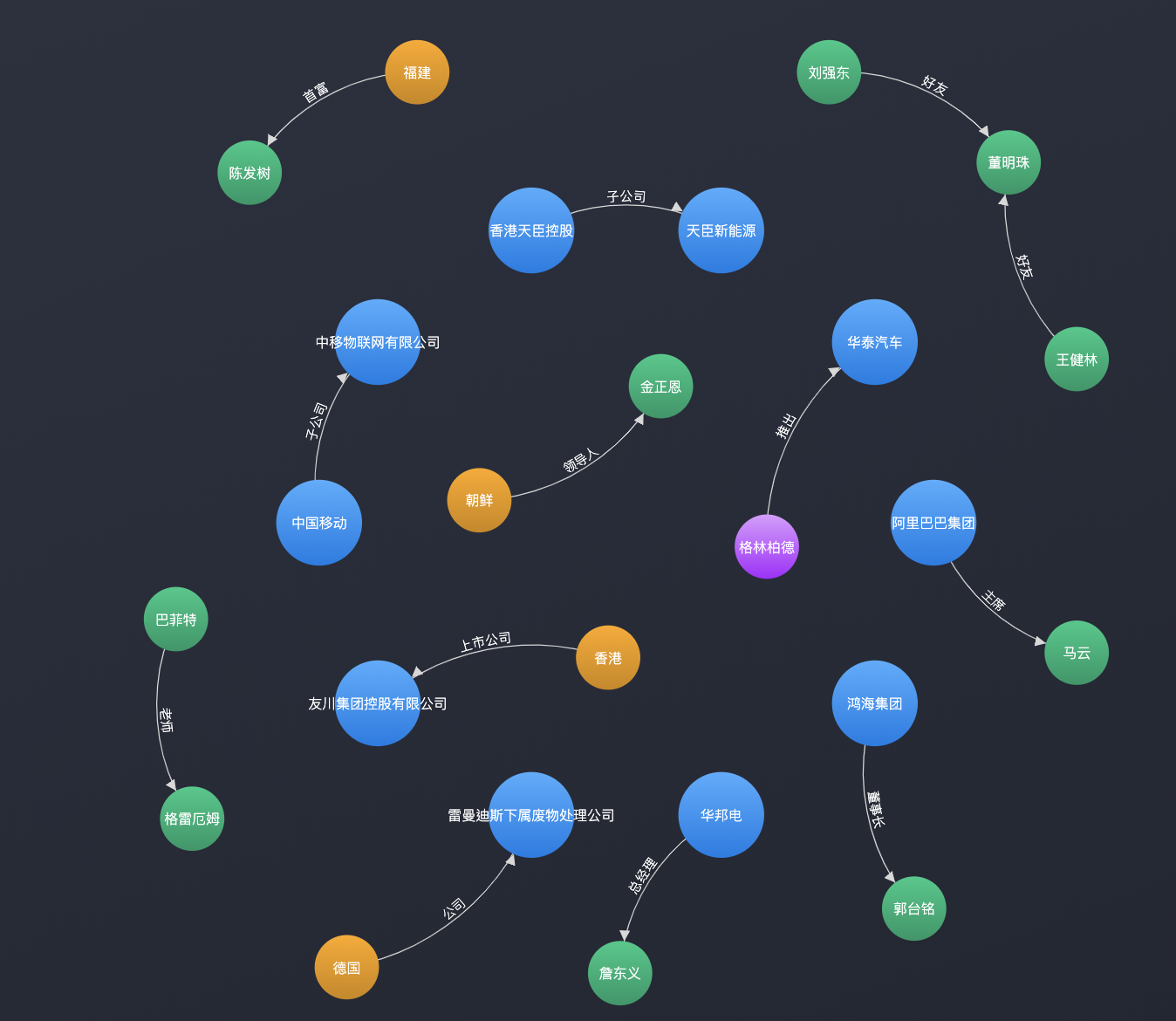
这个图给人以一种非常炫酷的感觉,因此,笔者就被它所吸引了。但笔者在这个demo网站上尝试了几篇新的语料,有些效果好,有些效果不尽如人意,因此,笔者决定自己动手实现一个关系抽取的模型! 虽然网上已经有许多现成的很好的关系抽取的模型,但笔者还是希望能够按照自己的意愿和想法来实现一下,当然,仅仅是作为一次尝试。笔者的思路如下:
- 以句子级别进行标注,标注出句子中的主语,谓语,宾语,形成标注序列;
- 利用标注好的语料,采用bert+dl的方法进行训练;
- 对新的语料,预测主语,谓语,宾语,然后利用一定的策略,形成实体关系;
- 对新语料的实体关系进行可视化展示。
如果你对笔者的尝试感兴趣,请尝试这阅读下去。
按照笔者的惯例,还是自己进行标注。那么,对于关系抽取,该如何进行标注呢?比如,下面这句话:
应日本国首相安倍晋三邀请,出席二十国集团领导人第十四次峰会。
我们需要的实体关系应该是: 日本国-->首相-->安倍晋三,那么我们可以选择主语为日本,谓语为首相,宾语为安倍晋三,形成的标注序列如下:
应 O
日 B-SUBJ
本 I-SUBJ
国 I-SUBJ
首 B-PRED
相 I-PRED
安 B-OBJ
倍 I-OBJ
晋 I-OBJ
三 I-OBJ
邀 O
请 O
, O
出 O
席 O
二 O
十 O
国 O
集 O
团 O
领 O
导 O
人 O
第 O
十 O
四 O
次 O
峰 O
会 O
。 O
对于句子中出现多主语,多谓语,多宾语的情况,也可以照此进行标注,比如下面这句:
齐鹏飞同志任中共中国人民大学委员会常委、副书记。
形成的标注序列如下:
齐 B-OBJ
鹏 I-OBJ
飞 I-OBJ
同 O
志 O
任 O
中 B-SUBJ
共 I-SUBJ
中 I-SUBJ
国 I-SUBJ
人 I-SUBJ
民 I-SUBJ
大 I-SUBJ
学 I-SUBJ
委 I-SUBJ
员 I-SUBJ
会 I-SUBJ
常 B-PRED
委 I-PRED
、 O
副 B-PRED
书 I-PRED
记 I-PRED
。 O
对此,我们希望形成两个三元组,分别为:中共中国人民大学委员会-->常委-->齐鹏飞, 中共中国人民大学委员会-->副书记-->齐鹏飞。 笔者利用自己的标注平台(后续会在Github开源),一共标注了950分语料,其中80%作为训练集,10%作为验证集,另外10%作为测试集。当然,标注的过程是很痛苦的,这些标注量也还远远不够,后续会持续不断地更新。
由于是小样本量的标注数量,因此,在模型的选择上,需要预训练模型,笔者的预训练模型选择BERT。在预训练的基础上,选择BiLSTM+CRF深度学习模型,对上述语料进行训练,共训练100次,在验证集和测试集上的效果如下:
验证集:
| 项目 | precision | recall | f1 |
|---|---|---|---|
| 全部 | 71.08% | 78.27% | 74.50% |
| 宾语 | 78.95% | 88.24% | 83.33% |
| 谓语 | 68.00% | 74.56% | 71.13% |
| 主语 | 67.18% | 73.33% | 70.12% |
测试集
| 项目 | precision | recall | f1 |
|---|---|---|---|
| 全部 | 75.07% | 82.18% | 78.46% |
| 宾语 | 78.33% | 85.45% | 81.74% |
| 谓语 | 73.23% | 82.30% | 77.50% |
| 主语 | 73.88% | 79.20% | 76.45% |
效果并没有达到很好,一方面是标注策略的问题,另一方面是标注的数量问题(因为这是一个通用模型),后续我们可以看看,当标注数量提上去后,模型训练的效果是否会有提升。
接着,我们利用刚才训练好的模型,对新的句子进行预测,记住,预测的级别为句子。当然,预测的结果,只是序列标注模型识别出的结果,我们还要采用一定的策略,将其形成三元组。比如以下的句子:
英媒称,美国农业部长桑尼·珀杜在6月25日播出的一个访谈节目中承认,美国农民是特朗普总统对华贸易战的“受害者”。
预测的结果如下:
[{'word': '美国', 'start': 4, 'end': 6, 'type': 'SUBJ'}, {'word': '农业部长', 'start': 6, 'end': 10, 'type': 'PRED'}, {'word': '桑尼·珀杜', 'start': 10, 'end': 15, 'type': 'OBJ'}, {'word': '美国', 'start': 34, 'end': 36, 'type': 'SUBJ'}]
可以看到,模型识别出主语为美国,谓语为农业部长,宾语为桑尼·珀杜,这是一个完美的三元组。
我们再来对下面的语句进行预测:
6月25日,华为常务董事、运营商事业部总裁丁耘表示,华为已在全球范围内获得50个5G商用合同,其中2/3是由华为协助其构建的。
预测结果为:
[{'word': '华为', 'start': 6, 'end': 8, 'type': 'SUBJ'}, {'word': '常务董事', 'start': 8, 'end': 12, 'type': 'PRED'}, {'word': '运营商事业部', 'start': 13, 'end': 19, 'type': 'SUBJ'}, {'word': '总裁', 'start': 19, 'end': 21, 'type': 'PRED'}, {'word': '丁耘', 'start': 21, 'end': 23, 'type': 'OBJ'}, {'word': '华为', 'start': 26, 'end': 28, 'type': 'SUBJ'}, {'word': '华为', 'start': 54, 'end': 56, 'type': 'SUBJ'}]
这就需要一定的策略,才能识别出具体的三元组了。笔者采用的策略如下:
- 按主语,谓语,宾语进行归类,形成主体集合
{华为, 运营商事业部},谓语集合{常务董事, 总裁}以及宾语集合{丁耘}; - 接着,按照各个元素在句子出现的位置进行组合,比如
华为的位置,离常务董事挨得近,那么形成一个三元组['华为', '常务董事', '丁耘'],同理,形成另一个三元组['运营商事业部', '总裁', '丁耘']; - 将句子按照逗号进行分割,形成
小句子集合,看三元组的三个元素是否都在一个小句子中,如果是,则提取该三元组,如果不是,则放弃该三元组。
对于关系抽取后的节后,我们将三元组导入至Neo4J中,查看可视化的效果。我们一共选择三篇文章进行测试,为了取得较好的效果,我们选择了程序处理+人工check(过滤)的过程,稍微有点工作量。
第一篇文章来自微信公众号,标题为:哈工大社会计算与信息检索研究中心(HIT-SCIR)拟于7月20日在哈工大举办首届事理图谱研讨会, 访问网址为:https://mp.weixin.qq.com/s/9H7rxsPdo5S5trwz_CASZw, 我们抽取出来的实体关系(带原文)如下:
原文,s,p,o 2017年10月,研究中心主任刘挺教授在中国计算机大会(CNCC)上正式提出事理图谱的概念,2018年9月,在研究中心丁效老师的主持下,研制出中文金融事理图谱1.0版本。,研究中心,老师,丁效
2017年10月,研究中心主任刘挺教授在中国计算机大会(CNCC)上正式提出事理图谱的概念,2018年9月,在研究中心丁效老师的主持下,研制出中文金融事理图谱1.0版本。,研究中心,教授,刘挺
2017年10月,研究中心主任刘挺教授在中国计算机大会(CNCC)上正式提出事理图谱的概念,2018年9月,在研究中心丁效老师的主持下,研制出中文金融事理图谱1.0版本。,研究中心,主任,刘挺
白硕(上海证券交易所前任总工程师,中科院计算所博导),上海证券交易所,前任总工程师,白硕
荀恩东(北京语言大学信息学院院长),北京语言大学信息学院,院长,荀恩东
赵军(中科院自动化所研究员),中科院自动化所,研究员,赵军
吴华(百度技术委员会主席),百度技术,主席,吴华
吴华(百度技术委员会主席),百度技术,委员,吴华
宋阳秋(香港科技大学助理教授),香港科技大学,助理教授,宋阳秋
李金龙(招商银行人工智能实验室负责人),招商银行人工智能实验室,负责人,李金龙
李世奇(北京西亚财信人工智能科技有限责任公司CEO),北京西亚财信人工智能科技有限责任公司,CEO,李世奇
对于这篇文章,我们没有抽取出李斌阳(国际关系学院副教授)中的实体关系,并且吴华(百度技术委员会主席这句为抽取有误,正确的应为:百度技术委员会,主席,吴华。
将上述关系修改下,导入至Neo4J中,得到的实体关系图如下:

第二篇文章为凤凰网的新闻,标题为南阳“水氢车”风波:一个中部城市的招商突围战,访问网址为:https://news.ifeng.com/c/7ntawxhCDvj ,我们抽取出来的实体关系(带原文)如下表:
原文,s,p,o 2017年,因巴铁所属企业北京华赢凯来资产管理有限公司涉嫌非法集资活动,北京警方将“巴铁之父”白丹青依法刑拘。,巴铁,之父,白丹青
南阳“神车”下线之后,界面新闻约访南阳市委书记张文深,被告知张文深与市长双双出差,工作人员并不确定张文深何时回到南阳,他的手机则处于忙线状态。,南阳,市委书记,张文深
南阳洛特斯新能源汽车有限公司实际控制人庞青年说,水氢汽车并未下线,媒体的报道使他措手不及。,南阳洛特斯新能源汽车有限公司,实际控制人,庞青年
从2006年开始,前湖北工业大学学者董仕节带领的团队开始研发一项车载铝合金水解制氢技术,并获得国家973前期研究项目和国家自然基金的支持。,湖北工业大学,学者,董仕节
南阳市高新区投资公司负责人尹召翼在接受央视采访时表示,庞青年经常拿“水氢”来混淆“水解制氢”的概念。,南阳市高新区投资公司,负责人,尹召翼
南阳市招商局招商二科科长赵怿接受界面新闻采访时表示,他只知道这个项目不是招商科引进的。,南阳市招商局招商二科,科长,赵怿
庞青年告诉界面新闻,南阳市高新区投资有限公司已经为他提供了9600万元,用途是南阳高新区投资有限公司给南阳市洛特斯新能源汽车有限公司的注册资金,占股49%。,南阳高新区投资有限公司,南阳市,洛特斯新能
曾先后在南阳市委党校、南阳市发改委任职的退休干部张一江(化名)说,“走工业突围道路的冲动在南阳早已有之,所以这几年的巴铁神车项目、加水就能跑的神车项目能被引进南阳,我觉得算不上奇怪。”,南阳市发改委,退休干部,张一江
以此次南阳神车项目为例,南阳市科技局局长张梅明确告诉界面新闻,庞青年的企业进入南阳时未有任何部门邀请科技局鉴别其“新能源技术”。,南阳市科技局,局长,张梅
官方报道显示,2012年6月18日,一位时任南阳市委主要领导在南阳宾馆会见了青年汽车董事局主席庞青年一行,双方就如何发挥自身优势,谋求合作共赢进行了交流,“南阳的发展需要大项目的带动和支撑,我们欢迎中国青年汽车集团这样有实力、有影响的大企业来南阳投资兴业。,青年汽车,董事局主席,庞青年
早在当年5月,在第十九届中国北京国际科技博览会上,时任南阳市副市长郑茂杰与巴铁科技发展有限公司总工程师宋有洲签署战略合作协议。,巴铁科技发展有限公司,总工程师,宋有洲
早在当年5月,在第十九届中国北京国际科技博览会上,时任南阳市副市长郑茂杰与巴铁科技发展有限公司总工程师宋有洲签署战略合作协议。,南阳市,副市长,郑茂杰
对于这篇文章,我们没有抽取出一些关系,比如南阳市发展和改革委员会主任乔长恩受访时承认,招商引入南阳洛斯特之前“掌握这个情况。”等,并且庞青年告诉界面新闻,南阳市高新区投资有限公司已经为他提供了9600万元,用途是南阳高新区投资有限公司给南阳市洛特斯新能源汽车有限公司的注册资金,占股49%。这句为抽取有误,应当删除。
将上述关系修改下,导入至Neo4J中,得到的实体关系图如下:

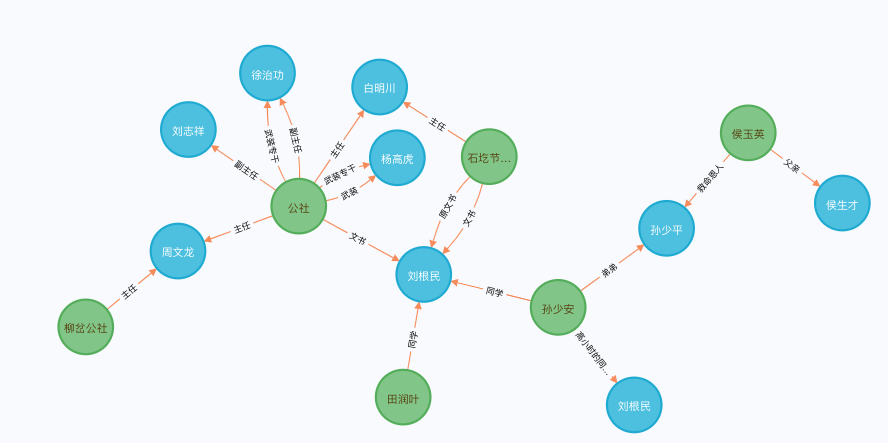
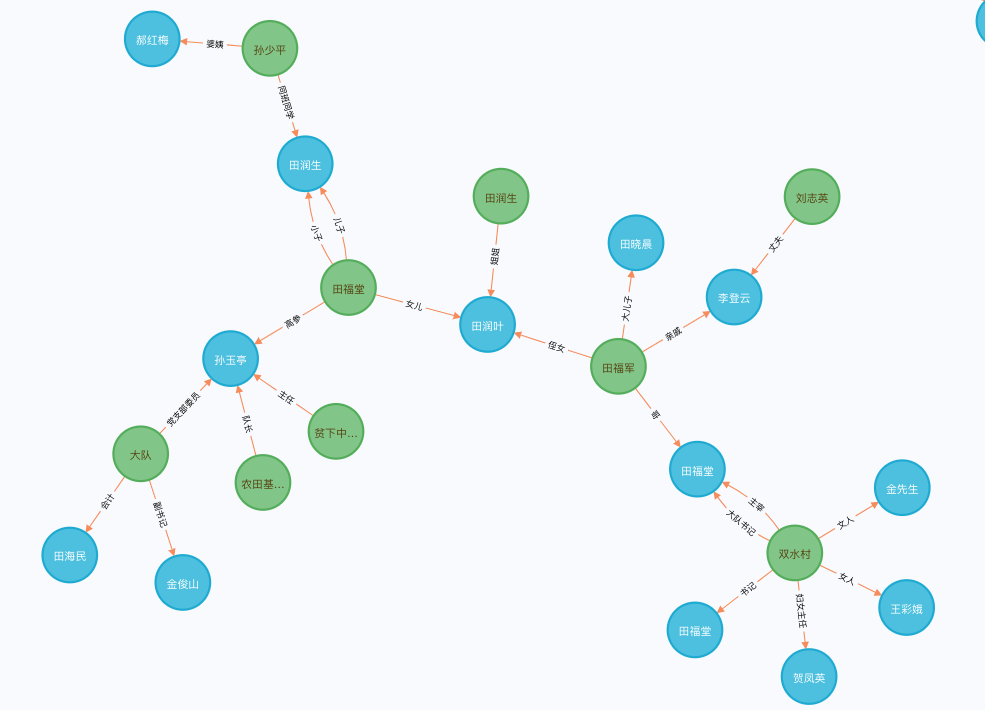
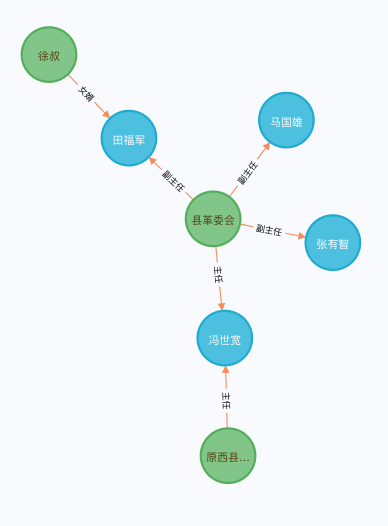
最后一篇为长篇小说——著名作家路遥的《平凡的世界》第一部。利用我们的关系抽取模型,一共在该小说中抽取了169对实体关系,其中有效实体关系100对。由于我们在该小说中抽取的实体关系过多,因此只展示前10条原文及抽取的实体关系:
原文,s,p,o 每天来回二十里路,与他一块上学的金波和大队书记田福堂的儿子润生都有自行车,只有他是两条腿走路。,田福堂,儿子,润生
不过,他对润生的姐姐润叶倒怀有一种亲切的感情。,润生,姐姐,润叶
“金波是金俊海的小子。”,金俊海,小子,“金波
脑子里把前后村庄未嫁的女子一个个想过去,最后选定了双水村孙玉厚的大女子兰花。,双水村孙玉厚,大女子,兰花
玉亭是大队党支部委员、农田基建队队长、贫下中农管理学校委员会主任,一身三职,在村里也是一个人物。,贫下中农管理学校,主任,玉亭
玉亭是大队党支部委员、农田基建队队长、贫下中农管理学校委员会主任,一身三职,在村里也是一个人物。,农田基建队,队长,玉亭
玉亭是大队党支部委员、农田基建队队长、贫下中农管理学校委员会主任,一身三职,在村里也是一个人物。,大队,党支部委员,玉亭
会战总指挥是公社副主任徐治功,副总指挥是公社武装专干杨高虎。,公社,武装,杨高虎
会战总指挥是公社副主任徐治功,副总指挥是公社武装专干杨高虎。,公社,副主任,徐治功
这时候,双水村妇女主任贺凤英,正领着本村和外村的一些“铁姑娘”,忙碌地布置会场。,双水村,妇女主任,贺凤英
……
将上述关系修改下,导入至Neo4J中,得到的实体关系图如下:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
本次关系抽取仅仅作为笔者的一次尝试,在实际的应用中还存在着许多的不足之处,比如:
- 对语料的标注,是否可以采用其他更好的办法;
- 作为通用模型,标注的数量还远远不够;
- 模型的选择方面,是否可以其他更好的模型;
- 对预测的结果,如何能更好地提取出三元组;
- 将三元组扫入至图数据库中,能否做到实体对齐,且能做一些实体关系的分析与推理。
本文用到的语料以及模型会在后续的文章中公开,希望大家能继续关注~ 注意:不妨了解下笔者的微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注~