简体中文 | English




- [2022-03-21] PaddleNLP一键预测工具Taskflow全新升级!🚀欢迎体验更丰富的功能、更便捷的使用方式;新推出适合不同场景的中文分词、命名实体识别模式!
- [2021-12-28] PaddleNLP新发语义检索、问答、评论观点抽取和情感倾向分析 产业化案例,🚀快速搭建系统!配套视频课程直通车!
PaddleNLP是飞桨自然语言处理开发库,具备易用的文本领域API,多场景的应用示例、和高性能分布式训练三大特点,旨在提升开发者在文本领域的开发效率,并提供丰富的NLP应用示例。
- 易用的文本领域API
- 提供丰富的产业级预置任务能力Taskflow和全流程的文本领域API:支持丰富中文数据集加载的Dataset API;灵活高效地完成数据预处理的Data API;提供100+预训练模型的Transformers API等,可大幅提升NLP任务建模的效率。
- 多场景的应用示例
- 覆盖从学术到产业级的NLP应用示例,涵盖NLP基础技术、NLP系统应用以及相关拓展应用。全面基于飞桨核心框架2.0全新API体系开发,为开发者提供飞桨文本领域的最佳实践。
- 高性能分布式训练
- 基于飞桨核心框架领先的自动混合精度优化策略,结合分布式Fleet API,支持4D混合并行策略,可高效地完成大规模预训练模型训练。
微信扫描下方二维码加入官方交流群,与各行各业开发者充分交流,期待您的加入⬇️

- python >= 3.6
- paddlepaddle >= 2.2
pip install --upgrade paddlenlp更多关于PaddlePaddle和PaddleNLP安装的详细教程请查看Installation。
Taskflow旨在提供开箱即用的NLP预置任务能力,覆盖自然语言理解与生成两大场景,提供产业级的效果与极致的预测性能。
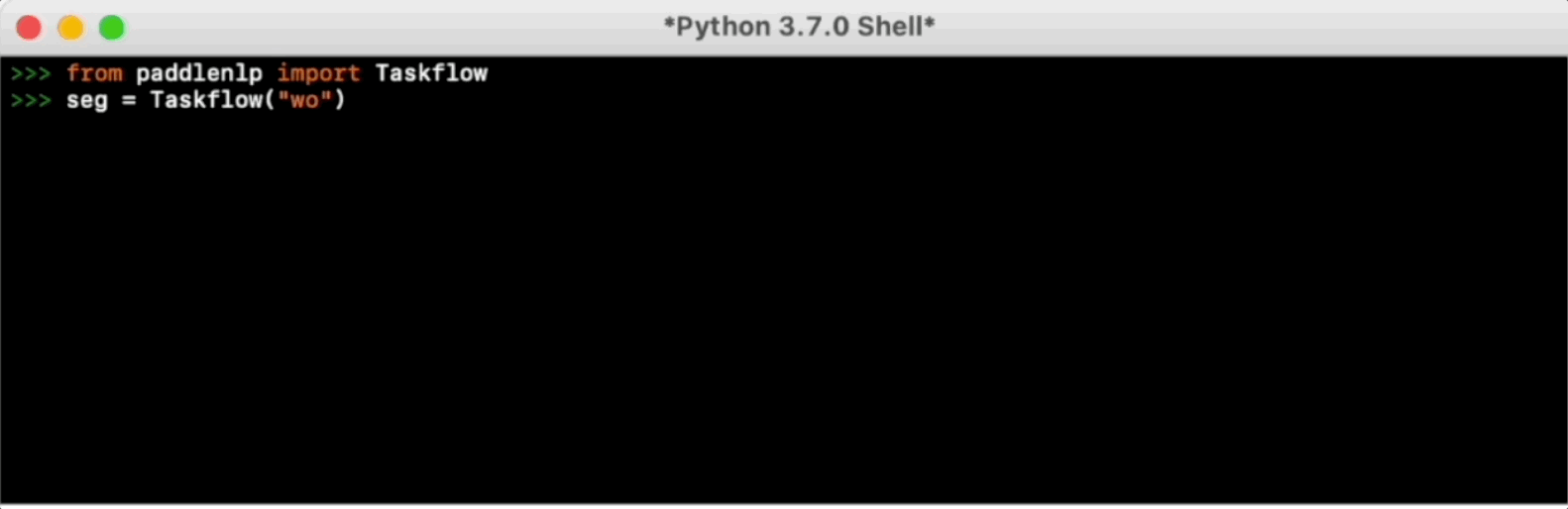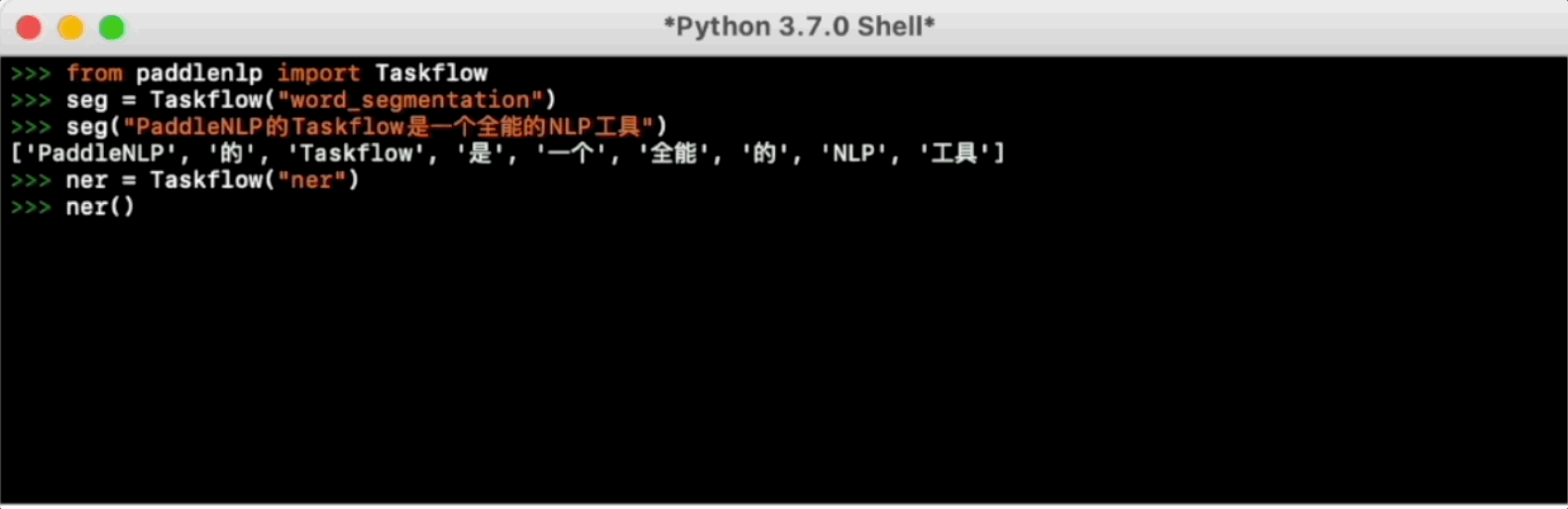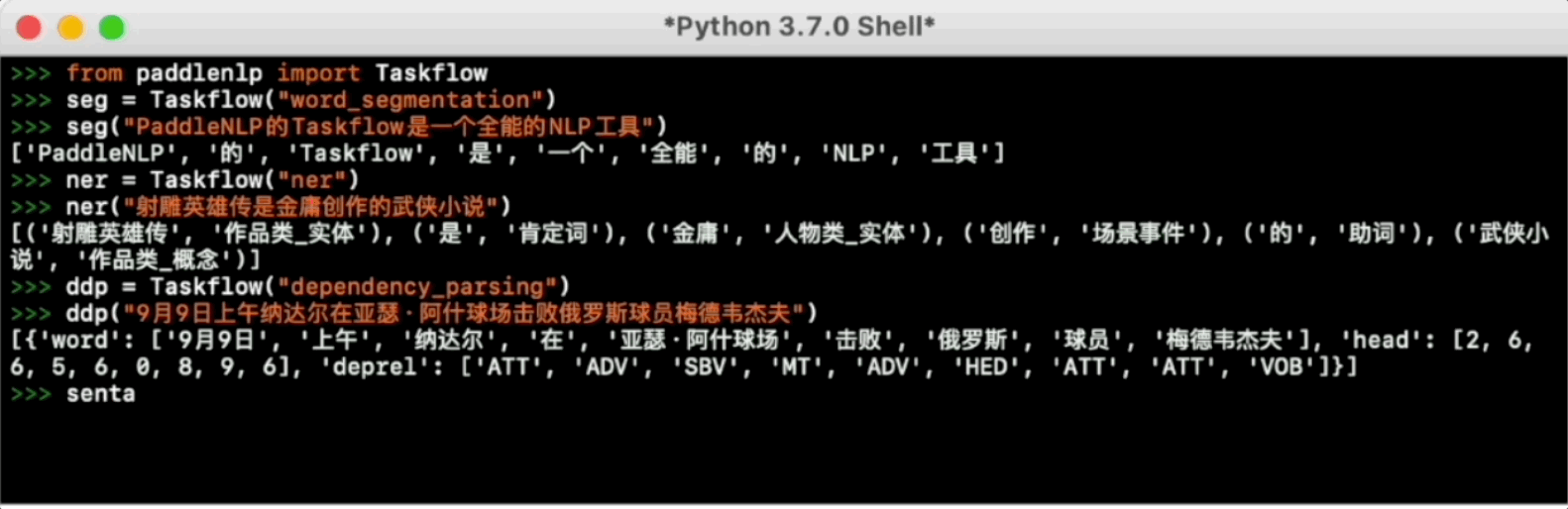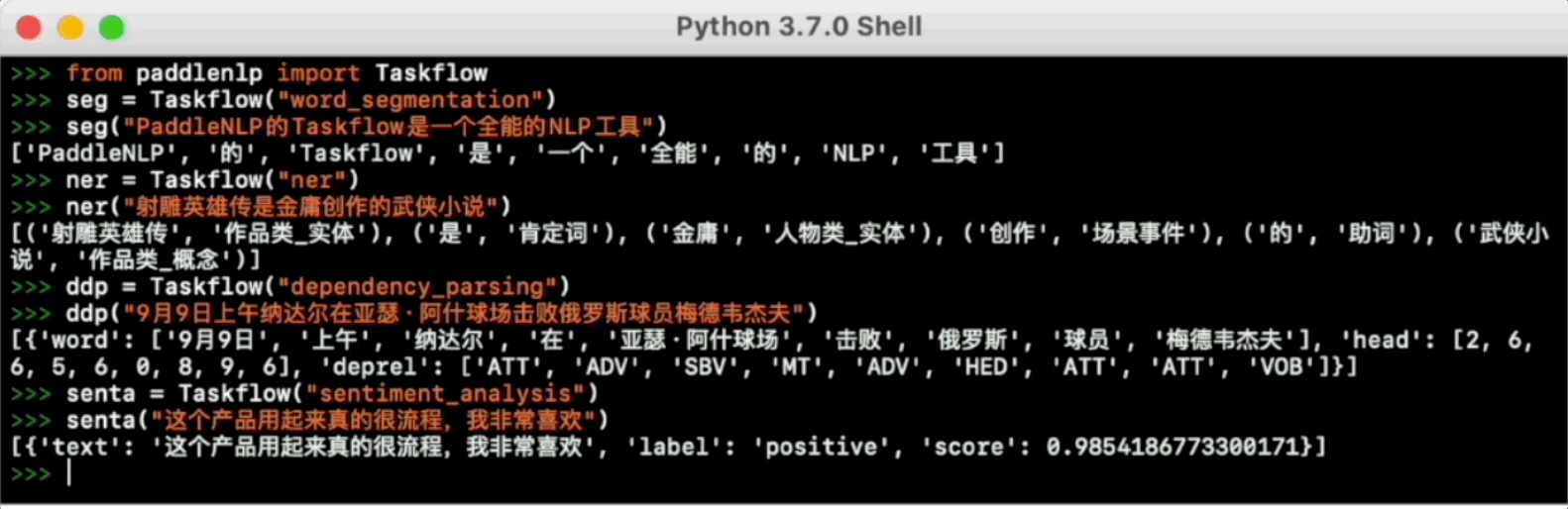
更多使用方法请参考Taskflow文档。
覆盖30个网络结构和100余个预训练模型参数,既包括百度自研的预训练模型如ERNIE系列, PLATO, SKEP等,也涵盖业界主流的中文预训练模型如BERT,GPT,XLNet,BART等。使用AutoModel可以下载不同网络结构的预训练模型。欢迎开发者加入贡献更多预训练模型!🤗
from paddlenlp.transformers import *
ernie = AutoModel.from_pretrained('ernie-1.0')
ernie_gram = AutoModel.from_pretrained('ernie-gram-zh')
bert = AutoModel.from_pretrained('bert-wwm-chinese')
albert = AutoModel.from_pretrained('albert-chinese-tiny')
roberta = AutoModel.from_pretrained('roberta-wwm-ext')
electra = AutoModel.from_pretrained('chinese-electra-small')
gpt = AutoModelForPretraining.from_pretrained('gpt-cpm-large-cn')对预训练模型应用范式如语义表示、文本分类、句对匹配、序列标注、问答等,提供统一的API体验。
import paddle
from paddlenlp.transformers import *
tokenizer = AutoTokenizer.from_pretrained('ernie-1.0')
text = tokenizer('自然语言处理')
# 语义表示
model = AutoModel.from_pretrained('ernie-1.0')
sequence_output, pooled_output = model(input_ids=paddle.to_tensor([text['input_ids']]))
# 文本分类 & 句对匹配
model = AutoModelForSequenceClassification.from_pretrained('ernie-1.0')
# 序列标注
model = AutoModelForTokenClassification.from_pretrained('ernie-1.0')
# 问答
model = AutoModelForQuestionAnswering.from_pretrained('ernie-1.0')请参考Transformer API文档查看目前支持的预训练模型结构、参数和详细用法。
Dataset API提供便捷、高效的数据集加载功能;内置千言数据集,提供丰富的面向自然语言理解与生成场景的中文数据集,为NLP研究人员提供一站式的科研体验。
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])
train_ds, dev_ds = load_dataset("lcqmc", splits=["train", "dev"])可参考Dataset文档 查看更多数据集。
from paddlenlp.embeddings import TokenEmbedding
wordemb = TokenEmbedding("w2v.baidu_encyclopedia.target.word-word.dim300")
print(wordemb.cosine_sim("国王", "王后"))
>>> 0.63395125
wordemb.cosine_sim("艺术", "火车")
>>> 0.14792643内置50+中文词向量,覆盖多种领域语料、如百科、新闻、微博等。更多使用方法请参考Embedding文档。
- Data API: 提供便捷高效的文本数据处理功能
- Metrics API: 提供NLP任务的评估指标,与飞桨高层API兼容。
更多的API示例与使用说明请查阅PaddleNLP官方文档
PaddleNLP提供了多粒度、多场景的NLP应用示例,面向动态图模式和全新的API体系开发,更加简单易懂。 涵盖了NLP基础技术、NLP系统应用以及文本相关的NLP拓展应用、与知识库结合的文本知识关联、与图结合的文本图学习等。
| 任务 | 简介 |
|---|---|
| 词向量 | 利用TokenEmbedding API展示如何快速计算词之间语义距离和词的特征提取。 |
| 词法分析 | 基于BiGRU-CRF模型实现了分词、词性标注和命名实体识的联合训练任务。 |
| 语言模型 | 覆盖了经典的LSTM类语言模型,和Transformer类的预训练语言模型,如BERT, ERNIE, GPT, XLNet, BART,ELECTRA,BigBird等。 |
| 语义解析⭐ | 语义解析Text-to-SQL任务是让机器自动让自然语言问题转换数据库可操作的SQL查询语句,是实现基于数据库自动问答的核心模块。 |
| 模型 | 简介 |
|---|---|
| Deep Biaffine Parsing | 实现经典的Deep Biaffine Parsing句法分析模型,并提供高质量的中文预训练模型可供直接使用。 |
| 模型 | 简介 |
|---|---|
| RNN/CNN/GRU/LSTM | 实现了经典的RNN, CNN, GRU, LSTM等经典文本分类结构。 |
| BiLSTM-Attention | 基于BiLSTM网络结构引入注意力机制提升文本分类效果。 |
| BERT/ERNIE | 提供基于预训练模型的文本分类任务实现,包含训练、预测和推理部署的全流程应用。 |
| 模型 | 简介 |
|---|---|
| SimCSE🌟 | 基于论文SimCSE: Simple Contrastive Learning of Sentence Embeddings实现无监督语义匹配模型,无需标注数据仅利用无监督数据也能训练效果出众的语义匹配模型。 |
| ERNIE-Gram w/ R-Drop | 提供基于ERNIE-Gram预训练模型结合R-Drop策略的问题匹配任在千言数据集上的基线代码。 |
| SimNet | 百度自研的语义匹配框架,使用BOW、CNN、GRNN等核心网络作为表示层,在百度内搜索、推荐等多个应用场景得到广泛易用。 |
| ERNIE | 基于ERNIE使用LCQMC数据完成中文句对匹配任务,提供了Pointwise和Pairwise两种类型学习方式。 |
| Sentence-BERT | 提供基于Siamese双塔结构的文本匹配模型Sentence-BERT实现,可用于获取文本的向量化表示。 |
| SimBERT | 提供SimBERT模型实现,用于获取文本的向量化表示。 |
| 模型 | 简介 |
|---|---|
| Seq2Seq | 实现了经典的Seq2Seq with Attention的网络结构,并提供在自动对联的文本生成应用示例。 |
| VAE-Seq2Seq | 在Seq2Seq框架基础上,加入VAE结构以实现更加多样化的文本生成。 |
| ERNIE-GEN | ERNIE-GEN是百度NLP提出的基于多流(multi-flow)机制生成完整语义片段的预训练模型,基于该模型实现了提供了智能写诗的应用示例。 |
| 模型 | 简介 |
|---|---|
| ERNIE-CSC 🌟 | ERNIE-CSC是基于ERNIE预训练模型融合了拼音特征的端到端中文拼写纠错模型,在SIGHAN数据集上取得SOTA的效果。 |
提供一套完整的语义索引开发流程,并提供了In-Batch Negative和Hardest Negatives两种策略,开发者可基于该示例实现一个轻量级的语义索引系统,更多信息请查看语义索引应用示例。
| 任务 | 简介 |
|---|---|
| DuEE | 基于DuEE数据集,使用预训练模型的方式提供句子级和篇章级的事件抽取示例。 |
| DuIE | 基于DuIE数据集,使用预训练模型的方式提供关系抽取示例。 |
| 快递单信息抽取 | 提供BiLSTM+CRF和预训练模型两种方式完成真实的快递单信息抽取案例。 |
| 模型 | 简介 |
|---|---|
| SKEP🌟 | SKEP是百度提出的基于情感知识增强的预训练算法,利用无监督挖掘的海量情感知识构建预训练目标,让模型更好理解情感语义,可为各类情感分析任务提供统一且强大的情感语义表示。 |
| 任务 | 简介 |
|---|---|
| SQuAD | 提供预训练模型在SQuAD 2.0数据集上微调的应用示例。 |
| DuReader-yesno | 提供预训练模型在千言数据集DuReader-yesno上微调的应用示例。 |
| DuReader-robust | 提供预训练模型在千言数据集DuReader-robust上微调的应用示例。 |
| 模型 | 简介 |
|---|---|
| Seq2Seq-Attn | 提供了Effective Approaches to Attention-based Neural Machine Translation基于注意力机制改进的Seq2Seq经典神经网络机器翻译模型实现。 |
| Transformer | 提供了基于Attention Is All You Need论文的Transformer机器翻译实现,包含了完整的训练到推理部署的全流程实现。 |
| 模型 | 简介 |
|---|---|
| STACL ⭐ | STACL是百度自研的基于Prefix-to-Prefix框架的同传翻译模型,结合Wait-k策略可以在保持较高的翻译质量的同时实现任意字级别的翻译延迟,并提供了轻量级同声传译系统搭建教程。 |
| 模型 | 简介 |
|---|---|
| PLATO-2 | PLATO-2是百度自研领先的基于课程学习两阶段方式训练的开放域对话预训练模型。 |
| PLATO-mini🌟 | 基于6层UnifiedTransformer预训练结构,结合海量中文对话语料数据预训练的轻量级中文闲聊对话模型。 |
🌟解语是由百度知识图谱部开发的文本知识关联框架,覆盖中文全词类的知识库和知识标注工具,能够帮助开发者面对更加多元的应用场景,方便地融合自有知识体系,显著提升中文文本解析和挖掘效果,还可以便捷地利用知识增强机器学习模型效果。
| 模型 | 简介 |
|---|---|
| ERNIESage | 基于飞桨PGL图学习框架结合PaddleNLP Transformer API实现的文本与图结构融合的模型。 |
| 模型 | 简介 |
|---|---|
| MiniLMv2 | 基于MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers论文策略的实现,是一种通用蒸馏方法。本实例以bert-base-chinese为教师模型,利用中文数据进行了通用蒸馏。 |
| TinyBERT | 基于论文TinyBERT: Distilling BERT for Natural Language Understanding的实现,提供了通用蒸馏和下游任务蒸馏的脚本。本实例利用开源模型tinybert-6l-768d-v2初始化,在GLUE的7个数据集上进行下游任务的蒸馏,最终模型参数量缩小1/2,预测速度提升2倍,同时保证模型精度几乎无损,其中精度可达教师模型bert-base-uncased的 98.90%。 |
| OFA-BERT | 基于PaddleSlim Once-For-ALL(OFA)策略对BERT在GLUE任务的下游模型进行压缩,在精度无损的情况下可减少33%参数量,达到模型小型化的提速的效果。 |
| Distill-LSTM | 基于Distilling Task-Specific Knowledge from BERT into Simple Neural Networks论文策略的实现,将BERT中英文分类的下游模型知识通过蒸馏的方式迁移至LSTM的小模型结构中,取得比LSTM单独训练更好的效果。 |
| PP-MiniLM 🌟 | 基于 PaddleSlim 通过模型蒸馏、剪裁、量化等级联模型压缩技术发布中文特色小模型 PP-MiniLM(6L768H) 及压缩方案,保证模型精度的同时模型推理速度达 BERT-base 的4.2倍,参数量相比减少52%,模型精度在中文语言理解评测基准 CLUE 高0.32。 |
| 算法 | 简介 |
|---|---|
| PET | 基于Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference 论文策略实现, 基于人工知识设计 Prompt, 将下游目标任务转换为完形填空任务来充分挖掘预训练模型中的知识, 显著提升模型效果。 |
| P-Tuning | 基于GPT Understands, Too 论文策略实现, 首次提出连续可学习的模板参数,在全参数空间对模板进行连续优化,大幅提升模型稳定性和模型效果。 |
| EFL | 基于Entailment as Few-Shot Learner 论文策略实现,将下游目标任务转换为蕴含任务降低模型预测空间,显著提升模型效果。 |
- 使用Seq2Vec模块进行句子情感分类
- 如何通过预训练模型Fine-tune下游任务
- 使用BiGRU-CRF模型完成快递单信息抽取
- 使用预训练模型ERNIE优化快递单信息抽取
- 使用Seq2Seq模型完成自动对联
- 使用预训练模型ERNIE-GEN实现智能写诗
- 使用TCN网络完成新冠疫情病例数预测
更多教程参见PaddleNLP on AI Studio。
更多版本更新说明请查看ChangeLog
如果PaddleNLP对您的研究有帮助,欢迎引用
@misc{=paddlenlp,
title={PaddleNLP: An Easy-to-use and High Performance NLP Library},
author={PaddleNLP Contributors},
howpublished = {\url{https://github.com/PaddlePaddle/PaddleNLP}},
year={2021}
}
我们借鉴了Hugging Face的Transformers🤗关于预训练模型使用的优秀设计,在此对Hugging Face作者及其开源社区表示感谢。
PaddleNLP遵循Apache-2.0开源协议。