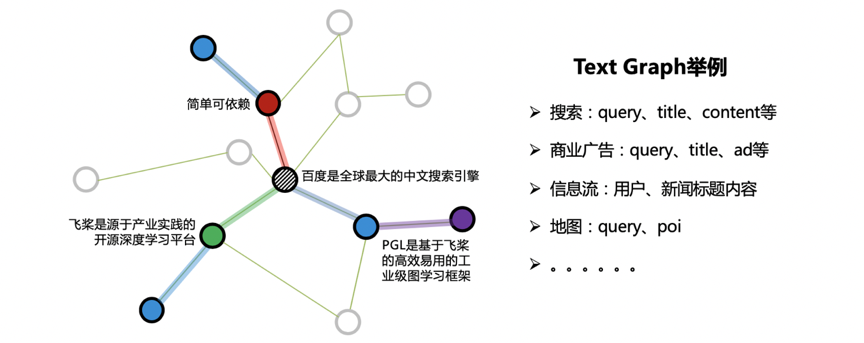
在很多工业应用中,往往出现如下图所示的一种特殊的图:Text Graph。顾名思义,图的节点属性由文本构成,而边的构建提供了结构信息。如搜索场景下的Text Graph,节点可由搜索词、网页标题、网页正文来表达,用户反馈和超链信息则可构成边关系。
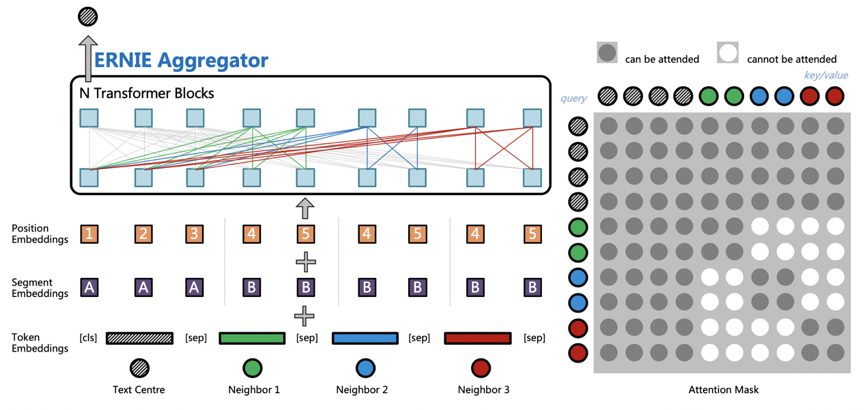
ErnieSage 由飞桨PGL团队提出,是ERNIE SAmple aggreGatE的简称,该模型可以同时建模文本语义与图结构信息,有效提升 Text Graph 的应用效果。其中 ERNIE 是百度推出的基于知识增强的持续学习语义理解框架。
ErnieSage 是 ERNIE 与 GraphSAGE 碰撞的结果,是 ERNIE SAmple aggreGatE 的简称,它的结构如下图所示,主要思想是通过 ERNIE 作为聚合函数(Aggregators),建模自身节点和邻居节点的语义与结构关系。ErnieSage 对于文本的建模是构建在邻居聚合的阶段,中心节点文本会与所有邻居节点文本进行拼接;然后通过预训练的 ERNIE 模型进行消息汇聚,捕捉中心节点以及邻居节点之间的相互关系;最后使用 ErnieSage 搭配独特的邻居互相看不见的 Attention Mask 和独立的 Position Embedding 体系,就可以轻松构建 TextGraph 中句子之间以及词之间的关系。
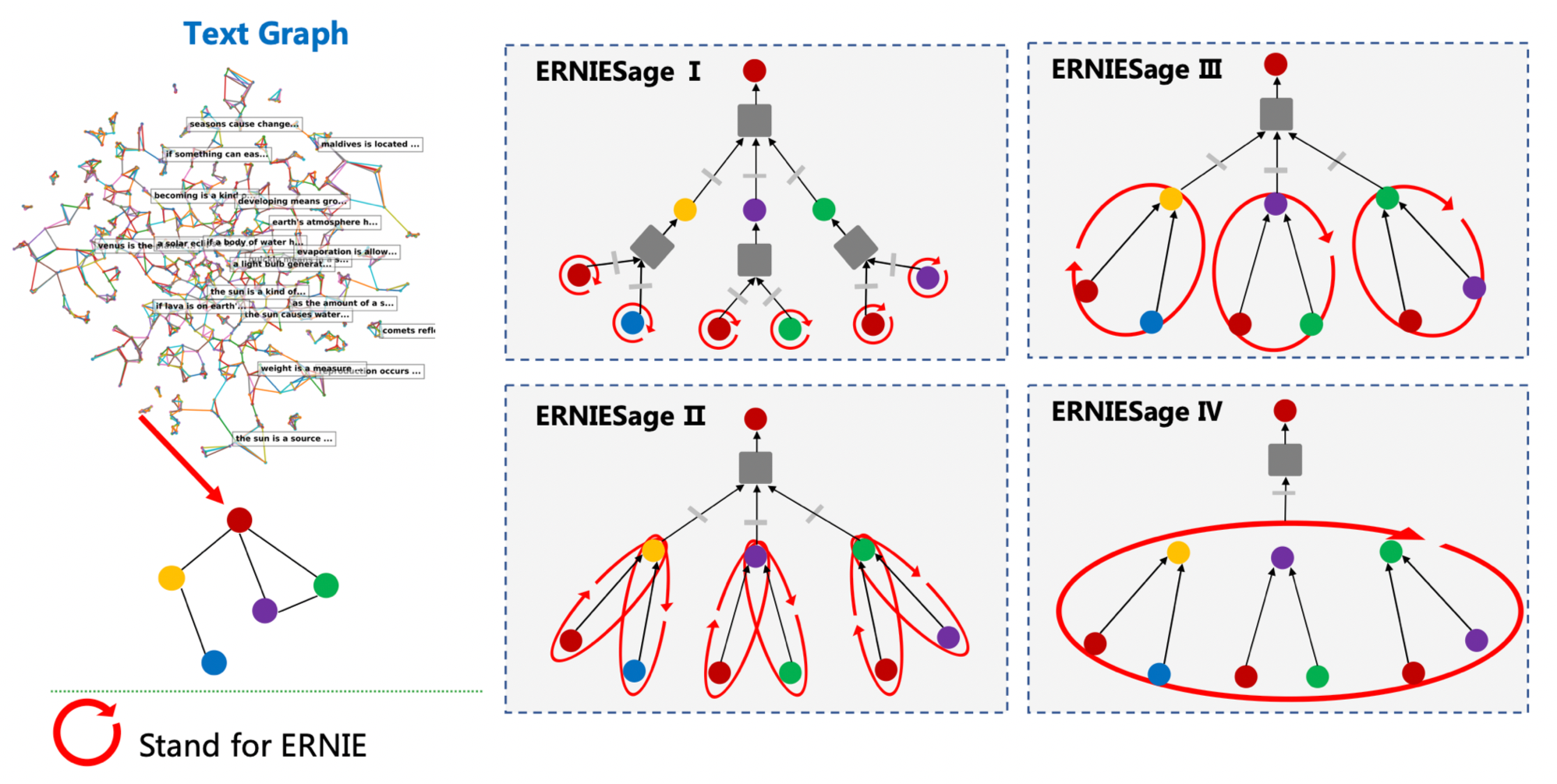
使用ID特征的GraphSAGE只能够建模图的结构信息,而单独的ERNIE只能处理文本信息。通过飞桨PGL搭建的图与文本的桥梁,ErnieSage能够很简单的把GraphSAGE以及ERNIE的优点结合一起。以下面TextGraph的场景,ErnieSage的效果能够比单独的ERNIE以及GraphSAGE模型都要好。
ErnieSage可以很轻松地在基于PaddleNLP构建基于Ernie的图神经网络,目前PaddleNLP提供了V2版本的ErnieSage模型:
- ErnieSage V2: ERNIE 作用在text graph的边上;
- pgl >= 2.1
安装命令
pip install pgl\>=2.1
示例数据data.txt中使用了NLPCC2016-DBQA的部分数据,格式为每行"query \t answer"。
NLPCC2016-DBQA 是由国际自然语言处理和中文计算会议 NLPCC 于 2016 年举办的评测任务,其目标是从候选中找到合适的文档作为问题的答案。[链接: http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf]
我们采用了PaddlePaddle Fleet作为我们的分布式训练框架,在config/*.yaml中,目前支持的ERNIE预训练语义模型包括ernie以及ernie_tiny,通过config/erniesage_link_prediction.yaml中的ernie_name指定。
# 数据预处理,建图
python ./preprocessing/dump_graph.py --conf ./config/erniesage_link_prediction.yaml
# GPU多卡或单卡模式ErnieSage
python -m paddle.distributed.launch --gpus "0" link_prediction.py --conf ./config/erniesage_link_prediction.yaml
# 对图节点的的embeding进行预测, 单卡或多卡
python -m paddle.distributed.launch --gpus "0" link_prediction.py --conf ./config/erniesage_link_prediction.yaml --do_predict- epochs: 训练的轮数
- graph_data: 训练模型时用到的图结构数据,使用“text1 \t text"格式。
- train_data: 训练时的边,与graph_data格式相同,一般可以直接用graph_data。
- graph_work_path: 临时存储graph数据中间文件的目录。
- samples: 采样邻居数
- model_type: 模型类型,包括ErnieSageV2。
- ernie_name: 热启模型类型,支持“ernie”和"ernie_tiny",后者速度更快,指定该参数后会自动从服务器下载预训练模型文件。
- num_layers: 图神经网络层数。
- hidden_size: 隐藏层大小。
- batch_size: 训练时的batchsize。
- infer_batch_size: 预测时batchsize。