Hybrid parallel MPI #1009
Merged
Hybrid parallel MPI #1009
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
pcarruscag
commented
May 30, 2020
Comment on lines
299
to
300
| void PostP2PRecvs(CGeometry *geometry, CConfig *config, unsigned short commType, | ||
| unsigned short countPerPoint, bool val_reverse) const; |
Member
Author
There was a problem hiding this comment.
A consequence of this is that the current count-per-point needs to be explicitly passed to a few routines, whereas before we could always rely on the maximum value.
Member
Author
|
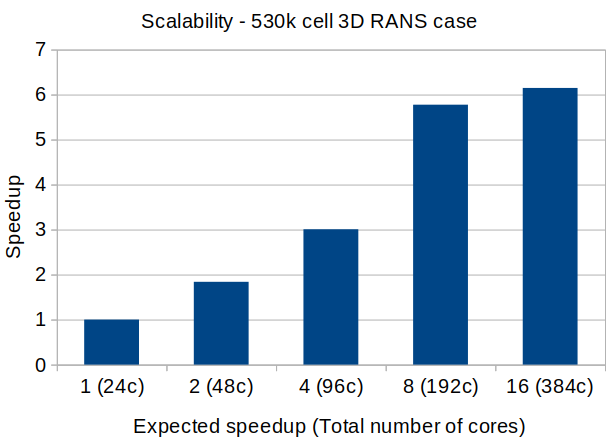
This is the sort of scalability (in terms of time to solution, not per iteration) we get now: Edit: The results at 192c are actually better, it depends on the position of the cluster nodes in the network, the update is apples to apples. |
talbring
reviewed
Jun 2, 2020
Member
 talbring
left a comment
talbring
left a comment
There was a problem hiding this comment.
Thanks @pcarruscag! Just two small comments below.
economon
reviewed
Jun 3, 2020
pcarruscag
commented
Jun 4, 2020
Comment on lines
+50
to
54
| CGeometry::CGeometry(void) : | ||
| size(SU2_MPI::GetSize()), | ||
| rank(SU2_MPI::GetRank()) { | ||
|
|
||
| } |
Member
Author
There was a problem hiding this comment.
The requested spring cleaning is done, I think I'll stop here.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Proposed Changes
This makes the routines InitiateComms and CompleteComms (and periodic counterparts) safe to call in parallel, until now they had to be guarded inside SU2_OMP_MASTER sections.
The calls to MPI are still only made by the master thread (funneled communication) but the buffers are packed and unpacked by all threads.
I also made a slight change which seems to make communications more efficient, we were always communicating the entire buffer, which is sized for the maximum number of variables per point, because the data was packed like this:
o o o o _ _ _ _ o o o o _ ...(count = 4, maxCount = 8);I changed it to:
o o o o o o o o ... _ _ _ _ ...Which allows only part of the buffer to be communicated.
(The maximum size
nPrimVarGrad*nDim*2is actually quite large compared to the mediannVar)In the process I also had to make a few more CGeometry routines thread safe.
Related Work
#789
Resolves #1011
PR Checklist