CSysMatrix cleanup and performance improvements #700
Conversation
…n CSysSolve the type of preconditioner defines the type of smoother
- not in use anywhere - exponential complexity, and so slower for most common nVar range - using an incompatible matrix format (** vs. *)
…rgument order of block methods
…rflow (after having removed an seemingly redundant exit condition)
- work on dest. vector instead of temporaries - using the optimized (mkl) block routines - Gaussian elimination instead of product with inverse
- avoid use of GetBlock in XXXProduct routines as that requires a search - work directly on ouput vector to avoid copy operations
- fewer working structures in CSysMatrix - stl containers and contiguous storage
… "Compute" method
…plied to CElasticityMovement and CFEASolver
 economon
left a comment
economon
left a comment
There was a problem hiding this comment.
First comments in the review.. very promising so far!
There was a problem hiding this comment.
Ok MKL works with the discrete adjoint now, it did get a bit creative...
@economon I added more comments.
Now to find out why the residuals changed for unsteady regressions.
Should I move some files to folders? Or move inlines to the hpp?
| } | ||
|
|
||
| #define __MATVECPROD_SIGNATURE__(TYPE,NAME) \ | ||
| inline void CSysMatrix<TYPE>::NAME(const TYPE *matrix, const TYPE *vector, TYPE *product) |
There was a problem hiding this comment.
I hope this does not look too bad, but this MKL stuff does work very well for the discrete adjoint (maybe 10% faster than native code).
|
Thanks @pcarruscag! This is a nice cleanup! 👍 So while you are already at it, you can already separate it in folders/files and remove the *inl (if all agree with these changes). Maybe adding a linear algebra subfolder makes sense. |
|
Thanks @talbring, |
…t was diverging...)
|
The case with large change of residuals (3 orders) is the rotating cylinders case (sliding interface). |
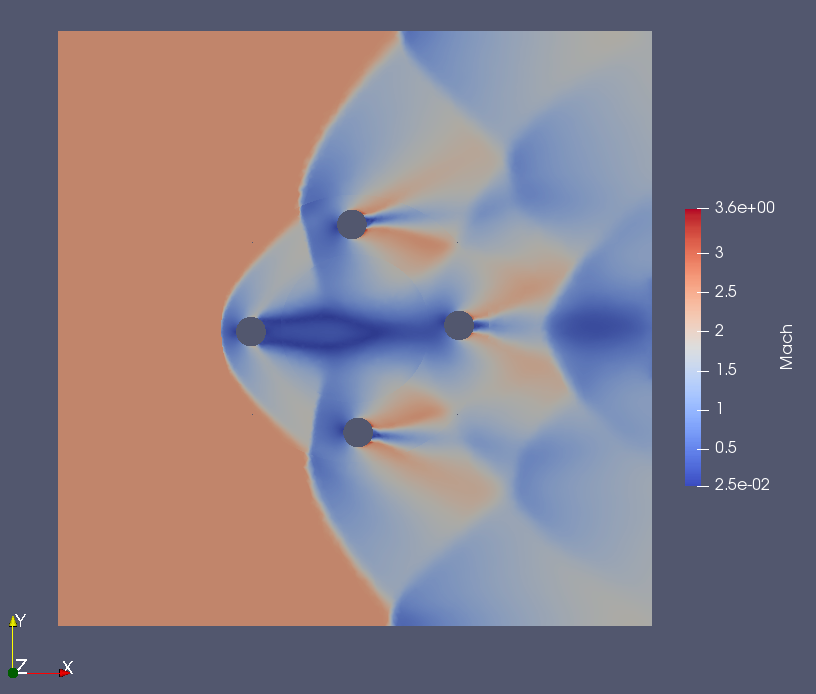
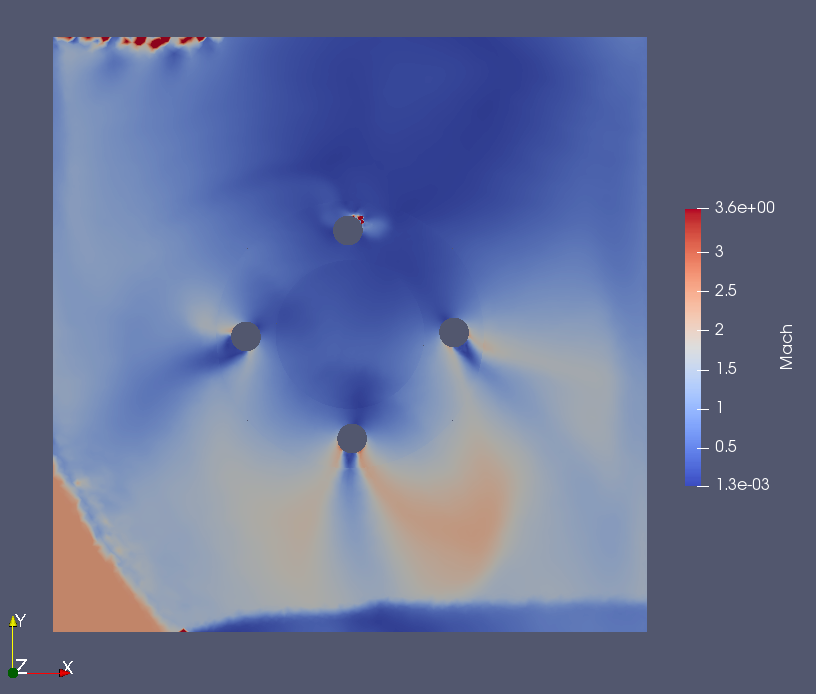
|
@pcarruscag Good that you mention it. I saw exactly the same behavior while working on #715. If I disable grid movement for the first zone (where grid velocity is 0 anyway because there is no rotation) it works. In my opinion having grid movement disabled or enabled and specifying zero movement should result in exactly the same convergence behavior ... |
|
I tested the MKL integration with the discrete adjoint, and everything looks ok, turns out to be only about 5% faster on a per iteration basis (i.e. excluding recording times). I had to grab some work from my other ongoing PR's to run a case with reasonable CFL settings so I am not going to upload files for this test. @economon , @talbring , if you do not mind me moving the files with significant changes on a separate PR, I think this is ready to go. |
|
@talbring : as you know, the difference between disabled and active grid movement with 0 velocity is that the former case does not even allocate the memory for the grid velocity at each node, and many conditionals checking for grid movement throughout the solver (fluxes, BCs) are avoided. This was to save memory and effort when grid motion is not needed, however, maybe we need to now change the strategy for multizone problems which may have both fixed and moving zones (perhaps always active with 0 as default). I am a little surprised they are not the same as well, but somewhere in the code path there must be an issue with this.. my guess is something related to BC_Fluid_Interface() or the transfer structure when grid movement is active on both sides but has a value of 0 on one of the interfaces. |
|
@pcarruscag For me its fine if you do it in a separate PR. @economon I also assume that is has something to do with how the interfaces are handled. We definitely have to check it. For now in PR #715 I enabled grid movement (in the config) also in fixed zones. |
|
If that case is so sensitive to be affected by the changes in this PR (it started converging without any change of options), it does not surprise me that other sources of numerical noise can have a similar influence. |
|
Ok for me to wait for another PR to break the other files. Would be good to get some additional reviews on this one from the community if folks have some time. |
|
|
||
| if ((kPoint >= jPoint) && (jPoint < (long)nPointDomain)) { | ||
| if (kPoint > jPoint) { | ||
|
|
There was a problem hiding this comment.
This was not a bug, but we overwrite the ij block completely so it is not necessary to update it here.
|
@economon no one seems to have time, let's get going please. |
 WallyMaier
left a comment
WallyMaier
left a comment
There was a problem hiding this comment.
The changes look good to me.
 EduardoMolina
left a comment
EduardoMolina
left a comment
There was a problem hiding this comment.
Thanks for this clean PR! I appreciate that you also update the config files in the TestCases folder.
Please revert the travis.yml before merge.
LGTM!
Eduardo
.travis.yml
Outdated
| before_script: | ||
| # Get the test cases | ||
| - git clone -b develop https://github.com/su2code/TestCases.git ./TestData | ||
| - git clone -b feature_refactor_lin_solvers https://github.com/su2code/TestCases.git ./TestData |
There was a problem hiding this comment.
Please revert before we merge.
| unsigned long Smoother_LinSolver(const VectorType & b, VectorType & x, ProductType & mat_vec, | ||
| PrecondType & precond, ScalarType tol, unsigned long m, | ||
| ScalarType *residual, bool monitoring, CConfig *config); | ||
|
|
There was a problem hiding this comment.
Thanks for the comments.
|
Thank you @WallyMaier and @EduardoMolina for the reviews. |
Proposed Changes
I made this in micro steps and the commit messages are fairly detailed, so here I will give only the highlights. Every change is mathematically equivalent.
I claim performance improvements based on the type of cases I run (steady RANS implicit, elasticity), results may vary, so please give this a try.
Cleanup
Performance
Bugs
ToDo
Related Work
#650, #653, #658
PR Checklist