-
Notifications
You must be signed in to change notification settings - Fork 1.7k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
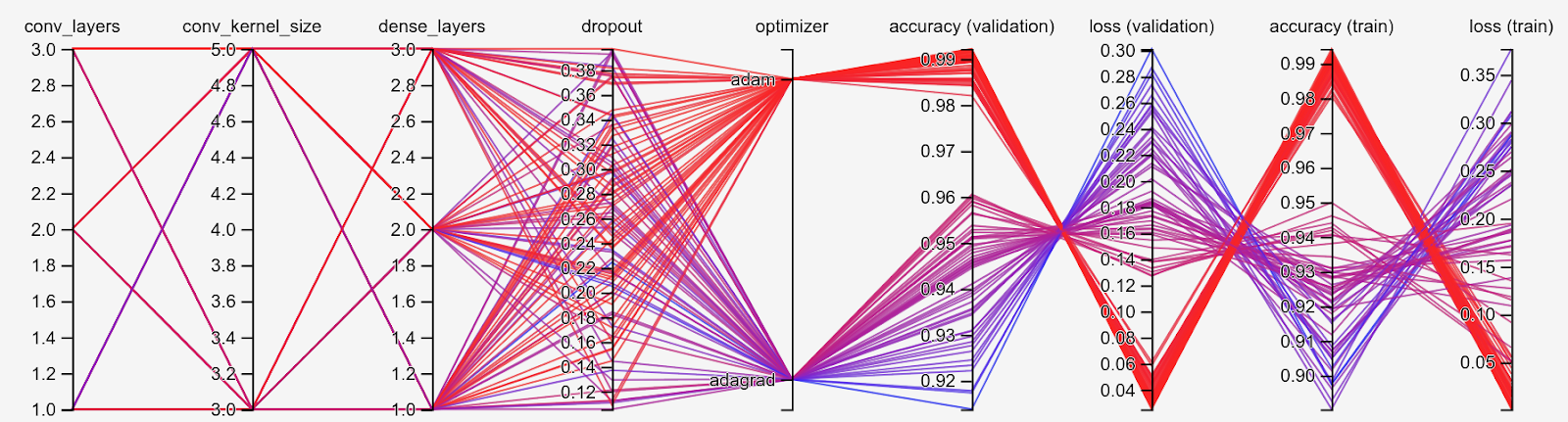
Summary: The existing demo in `hparams_demo.py` properly exercises the hparams functionality, but isn’t actually related to machine learning at all. This commit introduces a demo that trains a family of MNIST models. Some hyperparameters are critically important, while others end up having effectively no impact. The experiment includes categorical, discrete, and real-valued hyperparameters. The resulting parallel coordinates view looks something like this: ![Screenshot of the parallel coordinates view][parcoords] It’s immediately obvious that the `optimizer` parameter is in fact a perfect separator for both accuracy and loss, whereas the influence of the other hyperparameters is less clear. Filtering to the Adam-optimized sessions only, we can look at the scatter plot matrix: ![Screenshot of the scatter plot matrix for `optimizer="adam"`][matrix] Here, it’s easier to see that `dropout` and `dense_layers` appear to have negligible impact, while `conv_layers` and `conv_kernel_size` are each significant. [parcoords]: https://user-images.githubusercontent.com/4317806/56250030-cf26d180-6062-11e9-9b46-daf29d8c0229.png [matrix]: https://user-images.githubusercontent.com/4317806/56250052-e49bfb80-6062-11e9-911c-9bf4c868ef58.png This demo uses only the existing hparams APIs, even when they’re a bit awkward. We still need to manually manage file writers, construct protos (and `ListValue`s in particular…), and duplicate domain information across the experiment summary and our ad hoc tuner. Also, we can’t specify integer-valued hparams over ranges, because the `Interval` type applies only to real-valued hparams. As we improve these APIs (#1998), we can improve this demo! :-) Test Plan: Tested with `tf-nightly-2.0-preview==2.0.0.dev20190416`, Python 2 and 3. wchargin-branch: hparams-ml-demo
{kind=link}
{kind=link}
- Loading branch information
Showing
2 changed files
with
317 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,300 @@ | ||
| # Copyright 2019 The TensorFlow Authors. All Rights Reserved. | ||
| # | ||
| # Licensed under the Apache License, Version 2.0 (the "License"); | ||
| # you may not use this file except in compliance with the License. | ||
| # You may obtain a copy of the License at | ||
| # | ||
| # http://www.apache.org/licenses/LICENSE-2.0 | ||
| # | ||
| # Unless required by applicable law or agreed to in writing, software | ||
| # distributed under the License is distributed on an "AS IS" BASIS, | ||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| # See the License for the specific language governing permissions and | ||
| # limitations under the License. | ||
| # ============================================================================== | ||
| """Write sample summary data for the hparams plugin. | ||
| See also hparams_demo.py in this directory. | ||
| """ | ||
|
|
||
| from __future__ import absolute_import | ||
| from __future__ import division | ||
| from __future__ import print_function | ||
|
|
||
| import hashlib | ||
| import math | ||
| import os.path | ||
| import random | ||
| import shutil | ||
|
|
||
| from absl import app | ||
| from absl import flags | ||
| from google.protobuf import struct_pb2 | ||
| import numpy as np | ||
| import six | ||
| from six.moves import xrange # pylint: disable=redefined-builtin | ||
| import tensorflow as tf | ||
|
|
||
| from tensorboard.plugins.hparams import api_pb2 | ||
| from tensorboard.plugins.hparams import summary as hparams_summary | ||
|
|
||
|
|
||
| if int(tf.__version__.split(".")[0]) < 2: | ||
| # The tag names emitted for Keras metrics changed from "acc" (in 1.x) | ||
| # to "accuracy" (in 2.x), so this demo does not work properly in | ||
| # TensorFlow 1.x (even with `tf.enable_eager_execution()`). | ||
| raise ImportError("TensorFlow 2.x is required to run this demo.") | ||
|
|
||
|
|
||
| flags.DEFINE_integer( | ||
| "num_session_groups", | ||
| 30, | ||
| "The approximate number of session groups to create.", | ||
| ) | ||
| flags.DEFINE_string( | ||
| "logdir", | ||
| "/tmp/hparams_ml_demo", | ||
| "The directory to write the summary information to.", | ||
| ) | ||
| flags.DEFINE_integer( | ||
| "summary_freq", | ||
| 600, | ||
| "Summaries will be written every n steps, where n is the value of " | ||
| "this flag.", | ||
| ) | ||
| flags.DEFINE_integer( | ||
| "num_epochs", | ||
| 5, | ||
| "Number of epochs per trial.", | ||
| ) | ||
|
|
||
|
|
||
| # We'll use MNIST for this example. | ||
| DATASET = tf.keras.datasets.mnist | ||
| INPUT_SHAPE = (28, 28) | ||
| OUTPUT_CLASSES = 10 | ||
|
|
||
|
|
||
| def model_fn(hparams, seed): | ||
| """Create a Keras model with the given hyperparameters. | ||
| Args: | ||
| hparams: A dict mapping hyperparameter names to values. | ||
| seed: A hashable object to be used as a random seed (e.g., to | ||
| construct dropout layers in the model). | ||
| Returns: | ||
| A compiled Keras model. | ||
| """ | ||
| rng = random.Random(seed) | ||
|
|
||
| model = tf.keras.models.Sequential() | ||
| model.add(tf.keras.layers.Input(INPUT_SHAPE)) | ||
| model.add(tf.keras.layers.Reshape(INPUT_SHAPE + (1,))) # grayscale channel | ||
|
|
||
| # Add convolutional layers. | ||
| conv_filters = 8 | ||
| for _ in xrange(hparams["conv_layers"]): | ||
| model.add(tf.keras.layers.Conv2D( | ||
| filters=conv_filters, | ||
| kernel_size=hparams["conv_kernel_size"], | ||
| padding="same", | ||
| activation="relu", | ||
| )) | ||
| model.add(tf.keras.layers.MaxPool2D(pool_size=2, padding="same")) | ||
| conv_filters *= 2 | ||
|
|
||
| model.add(tf.keras.layers.Flatten()) | ||
| model.add(tf.keras.layers.Dropout(hparams["dropout"], seed=rng.random())) | ||
|
|
||
| # Add fully connected layers. | ||
| dense_neurons = 32 | ||
| for _ in xrange(hparams["dense_layers"]): | ||
| model.add(tf.keras.layers.Dense(dense_neurons, activation="relu")) | ||
| dense_neurons *= 2 | ||
|
|
||
| # Add the final output layer. | ||
| model.add(tf.keras.layers.Dense(OUTPUT_CLASSES, activation="softmax")) | ||
|
|
||
| model.compile( | ||
| loss="sparse_categorical_crossentropy", | ||
| optimizer=hparams["optimizer"], | ||
| metrics=["accuracy"], | ||
| ) | ||
| return model | ||
|
|
||
|
|
||
| def run(data, base_logdir, session_id, group_id, hparams): | ||
| """Run a training/validation session. | ||
| Flags must have been parsed for this function to behave. | ||
| Args: | ||
| data: The data as loaded by `prepare_data()`. | ||
| base_logdir: The top-level logdir to which to write summary data. | ||
| session_id: A unique string ID for this session. | ||
| group_id: The string ID of the session group that includes this | ||
| session. | ||
| hparams: A dict mapping hyperparameter names to values. | ||
| """ | ||
| model = model_fn(hparams=hparams, seed=session_id) | ||
| logdir = os.path.join(base_logdir, session_id) | ||
|
|
||
| # We need a manual summary writer for writing hparams metadata. | ||
| writer = tf.summary.create_file_writer(logdir) | ||
| with writer.as_default(): | ||
| pb = hparams_summary.session_start_pb(hparams, group_name=group_id) | ||
| tf.summary.experimental.write_raw_pb(pb.SerializeToString(), step=0) | ||
| writer.flush() | ||
|
|
||
| callback = tf.keras.callbacks.TensorBoard( | ||
| logdir, | ||
| update_freq=flags.FLAGS.summary_freq, | ||
| profile_batch=0, # workaround for issue #2084 | ||
| ) | ||
| ((x_train, y_train), (x_test, y_test)) = data | ||
| result = model.fit( | ||
| x=x_train, | ||
| y=y_train, | ||
| epochs=flags.FLAGS.num_epochs, | ||
| shuffle=False, | ||
| validation_data=(x_test, y_test), | ||
| callbacks=[callback], | ||
| ) | ||
|
|
||
| with writer.as_default(): | ||
| pb = hparams_summary.session_end_pb(api_pb2.STATUS_SUCCESS) | ||
| tf.summary.experimental.write_raw_pb(pb.SerializeToString(), step=0) | ||
| writer.flush() | ||
| writer.close() | ||
|
|
||
|
|
||
| def prepare_data(): | ||
| """Load and normalize data.""" | ||
| ((x_train, y_train), (x_test, y_test)) = DATASET.load_data() | ||
| x_train = x_train.astype("float32") | ||
| x_test = x_test.astype("float32") | ||
| x_train /= 255.0 | ||
| x_test /= 255.0 | ||
| return ((x_train, y_train), (x_test, y_test)) | ||
|
|
||
|
|
||
| def create_experiment_summary(): | ||
| """Create an `api_pb2.Experiment` proto describing the experiment.""" | ||
| def discrete_domain(values): | ||
| domain = struct_pb2.ListValue() | ||
| domain.extend(values) | ||
| return domain | ||
|
|
||
| hparams = [ | ||
| api_pb2.HParamInfo( | ||
| name="conv_layers", | ||
| type=api_pb2.DATA_TYPE_FLOAT64, # actually int | ||
| domain_discrete=discrete_domain([1, 2, 3]), | ||
| ), | ||
| api_pb2.HParamInfo( | ||
| name="conv_kernel_size", | ||
| type=api_pb2.DATA_TYPE_FLOAT64, # actually int | ||
| domain_discrete=discrete_domain([3, 5]), | ||
| ), | ||
| api_pb2.HParamInfo( | ||
| name="dense_layers", | ||
| type=api_pb2.DATA_TYPE_FLOAT64, # actually int | ||
| domain_discrete=discrete_domain([1, 2, 3]), | ||
| ), | ||
| api_pb2.HParamInfo( | ||
| name="dropout", | ||
| type=api_pb2.DATA_TYPE_FLOAT64, | ||
| domain_interval=api_pb2.Interval(min_value=0.1, max_value=0.4), | ||
| ), | ||
| api_pb2.HParamInfo( | ||
| name="optimizer", | ||
| type=api_pb2.DATA_TYPE_STRING, | ||
| domain_discrete=discrete_domain(["adam", "adagrad"]), | ||
| ), | ||
| ] | ||
| metrics = [ | ||
| api_pb2.MetricInfo( | ||
| name=api_pb2.MetricName(group="validation", tag="epoch_accuracy"), | ||
| display_name="accuracy (val.)", | ||
| ), | ||
| api_pb2.MetricInfo( | ||
| name=api_pb2.MetricName(group="validation", tag="epoch_loss"), | ||
| display_name="loss (val.)", | ||
| ), | ||
| api_pb2.MetricInfo( | ||
| name=api_pb2.MetricName(group="train", tag="batch_accuracy"), | ||
| display_name="accuracy (train)", | ||
| ), | ||
| api_pb2.MetricInfo( | ||
| name=api_pb2.MetricName(group="train", tag="batch_loss"), | ||
| display_name="loss (train)", | ||
| ), | ||
| ] | ||
| return hparams_summary.experiment_pb( | ||
| hparam_infos=hparams, | ||
| metric_infos=metrics, | ||
| ) | ||
|
|
||
|
|
||
| def run_all(logdir, verbose=False): | ||
| """Perform random search over the hyperparameter space. | ||
| Arguments: | ||
| logdir: The top-level directory into which to write data. This | ||
| directory should be empty or nonexistent. | ||
| verbose: If true, print out each run's name as it begins. | ||
| """ | ||
| data = prepare_data() | ||
| rng = random.Random(0) | ||
|
|
||
| base_writer = tf.summary.create_file_writer(logdir) | ||
| with base_writer.as_default(): | ||
| experiment_string = create_experiment_summary().SerializeToString() | ||
| tf.summary.experimental.write_raw_pb(experiment_string, step=0) | ||
| base_writer.flush() | ||
| base_writer.close() | ||
|
|
||
| sessions_per_group = 2 | ||
| num_sessions = flags.FLAGS.num_session_groups * sessions_per_group | ||
| session_index = 0 # across all session groups | ||
| for group_index in xrange(flags.FLAGS.num_session_groups): | ||
| hparams = { | ||
| "conv_layers": rng.randint(1, 3), | ||
| "conv_kernel_size": rng.choice([3, 5]), | ||
| "dense_layers": rng.randint(1, 3), | ||
| "dropout": rng.uniform(0.1, 0.4), | ||
| "optimizer": rng.choice(["adam", "adagrad"]) | ||
| } | ||
| hparams_string = str(hparams) | ||
| group_id = hashlib.sha256(hparams_string.encode("utf-8")).hexdigest() | ||
| for repeat_index in xrange(sessions_per_group): | ||
| session_id = str(session_index) | ||
| session_index += 1 | ||
| if verbose: | ||
| print( | ||
| "--- Running training session %d/%d" | ||
| % (session_index, num_sessions) | ||
| ) | ||
| print(hparams_string) | ||
| print("--- repeat #: %d" % (repeat_index + 1)) | ||
| run( | ||
| data=data, | ||
| base_logdir=logdir, | ||
| session_id=session_id, | ||
| group_id=group_id, | ||
| hparams=hparams, | ||
| ) | ||
|
|
||
|
|
||
| def main(unused_argv): | ||
| np.random.seed(0) | ||
| logdir = flags.FLAGS.logdir | ||
| shutil.rmtree(logdir, ignore_errors=True) | ||
| print("Saving output to %s." % logdir) | ||
| run_all(logdir=logdir, verbose=True) | ||
| print("Done. Output saved to %s." % logdir) | ||
|
|
||
|
|
||
| if __name__ == "__main__": | ||
| app.run(main) |