Design a public Python API for the hparams plugin #1998
Comments
|
Thanks for this awesome plugin, this is really a useful addition to Tensorboard. After using it in my project, I have some comments:
Just some small comments, amazing work overall 🥇 |
|
Hi @omoindrot—thanks for writing in, and glad to hear that you like it!
I was wondering the same thing. The parallel coordinates view and the
This should already be supported: tensorboard/tensorboard/plugins/hparams/api.proto Lines 90 to 96 in 25dc3e8 …though our tutorials don’t use it and it’s only mentioned in a proto
Great point; I’ve opened #2014 to track this. |
|
@wchargin can we add int64 dtype in DataType(present in api.proto) as requested by @omoindrot |
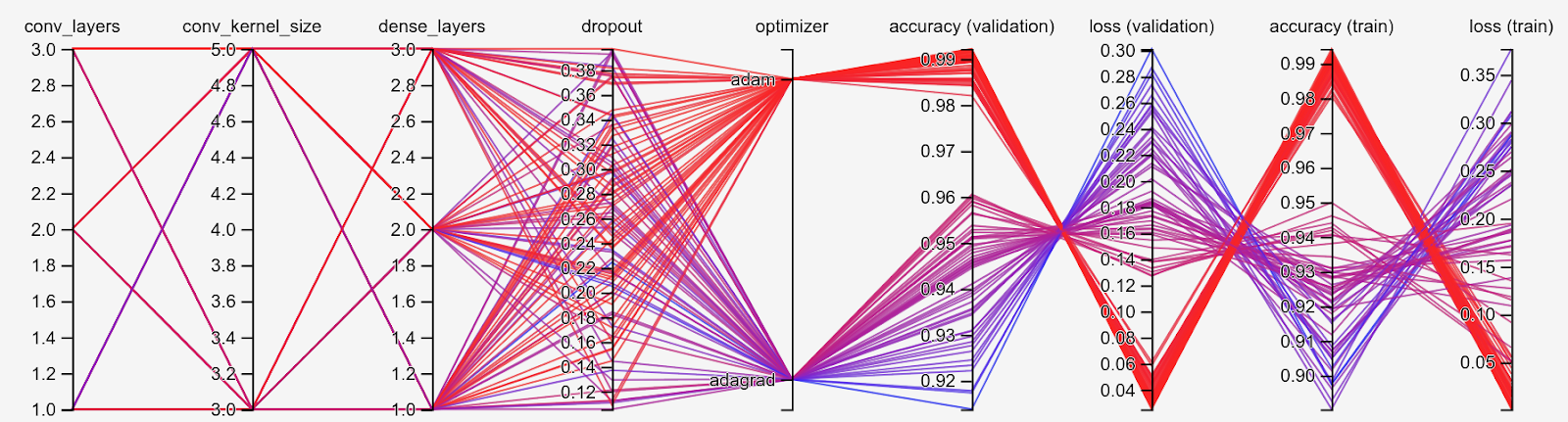
Summary: The existing demo in `hparams_demo.py` properly exercises the hparams functionality, but isn’t actually related to machine learning at all. This commit introduces a demo that trains a family of MNIST models. Some hyperparameters are critically important, while others end up having effectively no impact. The experiment includes categorical, discrete, and real-valued hyperparameters. The resulting parallel coordinates view looks something like this: ![Screenshot of the parallel coordinates view][parcoords] It’s immediately obvious that the `optimizer` parameter is in fact a perfect separator for both accuracy and loss, whereas the influence of the other hyperparameters is less clear. Filtering to the Adam-optimized sessions only, we can look at the scatter plot matrix: ![Screenshot of the scatter plot matrix for `optimizer="adam"`][matrix] Here, it’s easier to see that `dropout` and `dense_layers` appear to have negligible impact, while `conv_layers` and `conv_kernel_size` are each significant. [parcoords]: https://user-images.githubusercontent.com/4317806/56250030-cf26d180-6062-11e9-9b46-daf29d8c0229.png [matrix]: https://user-images.githubusercontent.com/4317806/56250052-e49bfb80-6062-11e9-911c-9bf4c868ef58.png This demo uses only the existing hparams APIs, even when they’re a bit awkward. We still need to manually manage file writers, construct protos (and `ListValue`s in particular…), and duplicate domain information across the experiment summary and our ad hoc tuner. Also, we can’t specify integer-valued hparams over ranges, because the `Interval` type applies only to real-valued hparams. As we improve these APIs (#1998), we can improve this demo! :-) Test Plan: Tested with `tf-nightly-2.0-preview==2.0.0.dev20190416`, Python 2 and 3. wchargin-branch: hparams-ml-demo
Summary: The existing demo in `hparams_demo.py` properly exercises the hparams functionality, but isn’t actually related to machine learning at all. This commit introduces a demo that trains a family of MNIST models. Some hyperparameters are critically important, while others end up having effectively no impact. The experiment includes categorical, discrete, and real-valued hyperparameters. The resulting parallel coordinates view looks something like this: ![Screenshot of the parallel coordinates view][parcoords] It’s immediately obvious that the `optimizer` parameter is in fact a perfect separator for both accuracy and loss, whereas the influence of the other hyperparameters is less clear. Filtering to the Adam-optimized sessions only, we can look at the scatter plot matrix: ![Screenshot of the scatter plot matrix for `optimizer="adam"`][matrix] Here, it’s easier to see that `dropout` and `dense_layers` appear to have negligible impact, while `conv_layers` and `conv_kernel_size` are each significant. [parcoords]: https://user-images.githubusercontent.com/4317806/56250030-cf26d180-6062-11e9-9b46-daf29d8c0229.png [matrix]: https://user-images.githubusercontent.com/4317806/56250052-e49bfb80-6062-11e9-911c-9bf4c868ef58.png This demo uses only the existing hparams APIs, even when they’re a bit awkward. We still need to manually manage file writers, construct protos (and `ListValue`s in particular…), and duplicate domain information across the experiment summary and our ad hoc tuner. Also, we can’t specify integer-valued hparams over ranges, because the `Interval` type applies only to real-valued hparams. As we improve these APIs (#1998), we can improve this demo! :-) Test Plan: Tested with `tf-nightly-2.0-preview==2.0.0.dev20190416`, Python 2 and 3. wchargin-branch: hparams-ml-demo
Summary: This change introduces `HParam`, `Metric`, and `Experiment` classes, which represent their proto counterparts in a more Python-friendly way. It similarly includes a `Domain` class hierarchy, which does not correspond to a specific proto message, but rather unifies the domain variants defined on the `HParamInfo` proto. The design is roughly as in the original sketch of #1998. The primary benefit of this change is that having first-class domains enables clients to reuse the domain information for both the experiment summary and the underlying tuning algorithm. We don’t provide a method to do this out of the box, because we don’t actually provide any tuners at this time, but it’s easy to write (e.g.) a `sample_uniform` function like the one included in this commit. Then, sampling is as easy as ```python hparams = {h: sample_uniform(h.domain, rng) for h in HPARAMS} ``` It is also now more convenient to reference hparam values such that static analysis can detect potential typos, because the `HParam` objects themselves can be declared as constants and used as keys in a dict. Writing `hparams["dropuot"]` fails at runtime, but `hparams[HP_DROPUOT]` fails at lint time. As a pleasant bonus, hparam definitions are now more compact, fitting on one line instead of several. The demo code has net fewer lines. Manual summary writer management is still required. A future change will introduce a Keras callback to reduce this overhead. Test Plan: Some unit tests included, and the demo still works. wchargin-branch: hparams-structured-api
Summary: This change introduces `HParam`, `Metric`, and `Experiment` classes, which represent their proto counterparts in a more Python-friendly way. It similarly includes a `Domain` class hierarchy, which does not correspond to a specific proto message, but rather unifies the domain variants defined on the `HParamInfo` proto. The design is roughly as in the original sketch of #1998. The primary benefit of this change is that having first-class domains enables clients to reuse the domain information for both the experiment summary and the underlying tuning algorithm. We don’t provide a method to do this out of the box, because we don’t actually provide any tuners at this time, but it’s easy to write (e.g.) a `sample_uniform` function like the one included in this commit. Then, sampling is as easy as ```python hparams = {h: sample_uniform(h.domain, rng) for h in HPARAMS} ``` It is also now more convenient to reference hparam values such that static analysis can detect potential typos, because the `HParam` objects themselves can be declared as constants and used as keys in a dict. Writing `hparams["dropuot"]` fails at runtime, but `hparams[HP_DROPUOT]` fails at lint time. As a pleasant bonus, hparam definitions are now more compact, fitting on one line instead of several. The demo code has net fewer lines. Manual summary writer management is still required. A future change will introduce a Keras callback to reduce this overhead. Test Plan: Some unit tests included, and the demo still works. wchargin-branch: hparams-structured-api
Summary: A new `hparams.api.KerasCallback` class simplifies client APIs by writing session start and end summaries automatically, with a dict of hparams provided by the client. Cf. #1998. This only works in TensorFlow eager mode. The stock `TensorBoard` Keras callback works in both eager and graph modes, but to do so it must use TensorFlow-internal symbols (`eager_mode` and `executing_eagerly` on the context object, which we do not have access to). Test Plan: Unit tests included. The demo still works, generating valid data. wchargin-branch: hparams-keras-callback
Summary: The `Experiment` object bundled `HParam`s and `Metric`s with some metadata that’s not actually used in the current UI. We don’t think that it pulls its conceptual weight, so this commit replaces it with a direct summary-writing operation. This function will soon be extracted into a `summary_pb2` module, as part of a [larger plan to refactor the `api` module][1]. Making this change first minimizes churn in the demo code. [1]: #2139 (comment) Cf. #1998. Test Plan: Unit tests modified appropriately, and the demo still works. wchargin-branch: hparams-experiment-writing
|
A few people have expressed confusion about the term “session” as used I propose omitting “session” from new API symbols where feasible, and
—and, I think, also suggests the correct meaning. “Session groups” would most literally become “trial groups”, though this Even better, though, I think that we can avoid asking for session group |
|
Some thoughts: even having a separate "trial/trial group" concept seems a little unwieldy to me. What if we just called them "runs" to use the terminology from the rest of TensorBoard? The mapping is not exact, but I think in the common cases the concepts do align, and it seems better to me to share terminology in the common cases than introduce new terms just to be slightly more exact in the less common cases. In the long run, it would make sense for "runs" to be more conceptually defined anyway - the "subdirectory with event files in it" definition doesn't apply to database-first summaries, for example. Off the top of my head, the cases where trials don't exactly match up with runs are:
|
|
If I may throw in my opinion, I have been trying out the API and I totally agree with @wchargin about
The "sessions" term is very confusing. Trial groups might not be perfect but more intuitive. On another note, I will be happy to start contributing to this plugin in the near future, since I am planning to make use of it once 1.14 gets released :) |
|
Hey @moritzmeister: thanks a ton for trying out the new APIs. This We can certainly add a
Excellent! Looking forward to it. :-) |
Summary: Resolves #2440. See #1998 for discussion. Test Plan: The hparams demo still does not specify trial IDs (intentionally, as this is the usual path). But apply the following patch— ```diff diff --git a/tensorboard/plugins/hparams/hparams_demo.py b/tensorboard/plugins/hparams/hparams_demo.py index ac4e762b..d0279f27 100644 --- a/tensorboard/plugins/hparams/hparams_demo.py +++ b/tensorboard/plugins/hparams/hparams_demo.py @@ -63,7 +63,7 @@ flags.DEFINE_integer( ) flags.DEFINE_integer( "num_epochs", - 5, + 1, "Number of epochs per trial.", ) @@ -160,7 +160,7 @@ def model_fn(hparams, seed): return model -def run(data, base_logdir, session_id, hparams): +def run(data, base_logdir, session_id, trial_id, hparams): """Run a training/validation session. Flags must have been parsed for this function to behave. @@ -179,7 +179,7 @@ def run(data, base_logdir, session_id, hparams): update_freq=flags.FLAGS.summary_freq, profile_batch=0, # workaround for issue #2084 ) - hparams_callback = hp.KerasCallback(logdir, hparams) + hparams_callback = hp.KerasCallback(logdir, hparams, trial_id=trial_id) ((x_train, y_train), (x_test, y_test)) = data result = model.fit( x=x_train, @@ -235,6 +235,7 @@ def run_all(logdir, verbose=False): data=data, base_logdir=logdir, session_id=session_id, + trial_id="trial-%d" % group_index, hparams=hparams, ) ``` —and then run `//tensorboard/plugins/hparams:hparams_demo`, and observe that the HParams dashboard renders a “Trial ID” column with the specified IDs: ![Screenshot of new version of HParams dashboard] [1]: https://user-images.githubusercontent.com/4317806/61491024-1fb01280-a963-11e9-8a47-35e0a01f3691.png wchargin-branch: hparams-trial-id
Summary: Resolves #2440. See #1998 for discussion. Test Plan: The hparams demo still does not specify trial IDs (intentionally, as this is the usual path). But apply the following patch— ```diff diff --git a/tensorboard/plugins/hparams/hparams_demo.py b/tensorboard/plugins/hparams/hparams_demo.py index ac4e762b..38b2b122 100644 --- a/tensorboard/plugins/hparams/hparams_demo.py +++ b/tensorboard/plugins/hparams/hparams_demo.py @@ -160,7 +160,7 @@ def model_fn(hparams, seed): return model -def run(data, base_logdir, session_id, hparams): +def run(data, base_logdir, session_id, trial_id, hparams): """Run a training/validation session. Flags must have been parsed for this function to behave. @@ -179,7 +179,7 @@ def run(data, base_logdir, session_id, hparams): update_freq=flags.FLAGS.summary_freq, profile_batch=0, # workaround for issue #2084 ) - hparams_callback = hp.KerasCallback(logdir, hparams) + hparams_callback = hp.KerasCallback(logdir, hparams, trial_id=trial_id) ((x_train, y_train), (x_test, y_test)) = data result = model.fit( x=x_train, @@ -235,6 +235,7 @@ def run_all(logdir, verbose=False): data=data, base_logdir=logdir, session_id=session_id, + trial_id="trial-%d" % group_index, hparams=hparams, ) ``` —and then run `//tensorboard/plugins/hparams:hparams_demo`, and observe that the HParams dashboard renders a “Trial ID” column with the specified IDs: ![Screenshot of new version of HParams dashboard][1] [1]: https://user-images.githubusercontent.com/4317806/61491024-1fb01280-a963-11e9-8a47-35e0a01f3691.png wchargin-branch: hparams-trial-id
|
@moritzmeister: Long delay, I know, but: I’ve just added a I’m going to close this issue, since its original purpose has been |
|
@wchargin Could we also include the run name (folder name) in the summary table too? So that you can easily link the data in the scalars tab with HPARMS |
|
@joshlk: There’s not a one-to-one correspondence; a single trial can Do note that you can check the “Show Metrics” box in the table view to
|

|
@wchargin Do you have an example of multiple runs per trail? How would that work? Do you take the average of the metrics in the display? |
|
@joshlk: Yes, the default is to take the average of each metric
The hparams demo script emits two runs per trial. For a trivial from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from tensorboard.plugins.hparams import api as hp
import tensorflow.compat.v2 as tf
__import__("tensorflow").compat.v1.enable_eager_execution()
with tf.summary.create_file_writer("a").as_default():
hp.hparams({"learning_rate": 0.2})
tf.summary.scalar("loss", 0.1, step=0)
tf.summary.scalar("accuracy", 0.8, step=0)
with tf.summary.create_file_writer("b").as_default():
hp.hparams({"learning_rate": 0.2})
tf.summary.scalar("loss", 0.3, step=0)
tf.summary.scalar("accuracy", 0.9, step=0)Then, launch
|

{kind=link}
{kind=link}
{kind=link}
|
@wchargin Thanks thats a really useful feature! 👍 I've been using the HParams feature for a couple of days now and it would still be really great to link the Tail ID to the Runs as otherwise the HParams tab is totally disconnected from Scalars. The HParams tab doesn't have the same overview of all runs like the Scalars tab does. When I look at the results I start from the Scalars tab and identify the runs that are doing well but then its very difficult for me to find those runs in the HParams tab. Maybe it could show the runs IDs when you select show metrics. Or you could filter by run ID on the right side. |
|
@joshlk: Yep; we generally agree. The original vision was that the Also filed #2464 to track aggregation support. |
|
@wchargin Great - thanks for the work! |
Summary: Active development of these APIs has completed, and they were published in the 1.14 release notes. Closes #1998. wchargin-branch: hparams-public-api
Summary: Active development of these APIs has completed, and they were published in the 1.14 release notes. Closes #1998. wchargin-branch: hparams-public-api
To use the hparams dashboard, users currently have to manually construct
hparams-specific protocol buffers and send them to file
writers (see the tutorial notebook for an example; it takes a few
dozen lines of Python code). The protobuf bindings are not particularly
idiomatic Python, and are less than pleasant to use. We should
investigate possible simplifications to this API.
For example, we could streamline the construction of the
ListValuesfor the discrete domains by allowing the user to pass Python lists, and
we can also infer the data types from the types of the elements of the
domain* (which also lets us require that the list is homogeneously
typed):
This is just a sketch, but it’s already three times shorter than the
current demo without (imho) any loss of utility.
* It’s fine to prohibit empty domains here. If a hyperparameter has
empty domain, then the whole hyperparameter space is empty, so there can
be no runs; thus, allowing empty domains is not actually useful.
The text was updated successfully, but these errors were encountered: