rust: load runs in parallel #4634
Conversation
Summary: The [`rayon`] crate provides easy data parallelism: change `iter()` to `par_iter()` and you’re off to the races—but not the data races, which are prevented at compile time. We can use it to load runs concurrently. [`rayon`]: https://crates.io/crates/rayon Test Plan: It builds: `bazel build //third_party/rust:rayon`. wchargin-branch: rust-dep-rayon wchargin-source: 743dee6a68571fd8849ea4dfd240169bcfbe1feb
Summary: A `LogdirLoader` now loads multiple runs at once. Each individual run is still loaded sequentially (no parallelism across or within event files). A thread pool is owned by a `LogdirLoader` and is reused for subsequent calls to `reload` on the same receiver. The thread pool size is configurable, and by default is [automatically chosen][nt] based on the number of logical CPUs. This implementation uses the Rayon library for parallelism. The tasks that we enqueue onto thread pools have references to local variables, so we can’t directly use [`std::thread::spawn`], whose closure is required to only contain static references. We can use [`crossbeam::scope`] to easily capture local variables in child threads, but then the threads are tied to a particular reload cycle. Rayon makes it easy to have a long-lived thread pool where each task has a separately scoped lifetime. [nt]: https://docs.rs/rayon/1.5.0/rayon/struct.ThreadPoolBuilder.html#method.num_threads [`std::thread::spawn`]: https://doc.rust-lang.org/std/thread/fn.spawn.html [`crossbeam::scope`]: https://docs.rs/crossbeam/0.8.0/crossbeam/fn.scope.html Test Plan: Running on a logdir with all the TensorBoard demo data, clocking in at 544 MB with 218 runs, we benchmark total load time as a function of thread pool size: ``` hyperfine -w3 -m25 \ './target/release/bench --logdir ~/tensorboard_data --reload-threads {threads}' \ -P threads 0 32 ``` ![Chart of reload time as a function of thread count. The curve starts at 0.34 seconds for 1 thread, then curves down to about 0.15 seconds for thread counts between 5 and 12, inclusive (all within error bars of each other). It then slowly curves back up, finishing around 0.23 seconds for 32 threads.][chart] When running TensorBoard with `--load_fast` on `edge_cgan`, the first load cycle now takes 3.09s on my machine, instead of 8.26s. [chart]: https://user-images.githubusercontent.com/4317806/106346290-df756400-626a-11eb-8539-453f8f0b3865.png wchargin-branch: rust-run-parallelism wchargin-source: cd656743bfbb3d415ca5dea5876aba9e9c013b25
{kind=link}
|
Not sure in which environment you have tested this but here are my runs (reporting the M1 perf; all in release mode): |
|
Ooh, sweet, thanks! I’m assuming that “before” and “after” are before My environment was a workstation with a W-2135 CPU and 64 GB RAM, also Nice numbers—cool to see that the M1 solidly outclocks the 2017 MBP. |
Yup
Correct. Initially, I saw so much variance between trials on 2017 MBP which I later reduced down to zombie Python2.7 process sucking up all the CPU cycles causing high variance.
I used the edge_cgan. I took the liberty to test the M1 against the
Yeah... except I cannot run Bazel just yet. They recently added the support and it is not released yet (bazelbuild/bazel@8c7e11a; it is my laziness, not technical blockage). As such, I did not test the whole flow e2e but instead just ran the |
It’s pretty good. My Xeon W-2135 takes 165.4 seconds for
FWIW, our Pip packages are also built via Cargo, not Bazel (for the same |
 nfelt
left a comment
nfelt
left a comment
There was a problem hiding this comment.
Wow, this seems almost too good to be true in how straightforward it is - nice.
Out of curiosity, how badly interleaved is the logging from the individual run loaders when this is actually executing in parallel?
| run | ||
| ) | ||
| }); | ||
| work_items.push((&mut run_state.loader, filenames, run_data)); |
There was a problem hiding this comment.
I might just be tying myself in knots here, but do you have any thoughts for how I can better understand the logic the borrow checker uses to handle this kind of case where we mutably borrow each run_state.loader and push them all into another vector for later extraction? I guess the original self.runs lifetime is the outer bound for the individual loaders, and then the Vec inherits their lifetime, but then we take the loaders back out of Vec - and I guess the lifetime follows them through to wherever they go? But presumably it's also somehow attached to the Vec itself now, right, so even if we were to empty the Vec entirely and then try to go refill it without dropping it in between, that would still prevent mutation of self.runs even though the actual loader references are all gone?
There was a problem hiding this comment.
Yep. Let’s spelunk through the logic:
- This method takes
&mut self; call that elided lifetime'1, so
it’sfn load_runs<'1>(&'1 mut self, ...). - We borrow
self.runs.iter_mut()for lifetime'2, which must not
outlive'1so that it doesn’t outlive borrowed content. - Then we borrow
&mut run_state.loader, for lifetime'3, which
must not outlive'3so that it doesn’t outlive that loan. - These are the lifetime upper bounds:
'1: '2and'2: '3, where
“:” is a subtyping relation that you can pronounce “outlives (or
is equal to)”. You’ll often seeT: 'staticto indicate thatT
has only static references (“outlives everything”). - We have a
Vec::<(&'v mut RunLoader, ...)>for some lifetime'v.
Since wepushitems with lifetime'3, we must have'3: 'v: the
referenced content must outlive the vector. - Now, we move
work_itemsinto the closure arg toinstall. From
here on out, there aren’t really any more lifetimes: we call
into_par_iterandfor_each, both of which are simply typed
methods with by-value receivers. In particular, neither of them has
a lifetime bound on its closure type, unlikestd::thread::spawn.
You can similarly analyze the lifetime flow for the &RwLock<...>
lifetime. You’ll get something like this:
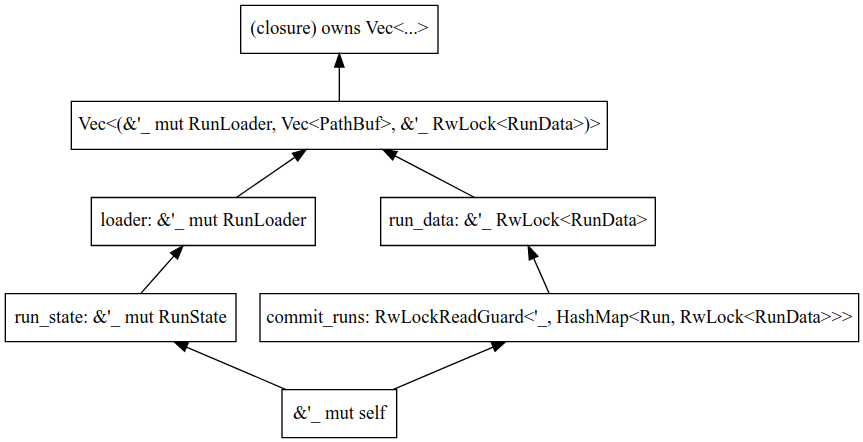
(Here, an arrow from a to b means a: b.)
Writing it out, the inference looks pretty unidirectional here: we
require '1: '2: '3: 'v, but there’s nothing concrete at the end of
that chain, so this is satisfiable by (e.g.) setting '1 = '2 = '3 = 'v
and the borrow checker is happy.
If we had called std::thread::spawn instead of install, we would
then require 'v: 'static, since spawn requires that F: 'static
(where F is the type of the closure), and we have 'v: F since the
vector must live as long as the closure itself. This transitively means
that the whole diagram must outlive 'static. But '1 was arbitrary:
it’s the lifetime to the receiver parameter. Thus, this isn’t
satisfiable in general and should be a borrowck error.
Let’s see what Rustc has to say. In this patch, I’ve dropped the
run_data arg so that the compiler is forced to complain about the left
branch of the graph above rather than the right branch (it’s the same
logic, just not the one that you asked about):
diff --git a/tensorboard/data/server/logdir.rs b/tensorboard/data/server/logdir.rs
--- a/tensorboard/data/server/logdir.rs
+++ b/tensorboard/data/server/logdir.rs
@@ -277,12 +277,13 @@ impl<'a> LogdirLoader<'a> {
run
)
});
- work_items.push((&mut run_state.loader, filenames, run_data));
+ work_items.push((&mut run_state.loader, filenames));
}
- self.thread_pool.install(|| {
- work_items
- .into_par_iter()
- .for_each(|(loader, filenames, run_data)| loader.reload(filenames, run_data));
+ drop(commit_runs);
+ std::thread::spawn(move || {
+ for (loader, filenames) in work_items.into_iter() {
+ loader.reload(filenames, todo!("omitted for example"));
+ }
});
}
}Rustc says:
error[E0759]: `self` has an anonymous lifetime `'_` but it needs to satisfy a `'static` lifetime requirement
--> logdir.rs:268:43
|
259 | fn load_runs(&mut self, discoveries: Discoveries) {
| --------- this data with an anonymous lifetime `'_`...
...
268 | for (run, run_state) in self.runs.iter_mut() {
| --------- ^^^^^^^^
| |
| ...is captured here...
...
283 | std::thread::spawn(move || {
| ------------------ ...and is required to live as long as `'static` here
This is pointing out the transitive '1: '2: 'static chain and
complaining about its unsatisfiability.
So how can Rayon’s install or Crossbeam’s scope get away with this
while thread::spawn needs the 'static requirement? The key is that
the scoped thread implementations ensure that the callback finishes
before install/scope itself returns. Thus, the borrowed content only
needs to live as long as the call to install, which is on the caller’s
stack frame and is thus known to be outlived by '1. Under the hood,
both of these will call thread::spawn after using unsafe to
transmute your closure to 'static. (If “unsafe” is surprising
here, remember that soundness is what we care about. “Sound” means “in
no real execution will it trigger undefined behavior”; “safe” means “the
compiler has statically proven that it is sound”; “unsafe” means “the
code author has statically proven that it is sound based on properties
too advanced to be represented in the base type system”. We use sound
unsafe code to build safe abstractions.)
But presumably it's also somehow attached to the
Vecitself now, right, so even if we were to empty theVecentirely and then try to go refill it without dropping it in between, that would still prevent mutation ofself.runseven though the actual loader references are all gone?
Yeah, definitely. You can get that kind of flexibility with RefCell,
which basically pushes the borrow checking to runtime. (Follows a Rust
pattern: you can have dynamic borrow checking, dynamic dispatch, dynamic
reference counting, dynamic typing (std::any), but you have to opt in,
and sometimes accept consequences like “your type is no longer Sync”.)
But a humble Vec<_> isn’t that smart by default.
Does this help?
There was a problem hiding this comment.
Got it, that helps! Thanks very much for the thorough explanation.
| run | ||
| ) | ||
| }); | ||
| work_items.push((&mut run_state.loader, filenames, run_data)); |
There was a problem hiding this comment.
Just to check my understanding, this is a Vec of the parameters to the closures we ultimately run, rather than the closures themselves, because the closures even though they are all identically structured here are in fact all different anonymous types, so we can't put them in a Vec directly (we'd have to used a boxed FnMut or something).
There was a problem hiding this comment.
Good question. Assuming that you’re talking about the closure argument
to for_each (currently line 285): my understanding is that these are
all the same closure type. The type is anonymous (you can’t name it),
but you can capture it (much like how in Java if you have a Foo<?> you
can pass it to a <T>helper(Foo<T>) to give T a local name). So we
could also write this:
diff --git a/tensorboard/data/server/logdir.rs b/tensorboard/data/server/logdir.rs
index 23ff65893..cbab00442 100644
--- a/tensorboard/data/server/logdir.rs
+++ b/tensorboard/data/server/logdir.rs
@@ -277,12 +277,11 @@ impl<'a> LogdirLoader<'a> {
run
)
});
- work_items.push((&mut run_state.loader, filenames, run_data));
+ let loader = &mut run_state.loader;
+ work_items.push(move || loader.reload(filenames, run_data));
}
self.thread_pool.install(|| {
- work_items
- .into_par_iter()
- .for_each(|(loader, filenames, run_data)| loader.reload(filenames, run_data));
+ work_items.into_par_iter().for_each(|f| f());
});
}
}As written, the closures desugar kind of like this:
struct MyClosure; // actually doesn't close over anything
impl for<'a> FnMut<(&'a mut RunLoader, Vec<PathBuf>, &RwLock<commit::RunData>)> for MyClosure {
fn call_mut(&mut self, arg: (&'a mut RunLoader, ...)) {
let (loader, filenames, run_data) = arg;
loader.reload(filenames, run_data);
}
}(Since they don’t close over anything, this could be a free-standing
function caled as .for_each(call_reload_with_things), but defining it
inline is easier to read, hence the “closure”.)
If we put them in a Vec directly, they would close over things, so
would desugar like this:
struct YourClosure<'a> {
loader: &'a mut RunLoader,
filenames: Vec<PathBuf>,
run_data: &RwLock<commit::RunData>,
}
impl for<'a> FnMut<()> for MyClosure { // now doesn't need any args
fn call_mut(&mut self) {
self.loader.reload(self.filenames, self.run_data);
}
}Both work, and I wouldn’t be surprised if they yielded exactly the same
machine code.
Does this help? Personally, I find the “collect the arguments” approach
a bit easier to think about here. I don’t have a strong preference. You?
There was a problem hiding this comment.
Okay, got it, thanks. I think my natural inclination would be to do a vector of argument-less closures since that seems more encapsulated (the work item execution code doesn't need to know anything task-specific about how to unpack the vec), but I don't have a strong preference.
wchargin-branch: rust-run-parallelism wchargin-source: d73143f1995acc811032529ff1d7baf520711214
 wchargin
left a comment
wchargin
left a comment
There was a problem hiding this comment.
Thanks! Some responses inline. I’ll go ahead and merge, but happy to
continue the discussion (and feel free to ping me if I miss a message).
Wow, this seems almost too good to be true in how straightforward it is - nice.
Yep. I thought the Crossbeam code was pretty easy considering the static
guarantees and runtime performance, but this is really a breeze.
Out of curiosity, how badly interleaved is the logging from the individual run loaders when this is actually executing in parallel?
I haven’t noticed any problems. The edge_cgan dataset loads fast
enough locally that it doesn’t trigger online commits, and nndiv_100m
only has the one run. On mnist, you can see the interleaving, but it’s
clearly disambiguated by run.
| run | ||
| ) | ||
| }); | ||
| work_items.push((&mut run_state.loader, filenames, run_data)); |
There was a problem hiding this comment.
Good question. Assuming that you’re talking about the closure argument
to for_each (currently line 285): my understanding is that these are
all the same closure type. The type is anonymous (you can’t name it),
but you can capture it (much like how in Java if you have a Foo<?> you
can pass it to a <T>helper(Foo<T>) to give T a local name). So we
could also write this:
diff --git a/tensorboard/data/server/logdir.rs b/tensorboard/data/server/logdir.rs
index 23ff65893..cbab00442 100644
--- a/tensorboard/data/server/logdir.rs
+++ b/tensorboard/data/server/logdir.rs
@@ -277,12 +277,11 @@ impl<'a> LogdirLoader<'a> {
run
)
});
- work_items.push((&mut run_state.loader, filenames, run_data));
+ let loader = &mut run_state.loader;
+ work_items.push(move || loader.reload(filenames, run_data));
}
self.thread_pool.install(|| {
- work_items
- .into_par_iter()
- .for_each(|(loader, filenames, run_data)| loader.reload(filenames, run_data));
+ work_items.into_par_iter().for_each(|f| f());
});
}
}As written, the closures desugar kind of like this:
struct MyClosure; // actually doesn't close over anything
impl for<'a> FnMut<(&'a mut RunLoader, Vec<PathBuf>, &RwLock<commit::RunData>)> for MyClosure {
fn call_mut(&mut self, arg: (&'a mut RunLoader, ...)) {
let (loader, filenames, run_data) = arg;
loader.reload(filenames, run_data);
}
}(Since they don’t close over anything, this could be a free-standing
function caled as .for_each(call_reload_with_things), but defining it
inline is easier to read, hence the “closure”.)
If we put them in a Vec directly, they would close over things, so
would desugar like this:
struct YourClosure<'a> {
loader: &'a mut RunLoader,
filenames: Vec<PathBuf>,
run_data: &RwLock<commit::RunData>,
}
impl for<'a> FnMut<()> for MyClosure { // now doesn't need any args
fn call_mut(&mut self) {
self.loader.reload(self.filenames, self.run_data);
}
}Both work, and I wouldn’t be surprised if they yielded exactly the same
machine code.
Does this help? Personally, I find the “collect the arguments” approach
a bit easier to think about here. I don’t have a strong preference. You?
| run | ||
| ) | ||
| }); | ||
| work_items.push((&mut run_state.loader, filenames, run_data)); |
There was a problem hiding this comment.
Yep. Let’s spelunk through the logic:
- This method takes
&mut self; call that elided lifetime'1, so
it’sfn load_runs<'1>(&'1 mut self, ...). - We borrow
self.runs.iter_mut()for lifetime'2, which must not
outlive'1so that it doesn’t outlive borrowed content. - Then we borrow
&mut run_state.loader, for lifetime'3, which
must not outlive'3so that it doesn’t outlive that loan. - These are the lifetime upper bounds:
'1: '2and'2: '3, where
“:” is a subtyping relation that you can pronounce “outlives (or
is equal to)”. You’ll often seeT: 'staticto indicate thatT
has only static references (“outlives everything”). - We have a
Vec::<(&'v mut RunLoader, ...)>for some lifetime'v.
Since wepushitems with lifetime'3, we must have'3: 'v: the
referenced content must outlive the vector. - Now, we move
work_itemsinto the closure arg toinstall. From
here on out, there aren’t really any more lifetimes: we call
into_par_iterandfor_each, both of which are simply typed
methods with by-value receivers. In particular, neither of them has
a lifetime bound on its closure type, unlikestd::thread::spawn.
You can similarly analyze the lifetime flow for the &RwLock<...>
lifetime. You’ll get something like this:
(Here, an arrow from a to b means a: b.)
Writing it out, the inference looks pretty unidirectional here: we
require '1: '2: '3: 'v, but there’s nothing concrete at the end of
that chain, so this is satisfiable by (e.g.) setting '1 = '2 = '3 = 'v
and the borrow checker is happy.
If we had called std::thread::spawn instead of install, we would
then require 'v: 'static, since spawn requires that F: 'static
(where F is the type of the closure), and we have 'v: F since the
vector must live as long as the closure itself. This transitively means
that the whole diagram must outlive 'static. But '1 was arbitrary:
it’s the lifetime to the receiver parameter. Thus, this isn’t
satisfiable in general and should be a borrowck error.
Let’s see what Rustc has to say. In this patch, I’ve dropped the
run_data arg so that the compiler is forced to complain about the left
branch of the graph above rather than the right branch (it’s the same
logic, just not the one that you asked about):
diff --git a/tensorboard/data/server/logdir.rs b/tensorboard/data/server/logdir.rs
--- a/tensorboard/data/server/logdir.rs
+++ b/tensorboard/data/server/logdir.rs
@@ -277,12 +277,13 @@ impl<'a> LogdirLoader<'a> {
run
)
});
- work_items.push((&mut run_state.loader, filenames, run_data));
+ work_items.push((&mut run_state.loader, filenames));
}
- self.thread_pool.install(|| {
- work_items
- .into_par_iter()
- .for_each(|(loader, filenames, run_data)| loader.reload(filenames, run_data));
+ drop(commit_runs);
+ std::thread::spawn(move || {
+ for (loader, filenames) in work_items.into_iter() {
+ loader.reload(filenames, todo!("omitted for example"));
+ }
});
}
}Rustc says:
error[E0759]: `self` has an anonymous lifetime `'_` but it needs to satisfy a `'static` lifetime requirement
--> logdir.rs:268:43
|
259 | fn load_runs(&mut self, discoveries: Discoveries) {
| --------- this data with an anonymous lifetime `'_`...
...
268 | for (run, run_state) in self.runs.iter_mut() {
| --------- ^^^^^^^^
| |
| ...is captured here...
...
283 | std::thread::spawn(move || {
| ------------------ ...and is required to live as long as `'static` here
This is pointing out the transitive '1: '2: 'static chain and
complaining about its unsatisfiability.
So how can Rayon’s install or Crossbeam’s scope get away with this
while thread::spawn needs the 'static requirement? The key is that
the scoped thread implementations ensure that the callback finishes
before install/scope itself returns. Thus, the borrowed content only
needs to live as long as the call to install, which is on the caller’s
stack frame and is thus known to be outlived by '1. Under the hood,
both of these will call thread::spawn after using unsafe to
transmute your closure to 'static. (If “unsafe” is surprising
here, remember that soundness is what we care about. “Sound” means “in
no real execution will it trigger undefined behavior”; “safe” means “the
compiler has statically proven that it is sound”; “unsafe” means “the
code author has statically proven that it is sound based on properties
too advanced to be represented in the base type system”. We use sound
unsafe code to build safe abstractions.)
But presumably it's also somehow attached to the
Vecitself now, right, so even if we were to empty theVecentirely and then try to go refill it without dropping it in between, that would still prevent mutation ofself.runseven though the actual loader references are all gone?
Yeah, definitely. You can get that kind of flexibility with RefCell,
which basically pushes the borrow checking to runtime. (Follows a Rust
pattern: you can have dynamic borrow checking, dynamic dispatch, dynamic
reference counting, dynamic typing (std::any), but you have to opt in,
and sometimes accept consequences like “your type is no longer Sync”.)
But a humble Vec<_> isn’t that smart by default.
Does this help?
Summary:
A
LogdirLoadernow loads multiple runs at once. Each individual runis still loaded sequentially (no parallelism across or within event
files). A thread pool is owned by a
LogdirLoaderand is reused forsubsequent calls to
reloadon the same receiver. The thread pool sizeis configurable, and by default is automatically chosen based on
the number of logical CPUs.
This implementation uses the Rayon library for parallelism. The tasks
that we enqueue onto thread pools have references to local variables, so
we can’t directly use
std::thread::spawn, whose closure is requiredto only contain static references. We can use
crossbeam::scopetoeasily capture local variables in child threads, but then the threads
are tied to a particular reload cycle. Rayon makes it easy to have a
long-lived thread pool where each task has a separately scoped lifetime.
Test Plan:
Running on a logdir with all the TensorBoard demo data, clocking in at
544 MB with 218 runs, we benchmark total load time as a function of
thread pool size:
When running TensorBoard with
--load_fastonedge_cgan, the firstload cycle now takes 3.09s on my machine, instead of 8.26s.
wchargin-branch: rust-run-parallelism