3.1 Ramificação (Branching) no Git O que é um Branch
Para compreender realmente a forma como o Git cria branches, precisamos dar um passo atrás e examinar como o Git armazena seus dados. Como você pode se lembrar do capítulo 1, o Git não armazena dados como uma série de mudanças ou deltas, mas sim como uma série de snapshots.
Quando você faz um commit no Git, o Git guarda um objeto commit que contém um ponteiro para o snapshot do conteúdo que você colocou na área de seleção, o autor e os metadados da mensagem, zero ou mais ponteiros para o commit ou commits que são pais deste commit: nenhum pai para o commit inicial, um pai para um commit normal e múltiplos pais para commits que resultem de um merge de dois ou mais branches.
Para visualizar isso, vamos supor que você tenha um diretório contendo três arquivos, e colocou todos eles na área de seleção e fez o commit. Colocar na área de seleção cria o checksum de cada arquivo (o hash SHA-1 que nos referimos no capítulo 1), armazena esta versão do arquivo no repositório Git (o Git se refere a eles como blobs), e acrescenta este checksum à área de seleção (staging area):
$ git add README test.rb LICENSE $ git commit -m 'commit inicial do meu projeto'
Quando você cria um commit executando git commit, o Git calcula o checksum de cada subdiretório (neste caso, apenas o diretório raiz do projeto) e armazena os objetos de árvore no repositório Git. O Git em seguida, cria um objeto commit que tem os metadados e um ponteiro para a árvore do projeto raiz, então ele pode recriar este snapshot quando necessário.
Seu repositório Git agora contém cinco objetos: um blob para o conteúdo de cada um dos três arquivos, uma árvore que lista o conteúdo do diretório e especifica quais nomes de arquivos são armazenados em quais blobs, e um commit com o ponteiro para a raiz dessa árvore com todos os metadados do commit. Conceitualmente, os dados em seu repositório Git se parecem como na Figura 3-1.
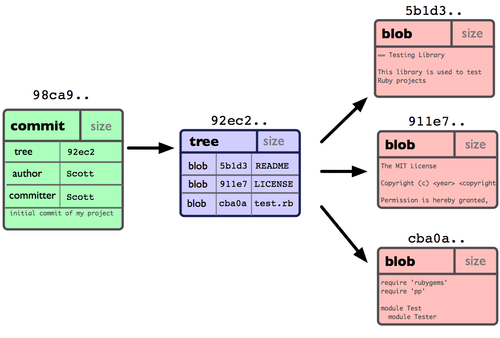
Se você modificar algumas coisas e fizer um commit novamente, o próximo commit armazenará um ponteiro para o commit imediatamente anterior. Depois de mais dois commits, seu histórico poderia ser algo como a Figura 3-2.
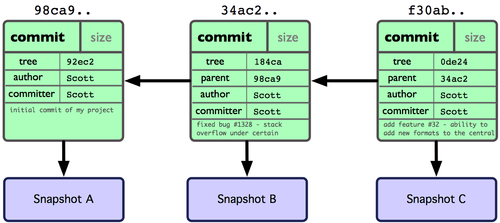
Um branch no Git é simplesmente um leve ponteiro móvel para um desses commits. O nome do branch padrão no Git é master. Como você inicialmente fez commits, você tem um branch principal (master branch) que aponta para o último commit que você fez. Cada vez que você faz um commit ele avança automaticamente.
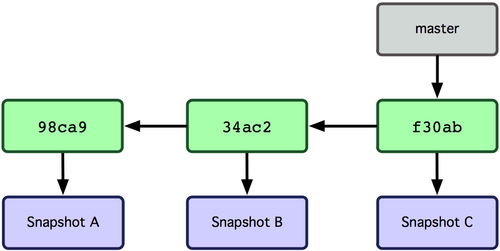
O que acontece se você criar um novo branch? Bem, isso cria um novo ponteiro para que você possa se mover. Vamos dizer que você crie um novo branch chamado testing. Você faz isso com o comando git branch:
$ git branch testing
Isso cria um novo ponteiro para o mesmo commit em que você está no momento (ver a Figura 3-4).
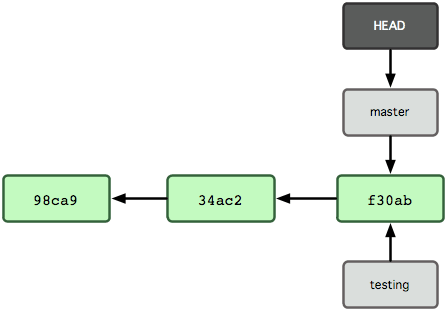
Como o Git sabe o branch em que você está atualmente? Ele mantém um ponteiro especial chamado HEAD. Observe que isso é muito diferente do conceito de HEAD em outros VCSs que você possa ter usado, como Subversion e CVS. No Git, este é um ponteiro para o branch local em que você está no momento. Neste caso, você ainda está no master. O comando git branch só criou um novo branch — ele não mudou para esse branch (veja Figura 3-5).
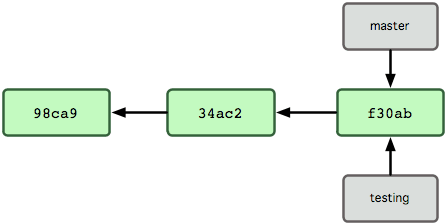
Para mudar para um branch existente, você executa o comando git checkout. Vamos mudar para o novo branch testing:
$ git checkout testing
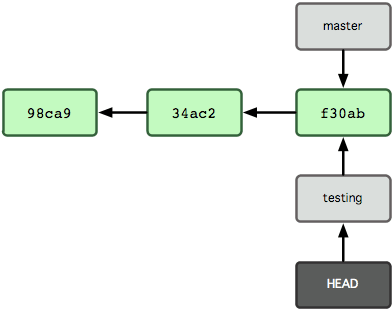
Isto move o HEAD para apontar para o branch testing (ver Figura 3-6).
Qual é o significado disso? Bem, vamos fazer um outro commit:
$ vim test.rb $ git commit -a -m 'fiz uma alteração'
A figura 3-7 ilustra o resultado.
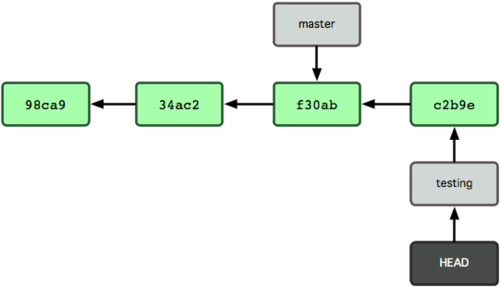
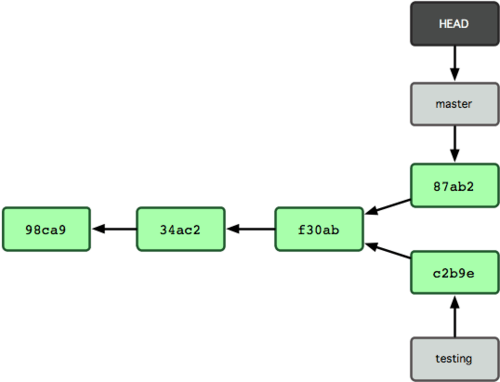
Isso é interessante, porque agora o seu branch testing avançou, mas o seu branch master ainda aponta para o commit em que estava quando você executou git checkout para trocar de branch. Vamos voltar para o branch master:
$ git checkout master
A figura 3-8 mostra o resultado.
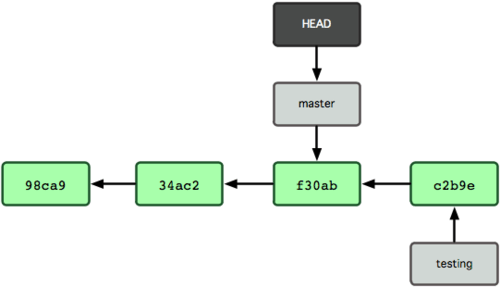
Esse comando fez duas coisas. Ele alterou o ponteiro HEAD para apontar novamente para o branch master, e reverteu os arquivos em seu diretório de trabalho para o estado em que estavam no snapshot para o qual o master apontava. Isto significa também que as mudanças feitas a partir deste ponto em diante, irão divergir de uma versão anterior do projeto. Ele essencialmente "volta" o trabalho que você fez no seu branch testing, temporariamente, de modo que você possa ir em uma direção diferente.
Vamos fazer algumas mudanças e fazer o commit novamente:
$ vim test.rb $ git commit -a -m 'fiz outra alteração'
Agora o histórico do seu projeto divergiu (ver Figura 3-9). Você criou e trocou para um branch, trabalhou nele, e então voltou para o seu branch principal e trabalhou mais. Ambas as mudanças são isoladas em branches distintos: você pode alternar entre os branches e fundi-los (merge) quando estiver pronto. E você fez tudo isso simplesmente com os comandos branch e checkout.
Como um branch em Git é na verdade um arquivo simples que contém os 40 caracteres do checksum SHA-1 do commit para o qual ele aponta, os branches são baratos para criar e destruir. Criar um novo branch é tão rápido e simples como escrever 41 bytes em um arquivo (40 caracteres e uma quebra de linha).
Isto está em nítido contraste com a forma com a qual a maioria das ferramentas VCS gerenciam branches, que envolve a cópia de todos os arquivos do projeto para um segundo diretório. Isso pode demorar vários segundos ou até minutos, dependendo do tamanho do projeto, enquanto que no Git o processo é sempre instantâneo. Também, porque nós estamos gravando os pais dos objetos quando fazemos commits, encontrar uma boa base para fazer o merge é uma tarefa feita automaticamente para nós e geralmente é muito fácil de fazer. Esses recursos ajudam a estimular os desenvolvedores a criar e utilizar branches com frequência.
Vamos ver por que você deve fazê-lo.