Corpus format 語料格式
以下規範適用於所有採取線性標註方式的語料。
本庫語料無明確的分詞標準。不一定因連讀音變分詞,因爲音變可能發生於一個詞組的內部。如「生肉柱」(榕拼:sang²¹-nyk⁵³-tiu²⁴²,長痤瘡)於本庫可能拆爲生與肉柱。
分詞不是強制的。
半形、全形標點符號原則上皆可使用,但被本文檔指定爲其他用途的標點符號則避免使用。
本庫純文本語料收錄於.xml、.tsv文檔,而"(半形引號)是該類文檔的製表符。故避免衝突,若需使用引號,請使用《GB/T 15834—2011》下的“與”。
省略號…用於成份殘缺處,跟在前一語詞之後。
填寫來源信息時,可能會遇到含有&的URL要填寫。而這會導致文件格式上的一些衝突。需要將它轉換爲URL Escape Codes——%26。下表供參考。
| Character | URL Escape Codes | String Literal Escape Code |
|---|---|---|
| SPACE | %20 | $20 |
< |
%3C | $3C |
> |
%3E | $3E |
# |
%23 | $23 |
% |
%25 | $25 |
+ |
%2B | $2B |
{ |
%7B | $7B |
} |
%7D | $7D |
| |
%7C | $7C |
\ |
%5C | $5C |
^ |
%5E | $5E |
~ |
%7E | $7E |
[ |
%5B | $5B |
] |
%5D | $5D |
‘ |
%60 | $60 |
; |
%3B | $3B |
/ |
%2F | $2F |
? |
%3F | $3F |
: |
%3A | $3A |
@ |
%40 | $40 |
= |
%3D | $3D |
& |
%26 | $26 |
$ |
%24 | $24 |
有時錄音或手跡裏有字詞無法辨別,則以?(全形問號)代之。
有時接到某詞,雖云知音知義,唯不知如何寫作漢字,則以□(虛缺號)代之。
口頭表達與書寫相較,前者更具隨意性,而後者則有自覺性。具體到閩東語的現狀,則口頭表達在語法與邏輯上較爲隨意,表意未必精準,且更能體現土話的真實樣貌;而書寫則更易受到漢語共通書面語的影響。
然而經由口頭表達出來的內容未必皆是土話,公共廣播、宣講、主持等正式場合的閩東語,可能也會體現出書面語的特徵。而網絡聊天室裏用戶打出的閩東語文字,則也會體現出口頭表達的特徵。
閩東語使用者在讀官話白話文的報章文字時,對其內容的轉述可能又呈現出一種「三及第」的面貌,這種對內容的接收與轉述過程很類似日本人對漢文的「訓讀」。一些用漢字寫就的文本,如古詩、古文、口號等,甚至可能被閩東語使用者憑字直接讀,類似日本人對漢傳佛經的「音讀」。
鑒於本庫所收閩東語語料來源之複雜,本庫的線性標註語料設有property字段,用以判斷語料的性質。設言文性質如下:
-
spoken:口頭 -
idiom:謠諺 -
written:文字 -
essay:文章 -
poem:詩歌 -
translated:翻譯 -
formal:正式
判斷流程如下:
- 語料爲正式場合的發言(這種發言很可能是由官話譯出的,但是不糾結於此),包括公告、通知,標
formal;若非, - 語料爲根據非閩東語口語文本讀出或譯出所得,無論是逐字讀出還是部分地以固有語訓譯,標
translated;若非, - 語料來自某人自覺創作的(即便語言多麼流暢自然的)詩歌、歌詞等,標
poem;若非, - 語料來自某人自覺創作的(即便語言多麼流暢自然的)文章、書信等,標
essay;若非, - 語料來自某人自覺的創作,如(即便語言多麼流暢自然的)作品中摘錄的句子、電子聊天打字等,標
written;若非, - 語料意圖對民間流傳的歌謠、俗語、諺語、歇後語、話頭等進行忠實的文字紀錄的,標
idiom, - 語料意圖對所聽到的口頭表達進行忠實的文字紀錄的,標
spoken。
本庫純文本語料推薦使用.xml格式(.xsd檔案、使用文檔)記錄,這是因爲該格式文檔能夠更靈活地分詞、標註。
可以藉助一些開發環境編輯.xml文檔,如XMLSpy 2005(中文教程)。
.xml文檔的規範參見plaintext/cdo-plaintext-corpus-document.xsd與plaintext/document。
本庫有一部分純文本語料,是以.tsv格式記錄的。推薦將它們逐步轉換爲.xml格式,不強制。
先看一段示例語料。
絲瓜<lan=cmn> 吓<m=啊><y=a53>. 絲瓜<lan=cmn> 汝<m=你><y=ny33> 是偍<m=是不是><y=sie21-nei55> 告<m=叫><y=goo213>, 閩侯<y=ming21-au242> 伊<m=他><y=i55> 是偍<m=是不是><y=sei21-nei55> 告<m=叫><y=goo213> 𢯽<y=ceo213>? 吓<m=啊><y=a213>. 福州<y=huk21-ziu55>, 我<y=nguai33> 福州<y=huk21-ziu55> 這邊<y=zi21-mieng55> 告<m=叫><y=goo213> 𢯽<y=coo213>. 吓<m=啊><y=a213>. 食<m=喫><y=sieh5> 其<m=的><y=li53> 嘻<m=那個><y=ia33> 絲瓜<lan=cmn> 吓<m=啊><y=a53>.
可見空格分詞。還能看見詞後有綴各類括號。以下介紹本庫.tsv語料的基本格式。
分詞同前述,如「生肉柱」(榕拼:sang²¹ nyk⁵³ tiu²⁴²,長痤瘡)於本庫可能拆爲生 肉柱。
分好的詞用 (半形空格)隔開。
由於閩東語世界幾無現成的數位化文本可用(除了閩東語維基項目),故此語料的收集,幾乎依賴手錄。這便不需要考慮自動化的分詞方案,而爲隨手按空格分詞似乎隨之成爲了優解。
組成句子的語詞擁有各自的性質。使用語料符號 v2.0標記其性質。
語料符號緊跟在分好的詞之後,並與後方其他語詞以分好的空格相隔。如:
攖<m=放><y=eing55><g=ĕng>
如果句料有以半形空格( )分詞,則標點符號不要緊跟於前一個字詞,而是同樣與前一個字詞空一半形空格。
半形、全形標點符號原則上皆可使用,但被本文檔指定爲其他用途的標點符號則避免使用。
本庫純文本語料收錄於.tsv文檔時,會有"(半形引號)作爲該類文檔的製表符。故避免衝突,若需使用引號,請使用《GB/T 15834—2011》下的“與”。
省略號用於成份殘缺處,跟在前一語詞之後。如:
請 趁 …
「趁」(teing²¹³,從)後需要跟上動作的出發點,以組成一個完整的介賓短語。顯然,引用的語料成份殘缺。其實這是從一段錄音裏截取出來的片段,故不完整乃爾。
有時錄音或手跡裏有字詞無法辨別,則以?(全形問號)代之。如:
在 伊 ? 講.
一段連江話語料裏出現了聽起來像普通話「jiàng」的詞。整理語料者無法辨別,就暫以?代替。?視爲一個語詞,參與分詞,並不像其他標點符號需要有所貼附。
有時接到某詞,雖云知音知義,唯不知如何寫作漢字,則以□(虛缺號)代之。如:
在 伊 □□<m=怎麼><y=zia53-o213> 講.
現在聰明的整理者明白了此詞的音義,可以作出相對規範的標記了。唯獨漢字寫法不明,故暫以□代替。□亦視爲一個語詞,參與分詞,不像其他標點符號需要有所貼附。
本庫的.tsv文檔,包括sentences.tsv與/plaintext目錄下的.tsv文檔,具備以下欄位:
-
Mindong:閩東語漢字的句子,帶有標註,部分有分詞。 -
Mandarin Trans.:句子的普通話翻譯,部分有分詞。 -
English Trans.:句子的英語翻譯。 -
Speaker ID:講話者編號,見speakers.csv。 -
ISO 639-6:語言的ISO代碼,參見中文維基學院的列表。 -
Provider:資料提供者。 -
Year:記錄年份,填入半角阿拉伯數字。 -
Month:記錄月份,填入半角阿拉伯數字,無前置0。 -
Day:記錄日期,填入半角阿拉伯數字,無前置0。 -
HH:MM:SS (UTC+8):記錄時間(UTC+8時區),如01:05:03。 -
Source:資料來源,格式用中國國家標準GB/T 7714-2015。 -
Copyright:版權信息。 -
Tag:標籤;見categories_yngdieng.tsv,使用文檔中的ThirdCategory或SecondCategory作爲語料標籤;如已有標籤不夠用,提出issue。 -
Note:備註,在單單有句料則不足以明瞭情況之場合,補充說明句料的情感、用途等。 -
Property:言文性質,見前述。 -
Path to Original File:本庫原始文件的路徑;僅適用於sentences.tsv,因本庫所有文字語料都將以句爲單位彙總一份於sentences.tsv,而後續之標註與修正也應彙總更新至sentences.tsv。
本庫使用ELAN對有聲語料分層標註。前文的標註,都集中於一層;而接落來介紹的標註,則是以一條有聲語料的選定時間段爲基本單位,分出多個不同屬性的標註層次。
以下是該軟件的影片教程:
創建標註,需要將待標註錄音、待標註影片(如果有)、分層模板加入工作區。
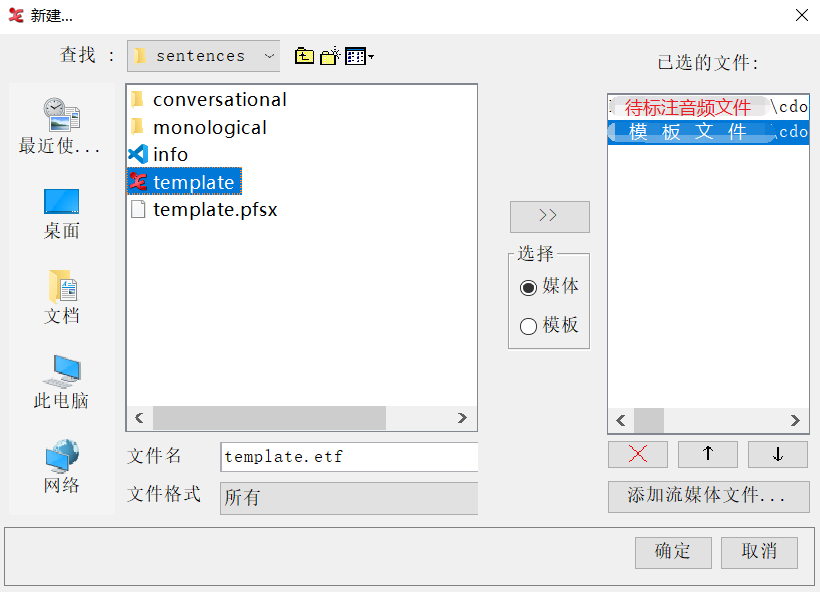
模板在\sentences目錄下。
進入軟件主界面後,先保存此新建文件。文件名同待標註多媒體文件。
新建標註文件後,會看見模板預設的多個層。以下分類介紹層。
-
word:詞彙。若待標註音頻僅含有一兩句話,則以語彙爲單位在此層轉寫文本。 -
character:音節。在已填寫word的情況下,可填寫此層,去進行以音節爲單位的精細轉寫。如果對應內容是祗含有一個音節的詞彙,則填寫於word層,不填寫於此層。 -
sentence:語句。若待標註音頻含有多句話,則先以語句爲單位在此層轉寫文本。 -
faulty fixing:正誤,以詞彙爲單位。語料中可能含有語病。不對轉寫文本直接正誤,但是可以在此層標註正確表達。 -
faulty fixing yp.:正音,以音節爲單位。語料中可能含有誤讀。不對注音直接正誤,但是可以在此層標註正確讀音。
-
yngping:榕拼,以詞彙爲單位。如有標註讀音,默認填寫此層。 -
yngping by char.:榕拼,以音節爲單位。在已填寫yngping的情況下,可填寫此層,去進行以音節爲單位的精細標註。 -
gáu-huôi lò̤-mā-cê:教會羅馬字,以詞彙爲單位。非必須。
-
cmn trans. by word:詞彙華語對譯。 -
cmn trans. by char.:音節華語對譯。 -
cmn trans. by sentence:語句華語對譯。
-
language:語言。填寫對應內容的ISO 639-6代碼。
本標註規範版本號爲0.3。
| 版本號 | 備註 |
|---|---|
| 0.1 | 增加線性標註規範 |
| 0.1.1 | 增加分層標註規範 |
| 0.2 | 增加分詞、標點、言文性質等規範 |
| 0.3 | 當前頁面 |