DevGuide Documentation
This article describes the SCons documentation toolchain in versions 2.3.x and higher. It's based on the file doc/overview.rst in the source repository, so go there first to add or change text please.
This article gives an overview of the SCons documentation toolchain. Interested users should better understand where and how the text he writes is processed. It also provides a reference for core developers and the release team.
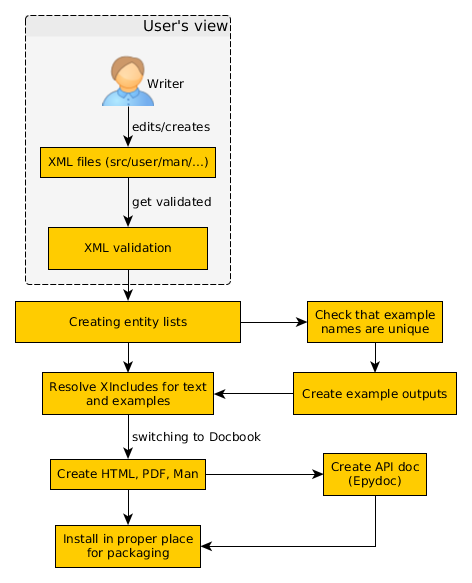
The diagram above describes steps that required for creating all the MAN pages, User manuals and reference documents. You may be wondering, "Why doesn't SCons simply convert XML files to PDF with Docbook or use REST?" Please continue reading, and things will become clearer.
Our toolchain not only produces beautiful HTML and PDF files, but it also performs a lot of processing under the covers. We aim for consistent documentation; thus, extra steps are required.
The toolchain only allows the User a restricted view on this whole "document processing cycle"; therefore, the User should only be concerned about updating or adding to documentation text. Even when adding a completely new chapter, the User can simply fire up an XML editor of choice and type away. A few configurations for XML editors supporting WYSIWYG editing are provided.
Really nice Users also care about validating XML files against our special "SCons Docbook DTD/XSD". This can be acheived via an XML editor or executing the SCons document validation script: python bin/docs-validate.py
from the top source folder afterwards or, preferably, both.
Once all all validation passes, all that's left is a pull request on Bitbucket. That's it!
Additionally, single documents can be created to get a feel for how the final result looks. Each of the document folders, design, developer, man, python10, reference, and user, contains an SConstruct file along with the actual XML files. By calling python ../../src/script/scons.py from within the directory, the User can have the MAN pages, HTML, and even PDF generated if you have a renderer installed: fop, xep or jw.
If you haven't already downloaded the documentation sources to your computer, please visit Introduction now. It will give you pointers, and lead you through the steps of setting up a local repository. Then, you can find the documentation stuff in the folder doc at the top-level.
Install python bindings for libxml2 (libxml2-python) with libxslt (libxslt-python). (Deprecated) lxml (python-lxml) may also be used. For rendering PDF documents, you'll fop, xep or jw available in your system-wide $PATH. Creating the EPUB output files of the UserGuide and the MAN page depend on the Ghostscript executable gs for creating the front cover image. fop requires Java but is easily installed via apt-get on Debian/Ubuntu. jw is available for Debian/Ubuntu as part of the docbook-utils package. You'll also need epydoc in the python-epydoc package.
We are using our own DTD/XSD as a kind of hook, which only exists to link our own SCons documentation tags into the normal Docbook XSD. For the output, we always have an intermediary step (see diagram above), where we rewrite tags like cvar into a block of Docbook formatting elements representing it.
The toolchain, and all the Python scripts supporting it, are based on the prerequisite that all documents are valid against the SCons Docbook XSD. This step guarantees that we can accept the pull request of a user/writer and create documentation for a new release of SCons without any problems later.
We are using entities for special keywords like SCons that should appear with the same formatting throughout the text. Entities are kept in a single file doc/scons.mod which gets included by the documents.
Additionally, for each Tool, Builder, Cvar and Function, a bunch of linkends in the form of entities get defined which can be used in the MAN page and the User manual.
When you add an XML file in the src/engine/Tools folder (EG. a tool named foobar), you can use the following two entities:
t-foobar : which prints the name of the Tool, and
t-link-foobar : which is a link to the description of the Tool in the Appendix
within the User guide's text.
By calling the script python bin/docs-update-generated.py, you can recreate the lists of entities (*.mod) in the generated folder. This will also generate the *.gen files, which list the full description of all the Builders, Tools, Functions and CVars for the MAN page and User Guide appendix.
For more information about describing these elements, refer to the start of the Python script bin/SConsDoc.py. The file describes the available tags and the exact syntax in detail.
In the User Guide, we support automatically created examples. This means that the output of the specified source files and SConstructs is generated by running them with the current SCons version. We do this to ensure that the output displayed in the manual, is identical to what you get when you run the example on the command-line.
A short description about how these examples have to be defined, can be found at the start of the file bin/SConsExamples.py. Call python bin/docs-create-example-outputs.py from the top level source folder, to run all examples through SCons.
Before this script starts to generate any output, it checks whether the names of all defined examples are unique. Another important prerequisite is that all the single scons_output blocks need to have a suffix attribute defined. These suffixes also have to be unique, within each example.
All example output files (*.xml) get written to the folder doc/generated/examples together with all files defined via the scons_example_file tag which are version controlled. This makes comparing the output of newly generated examples easy for a new version of SCons.
Note that these output files are not actually needed for editing the documents. When loading the User manual into an XML editor, you will always see the example's definition. Only when you create some output will the files from doc/generated/examples get XIncluded and all special scons* tags transformed into Docbook elements.
Documents are in the folders design, developer, man, python10, reference, and user.
editor_configs
: Prepared configuration sets for the validating WYSIWYG XML editors XmlMind and Serna. Try the latter because the XXE config requires you to have a full version (costing a few hundred bucks) and is therefore untested. For installing the Serna config, simply copy the scons folder into the plugins directory of your installation. Likewise, the XXE files from the xmlmind folder have to be copied into ~/.xxe4/ under Linux.
generated
: Entity lists and outputs of the UserGuide examples. They get generated by the update scripts bin/docs-update-generated.py and bin/docs-create-example-outputs.py.
images
: Images for the overview.rst document.
xsd : The SCons Docbook schema (XSD), based on the Docbook v4.5 DTD/XSD.
xslt
: XSLT transformation scripts for converting the special SCons tags like scons_output to valid Docbook during document processing.
This is the documentation for SCons versions before 2.3.x; see also the discussion page for some points that got discussed and finally led to the new DocBook-based approach above.
Documentation sources for Docbook are maintained in doc/*/*.xml files. For the ones that require preprocessing to insert examples, the primary source files are doc/*/*.in. We have our own preprocessing stage to update and insert examples into XML sources before they are processed.
These package names can be passed directly to 'apt-get install' for Ubuntu or Debian.
- python-epydoc
- jade
- openjade
- tetex-bin
- tetex-latex
- texlive-latex-extra
- jadetex ?
- docbook
- docbook-doc
- docbook-dsssl
- docbook-to-man
- docbook-utils
- docbook-xml
- docbook-xsl
- docbook2x
- man2html
[GaryOberbrunner 15-Jul-12] As of Ubuntu 10.04, some of the above pkgs don't exist. These do: apt-get install python-epydoc jade openjade texinfo texlive-latex-extra jadetex docbook docbook-dsssl docbook-to-man docbook-utils docbook-xml docbook-xsl docbook2x man2html and the doc seems to build OK with those packages (and their dependencies).
Not strictly doc-related, but if you're doing release builds, you also need rpm if you're on a non-RedHat/CentOS machine: apt-get install rpm.
- Edit the doc/user/file.in
- python bin/scons-doc.py --diff file
- Review the diffs introduced by your changes, and proceed if they look correct
- python bin/scons-doc.py --update file
- python bootstrap.py doc
- Review the generated documents in build/doc/html/scons-user.html (and .ps and .pdf)
- Submit patch for review
- Make documentation building process cross-platform
- Cut the amount of tools and dependencies (preferably to Python modules)
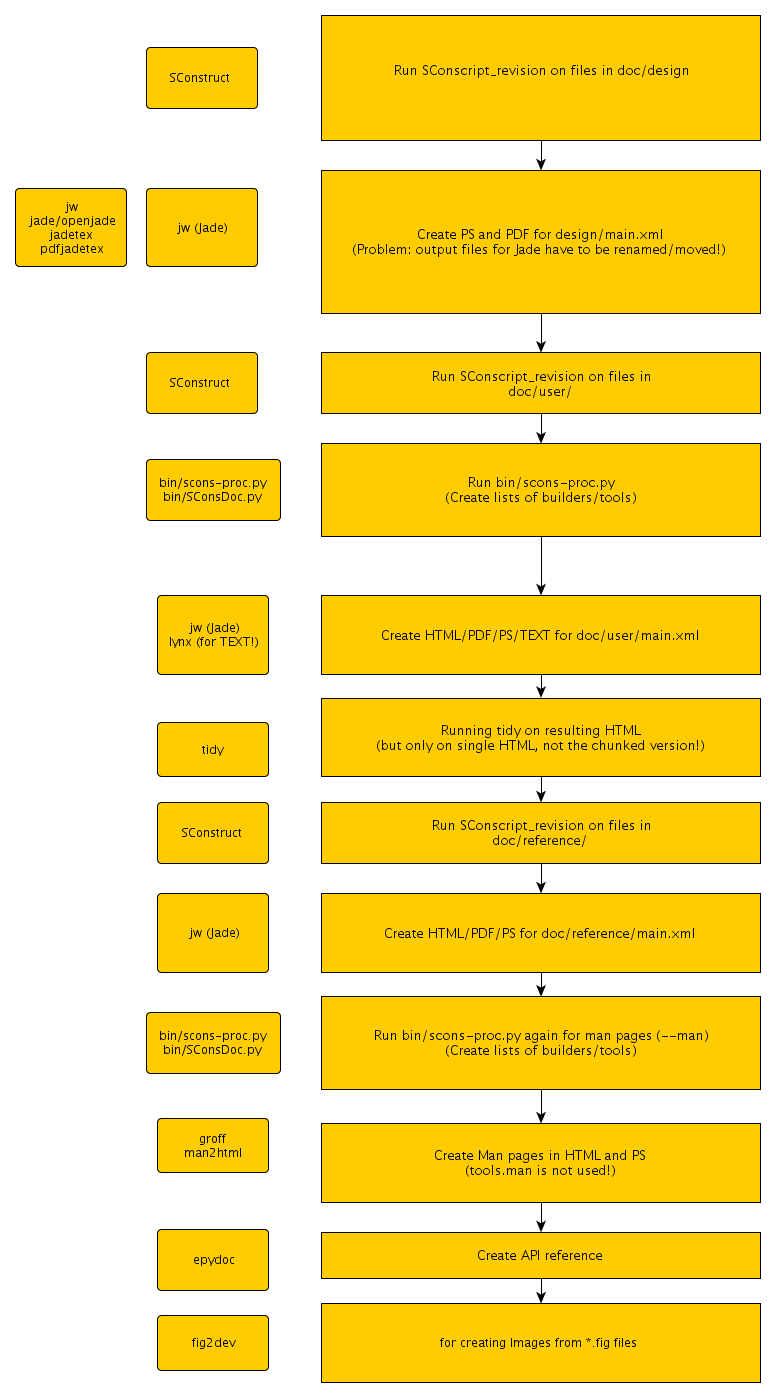
The following image depicts the single steps of a full build for the documentation. The first (and zeroth) column shows the required tools (= dependencies) for each section (= second column).
Note: after GitHub migration, a separate page no longer works well, so moved to end of main page.
techtonik: Historically, we use Docbook format to maintain documentation. Docbook is XML based format that should allow to convert source files into various formats, such as HTML, PDF, man pages and allow easy skinning and customizing. This was in theory. In practice it appeared that Docbook transformations in either XSLT or DSSSL languages are beautiful at micro level, but clumsy, hard to comprehend and maintain when you need to make a bigger thing done. The complexity in Docbook templates (and in customizations) grows significantly faster than with traditional template engines, and there are almost no free tools to debug XSLT templates. Docbook was good at the beginning, because there were no alternative, but today there is at least Sphinx.
We still maintain docs in Docbook, but we don't use XSLT for transformation. Transformation is made using even more "prehistoric" DSSSL templates and tool-chain that only runs on *nix like systems.
Greg: There are two issues with using Sphinx.
One issue is that Sphinx is a reStructuredText editor. Now, reStructuredText is a fine language for documentation, but we have many dozens of pages in XML that would have to be converted, and converted losslessly. I don't see an automated tool that would provide any assistance, and without such a tool, I can't see any way we could proceed.
-
techtonik: There is one that can be tweaked - http://code.google.com/p/db2rst/ Greg: The other, and far more important, issue is that I don't see how a workflow can be constructed to extract the examples, run them, verify that any changes are correct, and then proceed with the example output inserted in the documentation. Without such a workflow in hand, Sphinx is a non-starter.
-
techtonik: issue no.1 for research DB: I have never worked with Sphinx (took a short look at the reST primer right now), but know Docbook a little. I don't think that reST is a good language for technical documentation at all, because it does not restrict the user to "structured authoring". You can freely assign attributes like italic or bold to text passages, which automatically leads to trouble when you try to get the output for, let's say, a
guibuttonconsistent across all input files (and users!). This is where I feel that Docbook is still superior, you can also immediately check an input document against the DTD...and if it is valid, you are able to process it. There is (or: should be) a clear separation between the user that edits documents and one (or a few people) that actually process the XML to a HTML or PDF documentation. I don't like any support for fancy WYSIWYG to get in the way of this. -
techtonik: I do not know if it is possible to restrict Sphinx to process only a subset or markup leaving only "structured markup" elements thus restricting user to "structured authoring". This probably an issue no.2 worth investigation. But poor appearance (and usability) of SCons manual as it now is mostly due to Docbook "structured authoring". There is no CHM, no Eclipse Help, no searchable indexes for help systems, no appealing design, no DHTML beautifiers - nothing except plain text in paragraphs. Current SCons docs are boring. Just because rigid Docbook markup doesn't have all necessary elements and XSLT is a very bad language for analyzing/calculating anything. They are hard to customize. Time waste in introducing a change into Docbook process is enormous in comparison with Sphinx, mostly because Python people are more familiar with reST than with XML, DTD, XSLT and corresponding toolchain. I also do not agree with your separation between doc authors and doc builders. As an author - I always want to see the final result of my efforts as soon as possible. * DB: Sorry, but you are mixing things up a little too much here, for my taste. It is not Docbook's fault that the current output looks boring and dull (to you). The problem is that actually nobody really cares...and this may be due to the fact that the current docs use some tags, special to SCons, for the support of automatically created examples and such. Like this, you cannot easily edit doc sources in a Docbook-Editor...it does not know these tags and your document is not valid, regarding the official DTD. If you start to introduce "SConsic" tags to reST (tweaking it, if you like) you will have the same effect there, I guess. People might get put off by having to learn all that extra stuff. I, as an author, am mostly concerned with the contents of my texts...not how they look in the final output. In a first step we should work on getting the current docs up-to-date and consistently marked up, in what format ever. Then we can start the catfights about whether the SCons logo should appear in the page header or in the footer ;). DB: It may be true that Docbook toolchains are difficult to set up and I would also vote for the step DSSSL->XSL asap, but with Sphinx you also need LaTeX for the conversion to PDF as a prerequisite. This could be another source for trouble because LaTeX distributions can differ a lot, when looking at which packages are installed and which not, for example. So, you don't necessarily get it all for free with Sphinx...
-
techtonik: XSL toolchain for Docbook is not much lighter. Not every XSLT processor can handle the complexity of Docbook stylesheets, so you are pretty limited. Even processors that come bundled with Eclipse Java Enterprise Edition can not do this. And Sphinx doesn't need LaTeX for conversion to PDF - http://code.google.com/p/rst2pdf/ - very responsive and active project, and integrates well with Sphinx. * DB: ...and is based on the ReportLab library (replacing one dependency with another), which is available in a OpenSource and Commercial version. The OpenSource branch does not support vector graphics and you cannot use stylesheets...hmmmm, I wonder whether this could stop anything? I don't want to keep you from any of your investigations, but when trying to reach high-quality output, there is no way around a central place for managing fonts. And it needs to be configured for your local installation, such that it knows which font families, types, ..., are available. So, creating good-looking documents is complex stuff, that's why it is a good idea to keep the authors/editors far away from fiddling with the actual page layouts.
DB: Yes, Docbook stylesheets are pretty complex and need some care if you try to do special things. But if you stick to the default set of XSL for HTML and PDF (=FO), some basic customization like "displaying the SCons logo in page headers" is quite easy to accomplish.
Finally, I would like to point at a paragraph in the reST primer about sections. It talks about the adornments for section headers and requires the user (!) to "Be consistent, since all sections marked with the same adornment style are deemed to be at the same level".
Sorry, but this is not the right path to follow, or is it?
All together, our main concern should not be to make documentation (and its processing) easier for the core developer, but for the average user. If we can agree on this, then Docbook is still my choice. I will come up with an example workflow for Docbook, using XIncludes and PIs (processing instructions) in the next days and post it to this page.
- techtonik: It would be a very welcome addition for a comparison. While Sphinx all new and shiny, it may have some deficiencies that I overlooked in my vision, so I look forward to add my variant of workflow once your example is ready.
Overall goals are:
- simplifying the toolchains, especially reducing the number of required tools/packages
- getting the output of documents cross-platform again (Windows and *nix), including the special processing for SCons examples in the User's guide
- stronger decoupling of the mere "Editing" from the actual creation of the HTML/PDF output
- for the editing: better support for validation (a user, as editor of a text, should be able to ensure that his changes do not break validity of the whole XML document...before he decides to commit...and without having to create all docs first)
For a start, I created a first draft of a special "SCons Docbook DTD".
It can be used to check the User's guide for validity, after changing the doctype in main.xml accordingly. I also prepared configuration packages for two visual XML editors, namely the Xmlmind editor
and Syntext's Serna
. They should enable you to edit the User's guide WYSIWYG style. For more infos about how to install these archives, please have a look at the "SCons Docbook DTD Reference manual"
I had another close look at the top-level SConstruct and the SConscript in the doc folder. The following points are worth further investigation, in my opinion:
-
The PDF/HTML output files from the Jade toolchain have to be moved/renamed each time. With xsltproc/libxml2 this will not be needed anymore...
-
The SConscript checks for fig2dev, although it is not really used at the moment. It was required for the conversion FIG -> JPEG in the design docs...but they don't include any reference to images?
-
The builder SConscript_revision (top-level SConstruct) is run for all XML files in the doc folder. This is not really needed, these are intermediate files...so what's the use in replacing the COPYRIGHT notice? There is one exception: doc/user/build_install.xml uses VERSION, but this can be replaced with the entries from version.xml...or not?
-
tidy is run on the HTML files, for a cleanup to XHTML. Again, this would get superfluous with a modern Docbook toolchain, using recent XSL stylesheets.
-
Finally, the man pages are still edited in groff format (shudder). Switching this to Docbook would remove the dependencies on groff and man2html, and make editing much easier. I gave this a first try and converted the current man pages of SCons, SConsign and SCons-time to Docbook with doclifter 2.3 (by Eric S. Raymond). The archive doclifter_examples.tgz
- contains the new source XML files and output in the form of Man pages, HTML and PDF files. Here is the HTML version of SCons-time for taking a short peek: scons-time.html
All together, I see good chances to trade a new dependency on xsltproc (or the libxml2/libxslt Python modules) for removing groff, man2html, tidy, fig2dev and (at least for HTML) jw. When another FOP renderer is installed on the user's system (fop,XEP,...), it could replace the whole jade/openjade/jadetex/pdfjadetex stuff for PDF output.
I started to work on a design for the SCons documentation titlepages. Here is a first version of the User Guide 2.0.0,
illustrating what the current customizations look like.
- Customized SCons Docbook DTD.
- Configuration sets for XmlMind and Serna XML editors.
- Designs for a new titlepage and chapter pages (SCons PDF documents).
- SCons Docbook Tool.
- Simple script for validating single XML files, against the internal DTD or an external URL.
I am currently working on restructuring the User Guide source to use XIncludes instead of entity references. My thoughts revolve around a processing chain that looks something like this:
- User edits some input file(s) for documentation.
- Ensure that all required include files are present, e.g. for the example outputs of the User Guide. If not, create dummy files where needed.
- Validate all single input files.
- (optional) Rerun all SCons examples in the User Guide. Compare new vs. old output and report differences. Also check for errors during the SCons processing, in order to detect flaws in the examples (like missing files).
- Preprocess the User Guide by resolving all XIncludes and replacing special SCons DTD elements, e.g. scons_example, with valid Docbook counterparts.
- Finally, create the different output formats with the SCons Docbook Tool. A normal user or technical writer would usually stop with step 3 and then commit his changes. The points 4-6 should be reserved for members of the Release Team, when a new version is about to be published.