Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
# Objective - Follow up on #10519, diving deeper into optimising `Entity` due to the `derive`d `PartialOrd` `partial_cmp` not being optimal with codegen: rust-lang/rust#106107 - Fixes #2346. ## Solution Given the previous PR's solution and the other existing LLVM codegen bug, there seemed to be a potential further optimisation possible with `Entity`. In exploring providing manual `PartialOrd` impl, it turned out initially that the resulting codegen was not immediately better than the derived version. However, once `Entity` was given `#[repr(align(8)]`, the codegen improved remarkably, even more once the fields in `Entity` were rearranged to correspond to a `u64` layout (Rust doesn't automatically reorder fields correctly it seems). The field order and `align(8)` additions also improved `to_bits` codegen to be a single `mov` op. In turn, this led me to replace the previous "non-shortcircuiting" impl of `PartialEq::eq` to use direct `to_bits` comparison. The result was remarkably better codegen across the board, even for hastable lookups. The current baseline codegen is as follows: https://godbolt.org/z/zTW1h8PnY Assuming the following example struct that mirrors with the existing `Entity` definition: ```rust #[derive(Clone, Copy, Eq, PartialEq, PartialOrd, Ord)] pub struct FakeU64 { high: u32, low: u32, } ``` the output for `to_bits` is as follows: ``` example::FakeU64::to_bits: shl rdi, 32 mov eax, esi or rax, rdi ret ``` Changing the struct to: ```rust #[derive(Clone, Copy, Eq)] #[repr(align(8))] pub struct FakeU64 { low: u32, high: u32, } ``` and providing manual implementations for `PartialEq`/`PartialOrd`/`Ord`, `to_bits` now optimises to: ``` example::FakeU64::to_bits: mov rax, rdi ret ``` The full codegen example for this PR is here for reference: https://godbolt.org/z/n4Mjx165a To highlight, `gt` comparison goes from ``` example::greater_than: cmp edi, edx jae .LBB3_2 xor eax, eax ret .LBB3_2: setne dl cmp esi, ecx seta al or al, dl ret ``` to ``` example::greater_than: cmp rdi, rsi seta al ret ``` As explained on Discord by @scottmcm : >The root issue here, as far as I understand it, is that LLVM's middle-end is inexplicably unwilling to merge loads if that would make them under-aligned. It leaves that entirely up to its target-specific back-end, and thus a bunch of the things that you'd expect it to do that would fix this just don't happen. ## Benchmarks Before discussing benchmarks, everything was tested on the following specs: AMD Ryzen 7950X 16C/32T CPU 64GB 5200 RAM AMD RX7900XT 20GB Gfx card Manjaro KDE on Wayland I made use of the new entity hashing benchmarks to see how this PR would improve things there. With the changes in place, I first did an implementation keeping the existing "non shortcircuit" `PartialEq` implementation in place, but with the alignment and field ordering changes, which in the benchmark is the `ord_shortcircuit` column. The `to_bits` `PartialEq` implementation is the `ord_to_bits` column. The main_ord column is the current existing baseline from `main` branch. 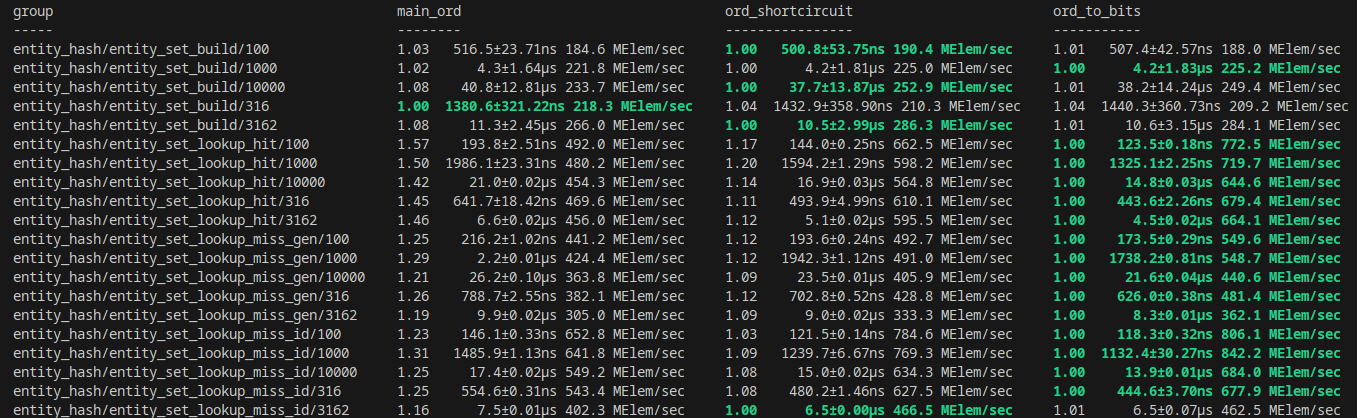 My machine is not super set-up for benchmarking, so some results are within noise, but there's not just a clear improvement between the non-shortcircuiting implementation, but even further optimisation taking place with the `to_bits` implementation. On my machine, a fair number of the stress tests were not showing any difference (indicating other bottlenecks), but I was able to get a clear difference with `many_foxes` with a fox count of 10,000: Test with `cargo run --example many_foxes --features bevy/trace_tracy,wayland --release -- --count 10000`: 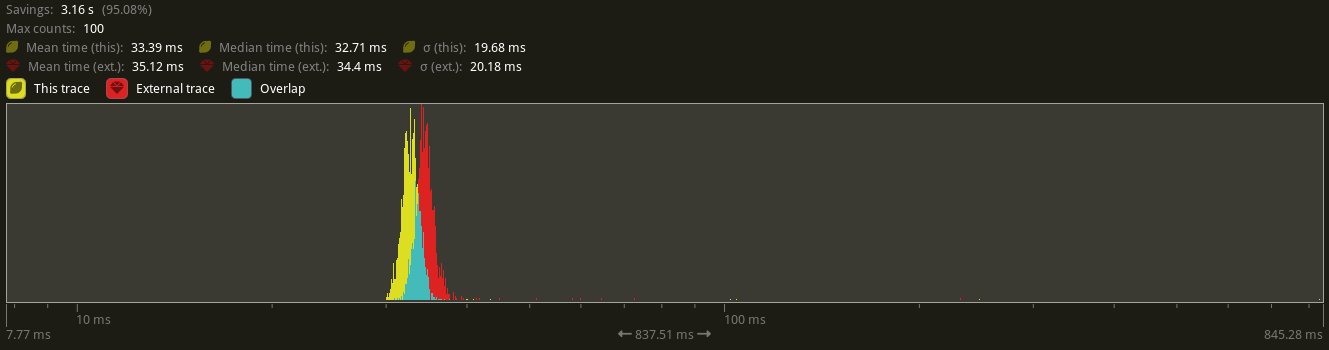 On avg, a framerate of about 28-29FPS was improved to 30-32FPS. "This trace" represents the current PR's perf, while "External trace" represents the `main` branch baseline. ## Changelog Changed: micro-optimized Entity align and field ordering as well as providing manual `PartialOrd`/`Ord` impls to help LLVM optimise further. ## Migration Guide Any `unsafe` code relying on field ordering of `Entity` or sufficiently cursed shenanigans should change to reflect the different internal representation and alignment requirements of `Entity`. Co-authored-by: james7132 <contact@jamessliu.com> Co-authored-by: NathanW <nathansward@comcast.net>
- Loading branch information
3 people
authored
Nov 18, 2023
1 parent
29f711c
commit 9c0fca0