Optimise Entity with repr align & manual PartialOrd/Ord
#10558
Conversation
|
@scottmcm could we get your review here? :) Really cool to see this work paying off. |
There was a problem hiding this comment.
Looks logically correct to me.
Codegen on ARM seems good too: https://godbolt.org/z/1o6oMGrbE
|
@alice-i-cecile My instinct here is that it might be a good idea to split this PR. The manual PartialOrd+Ord and the reversed field ordering is unambiguously good. (Maybe worse on BE, but does bevy even run on any BE targets?) That part I'd say definitely take. The It's also possible that it could be better to just store a TL/DR: it's possible that the align change is great, but it might be a good idea to double-check it on more benchmarks -- it's unrealistically good on the hashmap ones, since hashing calls |
crates/bevy_ecs/src/entity/mod.rs
Outdated
| // Alignment repr necessary to allow LLVM to better output | ||
| // optimised codegen for `to_bits`, `PartialEq` and `Ord`. | ||
| // See <https://github.com/rust-lang/rust/issues/106107> | ||
| #[repr(align(8))] |
There was a problem hiding this comment.
YMMV: you could consider adding an align: [u64; 0] field instead of the repr, which would make it aligned the same as u64, and thus less-aligned on smaller targets that don't care about 8-byte alignment for u64.
There was a problem hiding this comment.
Adding a field would complicate this PR, as then I'd have to change initialisation usages of Entity within the file. It would add either complication, or noise to change things to use new instead (which in my view, should be the case with constructors anyway). Also, the only 32-bit platform mainstream enough to worry about is wasm32, which should handle u64 just fine as it is a native type. All in all, I'd rather not complicate the structure of Entity too much. Maybe something for a different PR to explore if there's further potential there (or something to bake into #9797)
Currently it'll reorder them to reduce padding, but no, it doesn't look at the entire program to deduce from how it's use what order would be best for them to be in (yet 😏). |
|
Come to think of it, if #9907 lands to add a niche to Entity, that would allow the Oh, interesting: while looking for that PR above I accidentally found "Endianness based Entity representation" from Jan 2022 that looks like it proposed almost the same thing as what's here: |
There was a problem hiding this comment.
This shares a lot of overlap with #3788. I'm not sure if some of the results here are portable to non-little endian systems or if this would be an explicit rustc/LLVM-focused micro-optimization.
Also do note this has a knock-on effect for any type that has Entity as a member due to the alignment change, though that is probably OK given the number of types that already have u64s, usizes, and pointers within them.
Otherwise though, the results look good to me.
There was a problem hiding this comment.
This seems alright to me.
Just for future reference, it's important for future internal work that Entity values (or well, the underlying unified ID type as in #9797) sort in a specific way. So, for example, if we sort the following three Entity values, 3v1, 4v0, and 1v1, in ascending order, we should get 4v0, 1v1, 3v1. (i.e. to_bits returns generation in high bits, index in low bits)
We probably shouldn't make any guarantees about this for third-party usage though.
If it's guaranteed to return to being the same size as a |
I added tests for ordering in https://github.com/bevyengine/bevy/pull/10519/files#diff-64745065a7cefb843c5c5a881c561330ee9d06d3f1f36c28321788b97e64d88fR940, if you're wondering why they're not in this PR.
If Should there be a goal to keep this from being relied upon, it might be better to not implement the trait but have the internal code use a comparator of some sort. (I don't know how the ordering is used internally, though.) |
|
|
I've added a few bits brought up in the feedback, including fixing the struct layout with
|

Ideally, the bit representation ordering is kinda what we want if we want to separate |
Still works https://godbolt.org/z/fhdxWGPP8 |
There was a problem hiding this comment.
Added myself and @NathanSWard as co-authors in the PR description for the prior work on #3788 and #2372.
# Objective Keep essentially the same structure of `EntityHasher` from #9903, but rephrase the multiplication slightly to save an instruction. cc @superdump Discord thread: https://discord.com/channels/691052431525675048/1172033156845674507/1174969772522356756 ## Solution Today, the hash is ```rust self.hash = i | (i.wrapping_mul(FRAC_U64MAX_PI) << 32); ``` with `i` being `(generation << 32) | index`. Expanding things out, we get ```rust i | ( (i * CONST) << 32 ) = (generation << 32) | index | ((((generation << 32) | index) * CONST) << 32) = (generation << 32) | index | ((index * CONST) << 32) // because the generation overflowed = (index * CONST | generation) << 32 | index ``` What if we do the same thing, but with `+` instead of `|`? That's almost the same thing, except that it has carries, which are actually often better in a hash function anyway, since it doesn't saturate. (`|` can be dangerous, since once something becomes `-1` it'll stay that, and there's no mixing available.) ```rust (index * CONST + generation) << 32 + index = (CONST << 32 + 1) * index + generation << 32 = (CONST << 32 + 1) * index + (WHATEVER << 32 + generation) << 32 // because the extra overflows and thus can be anything = (CONST << 32 + 1) * index + ((CONST * generation) << 32 + generation) << 32 // pick "whatever" to be something convenient = (CONST << 32 + 1) * index + ((CONST << 32 + 1) * generation) << 32 = (CONST << 32 + 1) * index +((CONST << 32 + 1) * (generation << 32) = (CONST << 32 + 1) * (index + generation << 32) = (CONST << 32 + 1) * (generation << 32 | index) = (CONST << 32 + 1) * i ``` So we can do essentially the same thing using a single multiplication instead of doing multiply-shift-or. LLVM was already smart enough to merge the shifting into a multiplication, but this saves the extra `or`: 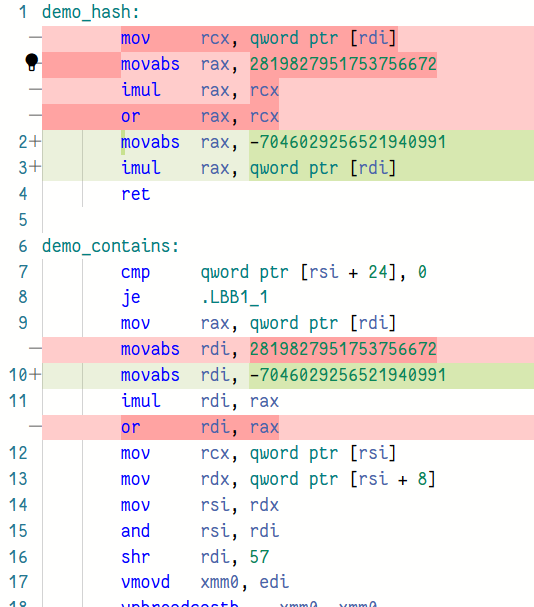 <https://rust.godbolt.org/z/MEvbz4eo4> It's a very small change, and often will disappear in load latency anyway, but it's a couple percent faster in lookups:  (There was more of an improvement here before #10558, but with `to_bits` being a single `qword` load now, keeping things mostly as it is turned out to be better than the bigger changes I'd tried in #10605.) --- ## Changelog (Probably skip it) ## Migration Guide (none needed)
…gine#10558) # Objective - Follow up on bevyengine#10519, diving deeper into optimising `Entity` due to the `derive`d `PartialOrd` `partial_cmp` not being optimal with codegen: rust-lang/rust#106107 - Fixes bevyengine#2346. ## Solution Given the previous PR's solution and the other existing LLVM codegen bug, there seemed to be a potential further optimisation possible with `Entity`. In exploring providing manual `PartialOrd` impl, it turned out initially that the resulting codegen was not immediately better than the derived version. However, once `Entity` was given `#[repr(align(8)]`, the codegen improved remarkably, even more once the fields in `Entity` were rearranged to correspond to a `u64` layout (Rust doesn't automatically reorder fields correctly it seems). The field order and `align(8)` additions also improved `to_bits` codegen to be a single `mov` op. In turn, this led me to replace the previous "non-shortcircuiting" impl of `PartialEq::eq` to use direct `to_bits` comparison. The result was remarkably better codegen across the board, even for hastable lookups. The current baseline codegen is as follows: https://godbolt.org/z/zTW1h8PnY Assuming the following example struct that mirrors with the existing `Entity` definition: ```rust #[derive(Clone, Copy, Eq, PartialEq, PartialOrd, Ord)] pub struct FakeU64 { high: u32, low: u32, } ``` the output for `to_bits` is as follows: ``` example::FakeU64::to_bits: shl rdi, 32 mov eax, esi or rax, rdi ret ``` Changing the struct to: ```rust #[derive(Clone, Copy, Eq)] #[repr(align(8))] pub struct FakeU64 { low: u32, high: u32, } ``` and providing manual implementations for `PartialEq`/`PartialOrd`/`Ord`, `to_bits` now optimises to: ``` example::FakeU64::to_bits: mov rax, rdi ret ``` The full codegen example for this PR is here for reference: https://godbolt.org/z/n4Mjx165a To highlight, `gt` comparison goes from ``` example::greater_than: cmp edi, edx jae .LBB3_2 xor eax, eax ret .LBB3_2: setne dl cmp esi, ecx seta al or al, dl ret ``` to ``` example::greater_than: cmp rdi, rsi seta al ret ``` As explained on Discord by @scottmcm : >The root issue here, as far as I understand it, is that LLVM's middle-end is inexplicably unwilling to merge loads if that would make them under-aligned. It leaves that entirely up to its target-specific back-end, and thus a bunch of the things that you'd expect it to do that would fix this just don't happen. ## Benchmarks Before discussing benchmarks, everything was tested on the following specs: AMD Ryzen 7950X 16C/32T CPU 64GB 5200 RAM AMD RX7900XT 20GB Gfx card Manjaro KDE on Wayland I made use of the new entity hashing benchmarks to see how this PR would improve things there. With the changes in place, I first did an implementation keeping the existing "non shortcircuit" `PartialEq` implementation in place, but with the alignment and field ordering changes, which in the benchmark is the `ord_shortcircuit` column. The `to_bits` `PartialEq` implementation is the `ord_to_bits` column. The main_ord column is the current existing baseline from `main` branch. 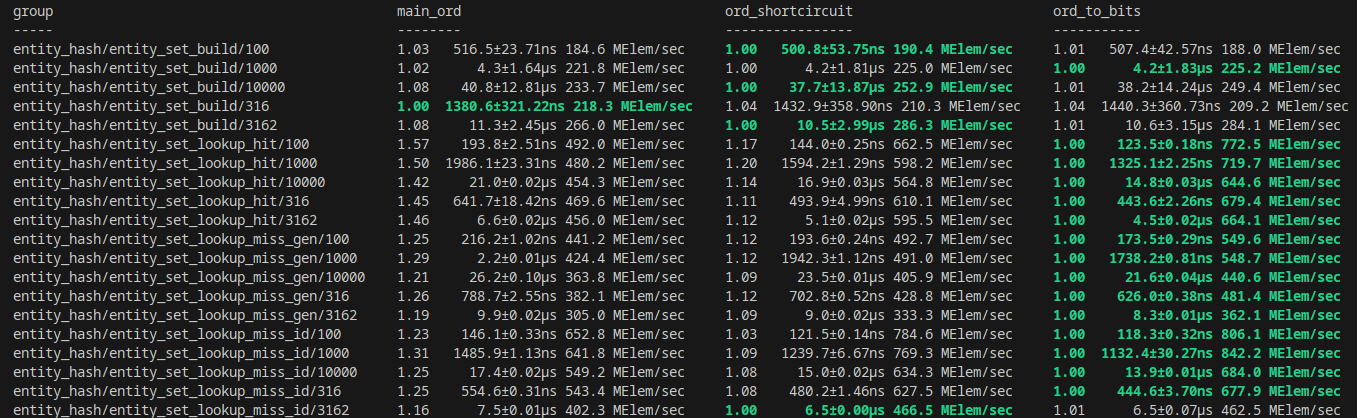 My machine is not super set-up for benchmarking, so some results are within noise, but there's not just a clear improvement between the non-shortcircuiting implementation, but even further optimisation taking place with the `to_bits` implementation. On my machine, a fair number of the stress tests were not showing any difference (indicating other bottlenecks), but I was able to get a clear difference with `many_foxes` with a fox count of 10,000: Test with `cargo run --example many_foxes --features bevy/trace_tracy,wayland --release -- --count 10000`: 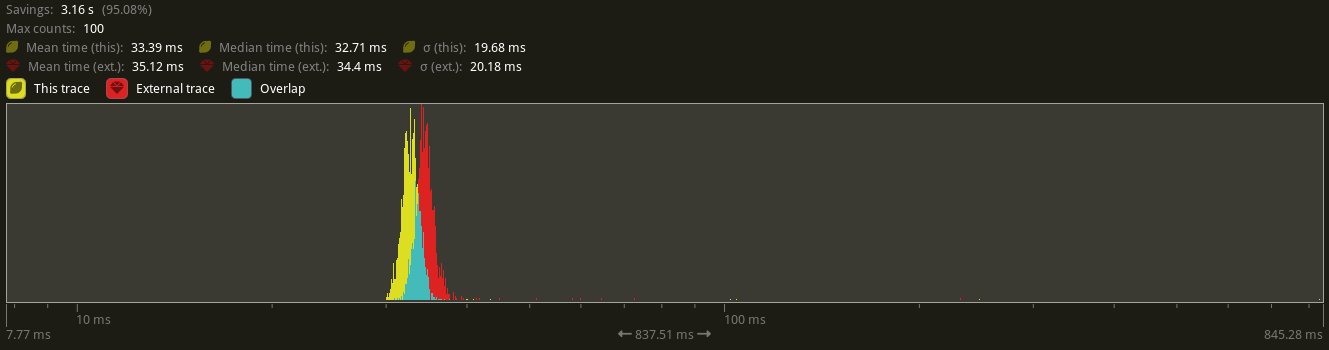 On avg, a framerate of about 28-29FPS was improved to 30-32FPS. "This trace" represents the current PR's perf, while "External trace" represents the `main` branch baseline. ## Changelog Changed: micro-optimized Entity align and field ordering as well as providing manual `PartialOrd`/`Ord` impls to help LLVM optimise further. ## Migration Guide Any `unsafe` code relying on field ordering of `Entity` or sufficiently cursed shenanigans should change to reflect the different internal representation and alignment requirements of `Entity`. Co-authored-by: james7132 <contact@jamessliu.com> Co-authored-by: NathanW <nathansward@comcast.net>
Objective
Entity::eq#10519, diving deeper into optimisingEntitydue to thederivedPartialOrdpartial_cmpnot being optimal with codegen: derivedPartialOrd::leis non-optimal for 2-field struct of primitive integers rust-lang/rust#106107Solution
Given the previous PR's solution and the other existing LLVM codegen bug, there seemed to be a potential further optimisation possible with
Entity. In exploring providing manualPartialOrdimpl, it turned out initially that the resulting codegen was not immediately better than the derived version. However, onceEntitywas given#[repr(align(8)], the codegen improved remarkably, even more once the fields inEntitywere rearranged to correspond to au64layout (Rust doesn't automatically reorder fields correctly it seems). The field order andalign(8)additions also improvedto_bitscodegen to be a singlemovop. In turn, this led me to replace the previous "non-shortcircuiting" impl ofPartialEq::eqto use directto_bitscomparison.The result was remarkably better codegen across the board, even for hastable lookups.
The current baseline codegen is as follows: https://godbolt.org/z/zTW1h8PnY
Assuming the following example struct that mirrors with the existing
Entitydefinition:the output for
to_bitsis as follows:Changing the struct to:
and providing manual implementations for
PartialEq/PartialOrd/Ord,to_bitsnow optimises to:The full codegen example for this PR is here for reference: https://godbolt.org/z/n4Mjx165a
To highlight,
gtcomparison goes fromto
As explained on Discord by @scottmcm :
Benchmarks
Before discussing benchmarks, everything was tested on the following specs:
AMD Ryzen 7950X 16C/32T CPU
64GB 5200 RAM
AMD RX7900XT 20GB Gfx card
Manjaro KDE on Wayland
I made use of the new entity hashing benchmarks to see how this PR would improve things there. With the changes in place, I first did an implementation keeping the existing "non shortcircuit"
PartialEqimplementation in place, but with the alignment and field ordering changes, which in the benchmark is theord_shortcircuitcolumn. Theto_bitsPartialEqimplementation is theord_to_bitscolumn. The main_ord column is the current existing baseline frommainbranch.My machine is not super set-up for benchmarking, so some results are within noise, but there's not just a clear improvement between the non-shortcircuiting implementation, but even further optimisation taking place with the
to_bitsimplementation.On my machine, a fair number of the stress tests were not showing any difference (indicating other bottlenecks), but I was able to get a clear difference with
many_foxeswith a fox count of 10,000:Test with
cargo run --example many_foxes --features bevy/trace_tracy,wayland --release -- --count 10000:On avg, a framerate of about 28-29FPS was improved to 30-32FPS. "This trace" represents the current PR's perf, while "External trace" represents the
mainbranch baseline.Changelog
Changed: micro-optimized Entity align and field ordering as well as providing manual
PartialOrd/Ordimpls to help LLVM optimise further.Migration Guide
Any
unsafecode relying on field ordering ofEntityor sufficiently cursed shenanigans should change to reflect the different internal representation and alignment requirements ofEntity.Co-authored-by: james7132 contact@jamessliu.com
Co-authored-by: NathanW nathansward@comcast.net