Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Save an instruction in
EntityHasher (#10648)
# Objective Keep essentially the same structure of `EntityHasher` from #9903, but rephrase the multiplication slightly to save an instruction. cc @superdump Discord thread: https://discord.com/channels/691052431525675048/1172033156845674507/1174969772522356756 ## Solution Today, the hash is ```rust self.hash = i | (i.wrapping_mul(FRAC_U64MAX_PI) << 32); ``` with `i` being `(generation << 32) | index`. Expanding things out, we get ```rust i | ( (i * CONST) << 32 ) = (generation << 32) | index | ((((generation << 32) | index) * CONST) << 32) = (generation << 32) | index | ((index * CONST) << 32) // because the generation overflowed = (index * CONST | generation) << 32 | index ``` What if we do the same thing, but with `+` instead of `|`? That's almost the same thing, except that it has carries, which are actually often better in a hash function anyway, since it doesn't saturate. (`|` can be dangerous, since once something becomes `-1` it'll stay that, and there's no mixing available.) ```rust (index * CONST + generation) << 32 + index = (CONST << 32 + 1) * index + generation << 32 = (CONST << 32 + 1) * index + (WHATEVER << 32 + generation) << 32 // because the extra overflows and thus can be anything = (CONST << 32 + 1) * index + ((CONST * generation) << 32 + generation) << 32 // pick "whatever" to be something convenient = (CONST << 32 + 1) * index + ((CONST << 32 + 1) * generation) << 32 = (CONST << 32 + 1) * index +((CONST << 32 + 1) * (generation << 32) = (CONST << 32 + 1) * (index + generation << 32) = (CONST << 32 + 1) * (generation << 32 | index) = (CONST << 32 + 1) * i ``` So we can do essentially the same thing using a single multiplication instead of doing multiply-shift-or. LLVM was already smart enough to merge the shifting into a multiplication, but this saves the extra `or`: 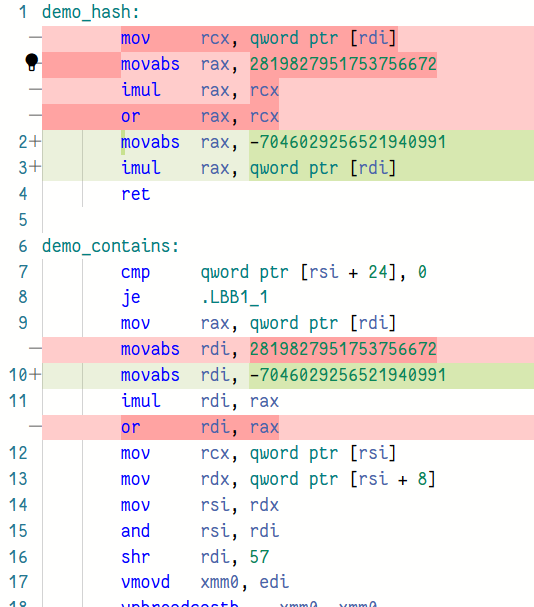 <https://rust.godbolt.org/z/MEvbz4eo4> It's a very small change, and often will disappear in load latency anyway, but it's a couple percent faster in lookups:  (There was more of an improvement here before #10558, but with `to_bits` being a single `qword` load now, keeping things mostly as it is turned out to be better than the bigger changes I'd tried in #10605.) --- ## Changelog (Probably skip it) ## Migration Guide (none needed)
- Loading branch information