Allow Mesh-related queue phase systems to parallelize #11804
Conversation
|
Does this have a significant effect on single threaded perf? |
|
Merge conflict. Code looks good. Could you test with a heavier single-material-type no-contention load like |
Checked against main and this PR. There seems to be next to zero impact on the average time spent, which makes sense: uncontended atomics on x86 machines is essentially free. There's a bit more variance, but not by much. Here's |

Most modern platforms (with maybe the exception of wasm) treat all load/store operations as atomic, and so long as there is no contention on the same cache line, it's identical to single threaded performance. The only thing you might be missing out on is the compiler reordering your operations to be more optimal, which isn't a particular concern for these systems. |
# Objective Partially addresses bevyengine#3548. `queue_shadows` and `queue_material_meshes` cannot parallelize because of the `ResMut<RenderMeshInstances>` parameter for `queue_material_meshes`. ## Solution Change the `material_bind_group` field to use atomics instead of needing full mutable access. Change the `ResMut` to a `Res`, which should allow both sets of systems to parallelize without issue. ## Performance Tested against `many_foxes`, this has a significant improvement over the entire render schedule. (Yellow is this PR, red is main) 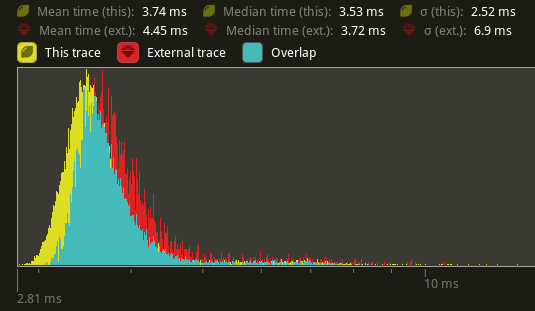 The use of atomics does seem to have a negative effect on `queue_material_meshes` (roughly a 8.29% increase in time spent in the system). 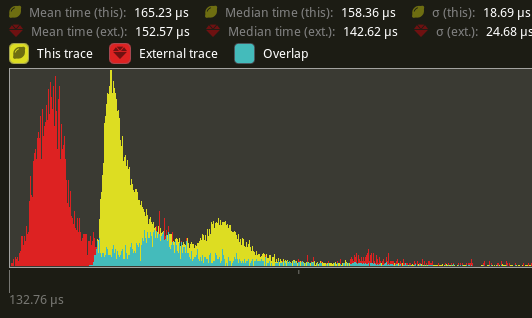 `queue_shadows` seems to be ever so slightly slower (1.6% more time spent) in the system.  `batch_and_prepare_render_phase` seems to be a mix, but overall seems to be slightly *faster* by about 5%. 
# Objective Partially addresses bevyengine#3548. `queue_shadows` and `queue_material_meshes` cannot parallelize because of the `ResMut<RenderMeshInstances>` parameter for `queue_material_meshes`. ## Solution Change the `material_bind_group` field to use atomics instead of needing full mutable access. Change the `ResMut` to a `Res`, which should allow both sets of systems to parallelize without issue. ## Performance Tested against `many_foxes`, this has a significant improvement over the entire render schedule. (Yellow is this PR, red is main)  The use of atomics does seem to have a negative effect on `queue_material_meshes` (roughly a 8.29% increase in time spent in the system).  `queue_shadows` seems to be ever so slightly slower (1.6% more time spent) in the system.  `batch_and_prepare_render_phase` seems to be a mix, but overall seems to be slightly *faster* by about 5%. 
# Objective - After #11804 , The queue_prepass_material_meshes function is now executed in parallel with other queue_* systems. This optimization introduced a potential issue where mesh_instance.should_batch() could return false in queue_prepass_material_meshes due to an unset material_bind_group_id.
Objective
Partially addresses #3548.
queue_shadowsandqueue_material_meshescannot parallelize because of theResMut<RenderMeshInstances>parameter forqueue_material_meshes.Solution
Change the
material_bind_groupfield to use atomics instead of needing full mutable access. Change theResMutto aRes, which should allow both sets of systems to parallelize without issue.Performance
Tested against

many_foxes, this has a significant improvement over the entire render schedule. (Yellow is this PR, red is main)The use of atomics does seem to have a negative effect on

queue_material_meshes(roughly a 8.29% increase in time spent in the system).queue_shadowsseems to be ever so slightly slower (1.6% more time spent) in the system.batch_and_prepare_render_phaseseems to be a mix, but overall seems to be slightly faster by about 5%.