Requiring mutable access to several common shared types prevents queue phase parallelization. #3548
Labels
A-Rendering
Drawing game state to the screen
C-Performance
A change motivated by improving speed, memory usage or compile times
Comments
github-merge-queue bot
pushed a commit
that referenced
this issue
Feb 20, 2024
# Objective Partially addresses #3548. `queue_shadows` and `queue_material_meshes` cannot parallelize because of the `ResMut<RenderMeshInstances>` parameter for `queue_material_meshes`. ## Solution Change the `material_bind_group` field to use atomics instead of needing full mutable access. Change the `ResMut` to a `Res`, which should allow both sets of systems to parallelize without issue. ## Performance Tested against `many_foxes`, this has a significant improvement over the entire render schedule. (Yellow is this PR, red is main) 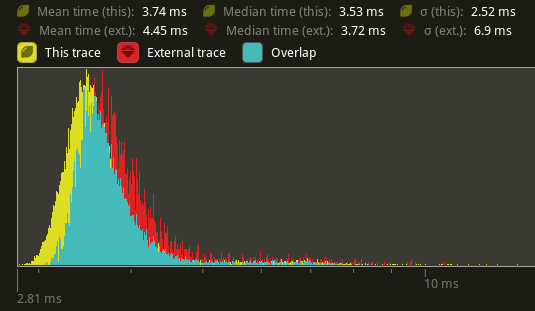 The use of atomics does seem to have a negative effect on `queue_material_meshes` (roughly a 8.29% increase in time spent in the system). 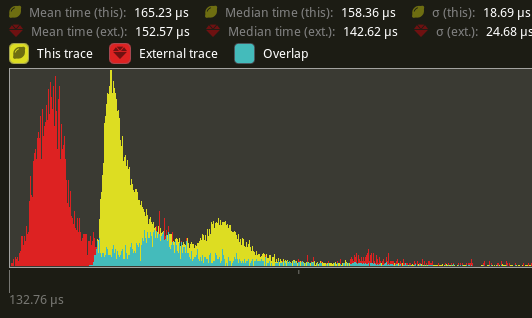 `queue_shadows` seems to be ever so slightly slower (1.6% more time spent) in the system.  `batch_and_prepare_render_phase` seems to be a mix, but overall seems to be slightly *faster* by about 5%. 
msvbg
pushed a commit
to msvbg/bevy
that referenced
this issue
Feb 26, 2024
# Objective Partially addresses bevyengine#3548. `queue_shadows` and `queue_material_meshes` cannot parallelize because of the `ResMut<RenderMeshInstances>` parameter for `queue_material_meshes`. ## Solution Change the `material_bind_group` field to use atomics instead of needing full mutable access. Change the `ResMut` to a `Res`, which should allow both sets of systems to parallelize without issue. ## Performance Tested against `many_foxes`, this has a significant improvement over the entire render schedule. (Yellow is this PR, red is main)  The use of atomics does seem to have a negative effect on `queue_material_meshes` (roughly a 8.29% increase in time spent in the system).  `queue_shadows` seems to be ever so slightly slower (1.6% more time spent) in the system.  `batch_and_prepare_render_phase` seems to be a mix, but overall seems to be slightly *faster* by about 5%. 
msvbg
pushed a commit
to msvbg/bevy
that referenced
this issue
Feb 26, 2024
# Objective Partially addresses bevyengine#3548. `queue_shadows` and `queue_material_meshes` cannot parallelize because of the `ResMut<RenderMeshInstances>` parameter for `queue_material_meshes`. ## Solution Change the `material_bind_group` field to use atomics instead of needing full mutable access. Change the `ResMut` to a `Res`, which should allow both sets of systems to parallelize without issue. ## Performance Tested against `many_foxes`, this has a significant improvement over the entire render schedule. (Yellow is this PR, red is main)  The use of atomics does seem to have a negative effect on `queue_material_meshes` (roughly a 8.29% increase in time spent in the system).  `queue_shadows` seems to be ever so slightly slower (1.6% more time spent) in the system.  `batch_and_prepare_render_phase` seems to be a mix, but overall seems to be slightly *faster* by about 5%. 
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
What problem does this solve or what need does it fill?
Query<&mut RenderPhase<T>>,RenderPipelineCache,SpecializedPipelines(to a lesser degree) requires mutable access to use. Each of these can limit the parallelism of the queue phase when rendering.Query<&mut RenderPhase<T>>limits it to one system per phase at a time. Generally allows parallelism across mutliple phases at the same time, unless there is one system that requires access to multiple render phases.RenderPipelineCachelimits any dependent pipeline from parallelizing.SpecializedPipelineslimits parallelization across multiple phases within a single extract-prepare-queue pipeline. This is less of an issue than the other two.What solution would you like?
SpecializedPipelinesfunctionality intoRenderPipelinesand make it generic over aSpecializedPipeline. This removes the global pipeline cache as a blocking requirement. Might also improve the ergonomics of writing those kinds of systems.RenderPhase<T>might benefit the most from this. Adding mutexes may be too much of a cost here. Perhaps a good place to try out lock-free data structures? Worth benchmarking.What alternative(s) have you considered?
The text was updated successfully, but these errors were encountered: