[WIP] Kernel IR Refactoring #249
Commits on Aug 7, 2020
-
[ONNX] Export tensor (pytorch#41872)
Summary: Adding tensor symbolic for opset 9 Pull Request resolved: pytorch#41872 Reviewed By: houseroad Differential Revision: D22968426 Pulled By: bzinodev fbshipit-source-id: 70e1afc7397e38039e2030e550fd72f09bac7c7c
-
Optimization of Backward Implementation for Learnable Fake Quantize P…
…er Tensor Kernels (CPU and GPU) (pytorch#42384) Summary: Pull Request resolved: pytorch#42384 In this diff, the original backward pass implementation is sped up by merging the 3 iterations computing dX, dScale, and dZeroPoint separately. In this case, a native loop is directly used on a byte-wise level (referenced by `strides`). In the benchmark test on the operators, for an input of shape `3x3x256x256`, we have observed the following improvement in performance: - original python operator: 1021037 microseconds - original learnable kernel: 407576 microseconds - optimized learnable kernel: 102584 microseconds - original non-backprop kernel: 139806 microseconds **Speedup from python operator**: ~10x **Speedup from original learnable kernel**: ~4x **Speedup from non-backprop kernel**: ~1.2x Test Plan: To assert correctness of the new kernel, on a devvm, enter the command `buck test //caffe2/test:quantization -- learnable_backward_per_tensor` To benchmark the operators, on a devvm, enter the command 1. Set the kernel size to 3x3x256x256 or a reasonable input size. 2. Run `buck test //caffe2/benchmarks/operator_benchmark/pt:quantization_test` 3. The relevant outputs are as follows: (CPU) ``` # Benchmarking PyTorch: FakeQuantizePerTensorOpBenchmark # Mode: Eager # Name: FakeQuantizePerTensorOpBenchmark_N3_C3_H256_W256_nbits4_cpu_op_typepy_module # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: py_module Backward Execution Time (us) : 1021036.957 # Benchmarking PyTorch: FakeQuantizePerTensorOpBenchmark # Mode: Eager # Name: FakeQuantizePerTensorOpBenchmark_N3_C3_H256_W256_nbits4_cpu_op_typelearnable_kernel # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: learnable_kernel Backward Execution Time (us) : 102583.693 # Benchmarking PyTorch: FakeQuantizePerTensorOpBenchmark # Mode: Eager # Name: FakeQuantizePerTensorOpBenchmark_N3_C3_H256_W256_nbits4_cpu_op_typeoriginal_kernel # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: original_kernel Backward Execution Time (us) : 139806.086 ``` (GPU) ``` # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typepy_module # Input: N: 3, C: 3, H: 256, W: 256, device: cuda, op_type: py_module Backward Execution Time (us) : 6548.350 # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typelearnable_kernel # Input: N: 3, C: 3, H: 256, W: 256, device: cuda, op_type: learnable_kernel Backward Execution Time (us) : 1340.724 # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typeoriginal_kernel # Input: N: 3, C: 3, H: 256, W: 256, device: cuda, op_type: original_kernel Backward Execution Time (us) : 656.863 ``` Reviewed By: vkuzo Differential Revision: D22875998 fbshipit-source-id: cfcd62c327bb622270a783d2cbe97f00508c4a16
-
[ONNX] Add preprocess pass for onnx export (pytorch#41832)
Summary: in `_jit_pass_onnx`, symbolic functions are called for each node for conversion. However, there are nodes that cannot be converted without additional context. For example, the number of outputs from split (and whether it is static or dynamic) is unknown until the point where it is unpacked by listUnpack node. This pass does a preprocess, and prepares the nodes such that enough context can be received by the symbolic function. * After preprocessing, `_jit_pass_onnx` should have enough context to produce valid ONNX nodes, instead of half baked nodes that replies on fixes from later postpasses. * `_jit_pass_onnx_peephole` should be a pass that does ONNX specific optimizations instead of ONNX specific fixes. * Producing more valid ONNX nodes in `_jit_pass_onnx` enables better utilization of the ONNX shape inference pytorch#40628. Pull Request resolved: pytorch#41832 Reviewed By: ZolotukhinM Differential Revision: D22968334 Pulled By: bzinodev fbshipit-source-id: 8226f03c5b29968e8197d242ca8e620c6e1d42a5
-
Print TE CUDA kernel (pytorch#42692)
Summary: Pull Request resolved: pytorch#42692 Test Plan: Imported from OSS Reviewed By: mruberry Differential Revision: D22986112 Pulled By: bertmaher fbshipit-source-id: 52ec3389535c8b276858bef8c470a59aeba4946f
-
Support iterating through an Enum class (pytorch#42661)
Summary: [5/N] Implement Enum JIT support Implement Enum class iteration Add aten.ne for EnumType Supported: Enum-typed function arguments using Enum type and comparing them Support getting name/value attrs of enums Using Enum value as constant Support Enum-typed return values Support iterating through Enum class (enum value list) TODO: Support serialization and deserialization Pull Request resolved: pytorch#42661 Reviewed By: SplitInfinity Differential Revision: D22977364 Pulled By: gmagogsfm fbshipit-source-id: 1a0216f91d296119e34cc292791f9aef1095b5a8
-
[blob reorder] Seperate user embeddings and ad embeddings in large mo…
…del loading script Summary: Put user embedding before ads embedding in blobReorder, for flash verification reason. Test Plan: ``` buck run mode/opt-clang -c python.package_style=inplace sigrid/predictor/scripts:enable_large_model_loading -- --model_path_src="/home/$USER/models/" --model_path_dst="/home/$USER/models_modified/" --model_file_name="182560549_0.predictor" ``` https://www.internalfb.com/intern/anp/view/?id=320921 to check blobsOrder Reviewed By: yinghai Differential Revision: D22964332 fbshipit-source-id: 78b4861476a3c889a5ff62492939f717c307a8d2
-
Updates alias pattern (and torch.absolute to use it) (pytorch#42586)
Summary: This PR canonicalizes our (current) pattern for adding aliases to PyTorch. That pattern is: - Copy the original functions native_functions.yaml entry, but replace the original function's name with their own. - Implement the corresponding functions and have them redispatch to the original function. - Add docstrings to the new functions that reference the original function. - Update the alias_map in torch/csrc/jit/passes/normalize_ops.cpp. - Update the op_alias_mappings in torch/testing/_internal/jit_utils.py. - Add a test validating the alias's behavior is the same as the original function's. An alternative pattern would be to use Python and C++ language features to alias ops directly. For example in Python: ``` torch.absolute = torch.abs ``` Let the pattern in this PR be the "native function" pattern, and the alternative pattern be the "language pattern." There are pros/cons to both approaches: **Pros of the "Language Pattern"** - torch.absolute is torch.abs. - no (or very little) overhead for calling the alias. - no native_functions.yaml redundancy or possibility of "drift" between the original function's entries and the alias's. **Cons of the "Language Pattern"** - requires manually adding doc entries - requires updating Python alias and C++ alias lists - requires hand writing alias methods on Tensor (technically this should require a C++ test to validate) - no single list of all PyTorch ops -- have to check native_functions.yaml and one of the separate alias lists **Pros of the "Native Function" pattern** - alias declarations stay in native_functions.yaml - doc entries are written as normal **Cons of the "Native Function" pattern** - aliases redispatch to the original functions - torch.absolute is not torch.abs (requires writing test to validate behavior) - possibility of drift between original's and alias's native_functions.yaml entries While either approach is reasonable, I suggest the "native function" pattern since it preserves "native_functions.yaml" as a source of truth and minimizes the number of alias lists that need to be maintained. In the future, entries in native_functions.yaml may support an "alias" argument and replace whatever pattern we choose now. Ops that are likely to use aliasing are: - div (divide, true_divide) - mul (multiply) - bucketize (digitize) - cat (concatenate) - clamp (clip) - conj (conjugate) - rad2deg (degrees) - trunc (fix) - neg (negative) - deg2rad (radians) - round (rint) - acos (arccos) - acosh (arcosh) - asin (arcsin) - asinh (arcsinh) - atan (arctan) - atan2 (arctan2) - atanh (arctanh) - bartlett_window (bartlett) - hamming_window (hamming) - hann_window (hanning) - bitwise_not (invert) - gt (greater) - ge (greater_equal) - lt (less) - le (less_equal) - ne (not_equal) - ger (outer) Pull Request resolved: pytorch#42586 Reviewed By: ngimel Differential Revision: D22991086 Pulled By: mruberry fbshipit-source-id: d6ac96512d095b261ed2f304d7dddd38cf45e7b0
-
Add use_glow_aot, and include ONNX again as a backend for onnxifiGlow (…
…pytorch#4787) Summary: Pull Request resolved: pytorch/glow#4787 Resurrect ONNX as a backend through onnxifiGlow (was killed as part of D16215878). Then look for the `use_glow_aot` argument in the Onnxifi op. If it's there and true, then we override whatever `backend_id` is set and use the ONNX backend. Reviewed By: yinghai, rdzhabarov Differential Revision: D22762123 fbshipit-source-id: abb4c3458261f8b7eeae3016dda5359fa85672f0
-
Blacklist to Blocklist in onnxifi_transformer (pytorch#42590)
Summary: Fixes issues in pytorch#41704 and pytorch#41705 Pull Request resolved: pytorch#42590 Reviewed By: ailzhang Differential Revision: D22977357 Pulled By: malfet fbshipit-source-id: ab61b964cfdf8bd2b469f4ff8f6486a76bc697de
-
[vulkan] Ops registration to TORCH_LIBRARY_IMPL (pytorch#42194)
Summary: Pull Request resolved: pytorch#42194 Test Plan: Imported from OSS Reviewed By: AshkanAliabadi Differential Revision: D22803036 Pulled By: IvanKobzarev fbshipit-source-id: 2f402541aecf887d78f650bf05d758a0e403bc4d
-
Fix cmake warning (pytorch#42707)
Summary: If argumenets in set_target_properties are not separated by whitespace, cmake raises a warning: ``` CMake Warning (dev) at cmake/public/cuda.cmake:269: Syntax Warning in cmake code at column 54 Argument not separated from preceding token by whitespace. ``` Fixes #{issue number} Pull Request resolved: pytorch#42707 Reviewed By: ailzhang Differential Revision: D22988055 Pulled By: malfet fbshipit-source-id: c3744f23b383d603788cd36f89a8286a46b6c00f -
[CPU] Added torch.bmm for complex tensors (pytorch#42383)
Summary: Pull Request resolved: pytorch#42383 Test Plan - Updated existing tests to run for complex dtypes as well. Also added tests for `torch.addmm`, `torch.badmm` Test Plan: Imported from OSS Reviewed By: ezyang Differential Revision: D22960339 Pulled By: anjali411 fbshipit-source-id: 0805f21caaa40f6e671cefb65cef83a980328b7d
-
Adds torch.linalg namespace (pytorch#42664)
Summary: This PR adds the `torch.linalg` namespace as part of our continued effort to be more compatible with NumPy. The namespace is tested by adding a single function, `torch.linalg.outer`, and testing it in a new test suite, test_linalg.py. It follows the same pattern that pytorch#41911, which added the `torch.fft` namespace, did. Future PRs will likely: - add more functions to torch.linalg - expand the testing done in test_linalg.py, including legacy functions, like torch.ger - deprecate existing linalg functions outside of `torch.linalg` in preference to the new namespace Pull Request resolved: pytorch#42664 Reviewed By: ngimel Differential Revision: D22991019 Pulled By: mruberry fbshipit-source-id: 39258d9b116a916817b3588f160b141f956e5d0b
-
Fix some linking rules to allow path with whitespaces (pytorch#42718)
Summary: Essentially, replace `-Wl,--whole-archive,$<TARGET_FILE:FOO>` with `-Wl,--whole-archive,\"$<TARGET_FILE:FOO>\"` as TARGET_FILE might return path containing whitespaces Fixes pytorch#42657 Pull Request resolved: pytorch#42718 Reviewed By: ezyang Differential Revision: D22993568 Pulled By: malfet fbshipit-source-id: de878b17d20e35b51dd350f20d079c8b879f70b5
-
Handle fused scale and bias in fake fp16 layernorm
Summary: Allow passing scale and bias to fake fp16 layernorm. Test Plan: net_runner. Now matches glow's fused layernorm. Reviewed By: hyuen Differential Revision: D22952646 fbshipit-source-id: cf9ad055b14f9d0167016a18a6b6e26449cb4de8
-
[NNC] Remove VarBinding and go back to Let stmts (pytorch#42634)
Summary: Awhile back when commonizing the Let and LetStmt nodes, I ended up removing both and adding a separate VarBinding section the Block. At the time I couldn't find a counter example, but I found it today: Local Vars and Allocations dependencies may go in either direction and so we need to support interleaving of those statements. So, I've removed all the VarBinding logic and reimplemented Let statements. ZolotukhinM I think you get to say "I told you so". No new tests, existing tests should cover this. Pull Request resolved: pytorch#42634 Reviewed By: mruberry Differential Revision: D22969771 Pulled By: nickgg fbshipit-source-id: a46c5193357902d0f59bf30ab103fe123b1503f1
-
Remove duplicate definitions of CppTypeToScalarType (pytorch#42640)
Summary: I noticed that `TensorIteratorDynamicCasting.h` defines a helper meta-function `CPPTypeToScalarType` which does exactly the same thing as the `c10::CppTypeToScalarType` meta-function I added in pytorchgh-40927. No need for two identical definitions. Pull Request resolved: pytorch#42640 Reviewed By: malfet Differential Revision: D22969708 Pulled By: ezyang fbshipit-source-id: 8303c7f4a75ae248f393a4811ae9d2bcacab44ff
-
[vulkan] Fix warnings: static_cast, remove unused (pytorch#42195)
Summary: Pull Request resolved: pytorch#42195 Test Plan: Imported from OSS Reviewed By: AshkanAliabadi Differential Revision: D22803035 Pulled By: IvanKobzarev fbshipit-source-id: d7bf256437eccb5c421a7fd0aa8ec23a8fec0470
-
Minor typo fix (pytorch#42731)
Summary: Just fixed a typo in test/test_sparse.py Pull Request resolved: pytorch#42731 Reviewed By: ezyang Differential Revision: D22999930 Pulled By: mrshenli fbshipit-source-id: 1b5b21d7cb274bd172fb541b2761f727ba06302c
-
[JIT] Exclude staticmethods from TS class compilation (pytorch#42611)
Summary: Pull Request resolved: pytorch#42611 **Summary** This commit modifies the Python frontend to ignore static functions on Torchscript classes when compiling them. They are currently included along with methods, which causes the first argument of the staticfunction to be unconditionally inferred to be of the type of the class it belongs to (regardless of how it is annotated or whether it is annotated at all). This can lead to compilation errors depending on how that argument is used in the body of the function. Static functions are instead imported and scripted as if they were standalone functions. **Test Plan** This commit augments the unit test for static methods in `test_class_types.py` to test that static functions can call each other and the class constructor. **Fixes** This commit fixes pytorch#39308. Test Plan: Imported from OSS Reviewed By: ZolotukhinM Differential Revision: D22958163 Pulled By: SplitInfinity fbshipit-source-id: 45c3c372792299e6e5288e1dbb727291e977a2af
-
C++ API TransformerEncoderLayer (pytorch#42633)
Summary: Pull Request resolved: pytorch#42633 Test Plan: Imported from OSS Reviewed By: ezyang Differential Revision: D22994332 Pulled By: glaringlee fbshipit-source-id: 873abdf887d135fb05bde560d695e2e8c992c946
-
Speed up HistogramObserver by vectorizing critical path (pytorch#41041)
Summary: 22x speedup over the code this replaces. Tested on ResNet18 on a devvm using CPU only, using default parameters for HistogramObserver (i.e. 2048 bins). Pull Request resolved: pytorch#41041 Test Plan: To run the test against the reference (old) implementation, you can use `python test/test_quantization.py TestRecordHistogramObserver.test_histogram_observer_against_reference`. To run the benchmark, while in the folder `benchmarks/operator_benchmark`, you can use `python -m benchmark_all_quantized_test --operators HistogramObserverCalculateQparams`. Benchmark results before speedup: ``` # ---------------------------------------- # PyTorch/Caffe2 Operator Micro-benchmarks # ---------------------------------------- # Tag : short # Benchmarking PyTorch: HistogramObserverCalculateQparams # Mode: Eager # Name: HistogramObserverCalculateQparams_C3_M512_N512_dtypetorch.quint8_cpu_qschemetorch.per_tensor_affine # Input: C: 3, M: 512, N: 512, dtype: torch.quint8, device: cpu, qscheme: torch.per_tensor_affine Forward Execution Time (us) : 185818.566 # Benchmarking PyTorch: HistogramObserverCalculateQparams # Mode: Eager # Name: HistogramObserverCalculateQparams_C3_M512_N512_dtypetorch.quint8_cpu_qschemetorch.per_tensor_symmetric # Input: C: 3, M: 512, N: 512, dtype: torch.quint8, device: cpu, qscheme: torch.per_tensor_symmetric Forward Execution Time (us) : 165325.916 ``` Benchmark results after speedup: ``` # ---------------------------------------- # PyTorch/Caffe2 Operator Micro-benchmarks # ---------------------------------------- # Tag : short # Benchmarking PyTorch: HistogramObserverCalculateQparams # Mode: Eager # Name: HistogramObserverCalculateQparams_C3_M512_N512_dtypetorch.quint8_cpu_qschemetorch.per_tensor_affine # Input: C: 3, M: 512, N: 512, dtype: torch.quint8, device: cpu, qscheme: torch.per_tensor_affine Forward Execution Time (us) : 12242.241 # Benchmarking PyTorch: HistogramObserverCalculateQparams # Mode: Eager # Name: HistogramObserverCalculateQparams_C3_M512_N512_dtypetorch.quint8_cpu_qschemetorch.per_tensor_symmetric # Input: C: 3, M: 512, N: 512, dtype: torch.quint8, device: cpu, qscheme: torch.per_tensor_symmetric Forward Execution Time (us) : 12655.354 ``` Reviewed By: raghuramank100 Differential Revision: D22400755 Pulled By: durumu fbshipit-source-id: 639ac796a554710a33c8a930c1feae95a1148718
-
BAND, BOR and BXOR for NCCL (all_)reduce should throw runtime errors (p…
…ytorch#42669) Summary: cc rohan-varma Fixes pytorch#41362 pytorch#39708 # Description NCCL doesn't support `BAND, BOR, BXOR`. Since the [current mapping](https://github.com/pytorch/pytorch/blob/0642d17efc73041e5209e3be265d9a39892e8908/torch/lib/c10d/ProcessGroupNCCL.cpp#L39) doesn't contain any of the mentioned bitwise operator, a default value of `ncclSum` is used instead. This PR should provide the expected behaviour where a runtime exception is thrown. # Notes - The way I'm throwing exceptions is derived from [ProcessGroupGloo.cpp](https://github.com/pytorch/pytorch/blob/0642d17efc73041e5209e3be265d9a39892e8908/torch/lib/c10d/ProcessGroupGloo.cpp#L101) Pull Request resolved: pytorch#42669 Reviewed By: ezyang Differential Revision: D22996295 Pulled By: rohan-varma fbshipit-source-id: 83a9fedf11050d2890f9f05ebcedf53be0fc3516
-
[caffe2] add type annotations for caffe2.distributed.python
Summary: Add Python type annotations for the `caffe2.distributed.python` module. Test Plan: Will check sandcastle results. Reviewed By: jeffdunn Differential Revision: D22994012 fbshipit-source-id: 30565cc41dd05b5fbc639ae994dfe2ddd9e56cb1
-
Automated submodule update: FBGEMM (pytorch#42713)
Summary: This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM). New submodule commit: pytorch/FBGEMM@a989b99 Pull Request resolved: pytorch#42713 Test Plan: Ensure that CI jobs succeed on GitHub before landing. Reviewed By: amylittleyang Differential Revision: D22990108 Pulled By: jspark1105 fbshipit-source-id: 3252a0f5ad9546221ef2fe908ce6b896252e1887
-
fix celu in quantized benchmark (pytorch#42756)
Summary: Pull Request resolved: pytorch#42756 Similar to ELU, CELU was also broken in the quantized benchmark, fixing. Test Plan: ``` cd benchmarks/operator_benchmark python -m pt.qactivation_test ``` Imported from OSS Reviewed By: jerryzh168 Differential Revision: D23010863 fbshipit-source-id: 203e63f9cff760af6809f6f345b0d222dc1e9e1b
-
Restrict conversion to SmallVector (pytorch#42694)
Summary: Pull Request resolved: pytorch#42694 The old implementation allowed calling SmallVector constructor and operator= for any type without restrictions, but then failed with a compiler error when the type wasn't a collection. Instead, we should only use it if Container follows a container concept and just not match the constructor otherwise. This fixes an issue kimishpatel was running into. ghstack-source-id: 109370513 Test Plan: unit tests Reviewed By: kimishpatel, ezyang Differential Revision: D22983020 fbshipit-source-id: c31264f5c393762d822f3d64dd2a8e3279d8da44
-
Skips some complex tests on ROCm (pytorch#42759)
Summary: Fixes ROCm build on OSS master. Pull Request resolved: pytorch#42759 Reviewed By: ngimel Differential Revision: D23011560 Pulled By: mruberry fbshipit-source-id: 3339ecbd5a0ca47aede6f7c3f84739af1ac820d5
-
Exposing Percentile Caffe2 Operator in PyTorch
Summary: As titled. Test Plan: ``` buck test caffe2/caffe2/python/operator_test:torch_integration_test -- test_percentile ``` Reviewed By: yf225 Differential Revision: D22999896 fbshipit-source-id: 2e3686cb893dff1518d533cb3d78c92eb2a6efa5
Commits on Aug 8, 2020
-
Add fake quantize operator that works in backward pass (pytorch#40532)
Summary: This diff adds FakeQuantizeWithBackward. This works the same way as the regular FakeQuantize module, allowing QAT to occur in the forward pass, except it has an additional quantize_backward parameter. When quantize_backward is enabled, the gradients are fake quantized as well (dynamically, using hard-coded values). This allows the user to see whether there would be a significant loss of accuracy if the gradients were quantized in their model. Pull Request resolved: pytorch#40532 Test Plan: The relevant test for this can be run using `python test/test_quantization.py TestQATBackward.test_forward_and_backward` Reviewed By: supriyar Differential Revision: D22217029 Pulled By: durumu fbshipit-source-id: 7055a2cdafcf022f1ea11c3442721ae146d2b3f2
-
Fix lite trainer unit test submodule registration (pytorch#42714)
Summary: Pull Request resolved: pytorch#42714 Change two unit tests for the lite trainer to register two instances/objects of the same submodule type instead of the same submodule object twice. Test Plan: Imported from OSS Reviewed By: iseeyuan Differential Revision: D22990736 Pulled By: ann-ss fbshipit-source-id: 2bf56b5cc438b5a5fc3db90d3f30c5c431d3ae77
-
[fbgemm] use new more general depthwise 3d conv interface (pytorch#42697
) Summary: Pull Request resolved: pytorch#42697 Pull Request resolved: pytorch/FBGEMM#401 As title Test Plan: CI Reviewed By: dskhudia Differential Revision: D22972233 fbshipit-source-id: a2c8e989dee84b2c0587faccb4f8e3bcb05c797c
-
[caffe2] Fix the timeout (stuck) issues of dedup SparseAdagrad C2 kernel
Summary: Backout D22800959 (pytorch@f30ac66). This one is causing the timeout (machine stuck) issues for dedup kernels. Reverting it make the unit test pass. Still need to investigate why this is the culprit... Original commit changeset: 641d52a51070 Test Plan: ``` buck test mode/dev-nosan //caffe2/caffe2/fb/net_transforms/tests:fuse_sparse_ops_test -- 'test_fuse_sparse_adagrad_with_sparse_lengths_sum_gradient \(caffe2\.caffe2\.fb\.net_transforms\.tests\.fuse_sparse_ops_test\.TestFuseSparseOps\)' --print-passing-details ``` Reviewed By: jspark1105 Differential Revision: D23008389 fbshipit-source-id: 4f1b9a41c78eaa5541d57b9d8aa12401e1d495f2
-
[NCCL] DDP communication hook: getFuture() without cudaStreamAddCallb…
…ack (pytorch#42335) Summary: Pull Request resolved: pytorch#42335 **Main goal:** For DDP communication hook, provide an API called "get_future" to retrieve a future associated with the completion of c10d.ProcessGroupNCCL.work. Enable NCCL support for this API in this diff. We add an API `c10::intrusive_ptr<c10::ivalue::Future> getFuture()` to `c10d::ProcessGroup::Work`. This API will only be supported by NCCL in the first version, the default implementation will throw UnsupportedOperation. We no longer consider a design that involves cudaStreamAddCallback which potentially was causing performance regression in [pytorch#41596](pytorch#41596). ghstack-source-id: 109461507 Test Plan: ```(pytorch) [sinannasir@devgpu017.ash6 ~/local/pytorch] python test/distributed/test_c10d.py Couldn't download test skip set, leaving all tests enabled... ..............................s.....................................................s................................ ---------------------------------------------------------------------- Ran 117 tests in 298.042s OK (skipped=2) ``` ### Facebook Internal: 2\. HPC PT trainer run to validate no regression. Check the QPS number: **Master:** QPS after 1000 iters: around ~34100 ``` hpc_dist_trainer --fb-data=none --mtml-fusion-level=1 --target-model=ifr_video --max-ind-range=1000000 --embedding-partition=row-wise mast --domain $USER"testvideo_master" --trainers 16 --trainer-version 1c53912 ``` ``` [0] I0806 142048.682 metrics_publishers.py:50] Finished iter 999, Local window NE: [0.963963 0.950479 0.953704], lifetime NE: [0.963963 0.950479 0.953704], loss: [0.243456 0.235225 0.248375], QPS: 34199 ``` [detailed logs](https://www.internalfb.com/intern/tupperware/details/task/?handle=priv3_global%2Fmast_hpc%2Fhpc.sinannasirtestvideo_mastwarm.trainer.trainer%2F0&ta_tab=logs) **getFuture/new design:** QPS after 1000 iters: around ~34030 ``` hpc_dist_trainer --fb-data=none --mtml-fusion-level=1 --target-model=ifr_video --max-ind-range=1000000 --embedding-partition=row-wise mast --domain $USER"testvideo_getFutureCyclicFix" --trainers 16 --trainer-version 8553aee ``` ``` [0] I0806 160149.197 metrics_publishers.py:50] Finished iter 999, Local window NE: [0.963959 0.950477 0.953704], lifetime NE: [0.963959 0.950477 0.953704], loss: [0.243456 0.235225 0.248375], QPS: 34018 ``` [detailed logs](https://www.internalfb.com/intern/tupperware/details/task/?handle=priv3_global%2Fmast_hpc%2Fhpc.sinannasirtestvideo_getFutureCyclicFix.trainer.trainer%2F0&ta_tab=logs) **getFuture/new design Run 2:** QPS after 1000 iters: around ~34200 ``` hpc_dist_trainer --fb-data=none --mtml-fusion-level=1 --target-model=ifr_video --max-ind-range=1000000 --embedding-partition=row-wise mast --domain $USER"test2video_getFutureCyclicFix" --trainers 16 --trainer-version 8553aee ``` ``` [0] I0806 160444.650 metrics_publishers.py:50] Finished iter 999, Local window NE: [0.963963 0.950482 0.953706], lifetime NE: [0.963963 0.950482 0.953706], loss: [0.243456 0.235225 0.248375], QPS: 34201 ``` [detailed logs](https://www.internalfb.com/intern/tupperware/details/task/?handle=priv3_global%2Fmast_hpc%2Fhpc.sinannasirtest2video_getFutureCyclicFix.trainer.trainer%2F0&ta_tab=logs) **getFuture/old design (Regression):** QPS after 1000 iters: around ~31150 ``` hpc_dist_trainer --fb-data=none --mtml-fusion-level=1 --target-model=ifr_video --max-ind-range=1000000 --embedding-partition=row-wise mast --domain $USER”testvideo_OLDgetFutureD22583690 (pytorch@d904ea5)" --trainers 16 --trainer-version 1cb5cbb ``` ``` priv3_global/mast_hpc/hpc.sinannasirtestvideo_OLDgetFutureD22583690 (https://github.com/pytorch/pytorch/commit/d904ea597277673eefbb3661430d3f905e8760d5).trainer.trainer/0 [0] I0805 101320.407 metrics_publishers.py:50] Finished iter 999, Local window NE: [0.963964 0.950482 0.953703], lifetime NE: [0.963964 0.950482 0.953703], loss: [0.243456 0.235225 0.248375], QPS: 31159 ``` 3\. `flow-cli` tests; roberta_base; world_size=4: **Master:** f210039922 ``` total: 32 GPUs -- 32 GPUs: p25: 0.908 35/s p50: 1.002 31/s p75: 1.035 30/s p90: 1.051 30/s p95: 1.063 30/s forward: 32 GPUs -- 32 GPUs: p25: 0.071 452/s p50: 0.071 449/s p75: 0.072 446/s p90: 0.072 445/s p95: 0.072 444/s backward: 32 GPUs -- 32 GPUs: p25: 0.821 38/s p50: 0.915 34/s p75: 0.948 33/s p90: 0.964 33/s p95: 0.976 32/s optimizer: 32 GPUs -- 32 GPUs: p25: 0.016 2037/s p50: 0.016 2035/s p75: 0.016 2027/s p90: 0.016 2019/s p95: 0.016 2017/s ``` **getFuture new design:** f210285797 ``` total: 32 GPUs -- 32 GPUs: p25: 0.952 33/s p50: 1.031 31/s p75: 1.046 30/s p90: 1.055 30/s p95: 1.070 29/s forward: 32 GPUs -- 32 GPUs: p25: 0.071 449/s p50: 0.072 446/s p75: 0.072 445/s p90: 0.072 444/s p95: 0.072 443/s backward: 32 GPUs -- 32 GPUs: p25: 0.865 37/s p50: 0.943 33/s p75: 0.958 33/s p90: 0.968 33/s p95: 0.982 32/s optimizer: 32 GPUs -- 32 GPUs: p25: 0.016 2037/s p50: 0.016 2033/s p75: 0.016 2022/s p90: 0.016 2018/s p95: 0.016 2017/s ``` Reviewed By: ezyang Differential Revision: D22833298 fbshipit-source-id: 1bb268d3b00335b42ee235c112f93ebe2f25b208
-
Adding Peter's Swish Op ULP analysis. (pytorch#42573)
Summary: Pull Request resolved: pytorch#42573 * Generate the ULP png files for different ranges. Test Plan: test_op_ulp_error.py Reviewed By: hyuen Differential Revision: D22938572 fbshipit-source-id: 6374bef6d44c38e1141030d44029dee99112cd18
-
Set proper return type (pytorch#42454)
Summary: This function was always expecting to return a `size_t` value Pull Request resolved: pytorch#42454 Reviewed By: ezyang Differential Revision: D22993168 Pulled By: ailzhang fbshipit-source-id: 044df8ce17983f04681bda8c30cd742920ef7b1e
-
[vulkan] inplace add_, relu_ (pytorch#41380)
Summary: Pull Request resolved: pytorch#41380 Test Plan: Imported from OSS Reviewed By: AshkanAliabadi Differential Revision: D22754939 Pulled By: IvanKobzarev fbshipit-source-id: 19b0bbfc5e1f149f9996b5043b77675421ecb2ed
-
update DispatchKey::toString() (pytorch#42619)
Summary: Pull Request resolved: pytorch#42619 Added missing entries to `DispatchKey::toString()` and reordered to match declaration order in `DispatchKey.h` Test Plan: Imported from OSS Reviewed By: ezyang Differential Revision: D22963407 Pulled By: bhosmer fbshipit-source-id: 34a012135599f497c308ba90ea6e8117e85c74ac
-
integrate int8 swish with net transformer
Summary: add a fuse path for deq->swish->quant update swish fake op interface to take arguments accordingly Test Plan: net_runner passes unit tests need to be updated Reviewed By: venkatacrc Differential Revision: D22962064 fbshipit-source-id: cef79768db3c8af926fca58193d459d671321f80
-
Revert D22217029: Add fake quantize operator that works in backward pass
Test Plan: revert-hammer Differential Revision: D22217029 (pytorch@48e978b) Original commit changeset: 7055a2cdafcf fbshipit-source-id: f57a27be412c6fbfd5a5b07a26f758ac36be3b67
-
[PyFI] Update hypothesis and switch from tp2 (pytorch#41645)
Summary: Pull Request resolved: pytorch#41645 Pull Request resolved: facebookresearch/pytext#1405 Test Plan: buck test Reviewed By: thatch Differential Revision: D20323893 fbshipit-source-id: 54665d589568c4198e96a27f0ed8e5b41df7b86b
-
fix asan failure for module freezing in conv bn folding (pytorch#42739)
Summary: Pull Request resolved: pytorch#42739 This is a test case which fails with ASAN on at the module freezing step. Test Plan: ``` USE_ASAN=1 USE_CUDA=0 python setup.py develop LD_PRELOAD=/usr/lib64/libasan.so.4 python test/test_mobile_optimizer.py TestOptimizer.test_optimize_for_mobile_asan // output tail: https://gist.github.com/vkuzo/7a0018b9e10ffe64dab0ac7381479f23 ``` Imported from OSS Reviewed By: kimishpatel Differential Revision: D23005962 fbshipit-source-id: b7d4492e989af7c2e22197c16150812bd2dda7cc
-
optimize_for_mobile: bring packed params to root module (pytorch#42740)
Summary: Pull Request resolved: pytorch#42740 Adds a pass to hoist conv packed params to root module. The benefit is that if there is nothing else in the conv module, subsequent passes will delete it, which will reduce module size. For context, freezing does not handle this because conv packed params is a custom object. Test Plan: ``` PYTORCH_JIT_LOG_LEVEL=">hoist_conv_packed_params.cpp" python test/test_mobile_optimizer.py TestOptimizer.test_hoist_conv_packed_params ``` Imported from OSS Reviewed By: kimishpatel Differential Revision: D23005961 fbshipit-source-id: 31ab1f5c42a627cb74629566483cdc91f3770a94
-
Include/ExcludeDispatchKeySetGuard API (pytorch#42658)
Summary: Pull Request resolved: pytorch#42658 Test Plan: Imported from OSS Reviewed By: ezyang Differential Revision: D22971426 Pulled By: bhosmer fbshipit-source-id: 4d63e0cb31745e7b662685176ae0126ff04cdece
Commits on Aug 9, 2020
-
Adds 'clip' alias for clamp (pytorch#42770)
Summary: Per title. Also updates our guidance for adding aliases to clarify interned_string and method_test requirements. The alias is tested by extending test_clamp to also test clip. Pull Request resolved: pytorch#42770 Reviewed By: ngimel Differential Revision: D23020655 Pulled By: mruberry fbshipit-source-id: f1d8e751de9ac5f21a4f95d241b193730f07b5dc
Commits on Aug 10, 2020
-
Fix op benchmark (pytorch#42757)
Summary: A benchmark relies on abs_ having a functional variant. Pull Request resolved: pytorch#42757 Reviewed By: ngimel Differential Revision: D23011037 Pulled By: mruberry fbshipit-source-id: c04866015fa259e4c544e5cf0c33ca1e11091d92
-
[ONNX] Fix scalar type cast for comparison ops (pytorch#37787)
Summary: Always promote type casts for comparison operators, regardless if the input is tensor or scalar. Unlike arithmetic operators, where scalars are implicitly cast to the same type as tensors. Pull Request resolved: pytorch#37787 Reviewed By: hl475 Differential Revision: D21440585 Pulled By: houseroad fbshipit-source-id: fb5c78933760f1d1388b921e14d73a2cb982b92f
-
Fix TensorPipe submodule (pytorch#42789)
Summary: Not sure what happened, but possibly I landed a PR on PyTorch which updated the TensorPipe submodule to a commit hash of a *PR* of TensorPipe. Now that the latter PR has been merged though that same commit has a different hash. The commit referenced by PyTorch, therefore, has become orphaned. This is causing some issues. Hence here I am updating the commit, which however does not change a single line of code. Pull Request resolved: pytorch#42789 Reviewed By: houseroad Differential Revision: D23023238 Pulled By: lw fbshipit-source-id: ca2dcf6b7e07ab64fb37e280a3dd7478479f87fd
-
generalize circleci docker build.sh and add centos support (pytorch#4…
…1255) Summary: Add centos Dockerfile and support to circleci docker builds, and allow generic image names to be parsed by build.sh, so both hardcoded images and custom images can be built. Currently only adds a ROCm centos Dockerfile. CC ezyang xw285cornell sunway513 Pull Request resolved: pytorch#41255 Reviewed By: mrshenli Differential Revision: D23003218 Pulled By: malfet fbshipit-source-id: 562c53533e7fb9637dc2e81edb06b2242afff477
-
Add python unittest target to
caffe2/test/TARGETS(pytorch#42766)Summary: Pull Request resolved: pytorch#42766 **Summary** Some python tests are missing in `caffe2/test/TARGETS`, add them to be more comprehension. According to [run_test.py](https://github.com/pytorch/pytorch/blob/master/test/run_test.py#L125), some tests are slower. Slow tests are added as independent targets and others are put together into one `others` target. The reason is because we want to reduce overhead, especially for code covarge collection. Tests in one target can be run as a bundle, and then coverage can be collected together. Typically coverage collection procedure is time-expensive, so this helps us save time. Test Plan: Run all the new test targets locally in dev server and record the time they cost. **Statistics** ``` # jit target real 33m7.694s user 653m1.181s sys 58m14.160s --------- Compare to Initial Jit Target runtime: ---------------- real 32m13.057s user 613m52.843s sys 54m58.678s ``` ``` # others target real 9m2.920s user 164m21.927s sys 12m54.840s ``` ``` # serialization target real 4m21.090s user 23m33.501s sys 1m53.308s ``` ``` # tensorexpr real 11m28.187s user 33m36.420s sys 1m15.925s ``` ``` # type target real 3m36.197s user 51m47.912s sys 4m14.149s ``` Reviewed By: malfet Differential Revision: D22979219 fbshipit-source-id: 12a30839bb76a64871359bc024e4bff670c5ca8b
-
Automated submodule update: FBGEMM (pytorch#42781)
Summary: Pull Request resolved: pytorch#42781 This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM). New submodule commit: pytorch/FBGEMM@fbd813e Pull Request resolved: pytorch#42771 Test Plan: Ensure that CI jobs succeed on GitHub before landing. Reviewed By: dskhudia Differential Revision: D23015890 Pulled By: jspark1105 fbshipit-source-id: f0f62969f8744df96a4e7f5aff2ce95baabb2f76
-
include missing settings import
Summary: from hypothesis import given, settings Test Plan: test_op_nnpi_fp16.py Differential Revision: D23031038 fbshipit-source-id: 751547e6a6e992d8816d4cc2c5a699ba19a97796
-
[ONNX] Add support for scalar src in torch.scatter ONNX export. (pyto…
…rch#42765) Summary: `torch.scatter` supports two overloads – one where `src` input tensor is same size as the `index` tensor input, and second, where `src` is a scalar. Currrently, ONNX exporter only supports the first overload. This PR adds export support for the second overload of `torch.scatter`. Pull Request resolved: pytorch#42765 Reviewed By: hl475 Differential Revision: D23025189 Pulled By: houseroad fbshipit-source-id: 5c2a3f3ce3b2d69661a227df8a8e0ed7c1858dbf
-
.circleci: Only do comparisons when available (pytorch#42816)
Summary: Pull Request resolved: pytorch#42816 Comparisons were being done on branches where the '<< pipeline.git.base_revision >>' didn't exist before so let's just move it so that comparison / code branch is only run when that variable is available Example: https://app.circleci.com/pipelines/github/pytorch/pytorch/198611/workflows/8a316eef-d864-4bb0-863f-1454696b1e8a/jobs/6610393 Signed-off-by: Eli Uriegas <eliuriegas@fb.com> Test Plan: Imported from OSS Reviewed By: ezyang Differential Revision: D23032900 Pulled By: seemethere fbshipit-source-id: 98a49c78b174d6fde9c6b5bd3d86a6058d0658bd
-
DDP communication hook: skip dividing grads by world_size if hook reg…
…istered. (pytorch#42400) Summary: Pull Request resolved: pytorch#42400 mcarilli spotted that in the original DDP communication hook design described in [39272](pytorch#39272), the hooks receive grads that are already predivided by world size. It makes sense to skip the divide completely if hook registered. The hook is meant for the user to completely override DDP communication. For example, if the user would like to implement something like GossipGrad, always dividing by the world_size would not be a good idea. We also included a warning in the register_comm_hook API as: > GradBucket bucket's tensors will not be predivided by world_size. User is responsible to divide by the world_size in case of operations like allreduce. ghstack-source-id: 109548696 **Update:** We discovered and fixed a bug with the sparse tensors case. See new unit test called `test_ddp_comm_hook_sparse_gradients` and changes in `reducer.cpp`. Test Plan: python test/distributed/test_c10d.py and perf benchmark tests. Reviewed By: ezyang Differential Revision: D22883905 fbshipit-source-id: 3277323fe9bd7eb6e638b7ef0535cab1fc72f89e
-
change pt_defs.bzl to python file (pytorch#42725)
Summary: Pull Request resolved: pytorch#42725 This diff changes pt_defs.bzl to pt_defs.py, so that it can be included as python source file. The reason is if we remove base ops, pt_defs.bzl becomes too big (8k lines) and we cannot pass its content to gen_oplist (python library). The easy solution is to change it to a python source file so that it can be used in gen_oplist. Test Plan: sandcastle Reviewed By: ljk53, iseeyuan Differential Revision: D22968258 fbshipit-source-id: d720fe2e684d9a2bf5bd6115b6e6f9b812473f12
-
Fix
torch.nn.functional.grid_samplecrashes ifgridhas NaNs (pyt……orch#42703) Summary: In `clip_coordinates` replace `minimum(maximum(in))` composition with `clamp_max(clamp_min(in))` Swap order of `clamp_min` operands to clamp NaNs in grid to 0 Fixes pytorch#42616 Pull Request resolved: pytorch#42703 Reviewed By: ezyang Differential Revision: D22987447 Pulled By: malfet fbshipit-source-id: a8a2d6de8043d6b77c8707326c5412d0250efae6
-
[vulkan] cat op (concatenate) (pytorch#41434)
Summary: Pull Request resolved: pytorch#41434 Test Plan: Imported from OSS Reviewed By: AshkanAliabadi Differential Revision: D22754941 Pulled By: IvanKobzarev fbshipit-source-id: cd03577e1c2f639b2592d4b7393da4657422e23c
-
-
test_cpp_rpc: Build test_e2e_process_group.cpp only if USE_GLOO is tr…
…ue (pytorch#42836) Summary: Fixes pytorch#42776 Pull Request resolved: pytorch#42836 Reviewed By: seemethere Differential Revision: D23041274 Pulled By: malfet fbshipit-source-id: 8605332701271bea6d9b3a52023f548c11d8916f
Commits on Aug 11, 2020
-
BatchedTensor fallback: extended to support ops with multiple Tensor …
…returns (pytorch#42628) Summary: Pull Request resolved: pytorch#42628 This PR extends the BatchedTensor fallback to support operators with multiple Tensor returns. If an operator has multiple returns, we stack shards of each return to create the full outputs. Test Plan: - `pytest test/test_vmap.py -v`. Added a new test for an operator with multiple returns (torch.var_mean). Reviewed By: izdeby Differential Revision: D22957095 Pulled By: zou3519 fbshipit-source-id: 5c0ec3bf51283cc4493b432bcfed1acf5509e662
-
Rename some BatchedTensorImpl APIs (pytorch#42700)
Summary: Pull Request resolved: pytorch#42700 I was about to use `isBatched` somewhere not in the files used to implement vmap but then realized how silly that sounds due to ambiguity. This PR renames some of the BatchedTensor APIs to make a bit more sense to onlookers. - isBatched(Tensor) -> isBatchedTensor(Tensor) - unsafeGetBatched(Tensor) -> unsafeGetBatchedImpl(Tensor) - maybeGetBatched(Tensor) -> maybeGetBatchedImpl(Tensor) Test Plan: - build Pytorch, run tests. Reviewed By: ezyang Differential Revision: D22985868 Pulled By: zou3519 fbshipit-source-id: b8ed9925aabffe98085bcf5c81d22cd1da026f46
-
Skip test_c10d.ProcessGroupNCCLTest under TSAN (pytorch#42750)
Summary: Pull Request resolved: pytorch#42750 All of these tests fail under TSAN since we fork in a multithreaded environment. ghstack-source-id: 109566396 Test Plan: CI Reviewed By: pritamdamania87 Differential Revision: D23007746 fbshipit-source-id: 65571607522b790280363882d61bfac8a52007a1
-
[c10d] Template computeLengthsAndOffsets() (pytorch#42706)
Summary: Pull Request resolved: pytorch#42706 Different backends accept different type of length to, like MPI_Alltoallv, nccSend/Recv(), gloo::alltoallv(). So to make computeLengthsAndOffsets() template Test Plan: Sandcastle CI HPC: ./trainer_cmd.sh -p 16 -n 8 -d nccl Reviewed By: osalpekar Differential Revision: D22961459 fbshipit-source-id: 45ec271f8271b96f2dba76cd9dce3e678bcfb625
-
adaptive_avg_pool[23]d: check output_size.size() (pytorch#42831)
Summary: Return an error if output_size is unexpected Fixes pytorch#42578 Pull Request resolved: pytorch#42831 Reviewed By: ezyang Differential Revision: D23039295 Pulled By: malfet fbshipit-source-id: d14a5e6dccdf785756635caee2c87151c9634872
-
Fix "non-negative integer" error messages (pytorch#42734)
Summary: Fixes pytorch#42662 Use "positive integer" error message for consistency with: https://github.com/pytorch/pytorch/blob/17f76f9a7896eccdfdba5fd22fd3a24002b0d917/torch/optim/lr_scheduler.py#L958-L959 https://github.com/pytorch/pytorch/blob/ad7133d3c11a35a7aedf9786ccf8d7a52939b753/torch/utils/data/sampler.py#L102-L104 Pull Request resolved: pytorch#42734 Reviewed By: zdevito Differential Revision: D23039575 Pulled By: smessmer fbshipit-source-id: 1be1e0caa868891540ecdbe6f471a6cd51c40ede
-
add net transforms for fusion (pytorch#42763)
Summary: Pull Request resolved: pytorch#42763 add the fp16 fusions as net transforms: -layernorm fused with mul+add -swish int8 Test Plan: added unit test, ran flows Reviewed By: yinghai Differential Revision: D23002043 fbshipit-source-id: f0b13d51d68c240b05d2a237a7fb8273e996328b
-
Fix ROCm CI by increasing test timeout (pytorch#42827)
Summary: ROCm is failing to run this test in the allotted time. See, for example, https://app.circleci.com/pipelines/github/pytorch/pytorch/198759/workflows/f6066acf-b289-46c5-aad0-6f4f663ce820/jobs/6618625. cc jeffdaily Pull Request resolved: pytorch#42827 Reviewed By: pbelevich Differential Revision: D23042220 Pulled By: mruberry fbshipit-source-id: 52b426b0733b7b52ac3b311466d5000334864a82
-
[quant] Sorting the list of dispathes (pytorch#42758)
Summary: Pull Request resolved: pytorch#42758 Test Plan: Imported from OSS Reviewed By: vkuzo Differential Revision: D23011764 Pulled By: z-a-f fbshipit-source-id: df87acdcf77ae8961a109eaba20521bc4f27ad0e
-
Revert D23002043: add net transforms for fusion
Test Plan: revert-hammer Differential Revision: D23002043 (pytorch@a4b763b) Original commit changeset: f0b13d51d68c fbshipit-source-id: d43602743af35db825e951358992e979283a26f6
-
Don't materialize output grads (pytorch#41821)
Summary: Added a new option in AutogradContext to tell autograd to not materialize output grad tensors, that is, don't expand undefined/None tensors into tensors full of zeros before passing them as input to the backward function. This PR is the second part that closes pytorch#41359. The first PR is pytorch#41490. Pull Request resolved: pytorch#41821 Reviewed By: albanD Differential Revision: D22693163 Pulled By: heitorschueroff fbshipit-source-id: a8d060405a17ab1280a8506a06a2bbd85cb86461
-
vmap: temporarily disable support for random functions (pytorch#42617)
Summary: Pull Request resolved: pytorch#42617 While we figure out the random plan, I want to initially disable support for random operations. This is because there is an ambiguity in what randomness means. For example, ``` tensor = torch.zeros(B0, 1) vmap(lambda t: t.normal_())(tensor) ``` in the above example, should tensor[0] and tensor[1] be equal (i.e., use the same random seed), or should they be different? The mechanism for disabling random support is as follows: - We add a new dispatch key called VmapMode - Whenever we're inside vmap, we enable VmapMode for all tensors. This is done via at::VmapMode::increment_nesting and at::VmapMode::decrement_nesting. - DispatchKey::VmapMode's fallback kernel is the fallthrough kernel. - We register kernels that raise errors for all random functions on DispatchKey::VmapMode. This way, whenever someone calls a random function on any tensor (not just BatchedTensors) inside of a vmap block, an error gets thrown. Test Plan: - pytest test/test_vmap.py -v -k "Operators" Reviewed By: ezyang Differential Revision: D22954840 Pulled By: zou3519 fbshipit-source-id: cb8d71062d4087e10cbf408f74b1a9dff81a226d
-
Added torch::cuda::manual_seed(_all) to mirror torch.cuda.manual_seed…
…(_all) (pytorch#42638) Summary: Pull Request resolved: pytorch#42638 Test Plan: Imported from OSS Reviewed By: glaringlee Differential Revision: D23030317 Pulled By: heitorschueroff fbshipit-source-id: b0d7bdf0bc592a913ae5b1ffc14c3a5067478ce3
-
Raise error if
at::native::embeddingis given 0-D weight (pytorch#4……2550) Summary: Previously, `at::native::embedding` implicitly assumed that the `weight` argument would be 1-D or greater. Given a 0-D tensor, it would segfault. This change makes it throw a RuntimeError instead. Fixes pytorch#41780 Pull Request resolved: pytorch#42550 Reviewed By: smessmer Differential Revision: D23040744 Pulled By: albanD fbshipit-source-id: d3d315850a5ee2d2b6fcc0bdb30db2b76ffffb01
-
Optimization with Backward Implementation of Learnable Fake Quantize …
…Per Channel Kernel (CPU and GPU) (pytorch#42810) Summary: Pull Request resolved: pytorch#42810 In this diff, the original backward pass implementation is sped up by merging the 3 iterations computing dX, dScale, and dZeroPoint separately. In this case, a native loop is directly used on a byte-wise level (referenced by `strides`). In addition, vectorization is used such that scale and zero point are expanded to share the same shape and the element-wise corresponding values to X along the channel axis. In the benchmark test on the operators, for an input of shape `3x3x256x256`, we have observed the following improvement in performance: **Speedup from python operator**: ~10x **Speedup from original learnable kernel**: ~5.4x **Speedup from non-backprop kernel**: ~1.8x Test Plan: To assert correctness of the new kernel, on a devvm, enter the command `buck test //caffe2/test:quantization -- learnable_backward_per_channel` To benchmark the operators, on a devvm, enter the command 1. Set the kernel size to 3x3x256x256 or a reasonable input size. 2. Run `buck test //caffe2/benchmarks/operator_benchmark/pt:quantization_test` 3. The relevant outputs for CPU are as follows: ``` # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cpu_op_typepy_module # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: py_module Backward Execution Time (us) : 989024.686 # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cpu_op_typelearnable_kernel # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: learnable_kernel Backward Execution Time (us) : 95654.079 # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cpu_op_typeoriginal_kernel # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: original_kernel Backward Execution Time (us) : 176948.970 ``` 4. The relevant outputs for GPU are as follows: The relevant outputs are as follows **Pre-optimization**: ``` # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typepy_module # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: py_module Backward Execution Time (us) : 6795.173 # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typelearnable_kernel # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: learnable_kernel Backward Execution Time (us) : 4321.351 # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typeoriginal_kernel # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: original_kernel Backward Execution Time (us) : 1052.066 ``` **Post-optimization**: ``` # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typepy_module # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: py_module Backward Execution Time (us) : 6737.106 # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typelearnable_kernel # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: learnable_kernel Backward Execution Time (us) : 2112.484 # Benchmarking PyTorch: FakeQuantizePerChannelOpBenchmark # Mode: Eager # Name: FakeQuantizePerChannelOpBenchmark_N3_C3_H256_W256_cuda_op_typeoriginal_kernel # Input: N: 3, C: 3, H: 256, W: 256, device: cpu, op_type: original_kernel Backward Execution Time (us) : 1078.79 Reviewed By: vkuzo Differential Revision: D22946853 fbshipit-source-id: 1a01284641480282b3f57907cc7908d68c68decd
-
[JIT] Fix typing.Final for python 3.8 (pytorch#39568)
Summary: fixes pytorch#39566 `typing.Final` is a thing since python 3.8, and on python 3.8, `typing_extensions.Final` is an alias of `typing.Final`, therefore, `ann.__module__ == 'typing_extensions'` will become False when using 3.8 and `typing_extensions` is installed. ~~I don't know why the test is skipped, seems like due to historical reason when python 2.7 was still a thing?~~ Edit: I know now, the `Final` for `<3.7` don't have `__origin__` Pull Request resolved: pytorch#39568 Reviewed By: smessmer Differential Revision: D23043388 Pulled By: malfet fbshipit-source-id: cc87a9e4e38090d784e9cea630e1c543897a1697
-
Fix a typo in EmbeddingBag.cu (pytorch#42742)
Summary: Pull Request resolved: pytorch#42742 Reviewed By: smessmer Differential Revision: D23011029 Pulled By: mrshenli fbshipit-source-id: 615f8b876ef1881660af71b6e145fb4ca97d2ebb
-
Update the documentation for scatter to include streams parameter. (p…
…ytorch#42814) Summary: Fixes pytorch#41827 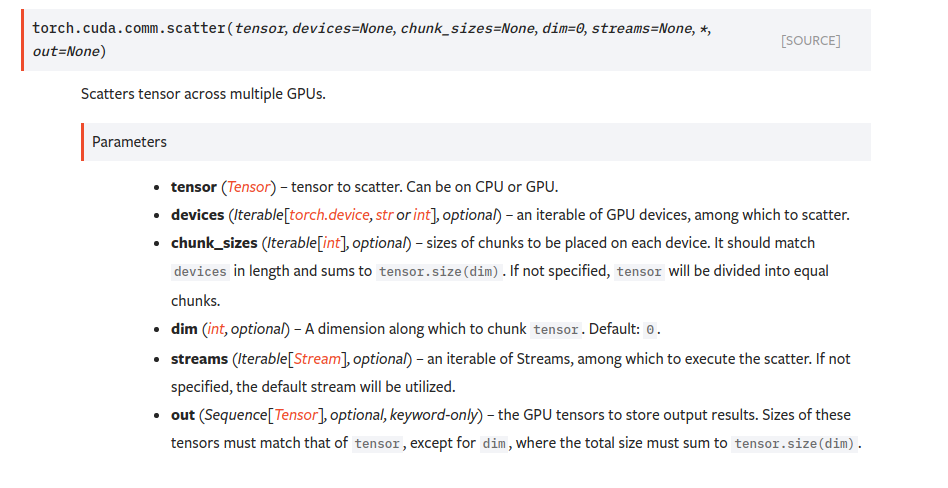 Current: https://pytorch.org/docs/stable/cuda.html#communication-collectives Pull Request resolved: pytorch#42814 Reviewed By: smessmer Differential Revision: D23033544 Pulled By: mrshenli fbshipit-source-id: 88747fbb06e88ef9630c042ea9af07dafd422296
-
Modify clang code coverage to CMakeList.txt (for MacOS) (pytorch#42837)
Summary: Pull Request resolved: pytorch#42837 Originally we use ``` list(APPEND CMAKE_C_FLAGS -fprofile-instr-generate -fcoverage-mapping) list(APPEND CMAKE_CXX_FLAGS -fprofile-instr-generate -fcoverage-mapping) ``` But when compile project on mac with Coverage On, it has the error: `clang: error: no input files /bin/sh: -fprofile-instr-generate: command not found /bin/sh: -fcoverage-mapping: command not found` The reason behind it, is `list(APPEND CMAKE_CXX_FLAGS` will add an additional `;` to the variable. This means, if we do `list(APPEND foo a)` and then `list(APPEND foo b)`, then `foo` will be `a;b` -- with the additional `;`. Since we have `CMAKE_CXX_FLAGS` defined before in the `CMakeList.txt`, we can only use `set(...)` here After changing it to ``` set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fprofile-instr-generate -fcoverage-mapping") set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fprofile-instr-generate -fcoverage-mapping") ``` Test successufully in local mac machine. Test Plan: Test locally on mac machine Reviewed By: malfet Differential Revision: D23043057 fbshipit-source-id: ff6f4891b35b7f005861ee2f8e4c550c997fe961
-
Introduce experimental FX library (pytorch#42741)
Summary: Pull Request resolved: pytorch#42741 Test Plan: Imported from OSS Reviewed By: dzhulgakov Differential Revision: D23006383 Pulled By: jamesr66a fbshipit-source-id: 6cb6d921981fcae47a07df581ffcf900fb8a7fe8
-
-
Fix orgqr input size conditions (pytorch#42825)
Summary: * Adds support for `n > k` * Throw error if `m >= n >= k` is not true * Updates existing error messages to match argument names shown in public docs * Adds error tests Fixes pytorch#41776 Pull Request resolved: pytorch#42825 Reviewed By: smessmer Differential Revision: D23038916 Pulled By: albanD fbshipit-source-id: e9bec7b11557505e10e0568599d0a6cb7e12ab46
-
align qconv benchmark to conv benchmark (pytorch#42761)
Summary: Pull Request resolved: pytorch#42761 Makes the qconv benchmark follow the conv benchmark exactly. This way it will be easy to compare q vs fp with the same settings. Test Plan: ``` cd benchmarks/operator_benchmark python -m pt.qconv_test python -m pt.conv_test ``` Imported from OSS Reviewed By: jerryzh168 Differential Revision: D23012533 fbshipit-source-id: af30ee585389395569a6322f5210828432963077
-
align qlinear benchmark to linear benchmark (pytorch#42767)
Summary: Pull Request resolved: pytorch#42767 Same as previous PR, forcing the qlinear benchmark to follow the fp one Test Plan: ``` cd benchmarks/operator_benchmark python -m pt.linear_test python -m pt.qlinear_test ``` Imported from OSS Reviewed By: jerryzh168 Differential Revision: D23013937 fbshipit-source-id: fffaa7cfbfb63cea41883fd4d70cd3f08120aaf8
-
[NNC] Registerizer for GPU [1/x] (pytorch#42606)
Summary: Adds a new optimization pass, the Registerizer, which looks for common Stores and Loads to a single item in a buffer and replaces them with a local temporary scalar which is cheaper to write. For example it can replace: ``` A[0] = 0; for (int x = 0; x < 10; x++) { A[0] = (A[0]) + x; } ``` with: ``` int A_ = 0; for (int x = 0; x < 10; x++) { A_ = x + A_; } A[0] = A_; ``` This is particularly useful on GPUs when parallelizing, since after replacing loops with metavars we have a lot of accesses like this. Early tests of simple reductions on a V100 indicates this can speed them up by ~5x. This diff got a bit unwieldy with the integration code so that will come in a follow up. Pull Request resolved: pytorch#42606 Reviewed By: bertmaher Differential Revision: D22970969 Pulled By: nickgg fbshipit-source-id: 831fd213f486968624b9a4899a331ea9aeb40180 -
Adds list of operator-related information for testing (pytorch#41662)
Summary: This PR adds: - an "OpInfo" class in common_method_invocations that can contain useful information about an operator, like what dtypes it supports - a more specialized "UnaryUfuncInfo" class designed to help test the unary ufuncs - the `ops` decorator, which can generate test variants from lists of OpInfos - test_unary_ufuncs.py, a new test suite stub that shows how the `ops` decorator and operator information can be used to improve the thoroughness of our testing The single test in test_unary_ufuncs.py simply ensures that the dtypes associated with a unary ufunc operator in its OpInfo entry are correct. Writing a test like this previously, however, would have required manually constructing test-specific operator information and writing a custom test generator. The `ops` decorator and a common place to put operator information make writing tests like this easier and allows what would have been test-specific information to be reused. The `ops` decorator extends and composes with the existing device generic test framework, allowing its decorators to be reused. For example, the `onlyOnCPUAndCUDA` decorator works with the new `ops` decorator. This should keep the tests readable and consistent. Future PRs will likely: - continue refactoring the too large test_torch.py into more verticals (unary ufuncs, binary ufuncs, reductions...) - add more operator information to common_method_invocations.py - refactor tests for unary ufuncs into test_unary_ufunc Examples of possible future extensions are [here](pytorch@616747e), where an example unary ufunc test is added, and [here](pytorch@d0b624f), where example autograd tests are added. Both tests leverage the operator info in common_method_invocations to simplify testing. Pull Request resolved: pytorch#41662 Reviewed By: ngimel Differential Revision: D23048416 Pulled By: mruberry fbshipit-source-id: ecce279ac8767f742150d45854404921a6855f2c
-
Correct the type of some floating point literals in calc_digamma (pyt…
…orch#42846) Summary: They are double, but they are supposed to be of accscalar_t or a faster type. Pull Request resolved: pytorch#42846 Reviewed By: zou3519 Differential Revision: D23049405 Pulled By: mruberry fbshipit-source-id: 29bb5d5419dc7556b02768f0ff96dfc28676f257
-
Initial quantile operator implementation (pytorch#42755)
Summary: Pull Request resolved: pytorch#42755 Attempting to land quantile again after being landed here pytorch#39417 and reverted here pytorch#41616. Test Plan: Imported from OSS Reviewed By: mruberry Differential Revision: D23030338 Pulled By: heitorschueroff fbshipit-source-id: 124a86eea3aee1fdaa0aad718b04863935be26c7
-
Ensure IDEEP transpose operator works correctly
Summary: I found out that without exporting to public format IDEEP transpose operator in the middle of convolution net produces incorrect results (probably reading some out-of-bound memory). Exporting to public format might not be the most efficient solution, but at least it ensures correct behavior. Test Plan: Running ConvFusion followed by transpose should give identical results on CPU and IDEEP Reviewed By: bwasti Differential Revision: D22970872 fbshipit-source-id: 1ddca16233e3d7d35a367c93e72d70632d28e1ef
-
Add nn.functional.adaptive_avg_pool size empty tests (pytorch#42857)
Summary: Pull Request resolved: pytorch#42857 Reviewed By: seemethere Differential Revision: D23053677 Pulled By: malfet fbshipit-source-id: b3d0d517cddc96796461332150e74ae94aac8090
-
Export BatchBucketOneHot Caffe2 Operator to PyTorch
Summary: As titled. Test Plan: ``` buck test caffe2/caffe2/python/operator_test:torch_integration_test -- test_batch_bucket_one_hot_op ``` Reviewed By: yf225 Differential Revision: D23005981 fbshipit-source-id: 1daa8d3e7d6ad75e97e94964db95ccfb58541672
-
Fix incorrect aten::sorted.str return type (pytorch#42853)
Summary: aten::sorted.str output type was incorrectly set to bool[] due to a copy-paste error. This PR fixes it. Fixes https://fburl.com/0rv8amz7 Pull Request resolved: pytorch#42853 Reviewed By: yf225 Differential Revision: D23054907 Pulled By: gmagogsfm fbshipit-source-id: a62968c90f0301d4a5546e6262cb9315401a9729
-
Summary: Pull Request resolved: pytorch#42866 Test Plan: Imported from OSS Reviewed By: zdevito Differential Revision: D23056813 Pulled By: jamesr66a fbshipit-source-id: d30cdffe6f0465223354dec00f15658eb0b08363
-
remove deadline enforcement for hypothesis (pytorch#42871)
Summary: Pull Request resolved: pytorch#42871 old version of hypothesis.testing was not enforcing deadlines after the library got updated, default deadline=200ms, but even with 1s or more, tests are flaky. Changing deadline to non-enforced which is the same behavior as the old version Test Plan: tested fakelowp/tests Reviewed By: hl475 Differential Revision: D23059033 fbshipit-source-id: 79b6aec39a2714ca5d62420c15ca9c2c1e7a8883
-
format for readability (pytorch#42851)
Summary: Pull Request resolved: pytorch#42851 Test Plan: Imported from OSS Reviewed By: smessmer Differential Revision: D23048382 Pulled By: bhosmer fbshipit-source-id: 55d84d5f9c69be089056bf3e3734c1b1581dc127
-
[hypothesis] Deadline followup (pytorch#42842)
Summary: Pull Request resolved: pytorch#42842 Test Plan: `buck test` Reviewed By: thatch Differential Revision: D23045269 fbshipit-source-id: 8a3f4981869287a0f5fb3f0009e13548b7478086
{kind=link}
Commits on Aug 12, 2020
-
Collect more data in collect_env (pytorch#42887)
Summary: Collect Python runtime bitness (32 vs 64 bit) Collect Mac/Linux OS machine time (x86_64, arm, Power, etc) Collect Clang version Pull Request resolved: pytorch#42887 Reviewed By: seemethere Differential Revision: D23064788 Pulled By: malfet fbshipit-source-id: df361bdbb79364dc521b8e1ecbed1b4bd08f9742
-
Fix manual seed to unpack unsigned long (pytorch#42206)
Summary: `torch.manual_seed` was unpacking its argument as an `int64_t`. This fix changes it to a `uint64_t`. Fixes pytorch#33546 Pull Request resolved: pytorch#42206 Reviewed By: ezyang Differential Revision: D22822098 Pulled By: albanD fbshipit-source-id: 97c978139c5cb2d5b62cc2c963550c758ee994f7
-
[quant] Reduce number of variants of add/mul (pytorch#42769)
Summary: Pull Request resolved: pytorch#42769 Some of the quantized add and mul can have the same name Test Plan: Imported from OSS Reviewed By: supriyar Differential Revision: D23054822 fbshipit-source-id: c1300f3f0f046eaf0cf767d03b957835e22cfb4b
-
[Resending] [ONNX] Add eliminate_unused_items pass (pytorch#42743)
Summary: This PR: - Adds eliminate_unused_items pass that removes unused inputs and initializers. - Fixes run_embed_params function so it doesn't export unnecessary parameters. - Removes test_modifying_params in test_verify since it's no longer needed. Pull Request resolved: pytorch#42743 Reviewed By: hl475 Differential Revision: D23058954 Pulled By: houseroad fbshipit-source-id: cd1e81463285a0bf4e60766c8c87fc9a350d9c7e
-
[quant] Attach qconfig to all modules (pytorch#42576)
Summary: Pull Request resolved: pytorch#42576 Previously we have qconfig propagate list and we only attach qconfig for modules in the list, this works when everything is quantized in the form of module. but now we are expanding quantization for functional/torch ops, we'll need to attach qconfig to all modules Test Plan: Imported from OSS Reviewed By: vkuzo Differential Revision: D22939453 fbshipit-source-id: 7d6a1f73ff9bfe461b3afc75aa266fcc8f7db517
-
Support boolean key in dictionary (pytorch#42833)
Summary: Fixes pytorch#41449 . Pull Request resolved: pytorch#42833 Test Plan: `python test/test_jit.py TestDict` Reviewed By: zou3519 Differential Revision: D23056250 Pulled By: asuhan fbshipit-source-id: 90dabe1490c99d3e57a742140a4a2b805f325c12
-
Adds linalg.det alias, fixes outer alias, updates alias testing (pyto…
…rch#42802) Summary: This PR: - updates test_op_normalization.py, which verifies that aliases are correctly translated in the JIT - adds torch.linalg.det as an alias for torch.det - moves the torch.linalg.outer alias to torch.outer (to be consistent with NumPy) The torch.linalg.outer alias was put the linalg namespace erroneously as a placeholder since it's a "linear algebra op" according to NumPy but is actually still in the main NumPy namespace. The updates to test_op_normalization are necessary. Previously it was using method_tests to generate tests, and method_tests assumes test suites using it also use the device generic framework, which test_op_normalization did not. For example, some ops require decorators like `skipCPUIfNoLapack`, which only works in device generic test classes. Moving test_op_normalization to the device generic framework also lets these tests run on CPU and CUDA. Continued reliance on method_tests() is excessive since the test suite is only interested in testing aliasing, and a simpler and more readable `AliasInfo` class is used for the required information. An example impedance mismatch between method_tests and the new tests, for example, was how to handle ops in namespaces like torch.linalg.det. In the future this information will likely be folded into a common 'OpInfo' registry in the test suite. The actual tests performed are similar to what they were previously: a scripted and traced version of the op is run and the test verifies that both graphs do not contain the alias name and do contain the aliased name. The guidance for adding an alias has been updated accordingly. cc mattip Note: ngimel suggests: - deprecating and then removing the `torch.ger` name - reviewing the implementation of `torch.outer` Pull Request resolved: pytorch#42802 Reviewed By: zou3519 Differential Revision: D23059883 Pulled By: mruberry fbshipit-source-id: 11321c2a7fb283a6e7c0d8899849ad7476be42d1
-
avoid redundant isCustomClassRegistered() checks (pytorch#42852)
Summary: Pull Request resolved: pytorch#42852 Test Plan: Imported from OSS Reviewed By: smessmer Differential Revision: D23048381 Pulled By: bhosmer fbshipit-source-id: 40b71670a84cb6f7e5a03279f58ce227d676aa03
-
Add
torch.nansum(pytorch#38628)Summary: Reference: pytorch#38349 Pull Request resolved: pytorch#38628 Reviewed By: VitalyFedyunin Differential Revision: D22860549 Pulled By: mruberry fbshipit-source-id: 87fcbfd096d83fc14b3b5622f2301073729ce710
-
Update to NNP-I v1.0.0.5 (pytorch#4770)
Summary: Align code to NNP-I v1.0.0.5 (glow tracing changes). Pull Request resolved: pytorch/glow#4770 Reviewed By: arunm-git Differential Revision: D22927904 Pulled By: hl475 fbshipit-source-id: 3746a6b07f3fcffc662d80a95513427cfccac7a5
-
Remove excessive logging in plan_executor (pytorch#42888)
Summary: Pull Request resolved: pytorch#42888 as title Test Plan: flow-cli test-locally dper.workflows.evaluation.eval_workflow --parameters-file /mnt/public/ehsanardestani/temp/quant_eval_inputs_all.json Reviewed By: amylittleyang Differential Revision: D23066529 fbshipit-source-id: f925afd1734e617e412b0f171e16c781d13272d9
-
Fix freeze_module pass for sharedtype (pytorch#42457)
Summary: During cleanup phase, calling recordReferencedAttrs would record the attributes which are referenced and hence kept. However, if you have two instances of the same type which are preserved through freezing process, as the added testcase shows, then during recording the attributes which are referenced, we iterate through the type INSTANCES that we have seen so far and record those ones. Thus if we have another instance of the same type, we will just look at the first instance in the list, and record that instances. This PR fixes that by traversing the getattr chains and getting the actual instance of the getattr output. Pull Request resolved: pytorch#42457 Test Plan: python test/test_jit.py TestFreezing Fixes #{issue number} Reviewed By: zou3519 Differential Revision: D22898051 Pulled By: kimishpatel fbshipit-source-id: 8b1d80f0eb40ab99244f931d4a1fdb28290a4683
-
MAINT: speed up istft by using col2im (the original python code used … (
pytorch#42826) Summary: Fixes pytorch#42213 The [original python code](https://github.com/pytorch/audio/blob/v0.5.0/torchaudio/functional.py#L178) from `torchaudio` was converted to a native function, but used `eye` to allocate a Tensor and was much slower. Using `at::col2im` (which is the equivalent of `torch.nn.functional.fold`) solved the slowdown. Pull Request resolved: pytorch#42826 Reviewed By: smessmer Differential Revision: D23043673 Pulled By: mthrok fbshipit-source-id: 3f5d0779a87379b002340ea19c9ae5042a43e94e
-
Fix coding style and safety issues in CuBLAS nondeterministic unit te…
…st (pytorch#42627) Summary: Addresses some comments that were left unaddressed after PR pytorch#41377 was merged: * Use `check_output` instead of `Popen` to run each subprocess sequentially * Use f-strings rather than old python format string style * Provide environment variables to subprocess through the `env` kwarg * Check for correct error behavior inside the subprocess, and raise another error if incorrect. Then the main process fails the test if any error is raised Pull Request resolved: pytorch#42627 Reviewed By: malfet Differential Revision: D22969231 Pulled By: ezyang fbshipit-source-id: 38d5f3f0d641c1590a93541a5e14d90c2e20acec
-
Use
C10_API_ENUMto fix invalid attribute warnings (pytorch#42464)Summary: Using the macro added in pytorch#38988 to fix more attribute warnings. Pull Request resolved: pytorch#42464 Reviewed By: malfet Differential Revision: D22916943 Pulled By: ezyang fbshipit-source-id: ab9ca8755cd8b89aaf7f8718b4107b4b94d95005
-
Follow-up for pytorch#37091. (pytorch#42806)
Summary: This is a follow-up PR for pytorch#37091, fixing some of the quirks of that PR as that one was landed early to avoid merge conflicts. This PR addresses the following action items: - [x] Use error-handling macros instead of a `try`-`catch`. - [x] Renamed and added comments to clarify the use of `HANDLED_FUNCTIONS_WRAPPERS` in tests. `HANDLED_FUNCTIONS_NAMESPACES` was already removed in the last PR as we had a way to test for methods. This PR does NOT address the following action item, as it proved to be difficult: - [ ] Define `__module__` for whole API. Single-line repro-er for why this is hard: ```python >>> torch.Tensor.grad.__get__.__module__ = "torch.Tensor.grad" Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'method-wrapper' object has no attribute '__module__' ``` Explanation: Methods defined in C/properties don't always have a `__dict__` attribute or a mutable `__module__` slot for us to modify. The documentation action items were addressed in the following commit, with the additional future task of adding the rendered RFCs to the documentation: pytorch/rfcs@552ba37 Pull Request resolved: pytorch#42806 Reviewed By: smessmer Differential Revision: D23031501 Pulled By: ezyang fbshipit-source-id: b781c97f7840b8838ede50a0017b4327f96bc98a
-
Optimize LayerNorm performance on CPU both forward and backward (pyto…
…rch#35750) Summary: This PR aims at improving `LayerNorm` performance on CPU for both forward and backward. Results on Xeon 6248: 1. single socket inference **1.14x** improvement 2. single core inference **1.77x** improvement 3. single socket training **6.27x** improvement The fine tuning of GPT2 on WikiTest2 dataset time per iteration on dual socket reduced from **4.69s/it** to **3.16s/it**, **1.48x** improvement. Pull Request resolved: pytorch#35750 Reviewed By: zhangguanheng66 Differential Revision: D20810026 Pulled By: glaringlee fbshipit-source-id: c5801bd76eb944f2e46c2fe4991d9ad4f40495c3
-
Summary: Pull Request resolved: pytorch#42691 fix quantization of FC bias to match nnpi quantize biases to fp16 Test Plan: improved the unit test to have input tensors in fp32 Reviewed By: tracelogfb Differential Revision: D22941521 fbshipit-source-id: 00afb70610f8a149110344d52595c39e3fc988ab
-
Fix get_writable_path (pytorch#42895)
Summary: As name suggests, this function should always return a writable path Call `mkdtemp` to create temp folder if path is not writable This fixes `TestNN.test_conv_backcompat` if PyTorch is installed in non-writable location Fixes #{issue number} Pull Request resolved: pytorch#42895 Reviewed By: dzhulgakov Differential Revision: D23070320 Pulled By: malfet fbshipit-source-id: ed6a681d46346696a0de7e71f0b21cba852a964e -
Improve calling backward() and grad() inside vmap error messages (pyt…
…orch#42876) Summary: Pull Request resolved: pytorch#42876 Previously, the error messages were pretty bad. This PR adds nice error messages for the following cases: - user attempts to call .backward() inside vmap for any reason whatsoever - user attempts to call autograd.grad(outputs, inputs, grad_outputs), where outputs or inputs is being vmapped over (so they are BatchedTensors). The case we do support is calling autograd.grad(outputs, inputs, grad_outputs) where `grad_outputs` is being vmapped over. This is the case for batched gradient support (e.g., user passes in a batched grad_output). Test Plan: - new tests: `pytest test/test_vmap.py -v` Reviewed By: ezyang Differential Revision: D23059836 Pulled By: zou3519 fbshipit-source-id: 2fd4e3fd93f558e67e2f0941b18f0d00d8ab439f
-
Revert D22898051: [pytorch][PR] Fix freeze_module pass for sharedtype
Test Plan: revert-hammer Differential Revision: D22898051 (pytorch@4665f3f) Original commit changeset: 8b1d80f0eb40 fbshipit-source-id: 4dc0ba274282a157509db16df13269eed6cd5be9
-
Use
string(APPEND FOO " bar")instead of `set(FOO "${FOO} bar") (py……torch#42844) Summary: Pull Request resolved: pytorch#42844 Reviewed By: scintiller Differential Revision: D23067577 Pulled By: malfet fbshipit-source-id: e4380ce02fd6aca37c955a7bc24435222c5d8b19
-
[pytorch] BUCK build for Vulkan backend
Summary: Introducing `//xplat/caffe2:aten_vulkan` target which contains pytorch Vulkan backend and its ops. `//xplat/caffe2:aten_vulkan` depends on ` //xplat/caffe2:aten_cpu` Just inclusion it to linking registers Vulkan Backend and its ops. **Code generation:** 1. `VulkanType.h`, `VulkanType.cpp` Tensor Types for Vulkan backend are generated by `//xplat/caffe2:gen_aten_vulkan` which runs aten code generation (`aten/src/ATen/gen.py`) with `--vulkan` argument. 2. Shaders compilation `//xplat/caffe2:gen_aten_vulkan_spv` genrule runs `//xplat/caffe2:gen_aten_vulkan_spv_bin` which is a wrapper on `aten/src/ATen/native/vulkan/gen_spv.py` GLSL files are listed in `aten/src/ATen/native/vulkan/glsl/*` and to compile them `glslc` (glsl compiler) is required. `glslc` is in opensource https://github.com/google/shaderc , that also has a few dependencies on other libraries, that porting this build to BUCK will take significant amount of time. To use `glslc` in BUCK introducing dotslash `xplat/caffe2/fb/vulkan/dotslash/glslc` which is stored on manifold the latest prebuilt binaries of `glslc` from ANDROID_NDK for linux, macos and windows. Not using it from ANDROID_NDK directly allows to update it without dependency on ndk. Test Plan: Building aten_vulkan target: ``` buck build //xplat/caffe2:aten_vulkan ``` Building vulkan_test that contains vulkan unittests for android: ``` buck build //xplat/caffe2:pt_vulkan_test_binAndroid#android-armv7 ``` And running it on the device with vulkan support. Reviewed By: iseeyuan Differential Revision: D22770299 fbshipit-source-id: 843af8df226d4b5395b8e480eb47b233d57201df
-
-
-
[jit] Scaffold a static runtime (pytorch#42753)
Summary: The premise of this approach is that a small subset of neural networks are well represented by a data flow graph. The README contains more information. The name is subject to change, but I thought it was a cute reference to fire. suo let me know if you'd prefer this in a different spot. Since it lowers a JIT'd module directly I assumed the JIT folder would be appropriate. There is no exposed Python interface yet (but is mocked up in `test_accelerant.py`) Pull Request resolved: pytorch#42753 Reviewed By: zou3519 Differential Revision: D23043771 Pulled By: bwasti fbshipit-source-id: 5353731e3aae31c08b5b49820815da98113eb551
-
CUDA reduction: allow outputs to have different strides (pytorch#42649)
Summary: Fixes pytorch#42364 Benchmark: https://github.com/zasdfgbnm/things/blob/master/2020Q3/min-benchmark.ipynb ```python import torch print(torch.__version__) print() for i in range(100): torch.randn(1000, device='cuda') for e in range(7, 15): N = 2 ** e input_ = torch.randn(N, N, device='cuda') torch.cuda.synchronize() %timeit input_.min(dim=0); torch.cuda.synchronize() input_ = torch.randn(N, N, device='cuda').t() torch.cuda.synchronize() %timeit input_.min(dim=0); torch.cuda.synchronize() print() ``` Before ``` 1.7.0a0+5d7c3f9 21.7 µs ± 1.67 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) 20.6 µs ± 773 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 22.5 µs ± 294 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 20.2 µs ± 250 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 26.4 µs ± 67 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 20.9 µs ± 316 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 33 µs ± 474 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 21.1 µs ± 218 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 84.2 µs ± 691 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 50.3 µs ± 105 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 181 µs ± 2.36 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) 145 µs ± 149 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 542 µs ± 753 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each) 528 µs ± 10.1 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) 2.04 ms ± 9.74 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) 2.01 ms ± 22.4 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) ``` After ``` 1.7.0a0+9911817 21.4 µs ± 695 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 20.6 µs ± 989 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 22.4 µs ± 153 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 20.5 µs ± 58.4 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 26.6 µs ± 147 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 20.9 µs ± 675 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 35.4 µs ± 560 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 21.7 µs ± 1.17 µs per loop (mean ± std. dev. of 7 runs, 100000 loops each) 86.5 µs ± 1.99 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) 52.2 µs ± 1.57 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) 195 µs ± 2.97 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) 153 µs ± 4.46 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) 550 µs ± 7.72 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) 527 µs ± 3.04 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) 2.05 ms ± 7.87 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) 2 ms ± 4.93 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) ``` Pull Request resolved: pytorch#42649 Reviewed By: ezyang Differential Revision: D22994446 Pulled By: ngimel fbshipit-source-id: cc60beebad2e04c26ebf3ca702a6cb05846522c9
-
Implemented non-named version of unflatten (pytorch#42563)
Summary: Pull Request resolved: pytorch#42563 Moved logic for non-named unflatten from python nn module to aten/native to be reused by the nn module later. Fixed some inconsistencies with doc and code logic. Test Plan: Imported from OSS Reviewed By: zou3519 Differential Revision: D23030301 Pulled By: heitorschueroff fbshipit-source-id: 7c804ed0baa5fca960a990211b8994b3efa7c415
-
Implement hypot (pytorch#42291)
Summary: Related to pytorch#38349 Closes pytorch#22764 Pull Request resolved: pytorch#42291 Reviewed By: malfet Differential Revision: D22951859 Pulled By: mruberry fbshipit-source-id: d0118f2b6437e5c3f775f699ec46e946a8da50f0
-
[FX] Add interface to reject nodes (pytorch#42865)
Summary: Pull Request resolved: pytorch#42865 Test Plan: Imported from OSS Reviewed By: zdevito Differential Revision: D23056584 Pulled By: jamesr66a fbshipit-source-id: 02db08165ab41be5f3c4b5ff253cbb444eb9a7b8
-
-
-
Update cuda init docstring to improve clarity (pytorch#42923)
Summary: A small clarity improvement to the cuda init docstring Pull Request resolved: pytorch#42923 Reviewed By: zhangguanheng66 Differential Revision: D23080693 Pulled By: mrshenli fbshipit-source-id: aad5ed9276af3b872c1def76c6175ee30104ccb2
-
Revert "Revert in-progress changes to switch to a new Kernel IR hiera…
…rchy" This reverts commit 72aec1d.
-
-
-
Revert "Remove the incomplete kernel source files"
This reverts commit 398502d.
Commits on Aug 13, 2020
-
Revert D22994446: [pytorch][PR] CUDA reduction: allow outputs to have…
… different strides Test Plan: revert-hammer Differential Revision: D22994446 (pytorch@7f3f502) Original commit changeset: cc60beebad2e fbshipit-source-id: f4635deac386db0c161f910760cace09f15a1ff9
-
Speed up CUDA kernel launch when block/thread extents are statically …
…known (pytorch#42899) Summary: Pull Request resolved: pytorch#42899 Test Plan: Imported from OSS Reviewed By: ZolotukhinM Differential Revision: D23078708 Pulled By: bertmaher fbshipit-source-id: 237404b47a31672d7145d70996868a3b9b97924e
-
Fix TE microbenchmark harness to use appropriate fuser/executor (pyto…
…rch#42900) Summary: Pull Request resolved: pytorch#42900 Test Plan: Imported from OSS Reviewed By: ZolotukhinM Differential Revision: D23079715 Pulled By: bertmaher fbshipit-source-id: 6aa2b08a550835b7737e355960a16a7ca83878ea
-
Add a microbenchmark for LSTM elementwise portion (pytorch#42901)
Summary: Pull Request resolved: pytorch#42901 Test Plan: Imported from OSS Reviewed By: ZolotukhinM Differential Revision: D23079714 Pulled By: bertmaher fbshipit-source-id: 28f8c3b5019ee898e82e64a0a674da1b4736d252
-
Add missing type annotation for Tensor.ndim (pytorch#42909)
Summary: Fixes pytorch#42908 Pull Request resolved: pytorch#42909 Reviewed By: zhangguanheng66 Differential Revision: D23090364 Pulled By: malfet fbshipit-source-id: 44457fddc86f6abde635aa671e7611b405780ab9
-
Allow Tensor& in the unboxing logic (pytorch#42712)
Summary: Pull Request resolved: pytorch#42712 Previously, operators taking Tensor& as arguments or returning it couldn't be c10-full because the unboxing logic didn't support it. This adds temporary support for that. We're planning to remove this again later, but for now we need it to make those ops c10-full. See https://docs.google.com/document/d/19thMVO10yMZA_dQRoB7H9nTPw_ldLjUADGjpvDmH0TQ for the full plan. This PR also makes some ops c10-full that now can be. ghstack-source-id: 109693706 Test Plan: unit tests Reviewed By: bhosmer Differential Revision: D22989242 fbshipit-source-id: 1bd97e5fa2b90b0860784da4eb772660ca2db5a3
-
Remove impl_unboxedOnlyKernel (pytorch#42841)
Summary: Pull Request resolved: pytorch#42841 There is nothing using those APIs anymore. While we still have ops that require an unboxedOnly implementation (i.e. that aren't c10-full yet), those are all already migrated to the new op registration API and use `.impl_UNBOXED()`. ghstack-source-id: 109693705 Test Plan: waitforsandcastle Reviewed By: bhosmer Differential Revision: D23045335 fbshipit-source-id: d8e15cea1888262135e0d1d94c515d8a01bddc45
-
[quant][fix] Remove activation_post_process in qat modules (pytorch#4…
…2343) Summary: Pull Request resolved: pytorch#42343 Currently activation_post_process are inserted by default in qat modules, which is not friendly to automatic quantization tools, this PR removes them. Test Plan: Imported from OSS Reviewed By: raghuramank100 Differential Revision: D22856816 fbshipit-source-id: 988a43bce46a992b38fd0d469929f89e5b046131
-
[quant][pyper] Make offsets an optional paramter in the qembedding_ba…
…g op (pytorch#42924) Summary: Pull Request resolved: pytorch#42924 offsets is an optional paramter in the python module currently. So we update the operator to follow suit in order to avoid bad optional access Test Plan: python test/test_quantization.py TestQuantizeDynamicJitOps.test_embedding_bag Imported from OSS Reviewed By: radkris-git Differential Revision: D23081152 fbshipit-source-id: 847b58f826f5a18e8d4978fc4afc6f3a96dc4230
-
[Codemod][FBSourceClangFormatLinter] Daily
arc lint --take CLANGFORMATReviewed By: zertosh Differential Revision: D23102075 fbshipit-source-id: afb89e061bb9c290df7cf4c58157fc8d67fe78ad
-
Remove Python dependency from TensorPipe RPC agent (pytorch#42678)
Summary: Pull Request resolved: pytorch#42678 ghstack-source-id: 109544679 Test Plan: CI Reviewed By: mrshenli Differential Revision: D22978716 fbshipit-source-id: 31f91d35e9538375b047184cf4a735e4b8809a15
-
Enroll TensorPipe agent in C++-only E2E test (pytorch#42680)
Summary: Pull Request resolved: pytorch#42680 ghstack-source-id: 109544678 Test Plan: CI Reviewed By: mrshenli Differential Revision: D22978714 fbshipit-source-id: 04d6d190c240c6ead9bd9f3b7f3a5f964d7451e8
-
Revert D22856816: [quant][fix] Remove activation_post_process in qat …
…modules Test Plan: revert-hammer Differential Revision: D22856816 (pytorch@8cb42fc) Original commit changeset: 988a43bce46a fbshipit-source-id: eff5b9abdfc15b21c02c61eefbda38d349173436
-
[tensorexpr] Autograd for testing (pytorch#42548)
Summary: A simple differentiable abstraction to allow testing of full training graphs. Included in this 1st PR is an example of trivial differentiation. If approved, I can add a full MLP and demonstrate convergence using purely NNC (for performance testing) in the next PR. Pull Request resolved: pytorch#42548 Reviewed By: ZolotukhinM Differential Revision: D23057920 Pulled By: bwasti fbshipit-source-id: 4a239852c5479bf6bd20094c6c35f066a81a832e
-
update clone doc (pytorch#42931)
Summary: Pull Request resolved: pytorch#42931 Reviewed By: zhangguanheng66 Differential Revision: D23083000 Pulled By: albanD fbshipit-source-id: d76d90476ca294763f204c185a62ff6484381c67
-
[NNC] Fix some bugs in Round+Mod simplification (pytorch#42934)
Summary: When working on the Cuda Codegen, I found that running the IRSimplifier before generating code lead to test fails. This was due to a bug in Round+Mod simplification (e.g. (x / y * y) + (x % y) => x) to do with the order in which the terms appeared. After fixing it and writing a few tests around those cases, I found another bug in simplification of the same pattern and have fixed it (with some more test coverage). Pull Request resolved: pytorch#42934 Reviewed By: zhangguanheng66 Differential Revision: D23085548 Pulled By: nickgg fbshipit-source-id: e780967dcaa7a5fda9f6d7d19a6b7e7b4e94374b
-
Do not ignore
torch/__init__.pyi(pytorch#42958)Summary: Delete abovementioned from .gitignore as the file is gone since pytorch#42908 and no longer should be autogenerated. Pull Request resolved: pytorch#42958 Reviewed By: seemethere Differential Revision: D23094391 Pulled By: malfet fbshipit-source-id: af303477301ae89d6f283e34d7aeddeda7a9260f
-
collect_env.py: Print CPU architecture after Linux OS name (pytorch#4…
…2961) Summary: Missed this case in pytorch#42887 Pull Request resolved: pytorch#42961 Reviewed By: zou3519 Differential Revision: D23095264 Pulled By: malfet fbshipit-source-id: ff1fb0eba9ecd29bfa3d8f5e4c3dcbcb11deefcb
-
[quant] Create PerRowQuantizer for floating point scale and zero_point (
pytorch#42612) Summary: Pull Request resolved: pytorch#42612 Add a new Quantizer that supports an input zero point (bias) that can be float. The quantization equation in this case is Xq = (Xf - bias) * inv_scale, where bias is float zero_point value We start with per-row implementation and can extend to per-tensor in the future, if necessary Test Plan: python test/test_quantization.py TestQuantizedTensor Imported from OSS Reviewed By: jerryzh168 Differential Revision: D22960142 fbshipit-source-id: ca9ab6c5b45115d3dcb1c4358897093594313706
-
[quant] Make PerChannel Observer work with float qparams (pytorch#42690)
Summary: Pull Request resolved: pytorch#42690 Add implementation for new qscheme per_channel_affine_float_qparams in observer Test Plan: python test/test_quantization.py TestObserver.test_per_channel_observers Imported from OSS Reviewed By: vkuzo Differential Revision: D23070633 fbshipit-source-id: 84d348b0ad91e9214770131a72f7adfd3970349c
-
Update ort-nightly version to dev202008122 (pytorch#43019)
Summary: Fixes caffe2_onnx_ort1_py3_6_clang7_ubuntu16_04 test failures Pull Request resolved: pytorch#43019 Reviewed By: gchanan Differential Revision: D23108767 Pulled By: malfet fbshipit-source-id: 0131cf4ac0bf93d3d93cb0c97a888f1524e87472
-
Add executor and fuser options to the fastrnn test fixture (pytorch#4…
…2946) Summary: Pull Request resolved: pytorch#42946 There are 3 options for the executor and fuser and some of them aren't super interesting so I've combined the options into a single parameter, but made it fairly easy to expand the set if there are other configs we might care about. Test Plan: Benchmark it Imported from OSS Reviewed By: zheng-xq Differential Revision: D23090177 fbshipit-source-id: bd93a93c3fc64e5a4a847d1ce7f42ce0600a586e
-
1. Fusion::values_map_ is no longer necessary 2. Fusion::kir_map_ moved to GpuLower::kir_map_ 3. the actual lowering part of prepareForLowering() is now part of GpuLower
-
-
Enable torch.utils typechecks (pytorch#42960)
Summary: Fix typos in torch.utils/_benchmark/README.md Add empty __init__.py to examples folder to make example invocations from README.md correct Fixed uniform distribution logic generation when mixval and maxval are None Fixes pytorch#42984 Pull Request resolved: pytorch#42960 Reviewed By: seemethere Differential Revision: D23095399 Pulled By: malfet fbshipit-source-id: 0546ce7299b157d9a1f8634340024b10c4b7e7de
-
Fix to Learnable Fake Quantization Op Benchmarking (pytorch#43018)
Summary: Pull Request resolved: pytorch#43018 In this diff, a fix is added where the original non-learnable fake quantize is provided with trainable scale and zero point, whereas the requires_grad for both parameters should be completely disabled. Test Plan: Use the following command to execute the benchmark test: `buck test mode/dev-nosan pt:quantization_test` Reviewed By: vkuzo Differential Revision: D23107846 fbshipit-source-id: d2213983295f69121e9e6ae37c84d1f37d78ef39
-
make deadline=None for all numerics tests (pytorch#43014)
Summary: Pull Request resolved: pytorch#43014 changing this behavior mimics the behavior of the hold hypothesis testing library Test Plan: ran all tests on devserver Reviewed By: hl475 Differential Revision: D23085949 fbshipit-source-id: 433fdfbb04b6a609b738eb7c319365049a49579b
Commits on Aug 14, 2020
-
Add DDP+RPC tutorial to RPC docs page. (pytorch#42828)
Summary: Pull Request resolved: pytorch#42828 ghstack-source-id: 109855425 Test Plan: waitforbuildbot Reviewed By: jlin27 Differential Revision: D23037016 fbshipit-source-id: 250f322b652b86257839943309b8f0b8ce1bb25b
-
Nightly checkout tool (pytorch#42635)
Summary: Fixes pytorch#40829 This is cross-platform but I have only tried it on linux, personally. Also, I am not fully certain of the usage pattern, so if there are any additional features / adjustments / tests that you want me to add, please just let me know! CC ezyang rgommers Pull Request resolved: pytorch#42635 Reviewed By: zhangguanheng66 Differential Revision: D23078663 Pulled By: ezyang fbshipit-source-id: 5c8c8abebd1d462409c22dc4301afcd8080922bb
-
Allow RPC to be initialized again after shutdown. (pytorch#42723)
Summary: Pull Request resolved: pytorch#42723 This PR is addressing pytorch#39340 and allows users to initialize RPC again after shutdown. Major changes in the PR include: 1. Change to DistAutogradContainer to support this. 2. Ensure PythonRpcHandler is reinitialized appropriately. 3. Use PrefixStore in RPC initialization to ensure each new `init_rpc` uses a different prefix. ghstack-source-id: 109805368 Test Plan: waitforbuildbot Reviewed By: rohan-varma Differential Revision: D22993909 fbshipit-source-id: 9f1c1e0a58b58b97125f41090601e967f96f70c6
-
[jit][static runtime] Simplify the graph and add operator whitelist (p…
…ytorch#43024) Summary: This PR whitelists and simplifies graphs to help with development later on. Key to note in this PR is the use of both a pattern substitution and the registration of custom operators. This will likely be one of the main optimization types done in this folder. Pull Request resolved: pytorch#43024 Reviewed By: hlu1 Differential Revision: D23114262 Pulled By: bwasti fbshipit-source-id: e25aa3564dcc8a2b48cfd1561b3ee2a4780ae462
-
[quant][doc] Print more info for fake quantize module (pytorch#43031)
Summary: Pull Request resolved: pytorch#43031 fixes: pytorch#43023 Test Plan: Imported from OSS Reviewed By: vkuzo Differential Revision: D23116200 fbshipit-source-id: faa90ce8711da0785d635aacd0362c45717cfacc
-
Python/C++ API Parity: TransformerDecoderLayer (pytorch#42717)
Summary: Fixes pytorch#37756 Pull Request resolved: pytorch#42717 Reviewed By: zhangguanheng66 Differential Revision: D23095841 Pulled By: glaringlee fbshipit-source-id: 327a5a23c9a3cca05e422666a6d7d802a7e8c468
-
Back out "change pt_defs.bzl to python file"
Summary: Original commit changeset: d720fe2e684d Test Plan: CIs Reviewed By: linbinyu Differential Revision: D23114839 fbshipit-source-id: fda570b5e989a51936a6c5bc68f0e60c6f6b4b82
-
[reland][quant][fix] Remove activation_post_process in qat modules (p…
…ytorch#42343) (pytorch#43015) Summary: Pull Request resolved: pytorch#43015 Currently activation_post_process are inserted by default in qat modules, which is not friendly to automatic quantization tools, this PR removes them. Test Plan: Imported from OSS Imported from OSS Reviewed By: vkuzo Differential Revision: D23105059 fbshipit-source-id: 3439ac39e718ffb0390468163bcbffd384802b57
-
Clearer Semantics and Naming for Customized Quantization Range Initia…
…lization in Observer (pytorch#42602) Summary: Pull Request resolved: pytorch#42602 In this diff, clearer semantics and namings for are introduced by splitting the original `init_dynamic_qrange` into 2 separate `Optional[int]` types `qmin` and `qmax` to avoid the confusion of the parameters with dynamic quantization. The `qmin` and `qmax` parameters allow customers to specify their own customary quantization range and enables specific use cases for lower bit quantization. Test Plan: To assert the correctness and compatibility of the changes with existing observers, on a devvm, execute the following command to run the unit tests: `buck test //caffe2/test:quantization -- observer` Reviewed By: vkuzo, raghuramank100 Differential Revision: D22948334 fbshipit-source-id: 275bc8c9b5db4ba76fc2e79ed938376ea4f5a37c
-
Add more verbose error message about PackedSequence lengths argument (p…
…ytorch#42891) Summary: Add given tensor dimentionality, device and dtype to the error message Pull Request resolved: pytorch#42891 Reviewed By: ezyang Differential Revision: D23068769 Pulled By: malfet fbshipit-source-id: e49d0a5d0c10918795c1770b4f4e02494d799c51
-
Reconstruct scopes (pytorch#41615)
Summary: Pull Request resolved: pytorch#41615 Test Plan: Imported from OSS Reviewed By: ZolotukhinM Differential Revision: D22611331 Pulled By: taivu1998 fbshipit-source-id: d4ed4cf6360bc1f72ac9fa24bb4fcf6b7d9e7576
-
[TensorExpr] Wrap fuser in a class. (pytorch#42936)
Summary: Pull Request resolved: pytorch#42936 Test Plan: Imported from OSS Reviewed By: eellison Differential Revision: D23084407 Pulled By: ZolotukhinM fbshipit-source-id: f622874efbcbf8d4e49c8fa519a066161ebe4877
-
[TensorExpr] Remove redundant checks from canHandle in TE fuser. (pyt…
…orch#42937) Summary: Pull Request resolved: pytorch#42937 Test Plan: Imported from OSS Reviewed By: eellison Differential Revision: D23084408 Pulled By: ZolotukhinM fbshipit-source-id: 8e562e25ecc73b4e7b01e30f8b282945b96b4871
-
[TensorExpr] Cleanup logic in the TensorExpr fuser pass. (pytorch#42938)
Summary: Pull Request resolved: pytorch#42938 1. Structure the logic in a more straight-forward way: instead of magic tricks with node iterators in a block we now have a function that tries to create a fusion group starting from a given node (and pull everything it can into it). 2. The order in which we're pulling nodes into a fusion group is now more apparent. 3. The new pass structure automatically allows us to support fusion groups of size=1. Test Plan: Imported from OSS Reviewed By: eellison Differential Revision: D23084409 Pulled By: ZolotukhinM fbshipit-source-id: d59fc00c06af39a8e1345a4aed8d829494db084c
-
torch.complex and torch.polar (pytorch#39617)
Summary: For pytorch#35312 and pytorch#38458 (comment). Pull Request resolved: pytorch#39617 Reviewed By: zhangguanheng66 Differential Revision: D23083926 Pulled By: anjali411 fbshipit-source-id: 1874378001efe2ff286096eaf1e92afe91c55b29
-
Implement torch.nextafter (pytorch#42580)
Summary: Related to pytorch#38349. Pull Request resolved: pytorch#42580 Reviewed By: smessmer Differential Revision: D23012260 Pulled By: mruberry fbshipit-source-id: ce82a63c4ad407ec6ffea795f575ca7c58cd6137
-
Fix illegal memory acess issue for CUDA versionn of SplitByLengths op…
…erator. Summary: 1. Fix illegal memory access issue for SplitByLengths operator in the CUDA context. 2. Add support to scaling lengths vector for SplitByLengths operator. 3. Add support to test SplitByLengths operator in the CUDA context. Example for SplitByLengths operator processing scaling lengths vector: value vector A = [1, 2, 3, 4, 5, 6] length vector B = [1, 2] after execution of SplitByLengths operator, the output should be [1,2] and [3,4,5,6] Test Plan: buck test mode/dev-nosan caffe2/caffe2/python/operator_test:concat_split_op_test Reviewed By: kennyhorror Differential Revision: D23079841 fbshipit-source-id: 3700e7f2ee0a5a2791850071fdc16e5b054f8400
-
Get, save, and load module information for each operator (pytorch#42133)
Summary: Pull Request resolved: pytorch#42133 Test Plan: We save a module with module debugging information as follows. ``` import torch m = torch.jit.load('./detect.pt') # Save module without debug info m._save_for_lite_interpreter('./detect.bc') # Save module with debug info m._save_for_lite_interpreter('./detect.bc', _save_debug_info_in_bytecode=True) ``` Size of the file without module debugging information: 4.508 MB Size of the file with module debugging information: 4.512 MB Reviewed By: kimishpatel Differential Revision: D22803740 Pulled By: taivu1998 fbshipit-source-id: c82ea62498fde36a1cfc5b073e2cea510d3b7edb
-
Guard TensorPipe agent by USE_TENSORPIPE (pytorch#42682)
Summary: Pull Request resolved: pytorch#42682 ghstack-source-id: 109834351 Test Plan: CI Reviewed By: malfet Differential Revision: D22978717 fbshipit-source-id: 18b7cbdb532e78ff9259e82f0f92ad279124419d
-
Automated submodule update: FBGEMM (pytorch#42834)
Summary: This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM). New submodule commit: pytorch/FBGEMM@29d5eb9 Pull Request resolved: pytorch#42834 Test Plan: Ensure that CI jobs succeed on GitHub before landing. Reviewed By: jspark1105 Differential Revision: D23040145 fbshipit-source-id: 1d7209ea1910419b7837703122b8a4c76380ca4a
-
Fix typo in collect_env.py (pytorch#43050)
Summary: Minor typo fix introduced in yesterdays PR: pytorch#42961 Pull Request resolved: pytorch#43050 Reviewed By: ezyang, malfet Differential Revision: D23130936 Pulled By: zou3519 fbshipit-source-id: e8fa2bf155ab6a5988c74e8345278d8d70855894
-
Make Mish support large inputs. (pytorch#43037)
Summary: Pull Request resolved: pytorch#43037 In the previous version of mish_op.cc, the output would be 'nan' for large inputs. We re-write mish_op.cc to solve this problem. Test Plan: Unit test buck test //dper3/dper3/modules/tests:core_modules_test -- test_linear_compress_embedding_with_attention_with_activation_mish {F284052906} buck test mode/opt //dper3/dper3_models/ads_ranking/tests:model_paradigm_e2e_tests -- test_sparse_nn_with_mish {F284224158} ## Workflow f212113434 {F285281318} Differential Revision: D23102644 fbshipit-source-id: 98f1ea82f8c8e05b655047b4520c600fc1a826f4
-
Test Plan: CI Reviewed By: linbinyu Differential Revision: D23108919 fbshipit-source-id: 913c982351a94080944f350641d7966c6c2cc508
-
Build test_e2e_tensorpipe only if Gloo is enabled (pytorch#43041)
Summary: test_e2e_tensorpipe depends on ProcessGroupGloo, therefore it could not be tested with Gloo disabled Otherwise, it re-introduces pytorch#42776 Pull Request resolved: pytorch#43041 Reviewed By: lw Differential Revision: D23122101 Pulled By: malfet fbshipit-source-id: a8a088b6522a3bc888238ede5c2d589b83c6ea94
-
Add inplace option for torch.nn.Hardsigmoid and torch.nn.Hardswish la…
…yers (pytorch#42346) Summary: **`torch.nn.Hardsigmoid`** and **`torch.nn.Hardswish`** classes currently do not support `inplace` operations as it uses `torch.nn.functional.hardsigmoid` and `torch.nn.functional.hardswish` functions with their default inplace argument which is `False`. So, I added `inplace` argument for `torch.nn.Hardsigmoid` and `torch.nn.Hardswish` classes so that forward operation can be done inplace as well while using these layers. Pull Request resolved: pytorch#42346 Reviewed By: izdeby Differential Revision: D23108487 Pulled By: albanD fbshipit-source-id: 0767334fa10e5ecc06fada2d6469f3ee1cacd957
-
Test the type promotion between every two dtypes thoroughly (pytorch#…
…42585) Summary: Fixes pytorch#41842 Pull Request resolved: pytorch#42585 Reviewed By: izdeby Differential Revision: D23126759 Pulled By: mruberry fbshipit-source-id: 8337e02f23a4136c2ba28c368f8bdbd28400de44
-
Add complex tensor dtypes for the __cuda_array_interface__ spec (pyto…
…rch#42918) Summary: Fixes pytorch#42860 The `__cuda_array_interface__` tensor specification is missing the appropriate datatypes for the newly merged complex64 and complex128 tensors. This PR addresses this issue by casting: * `torch.complex64` to 'c8' * `torch.complex128` to 'c16' Pull Request resolved: pytorch#42918 Reviewed By: izdeby Differential Revision: D23130219 Pulled By: anjali411 fbshipit-source-id: 5f8ee8446a71cad2f28811afdeae3a263a31ad11
-
Remove
itruedivbecause it's already defined in torch/tensor.py (py……torch#42962) Summary: Fixes pytorch#42955 Pull Request resolved: pytorch#42962 Reviewed By: mruberry Differential Revision: D23111523 Pulled By: malfet fbshipit-source-id: ecab7a4aae1fe556753b8d6528cae1ae201beff3
-
Add back Tensor.nonzero type annotation (pytorch#43053)
Summary: Closes pytorchgh-42998 The issue is marked for 1.6.1, if there's anything I need to do for a backport please tell me what that is. Pull Request resolved: pytorch#43053 Reviewed By: izdeby Differential Revision: D23131708 Pulled By: malfet fbshipit-source-id: 2744bacce6bdf6ae463c17411b672f09707e0887
-
Clip Binomial results for different endpoints in curand_uniform (pyto…
…rch#42702) Summary: Fixes pytorch#42153 As [documented](https://docs.nvidia.com/cuda/curand/device-api-overview.html) (search for `curand_uniform` on the page), `curand_uniform` returns "from 0.0 to 1.0, where 1.0 is included and 0.0 is excluded." These endpoints are different than the CPU equivalent, and makes the calculation in the PR fail when the value is 1.0. The test from the issue is added, it failed for me consistently before the PR even though I cut the number of samples by 10. Pull Request resolved: pytorch#42702 Reviewed By: gchanan Differential Revision: D23107451 Pulled By: ngimel fbshipit-source-id: 3575d5b8cd5668e74b5edbecd95154b51aa485a1
-
fix searchsorted output type (pytorch#42933)
Summary: Fixes pytorch#41389 Make sure searchsorted that returns integer type does not make them require gradients. Pull Request resolved: pytorch#42933 Reviewed By: gchanan Differential Revision: D23109583 Pulled By: albanD fbshipit-source-id: 5af300b2f7f3c140d39fd7f7d87799f7b93a79c1
-
Enable typechecking of
collect_env.pyduring CI (pytorch#43062)Summary: No type annotations can be added to the script, as it still have to be Python-2 compliant. Make changes to avoid variable type redefinition. Pull Request resolved: pytorch#43062 Reviewed By: zou3519 Differential Revision: D23132991 Pulled By: malfet fbshipit-source-id: 360c02e564398f555273e5889a99f834a5467059
-
[JIT] Add property support to TorchScript classes (pytorch#42389)
Summary: Pull Request resolved: pytorch#42389 **Summary** This commit adds support for properties to TorchScript classes, specifically for getters and setters. They are implemented essentially as pointers to the methods that the corresponding decorators decorate, which are treated like regular class methods. Deleters for properties are considered to be out of scope (and probably useless for TorchScript anyway). **Test Plan** This commit adds a unit test for a class with a property that has both getter and setter and one that has only a getter. `python test/test_jit.py TestClassType.test_properties` Test Plan: Imported from OSS Reviewed By: eellison, ppwwyyxx Differential Revision: D22880232 Pulled By: SplitInfinity fbshipit-source-id: 4828640f4234cb3b0d4f3da4872a75fbf519e5b0
-
Embed torch.nn typing annotations (pytorch#43044)
Summary: Delete several .pyi files and embed annotations from those files in respective .py Pull Request resolved: pytorch#43044 Reviewed By: ezyang Differential Revision: D23123234 Pulled By: malfet fbshipit-source-id: 4ba361cc84402352090523924b0035e100ba48b1
-
add fake fp16 fusions to net transforms (pytorch#42927)
Summary: Pull Request resolved: pytorch#42927 added fp16 fusion to net transforms refactored the transforms as well as glow_transform to get out of opt/custom so that the OSS builds passed Test Plan: added net runner tests for this Reviewed By: yinghai Differential Revision: D23080881 fbshipit-source-id: ee6451811fedfd07c6560c178229854bca29301f
-
Export MergeIdLists Caffe2 Operator to PyTorch
Summary: As titled. Test Plan: buck test //caffe2/caffe2/python/operator_test:torch_integration_test -- test_merge_id_lists Reviewed By: yf225 Differential Revision: D23076951 fbshipit-source-id: c37dfd93003590eed70b0d46e0151397a402dde6
-
Enable test_logit FakeLowP test. (pytorch#43073)
Summary: Pull Request resolved: pytorch#43073 Enable test_logit FakeLowP test. Test Plan: test_op_nnpi_fp16.py Reviewed By: hyuen Differential Revision: D23141375 fbshipit-source-id: cb7e7879487e33908b14ef401e1ab05fda193d28
-
Implemented torch::nn::Unflatten in libtorch (pytorch#42613)
Summary: Pull Request resolved: pytorch#42613 Test Plan: Imported from OSS Reviewed By: glaringlee Differential Revision: D23030302 Pulled By: heitorschueroff fbshipit-source-id: 954f1cdfcbd3a62a7f0e887fcf5995ef27222a87
-
Fix a casting warning (pytorch#42451)
Summary: Fix an annoying casting warning Pull Request resolved: pytorch#42451 Reviewed By: yf225 Differential Revision: D22993194 Pulled By: ailzhang fbshipit-source-id: f317a212d4e768d49d24f50aeff9c003be2fd30a
-
[quant] Add embeddingbag_prepack function that works on quantized ten…
…sor. (pytorch#42762) Summary: Pull Request resolved: pytorch#42762 Use a prepack function that accepts qtensor as an input. The output is a byte tensor with packed data. This is currently implemented only for 8-bit. In the future once we add 4-bit support this function will be extended to support that too. Note -In the following change I will add TorchBind support for this to support serialization of packed weights. Test Plan: python test/test_quantization.py TestQuantizedEmbeddingBag Imported from OSS Reviewed By: vkuzo Differential Revision: D23070632 fbshipit-source-id: 502aa1302dffec1298cdf52832c9e2e5b69e44a8
-
[quant] Add torchbind support for embedding_bag packed weights (pytor…
…ch#42881) Summary: Pull Request resolved: pytorch#42881 This enables serialization/de-serialization of embedding packed params using getstate/setstate calls. Added version number to deal with changes to serialization formats in future. This can be extended in the future to support 4-bit/2-bit once we add support for that. Test Plan: python test/test_quantization.py TestQuantizedEmbeddingBag Imported from OSS Reviewed By: jerryzh168 Differential Revision: D23070634 fbshipit-source-id: 2ca322ab998184c728be6836f9fd12cec98b2660
-
Fix warning: dynamic initialization in unreachable code. (pytorch#43065)
Summary: Pull Request resolved: pytorch#43065 Test Plan: Imported from OSS Reviewed By: suo Differential Revision: D23136883 Pulled By: ZolotukhinM fbshipit-source-id: 878f6af13ff8df63fef5f34228f7667ee452dd95
-
[fx] split Node into Node/Proxy (pytorch#42991)
Summary: Pull Request resolved: pytorch#42991 Have Node both be a record of the operator in the graph, and the way we _build_ the graph made it difficult to keep the IR datastructure separate from the proxying logic in the build. Among other issues this means that typos when using nodes would add things to the graph: ``` for node in graph.nodes: node.grph # does not error, returns an node.Attribute object! ``` This separates the builder into a Proxy object. Graph/Node no longer need to understand `delegate` objects since they are now just pure IR. This separates the `symbolic_trace` (proxy.py/symbolic_trace.py) from the IR (node.py, graph.py). This also allows us to add `create_arg` to the delegate object, allowing the customization of how aggregate arguments are handled when converting to a graph. Test Plan: Imported from OSS Reviewed By: jamesr66a Differential Revision: D23099786 Pulled By: zdevito fbshipit-source-id: 6f207a8c237e5eb2f326b63b0d702c3ebcb254e4
Commits on Aug 15, 2020
-
Add polygamma where n >= 2 (pytorch#42499)
Summary: pytorch#40980 I have a few questions during implementing Polygamma function... so, I made PR prior to complete it. 1. some code blocks brought from cephes library(and I did too) ``` /* * The following function comes with the following copyright notice. * It has been released under the BSD license. * * Cephes Math Library Release 2.8: June, 2000 * Copyright 1984, 1987, 1992, 2000 by Stephen L. Moshier */ ``` is it okay for me to use cephes code with this same copyright notice(already in the Pytorch codebases) 2. There is no linting in internal Aten library. (as far as I know, I read https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md) How do I'm sure my code will follow appropriate guidelines of this library..? 3. Actually, there's a digamma, trigamma function already digamma is needed, however, trigamma function becomes redundant if polygamma function is added. it is okay for trigamma to be there or should be removed? btw, CPU version works fine with 3-rd order polygamma(it's what we need to play with variational inference with beta/gamma distribution) now and I'm going to finish GPU version soon. Pull Request resolved: pytorch#42499 Reviewed By: gchanan Differential Revision: D23110016 Pulled By: albanD fbshipit-source-id: 246f4c2b755a99d9e18a15fcd1a24e3df5e0b53e
-
Add GCC codecoverage flags (pytorch#43066)
Summary: Rename `CLANG_CODE_COVERAGE` option to `CODE_COVERAGE` and add compiler specific flags for GCC and Clang Pull Request resolved: pytorch#43066 Reviewed By: scintiller Differential Revision: D23137488 Pulled By: malfet fbshipit-source-id: a89570469692f878d84f7da6f9d5dc01df423e80
-
Stop treating ASAN as special case (pytorch#43048)
Summary: Add "asan" node to a `CONFIG_TREE_DATA` rather than hardcoded that non-xla clang-5 is ASAN Pull Request resolved: pytorch#43048 Reviewed By: houseroad Differential Revision: D23126296 Pulled By: malfet fbshipit-source-id: 22f02067bb2f5435a0e963a6c722b9c115ccfea4
-
Fix type annotations for a number of torch.utils submodules (pytorch#…
…42711) Summary: Related issue on `torch.utils` type annotation hiccups: pytorchgh-41794 Pull Request resolved: pytorch#42711 Reviewed By: mrshenli Differential Revision: D23005434 Pulled By: malfet fbshipit-source-id: 151554b1e7582743f032476aeccdfdad7a252095
-
Add set_device_map to TensorPipeOptions to support GPU args (pytorch#…
…42637) Summary: Pull Request resolved: pytorch#42637 This commit enables sending non-CPU tensors through RPC using TensorPipe backend. Users can configure device mappings by calling set_map_location on `TensorPipeRpcBackendOptions`. Internally, the `init_rpc` API verifies the correctness of device mappings. It will shutdown RPC if the check failed, or proceed and pass global mappings to `TensorPipeAgent` if the check was successful. For serde, we added a device indices field to TensorPipe read and write buffers, which should be either empty (all tensors must be on CPU) or match the tensors in order and number in the RPC message. This commit does not yet avoid zero-copy, the tensor is always moved to CPU on the sender and then moved to the specified device on the receiver. Test Plan: Imported from OSS Reviewed By: izdeby Differential Revision: D23011572 Pulled By: mrshenli fbshipit-source-id: 62b617eed91237d4e9926bc8551db78b822a1187
-
Document unavailable reduction ops with NCCL backend (pytorch#42822)
Summary: Pull Request resolved: pytorch#42822 These ops arent supported with NCCL backend and used to silently error. We disabled them as part of addressing pytorch#41362, so document that here. ghstack-source-id: 109957761 Test Plan: CI Reviewed By: mrshenli Differential Revision: D23023046 fbshipit-source-id: 45d69028012e0b6590c827d54b35c66cd17e7270
-
[JIT] Represent profiled types as a node attribute (pytorch#43035)
Summary: This changes profiled types from being represented as: `%23 : Float(4:256, 256:1, requires_grad=0, device=cpu) = prim::profile(%0)` -> `%23 : Tensor = prim::profile[profiled_type=Float(4:256, 256:1, requires_grad=0, device=cpu)](%0)` Previously, by representing the profiled type in the IR directly it was very easy for optimizations to accidentally use profiled types without inserting the proper guards that would ensure that the specialized type would be seen. It would be a nice follow up to extend this to prim::Guard as well, however we have short term plans to get rid of prim::Guard. Pull Request resolved: pytorch#43035 Reviewed By: ZolotukhinM Differential Revision: D23120226 Pulled By: eellison fbshipit-source-id: c78d7904edf314dd65d1a343f2c3a947cb721b32
-
[jit] DeepAndWide benchmark (pytorch#43096)
Summary: Pull Request resolved: pytorch#43096 Add benchmark script for deep and wide model. Reviewed By: bwasti, yinghai Differential Revision: D23099925 fbshipit-source-id: aef09d8606eba1eccc0ed674dfea59b890d3648b
Commits on Aug 16, 2020
-
Implement hstack, vstack, dstack (pytorch#42799)
Summary: Related to pytorch#38349 Pull Request resolved: pytorch#42799 Reviewed By: izdeby Differential Revision: D23140704 Pulled By: mruberry fbshipit-source-id: 6a36363562c50d0abce87021b84b194bb32825fb
-
Updates torch.clone documentation to be consistent with other functio…
…ns (pytorch#43098) Summary: `torch.clone` exists but was undocumented, and the method incorrectly listed `memory_format` as a positional argument. This: - documents `torch.clone` - lists `memory_format` as a keyword-only argument - wordsmiths the documentation Pull Request resolved: pytorch#43098 Reviewed By: ngimel Differential Revision: D23153397 Pulled By: mruberry fbshipit-source-id: c2ea781cdcb8b5ad3f04987c2b3a2f1fe0eaf18b
-
Optimize SiLU (Swish) op in PyTorch (pytorch#42976)
Summary: Pull Request resolved: pytorch#42976 Optimize SiLU (Swish) op in PyTorch. Some benchmark result input = torch.rand(1024, 32768, dtype=torch.float, device="cpu") forward: 221ms -> 133ms backward: 600ms -> 170ms input = torch.rand(1024, 32768, dtype=torch.double, device="cpu") forward: 479ms -> 297ms backward: 1438ms -> 387ms input = torch.rand(8192, 32768, dtype=torch.float, device="cuda") forward: 24.34ms -> 9.83ms backward: 97.05ms -> 29.03ms input = torch.rand(4096, 32768, dtype=torch.double, device="cuda") forward: 44.24ms -> 30.15ms backward: 126.21ms -> 49.68ms Test Plan: buck test mode/dev-nosan //caffe2/test:nn -- "SiLU" Reviewed By: houseroad Differential Revision: D23093593 fbshipit-source-id: 1ba7b95d5926c4527216ed211a5ff1cefa3d3bfd
Commits on Aug 17, 2020
-
Adds arccosh alias for acosh and adds an alias consistency test (pyto…
…rch#43107) Summary: This adds the torch.arccosh alias and updates alias testing to validate the consistency of the aliased and original operations. The alias testing is also updated to run on CPU and CUDA, which revealed a memory leak when tracing (see pytorch#43119). Pull Request resolved: pytorch#43107 Reviewed By: ngimel Differential Revision: D23156472 Pulled By: mruberry fbshipit-source-id: 6155fac7954fcc49b95e7c72ed917c85e0eabfcd
-
add training mode to mobile::Module (pytorch#42880)
Summary: Pull Request resolved: pytorch#42880 Enable switching between and checking for training and eval mode for torch::jit::mobile::Module using train(), eval(), and is_training(), like exists for torch::jit::Module. Test Plan: Imported from OSS Reviewed By: iseeyuan Differential Revision: D23063006 Pulled By: ann-ss fbshipit-source-id: b79002148c46146b6e961cbef8aaf738bbd53cb2
-
prepare to split transformer header file (pytorch#43069)
Summary: Pull Request resolved: pytorch#43069 The transformer c++ impl need to put TransformerEncoderLayer/DecoderLayer and TransformerEncoder/TransformerDecoder in different header since TransformerEncoder/Decoder's options class need TransformerEncoderLayer/DecoderLayer as input parameter. Split header files to avoid cycle includsion. Test Plan: Imported from OSS Reviewed By: yf225 Differential Revision: D23139437 Pulled By: glaringlee fbshipit-source-id: 3c752ed7702ba18a9742e4d47d049e62d2813de0
-
Fix freeze_module pass for sharedtype (pytorch#42457)
Summary: During cleanup phase, calling recordReferencedAttrs would record the attributes which are referenced and hence kept. However, if you have two instances of the same type which are preserved through freezing process, as the added testcase shows, then during recording the attributes which are referenced, we iterate through the type INSTANCES that we have seen so far and record those ones. Thus if we have another instance of the same type, we will just look at the first instance in the list, and record that instances. This PR fixes that by traversing the getattr chains and getting the actual instance of the getattr output. Pull Request resolved: pytorch#42457 Test Plan: python test/test_jit.py TestFreezing Fixes #{issue number} Reviewed By: gchanan Differential Revision: D23106921 Pulled By: kimishpatel fbshipit-source-id: ffff52876938f8a1fedc69b8b24a3872ea66103b
-
Add torch.dot for complex tensors (pytorch#42745)
Summary: Pull Request resolved: pytorch#42745 Test Plan: Imported from OSS Reviewed By: izdeby Differential Revision: D23056382 Pulled By: anjali411 fbshipit-source-id: c97f15e057095f78069844dbe0299c14104d2fce
-
Set default ATen threading backend to native if USE_OPENMP is false (p…
…ytorch#43067) Summary: Since OpenMP is not available on some platforms, or might be disabled by user, set default `ATEN_THREADING` based on USE_OPENMP and USE_TBB options Fixes pytorch#43036 Pull Request resolved: pytorch#43067 Reviewed By: houseroad Differential Revision: D23138856 Pulled By: malfet fbshipit-source-id: cc8f9ee59a5559baeb3f19bf461abbc08043b71c
-
Rename XLAPreAutograd to AutogradXLA. (pytorch#43047)
Summary: Fixes #{issue number} Pull Request resolved: pytorch#43047 Reviewed By: ezyang Differential Revision: D23134326 Pulled By: ailzhang fbshipit-source-id: 5fcbc23755daa8a28f9b03af6aeb3ea0603b5c9a -
.circleci: Copy LLVM from pre-built image (pytorch#43038)
Summary: LLVM builds took a large amount of time and bogged down docker builds in general. Since we build it the same for everything let's just copy it from a pre-built image instead of building it from source every time. Builds are defined in pytorch/builder#491 Signed-off-by: Eli Uriegas <eliuriegas@fb.com> Pull Request resolved: pytorch#43038 Reviewed By: malfet Differential Revision: D23119513 Pulled By: seemethere fbshipit-source-id: f44324439d45d97065246caad07c848e261a1ab6
-
vmap: fixed to work with functools.partial (pytorch#43028)
Summary: Pull Request resolved: pytorch#43028 There was a bug where we always tried to grab the `__name__` attribute of the function passed in by the user. Not all Callables have the `__name__` attribute, an example being a Callable produced by functools.partial. This PR modifies the error-checking code to use `repr` if `__name__` is not available. Furthermore, it moves the "get the name of this function" functionality to the actual error sites as an optimization so we don't spend time trying to compute `__repr__` for the Callable if there is no error. Test Plan: - `pytest test/test_vmap.py -v`, added new tests. Reviewed By: yf225 Differential Revision: D23130235 Pulled By: zou3519 fbshipit-source-id: 937f3640cc4d759bf6fa38b600161f5387a54dcf
-
Implement batching rules for some unary ops (pytorch#43059)
Summary: Pull Request resolved: pytorch#43059 This PR implements batching rules for some unary ops. In particular, it implements the batching rules for the unary ops that take a single tensor as input (and nothing else). The batching rule for a unary op is: (1) grab the physical tensor straight out of the BatchedTensor (2) call the unary op (3) rewrap the physical tensor in a BatchedTensor Test Plan: - new tests `pytest test/test_vmap.py -v -k "Operators"` Reviewed By: ezyang Differential Revision: D23132277 Pulled By: zou3519 fbshipit-source-id: 24b9d7535338207531d767155cdefd2c373ada77
-
Adds movedim method, fixes movedim docs, fixes view doc links (pytorc…
…h#43122) Summary: This PR: - Adds a method variant to movedim - Fixes the movedim docs so it will actually appear in the documentation - Fixes three view doc links which were broken Pull Request resolved: pytorch#43122 Reviewed By: ngimel Differential Revision: D23166222 Pulled By: mruberry fbshipit-source-id: 14971585072bbc04b5366d4cc146574839e79cdb
-
Fix type annotations for torch.sparse, enable in CI (pytorch#43108)
Summary: Closes pytorchgh-42982 Pull Request resolved: pytorch#43108 Reviewed By: malfet Differential Revision: D23167560 Pulled By: ezyang fbshipit-source-id: 0d660ca686ada2347bf440c6349551d1539f99ef
-
[jit] better error message (pytorch#43093)
Summary: Pull Request resolved: pytorch#43093 without this it's hard to tell which module is going wrong Test Plan: ``` > TypeError: > 'numpy.int64' object in attribute 'Linear.in_features' is not a valid constant. > Valid constants are: > 1. a nn.ModuleList > 2. a value of type {bool, float, int, str, NoneType, torch.device, torch.layout, torch.dtype} > 3. a list or tuple of (2) ``` Reviewed By: eellison Differential Revision: D23148516 fbshipit-source-id: b86296cdeb7b47c9fd69b5cfa479914c58ef02e6
-
Use c10 threadpool for GPU to CPU distributed autograd continuations. (…
…pytorch#42511) Summary: Pull Request resolved: pytorch#42511 DistEngine currently only has a single thread to execute GPU to CPU continuations as part of the backward pass. This would be a significant performance bottleneck in cases where we have such continuations and would like to execute these using all CPU cores. To alleviate this in this PR, we have the single thread in DistEngine only dequeue work from the global queue, but then hand off execution of that work to the c10 threadpool where we call "execute_graph_task_until_ready_queue_empty". For more context please see: pytorch#40255 (comment). ghstack-source-id: 109997718 Test Plan: waitforbuildbot Reviewed By: albanD Differential Revision: D22917579 fbshipit-source-id: c634b6c97f3051f071fd7b994333e6ecb8c54155
-
Remove unused variable vecVecStartIdx (pytorch#42257)
Summary: Pull Request resolved: pytorch#42257 Reviewed By: gchanan Differential Revision: D23109328 Pulled By: ezyang fbshipit-source-id: dacd438395fedd1050ad3ffb81327bbb746c776c
Commits on Aug 18, 2020
-
quant bench: update observer configs (pytorch#42956)
Summary: Pull Request resolved: pytorch#42956 In preparation for observer perf improvement, cleans up the micro benchmarks: * disable CUDA for histogram observers (it's too slow) * add larger shapes for better representation of real workloads Test Plan: ``` cd benchmarks/operator_benchmark python -m pt.qobserver_test ``` Imported from OSS Reviewed By: supriyar Differential Revision: D23093996 fbshipit-source-id: 5dc477c9bd5490d79d85ff8537270cd25aca221a
-
observers: make eps a buffer (pytorch#43149)
Summary: Pull Request resolved: pytorch#43149 This value doesn't change, making it a buffer to only pay the cost of creating a tensor once. Test Plan: Imported from OSS Reviewed By: jerryzh168 Differential Revision: D23170428 fbshipit-source-id: 6b963951a573efcc5b5a57649c814590b448dd72
-
observers: use clamp instead of min/max in calculate_qparams (pytorch…
…#43150) Summary: Pull Request resolved: pytorch#43150 The current logic was expensive because it created tensors on CUDA. Switching to clamp since it can work without needing to create tensors. Test Plan: benchmarks Imported from OSS Reviewed By: jerryzh168 Differential Revision: D23170427 fbshipit-source-id: 6fe3a728e737aca9f6c2c4d518c6376738577e21
-
observers: use torch.all to check for valid min and max values (pytor…
…ch#43151) Summary: Pull Request resolved: pytorch#43151 Using `torch.all` instead of `torch.sum` and length check. It's unclear whether the increase in perf (~5% for small inputs) is real, but should be a net benefit, especially for larger channel inputs. Test Plan: Imported from OSS Reviewed By: jerryzh168 Differential Revision: D23170426 fbshipit-source-id: ee5c25eb93cee1430661128ac9458a9c525df8e5
-
Delete accidentally committed file errors.txt. (pytorch#43164)
Summary: Pull Request resolved: pytorch#43164 Test Plan: Imported from OSS Reviewed By: mruberry Differential Revision: D23175392 Pulled By: gchanan fbshipit-source-id: 0d2d918fdf4a94361cdc3344bf1bc89dd0286ace
-
[ONNX] Squeeze operator should give an error when trying to apply to …
…a dimension with shape > 1 (pytorch#38476) Summary: The ONNX spec for the Squeeze operator: > Remove single-dimensional entries from the shape of a tensor. Takes a parameter axes with a list of axes to squeeze. If axes is not provided, all the single dimensions will be removed from the shape. If an axis is selected with shape entry not equal to one, an error is raised. Currently, as explained in issue pytorch#36796, it is possible to export such a model to ONNX, and this results in an exception from ONNX runtime. Fixes pytorch#36796. Pull Request resolved: pytorch#38476 Reviewed By: hl475 Differential Revision: D22158024 Pulled By: houseroad fbshipit-source-id: bed625f3c626eabcbfb2ea83ec2f992963defa19
-
Improve zero sized input for addmv (pytorch#41824)
Summary: fixes pytorch#41340 Unfortunately, I still can not get a K80 to verify the fix, but it should be working. Pull Request resolved: pytorch#41824 Reviewed By: mruberry Differential Revision: D23172775 Pulled By: ngimel fbshipit-source-id: aa6af96fe74e3bb07982c006cb35ecc7f18181bc
-
remove dot from TH (pytorch#43148)
Summary: small cleanup of dead code Pull Request resolved: pytorch#43148 Reviewed By: mruberry Differential Revision: D23175571 Pulled By: ngimel fbshipit-source-id: b1b0ae9864d373c75666b95c589d090a9ca791b2
-
Pin VC++ version to 14.26 (pytorch#43184)
Summary: VC++14.27 fails to compile mkl-dnn, see oneapi-src/oneDNN#812 Pull Request resolved: pytorch#43184 Reviewed By: glaringlee Differential Revision: D23181803 Pulled By: malfet fbshipit-source-id: 9861c6243673c775374d77d2f51b45a42791b475
-
[NVFuser] Enable E2E BCast-PWise-Reduction fusions (pytorch#43129)
Summary: Had a bunch of merged commits that shouldn't have been there, reverted them to prevent conflicts. Lots of new features, highlights listed below. **Overall:** - Enables pointwise fusion, single (but N-D) broadcast -- pointwise fusion, single (but N-D) broadcast -- pointwise -- single (but N-D) reduction fusion. **Integration:** - Separate "magic scheduler" logic that takes a fusion and generates code generator schedule - Reduction fusion scheduling with heuristics closely matching eagermode (unrolling supported, but no vectorize support) - 2-Stage caching mechanism, one on contiguity, device, type, and operations, the other one is input size->reduction heuristic **Code Generation:** - More generic support in code generation for computeAt - Full rework of loop nest generation and Indexing to more generically handle broadcast operations - Code generator has automatic kernel launch configuration (including automatic allocation of grid reduction buffers) - Symbolic (runtime) tilling on grid/block dimensions is supported - Simplified index generation based on user-defined input contiguity - Automatic broadcast support (similar to numpy/pytorch semantics) - Support for compile time constant shared memory buffers - Parallelized broadcast support (i.e. block reduction -> block broadcast support) Pull Request resolved: pytorch#43129 Reviewed By: mrshenli Differential Revision: D23162207 Pulled By: soumith fbshipit-source-id: 16deee4074c64de877eed7c271d6a359927111b2
-
Add shape inference to SparseLengthsSumSparse ops (pytorch#43181)
Summary: Pull Request resolved: pytorch#43181 att Test Plan: ``` buck test caffe2/caffe2/opt:bound_shape_inference_test ``` Reviewed By: ChunliF Differential Revision: D23097145 fbshipit-source-id: 3e4506308446f28fbeb01dcac97dce70c0443975
-
Compress fatbin to fit into 32bit indexing (pytorch#43074)
Summary: Fixes pytorch#39968 tested with `TORCH_CUDA_ARCH_LIST='3.5 5.2 6.0 6.1 7.0 7.5 8.0+PTX'`, before this PR, it was failing, and with this PR, the build succeed. With `TORCH_CUDA_ARCH_LIST='7.0 7.5 8.0+PTX'`, `libtorch_cuda.so` with symbols changes from 2.9GB -> 2.2GB cc: ptrblck mcarilli jjsjann123 Pull Request resolved: pytorch#43074 Reviewed By: mrshenli Differential Revision: D23176095 Pulled By: malfet fbshipit-source-id: 7b3e6d049fc080e519f21e80df05ef68e7bea57e
-
CI, to our fork. (#145) (#303)
Co-authored-by: Christian Sarofeen <csarofeen@nvidia.com>