V1.6.0 features #565
Merged
V1.6.0 features #565
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
### Feature or Bugfix - Refactoring ### Detail Replaced externalId and PivotRoleName secrets in SecretsManager by SSM parameters: - modified parameter_stack and secrets_stack to create the parameters and remove the secrets. - the new externalId parameter uses a pre-existing secret if it exists, otherwise it generates a random sequence of numbers and letters - modified the sts handler to retrieve the pivotRoleName and externalId from SSM ### Relates - #443 By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
…ts (#482) ### Feature or Bugfix - Feature ### Detail - For datasets that are classified as "Secret", data preview is disabled. In the same way, data profiling results should alse be denied. - Added tests for profiling - removed unused methods 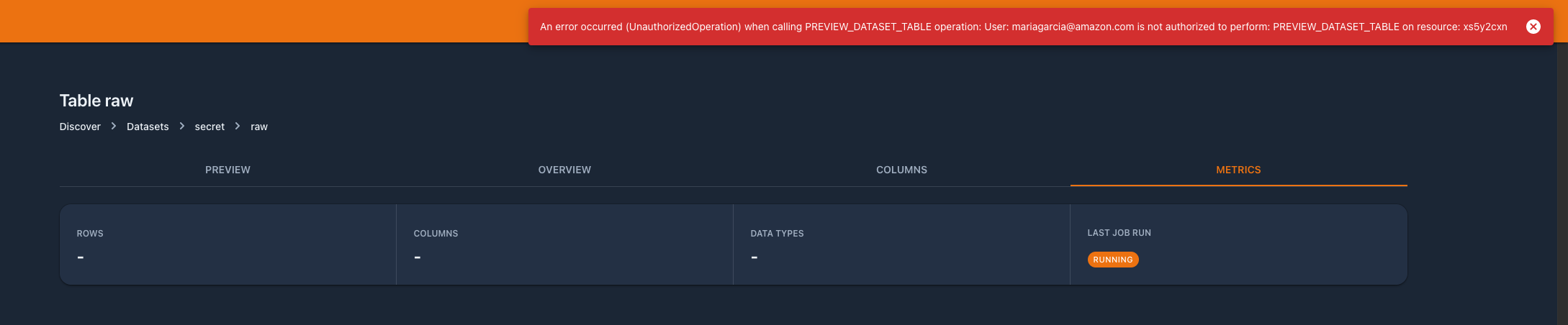 ### Relates - #478 By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
### Feature or Bugfix - Refactoring ### Detail The resulting IAM policy can: - list all buckets - read and write objects to the dataset Bucket which is encrypted - read S3 access points in the dataset Bucket - putLogs in dataset Glue crawler log group - read dataset Glue database, read and write tables in the dataset Glue database. This is not strictly necessary as in data.all permission to data is handled using Lake Formation. But restricting the IAM-based data permissions we ensure that any Glue resource that is not protected using Lake Formation is not accessible by this role - WIP - read objects to the `/profiling/code` prefix in the environment bucket - WIP - read and write objects to the `/profiling/code/results/datasetUri/` prefix in the environment bucket IMPORTANT: I found a bug related to profiling jobs that prevented me to test the profiling jobs. A separate [issue](#506) has been opened for it. For this reason the profiling permissions are a work in progress and might require changes. e.g. additional KMS permissions. It cannot: - read or write to any other S3 Bucket - use any KMS key different from the dataset KMS key - read or write any other Glue database/tables In addition, the Glue crawler and the profiling Job of the dataset have been modified to always use the dataset role and not the PivotRole to break down the "super permissions" of the pivot role and distribute responsibilities. As a result, the dataset role can be assumed: - by the pivotRole -> used whenever users are assuming the role from data.all UI - by Glue -> to run Glue profiling jobs and Glue crawler ### Relates - #461 By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license. --------- Co-authored-by: Gezim Musliaj <102723839+gmuslia@users.noreply.github.com>
### Feature or Bugfix - Bugfix ### Detail - Add urllib3 supported version for Glue Profiling Job ### Relates - [#506 ] By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
### Feature or Bugfix - Feature ### Detail - Expose the Share Request Comments as Part of the Share View for the Approver to See - Allow Approver to Provide Comments when Rejecting a Share for the Requester to See ### Relates - [#422 ] By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
…se headers (#529) ### Feature or Bugfix - Feature ### Detail To avoid the following attacks: cross site scripting, click-hijacking, + also MIME type sniffing, the security response headers have been added to all cloudfront distribution. Since cloudfront's `CloudFrontWebDistribution` is not supporting response policies (it can only be done by escape hatches), all distribution have been migrated to `Distribution` interface. Along with that, the legacy caching was migrated to `CACHE_OPTIMIZED` which is recommended for S3 origins. The headers in the documentation distribution: By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license. --------- Co-authored-by: chamcca <40579012+chamcca@users.noreply.github.com> Co-authored-by: dlpzx <71252798+dlpzx@users.noreply.github.com>
We should avoid possible connection injection. To do so, we have to sanitize and validate inputs for the database
…d datasets (#515) ### Feature or Bugfix - Feature ### Detail With this PR, the IAM policies for the environment admin group and for environment invited groups, are generated in the same way. We remove unnecessary duplicities and use a single method to create both. The resulting role has been hardened and its policies restricted. The following sheet contains the analysis of the 2 types of roles and the measures taken to restrict the policies. [DataallEnvRolesAnalysis.xlsx](https://github.com/awslabs/aws-dataall/files/11732639/DataallEnvRolesAnalysis.xlsx) As a summary: - restricted access to S3 buckets and KMS keys to the Team-owned datasets only - restricted access to environment s3 bucket, athenaqueries result of the team only - restricted trust policies to Glue and iam:PassRole to Lambda, Glue, StepFunctions, Databrew and SageMaker - restricted creation and access to resources of any type: all must be tagged with tag `Team=teamname` and prefixed by the environment specified `resource_prefix` - removed unused Redshift policies and created new service policies (ssm, secretsmanager, athena) to clearly differenciate policies. To restrict access to KMS keys, we had to introduce a KMS Alias field in the importing dataset form, allowing customers to import existing KMS keys. The necessary database and graphql fields were already in place, we just made it available as input of the imported dataset. It adds a check to import the KMS resource, in case the KMS key does not exists the stack deployment will fail. In this PR we also modify the frontend views to show the KMS alias in imported datasets.  Userguide documentation has been updated: 1) add KMS import information in datasets 2) description of dataset IAM role - usage, policies, data access 3) description of env roles - usage, policies, data access Finally, the CloudFormation output giving the pivotRole name has been updated to be more specific to the environment and allow multiple environments being deployed in the same account/region (not recommended, but might be needed in some customers) ### Relates - #462 By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
### Feature or Bugfix <!-- please choose --> - Feature ### Detail - Restricting KMS Key Policies This PR restricts the KMS Keys created in Data.all Environments (i.e. linked AWS Accounts), including - Environment KMS Keys (Used for subscriptions and Custom Resources) - Dataset KMS Keys (To Encrypt Data in S3) - Notebook KMS Keys (To Encrypt SageMaker Notebook Instance Storage Volumes) - SageMaker Studio KMS Keys (To Encrypt SageMaker Studio Storage Volumes) Additional as part of this PR: - Consolidate Environment Keys - Reduce 4 KMS Keys to 1 Key to Encrypt all SQS DLQs used for Lambda Custom Resource Failed Invocations - Reduce 3 KMS Keys to 1 Key to Encrypt SNS and SQS Resources related to Environment Subscriptions - Remove Unused Custom Resources - Remove Glue DB No Delete Custom Resource (this is no longer used and is replaced by Glue DB Custom Resource which additionally handles deletes of Glue DBs) - Remove Data Location CustomResource (this is no longer used and is replaced by CfnResource used to register S3 location in LakeFormation) - Remove KMS Key Permissions in Environment Roles where applicable - Since we are restricting KMS Key Permissions we do not need to explicitly give KMS Permissions to IAM Roles for Env Group Roles where the dataset is created by data.all (if the dataset is imported we still add KMS Permissions to the IAM Role) ### Relates - [#512 ] By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license. --------- Co-authored-by: dlpzx <dlpzx@amazon.com>
### Feature or Bugfix - Feature ### Detail - Restrict trust policy to backend compute IAM roles only (instead of full root central account) - Restrict KMS permissions to just encrypt/decrypt and list keys - Restrict CloudFormation permissions to describe and deleteStack (remove the need of PassRole) - Restrict Athena to the bare minimum to run preview and worksheets - Restrict EC2 to describe actions only - Remove LakeFormation registering (now in CloudFormation) and Transaction policies (deprecated) - Remove Organisations and tag resources (unused) - Remove Redshift and DataBrew (unused) - Remove StepFunctions, CodePipelines, ECR and Lambda (unused) ### Relates - #491 ### Testing with `dataallPivotRole-cdk` I verified that there are not error logs in CloudWatch for graphql, worker and ecs log-groups - [X] Link environment with pivot_role_auto_create enabled, `dataallPivotRole-cdk` gets created successfully - [X] Get credentials and url from Environment-Teams tab - [X] See CloudFormation resources in stack tab and logs in logs - [X] Import consumption role - [X] Create Dataset - [ ] Import Dataset - there is an issue fixed in #515 - [X] Get credentials and url from Dataset menu - [X] Start crawler - [X] Sync tables - [X] Preview tables - [X] Use Worksheets to query tables - [X] Start profiling job - [X] Create Folder - [X] Share tables and Folders - [X] Revoke tables and folders until completely cleaned up and delete share - [X] Delete dataset - [X] Create Notebook - [X] Start and Stop Notebook - [X] Open Jupyter - [x] Delete Notebook - [X] Create ML Studio user, open ML Studio - [x] Delete ML Studio user - [X] Create pipelines of all types - [X] Get credentials for pipelines - [x] Delete pipelines of all types - [X] Start Quicksight session (GetAuthorSession) - [ ] Import dashboard and see embedded dashboard - we need to look at the reader session authorization issue - check the fix from BT - [X] Share dashboard and see embedded dashboard By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
### Feature or Bugfix - Feature ### Detail - Replace NACL Rules on VPC Subnet with individual security groups defined for the backend VPC as restrictive as possible, allowing only the needed traffic. ### Relates - #487 By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license. --------- Co-authored-by: chamcca <40579012+chamcca@users.noreply.github.com> Co-authored-by: dlpzx <71252798+dlpzx@users.noreply.github.com> Co-authored-by: Nikita Podshivalov <nikpodsh@amazon.com>
### Feature or Bugfix - Bugfix ### Detail - When updating the dataset database handler custom resource to use a different PhysicalId to distinguish imported datasets CloudFormation forces a replacement of the resource which results in the deletion of the glue database. With this PR we add a condition to only delete databases when the custom resource physical id is prefixed by "CREATED-". - Force that Glue crawlers ccreated by data.all use the dataset IAM role as execution role. Previously a boto3 call updated this to use the pivotRole (contrary to what it was defined in CloudFormation). With this PR we make sure that the correct role is used in any existing crawler. I tested in a real AWS deployment that had previously created environments and datasets, with a crawler with the pivotRole assigned: - [X] Crawler execution role gets updated to dataset role - [X] Imported glue databases do not get deleted when the custom resource updates the physicalID ### Relates - #531 By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
|
During validation 2 issues where found:
I will work on this items today @noah-paige. We can meet later to discuss on them |
### Feature or Bugfix - Feature - Bugfix ### Detail #### SSE-S3 for imported datasets With #515 we added the possibility to introduce the KMS key that encrypts the imported bucket when importing a dataset. This is a required field that cannot be empty. In this PR we allow customers to leave the field empty for the case in which no KMS key is used. We assume that if no key is defined, then the bucket is encrypted using SSE-S3 encryption. - changes in frontend views - changes in definition of RDS column values - added line in migration script to backfill `undefined` keys with the `undefined` value for previously imported datasets. #### Rename imported dataset resources In #535 the permissions given to the pivot role were restricted to more specific resources. Most policies where updated to access `resource-prefix` AWS resources only. For imported datasets some of the data.all created resources in the dataset stack (Glue crawler ....) do not follow this naming pattern. In this PR we update the name of those resources to include the prefix. This way the pivot role will be able to execute actions on them. - Added naming convention pattern - Enforce pattern in dataset import - Added migration script to update the names of existing imported datasets⚠️ After the migration script is executed, dataset stacks need to be updated for the AWS resources to be updated⚠️ ### Testing - in-progress I tested locally, but now I am also testing in a real deployment: - [ ] CICD pipeline completes successfully - [ ] KMS RDS info updated as expected - [ ] KMS RDS info of new created and imported datasets as expected - [ ] CloudFormation stacks of updated stacks of imported and created datasets successful (resources updated) - [ ] CloudFormation stacks of new stacks of imported and created datasets successful (resources prefixed) - [ ] Crawlers can be run for all dataset cases ### Relates - #535 - #515 By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
### Feature or Bugfix - Bugfix ### Detail - missing definition of field in Dataset class results in skipping one of the RDS updates (for GlueCrawler name) ### Relates Release v1.6 By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
…573) ### Feature or Bugfix - Feature - Bugfix ### Detail - Allow Traffic to other AWS Regions to support Data All resources in other regions (e.g. Deployment in `us-east-1` and Link Environment in `us-west-2`) - Based on Route Priority in AWS [Docs](https://docs.aws.amazon.com/vpc/latest/userguide/VPC_Route_Tables.html#route-tables-priority) routes will prioritize the most specific CIDR Blocks first as preferred method of traffic - Same region resources as the deployment account region should defer to private communication while deployment of resources to regions different from the deployment region will be able to use NAT Gateway from the private subnet to deploy the stacks - Alternative to this solution is to specify VPC Endpoints for every Region where data all related resources could/would be deployed to By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license. --------- Co-authored-by: dlpzx <dlpzx@amazon.com>
…#579) ### Feature or Bugfix - Feature - Bugfix ### Detail - For cross-account shares of data all tables using LF named resources and RAM for share invitations we require `glue:PutResourcePolicy` and `glue:DeleteResourcePolicy` permissions for the pivotRoles handling management of RAM share invitations - Without the above permissions - the sharing of tables cross-account to other data.all environments failed with a similar error to the following: ``` Failed granting principal arn:aws:iam::ACCOUNT_A:role/TARGET_ROLE read access to resource link on target ACCOUNT_B://GLUE_DB/TABLE_NAME due to: An error occurred (AccessDeniedException) when calling the GrantPermissions operation: Insufficient Glue permissions to access table TABLE_NAME ``` By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
### Feature or Bugfix - Feature ### Detail - Allow edition of KMS key alias for imported datasets that were created before v1.6.0 - Added check for imported KMS key alias - Added check in data policy of env roles - Fixed tests ### Relates - #515 By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
…lines stacks (#582) Workaround for cookiecutter file writes to root filesystem, which occurs during creation of datapipelines. ### Feature or Bugfix - Bugfix ### Detail Cookiecutter is used by DDK to generate a sample project. However it tries to write to the root file system which conflicts with our "read-only" settings on root. This PR modifies the settings of cookiecutter to write to `/dataall` instead ### Relates - #523 By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license. --------- Co-authored-by: dlpzx <dlpzx@amazon.com>
### Feature - Feature ### Detail - UI changes to provide CloudFormation stack Yaml file to create custom IAM policy with least privileges for bootstrapping CDK in linked environments. By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
### Feature or Bugfix - Bugfix ### Detail - Renamed resource to avoid duplicated resource names in CloudFormation ### Relates - #562 By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.
noah-paige
approved these changes
Jul 19, 2023
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Feature or Bugfix
Release PR with the following list of features. Refer to each PR for the details
Detail
Breaking changes - release notes
enable_update_dataall_stacks_in_cicd_pipeline, waiting for overnight update stack task, or manually updating first environments and then datasetsRelates
V1.6.0 release
By submitting this pull request, I confirm that my contribution is made under the terms of the Apache 2.0 license.