Machine Learning
(Some of these issues may be closed or open/in progress.)
Congratulations on taking a big step toward becoming a machine learning practitioner! In addition to working with the provided material, be sure to take advantage of all of the learning support available to you, including tips from other experts in machine learning. While this guide should be enough to get you up and running, not every single term and concept is defined or explained for brevity. You should Google things you don't understand when you encounter that. One good way to learn more is to click on the links for the images. Some quality articles are linked. This guide explains Machine Learning and encourages you to use a chatbot (LLM) to guide your research and generate the code needed at each step.
Machine Learning is a way of taking data and turning it into insights. We use computer power to analyze examples from the past to build a model that can classify or predict the result for new examples. We encounter machine learning models every day. For example, when Netflix recommends a show to you, they use a model based on what you and other users have watched to predict what you would like. When Amazon chooses a price for an item, they use a model based on how similar items have sold in the past. When your credit card company calls you because of suspicious activity, they use a model based on your past activity to recognize anomalous behavior.
The formal definition of Machine Learning is "to perform a task or calculation without an explicit program". That is, machine learning does not proceed with rules that lead to a determined outcome. Instead, mathematical algorithms are trained on data that then can predict the class or value of unseen data when it is passed to a trained model.
Note
One thing this guide does not cover is the Python code. To make use of this guide you should already have basic python programming skills. You need to be able to look at the code and understand what it is doing. The comments in the code that come out of the LLM will help you and usually clear things up. Often the bugs you encounter will be simple: the wrong file location, wrong variable name, etc...these are things the chatbot may have trouble tracking. It is always faster to correct the chatbot rather than correct the code in your notebook, this way the code is easily copied and pasted back into your notebook over several iterations when you tell it to make changes. Feel free to paste back in the exact snippet you are talking about for changes. For instance, your use of "this code" may mean the whole code base rather than the snippet in question when you prompt an LLM, depending on what it is thinking, so BE SPECIFIC, as always, for what you want back from the LLM.
In this Wiki we will cover the ML process and lifecycle, starting from the beginning and proceeding in order through the steps necessary to get an ML system working. They are:
- Problem Statement/Requirements
- Data, EDA, and Preprocessing
- Feature Engineering and Feature Selection
- Model Training and Selection
- Hyperparameter Tuning and Model Evaluation
- Deployment
- Post-Deployment
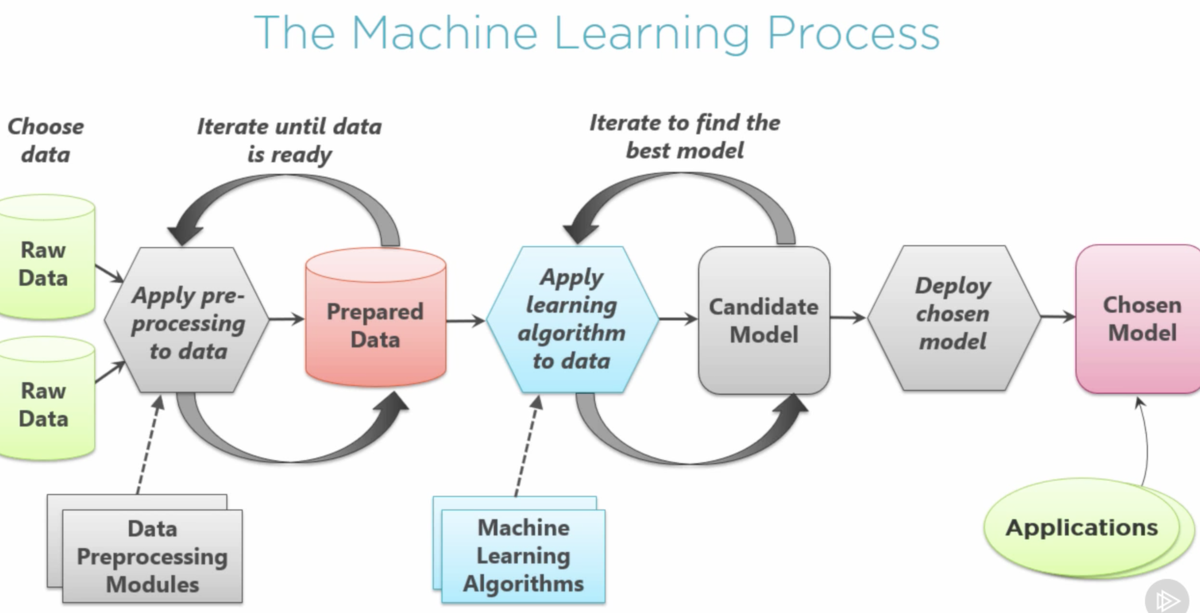
Image 1: The ML Process steps 2-6
Image Credit: Link 1 (see bottom)
Each section will have an outline consisting of tasks and questions to ask, and sometimes some sample code. What is important is to grasp the principles. Other manuals on machine learning may have a different number of steps but I have combined them in a rational way so you only have 7 to memorize. Today Machine Learning projects are done very easily with the use of ChatGPT or another LLM so there will be some discussion about how to do this interleaved into the detailed steps of the ML process. When you are done with this wiki you will be able to take a pool of data, and head over to ChatGPT to generate code to create a dataset, perform steps 1-7 and get a model ready to perform predictions, also known as inference. The idea is to read the Wiki start to finish ONCE, then use it thereafter as structure for working with an LLM on each step one at a time.
Important
In the outlines to follow, the list of tasks is comprehensive. You may not need to perform ALL of the tasks listed in each step (because some are optional, like PCA), but you SHOULD ask all the critical questions listed below to make sure you have done a thorough job. The answers to the questions provided in each step will guide you to which tasks are required, and which are optional, for your project. BUT, not all critical questions are listed because it depends on the project. When in doubt, ask if a particular task applies to your research question.
Here's an example LLM prompt I use all the time:
ChatGPT Prompt:
**"Hello, today we will be generating a research plan for answering the problem posed in the uploaded requirements document.
Please apply the following process (Shift+Enter, then paste in a copy of this wiki, then Shift+Enter) to that document to generate a detailed plan while paying attention to what tasks are required and which are optional given this general description of the data we have:**
**(list the column titles of your data pool)"**
Submit that prompt to get the iterative process started working with an LLM.
Take note of this prompt you will be using it when you reach Step 2, after the requirements are documented.
LLMs have a tendency to summarize in their responses unless you specify what you want returned. The trick is to get a detailed outline of your problem, including steps, and then ask for code one step at a time, pasting the step outline back in to create detailed code:
LLM ML technique:
A) Generate Requirements
B) Use that and this wiki to generate an outline for your project
C) Paste in pieces of the project outline and pieces of this ML Wiki (again) to generate code
D) Construct a Jupyter notebook one section at a time being flexible so you answer the research question with insights, OR...
E) Train up and evaluate a model to use in online inference
Let's start with a brief description of each of these 7 steps:
Define the business problem, success metrics, and project scope. Determine whether you need supervised, unsupervised, or reinforcement learning. Establish performance benchmarks and constraints like latency, accuracy requirements, and resource limitations (and more).
Image 2: Requirements Gathering Techniques
Image Credit: Link 2
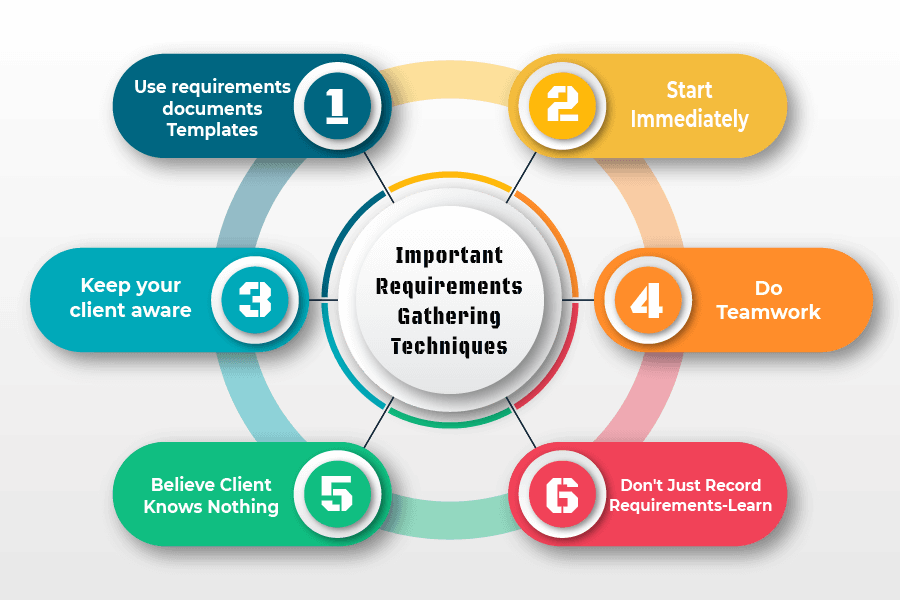
Image 3: Why Requirements Gathering is Important
Image Credit: Link 3

Gather relevant datasets from internal systems, public sources, or third-party providers while ensuring legal compliance and data quality. Perform exploratory data analysis to understand distributions, patterns, and anomalies. Handle missing values, remove duplicates, normalize numerical features, and encode categorical variables appropriately. It's very important to scale features that fall in a range far outside the range of other variables. Scaling is just generally good practice for an ML to learn better and makes training much faster.
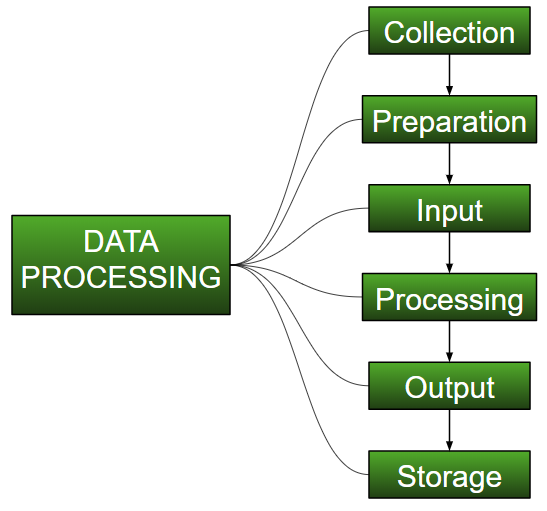
Image 4: The Data Process in ML
Image Credit: Link 4
-Data Splitting happens here: Here you divide your dataset into training, validation, and test sets with proper stratification for classification problems and time-based splits for temporal data. The training set is to prepare and teach the model, the validation set is to tune the model, and the test set is provide the final performance metrics of how the model is doing. The usual split is 50-80% training data and 10-25% each for the validation and test sets. What's not included here? Unseen data. This is the data that will come in later on during deployment when the model is actually in service. Data splitting has to happen before feature scaling so there isn't data leakage of the test set characteristics into the training data. Basically scaling and/or normalization is the last thing you do before moving on to 3, engineering features.
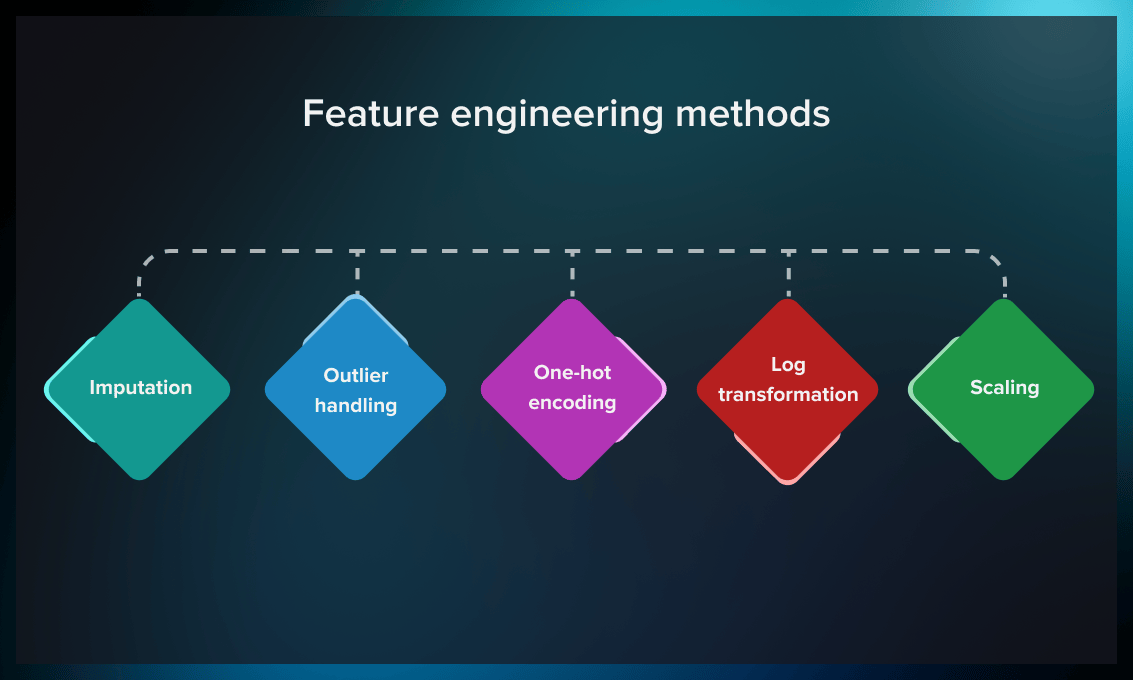
Create new features from existing data through transformations, combinations, or domain-specific calculations. Generate polynomial features, interaction terms, or time-based features as relevant to your problem. Identify the most relevant features using statistical tests, correlation analysis, or model-based importance scores, removing redundant or irrelevant features to improve model performance. Here you should measure feature importance using tools such as a correlation matrix, mutual information scores, and Random Forest rankings. Once you have this you can do Recursive Feature Elimination as you move into step 4 (the model needs to be in training).
Image 5: Feature Engineering Phases
Image Credit: Link 5
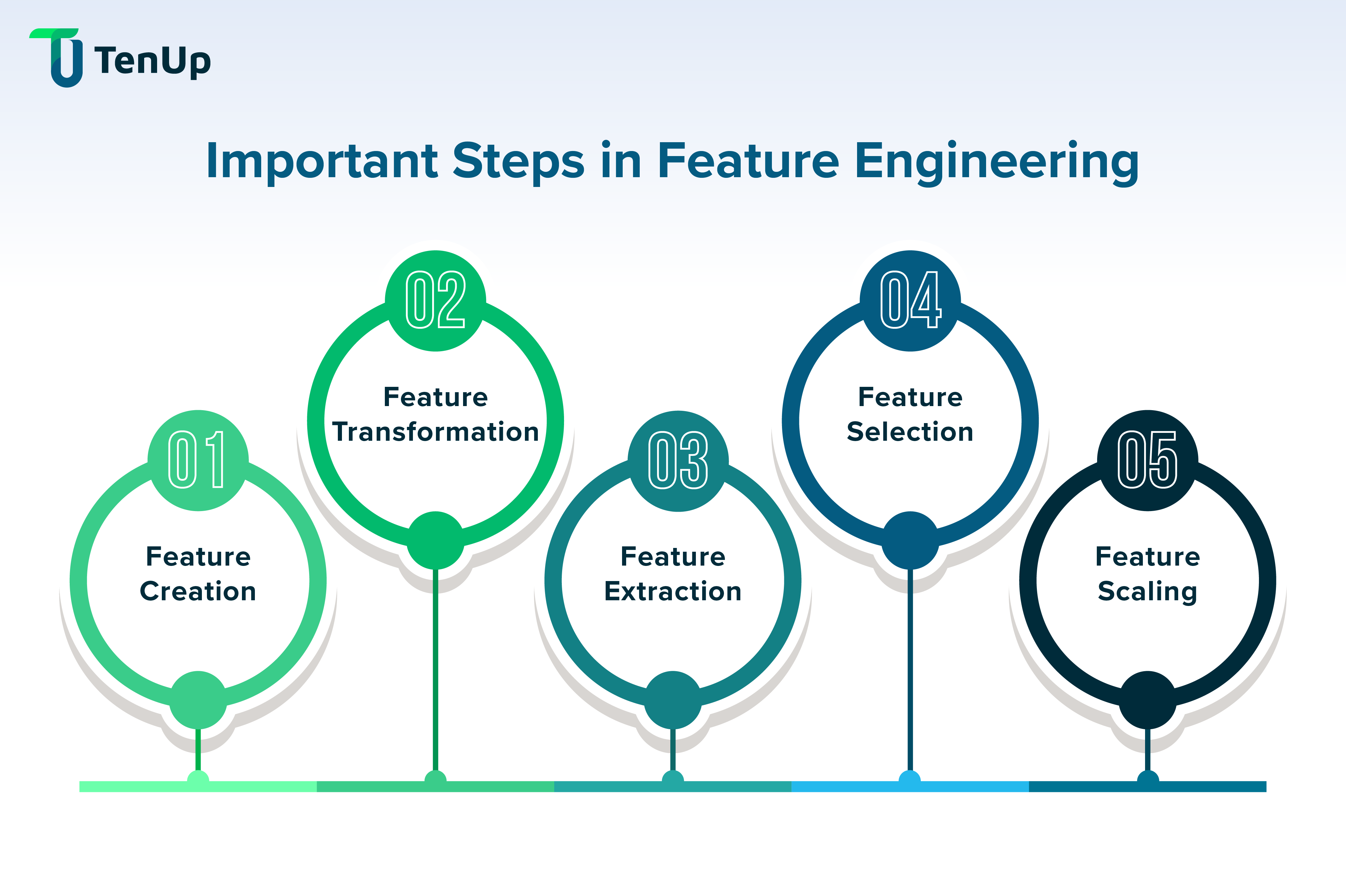
Image 6: Some Feature Engineering Techniques
Image Credit: Link 6
Choose appropriate algorithms based on your problem type, data size, and interpretability requirements. Train multiple candidate models including linear models, tree-based methods, and neural networks, comparing test set results.
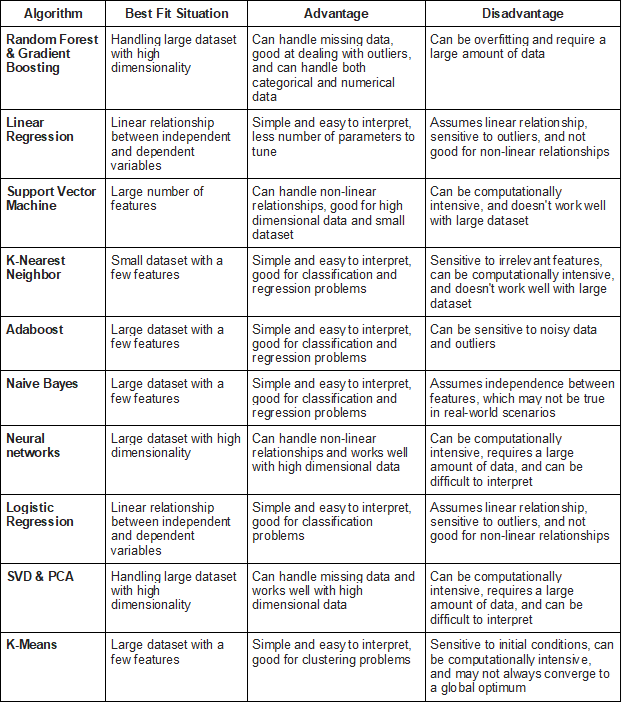
Table 1: Some of the Most Popular ML Models
*Image Credit: Model Selection at ProjectPRo

Image 7: Model Selection SEQUENTIAL Process (Each step in order)
Image Credit: Link 7
Optimize model parameters using techniques like grid search, random search, or Bayesian optimization with cross-validation to ensure robust parameter selection. Assess model performance using appropriate metrics and compare models using statistical tests, considering business-relevant metrics beyond accuracy. Understand feature importance, model predictions, and potential biases while validating model behavior on edge cases to ensure results align with domain knowledge and business logic. There is also a special data splitting technique called K-Fold cross validation that works well for hyperparameter tuning, where the data is split into k folds where k = 5 to 10 usually. More information at the below links:

Image 8: Data Mining for Model evaluation
Image Credit: Link 8
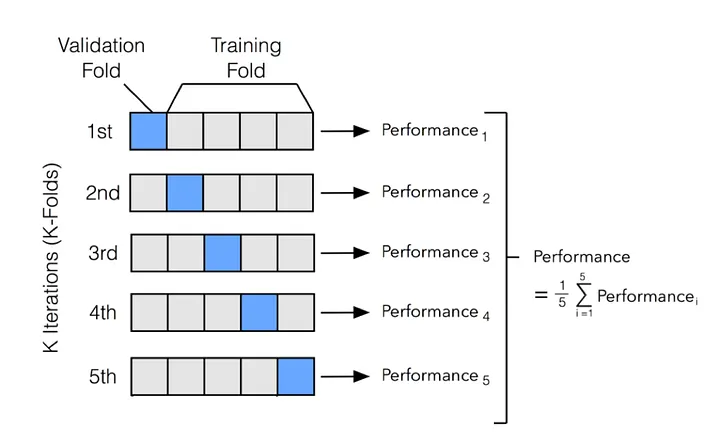
Image 9: K-Fold Cross Validation
Image Credit: Link 9
There is also a variant of K-Fold validation for multi-class or imbalanced class problems called Stratified K-Fold that is important to use for your model to learn correctly when trained for these problems. This preserves the class proportions across all folds:

Image 10: Stratified K-Fold Cross-Validation
Image Credit: Link 10
When datasets are small, we use a technique called "Leave-One-Out Validation", which you can read about at the above link if you are facing that problem, for instance, if your dataset is only 100 observations or fewer.
Deploy the model to production environments using appropriate infrastructure. Implement APIs, batch processing pipelines, or real-time serving systems. Consider scalability and security requirements. You may also want to containerize your app/model with Docker to ensure portability and reproducibility.

Image 11: Online Deployment Overview
Image Credit: Link 11
Don't be daunted by the above diagram, this only applies to deploying an online inference service. You may not need to do that.
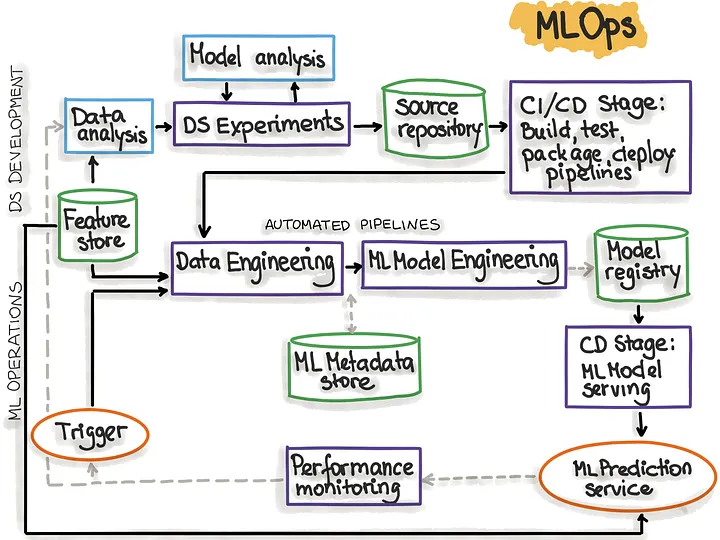
Image 12: MLOps Overview
Image Credit: Link 12
Monitor model performance, data drift, and system health in production with alerts for performance degradation. Establish procedures for model retraining and updates. Document the entire pipeline, model assumptions, and deployment procedures while maintaining version control, testing protocols, and regulatory compliance.
Image 13: The Post-Deployment Monitoring Workflow
Image Credit: Link 13
.jpg)
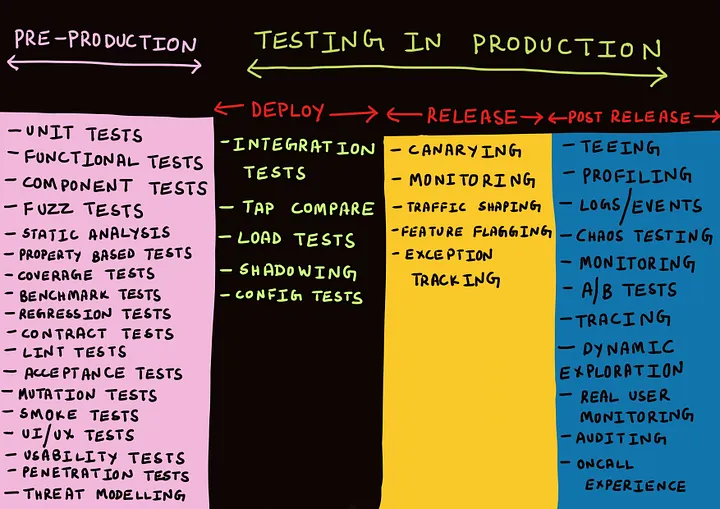
Image 14: Post-Deployment Tests
Image Credit: Link 14
Now let's look deeper into each section with an eye to detail.
Specific implementation procedures (and code) will come out of your chats with the LLM and online research.
What are you trying to prove? What are you trying to do? Usually the task of the Machine Learning Engineer is to answer the questions posed by the Data Scientist and the Data Engineer. Once the question has been answered, a trained model can be put into service to perform some task that is usually integrated into an app or online workflow.
It's important to ask a lot of questions upfront about what/who/when and especially WHY are we seeking to create predictions. There are functional and non-functional requirements:
Functional requirements define what a system should do - the specific behaviors, features, and capabilities it must provide. They describe the system's functionality from the user's perspective and answer "what" the system needs to accomplish.
Examples of functional requirements:
- A user must be able to log in with username and password
- The system shall calculate tax based on current rates
- Users can search products by category, price range, or keyword
- The application must generate monthly sales reports
- Customers can add items to a shopping cart and checkout
Non-functional requirements define how a system should perform - the quality attributes, constraints, and criteria that determine how well the system operates. They describe the system's performance characteristics and answer "how well" the system should work.
Examples of non-functional requirements:
- The system must respond to user requests within 2 seconds (performance)
- The application should be available 99.9% of the time (reliability)
- The system must handle 10,000 concurrent users (scalability)
- All data must be encrypted during transmission (security)
- The interface should be intuitive for users with basic computer skills (usability)
- The system must work on Windows, Mac, and Linux (compatibility)
Key differences:
Functional requirements are typically easier to test with clear pass/fail criteria - either the login feature works or it doesn't. Non-functional requirements often involve measurable thresholds and can be more subjective - determining if something is "user-friendly enough" requires more nuanced evaluation.
Both types are crucial for successful system development. Functional requirements ensure the system does what users need, while non-functional requirements ensure it does so in an acceptable manner that meets business and technical constraints.
Remember you want to start from the kind of questions the stakeholders were (or should have been) asked: What is your need? want? current experience, complaints, etc.? Stakeholders include Hack For LA, owners, users, vendors, third parties, etc. Also keep in mind you should specify your proposed research approaches to finding the best way to answer the question, and which technology solutions you are considering so that when you present the requirements write-up to the team or a superior for feedback you can get perspective. It's very important to get feedback if you can from your users or future users (and in an agile way if possible) and proceed from that input.
An important non-functional requirement is determining the necessary performance level of the system. What is the sufficient level of accuracy (for balanced classes questions), F1 accuracy score (for imbalanced classes when False Positives and False Negatives are equally important) or FBeta score (when False Positives or False Negatives have one more important than another there is a weighting included called Beta)? Remember:
These are the four outcomes in a binary classification confusion matrix:
True Positive (TP): The model correctly predicted the positive class. The actual label was positive, and the model predicted positive.
- Example: A spam detector correctly identifies an email as spam when it actually is spam.
True Negative (TN): The model correctly predicted the negative class. The actual label was negative, and the model predicted negative.
- Example: A spam detector correctly identifies an email as not spam when it actually isn't spam.
False Positive (FP): The model incorrectly predicted the positive class. The actual label was negative, but the model predicted positive. Also called a "Type I error."
- Example: A spam detector incorrectly flags a legitimate email as spam.
False Negative (FN): The model incorrectly predicted the negative class. The actual label was positive, but the model predicted negative. Also called a "Type II error."
- Example: A spam detector fails to identify an actual spam email, letting it through to the inbox.
Visual representation is called a "Confusion Matrix":
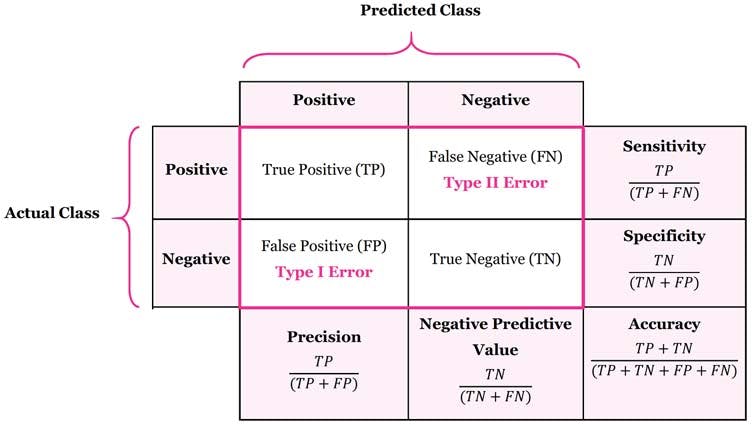
Table 2: A Confusion Matrix
Image Credit: Confusion Matrix by Manisha Sirsat
These metrics form the foundation for calculating important evaluation measures like:
- Accuracy = (TP + TN) / (TP + TN + FP + FN) measures overall correctness of predictions.
- Precision = TP / (TP + FP) measures how many positive predictions were actually correct.
- Recall (Sensitivity) = TP / (TP + FN) measures how many of the actual positives were correctly identified.
- Specificity = TN / (TN + FP) measures how many actual negatives were correctly identified.
The relative importance of minimizing FP versus FN depends on your specific use case and the costs associated with each type of error. So the performance level required of your model can be dictated by any of the above metrics, individually or in conjunction. Also, performance is typically measured in custom metrics, or in metrics that matter to the project, as in dollars and cents or click-throughs, transactions, conversions, etc.
Now that we have had a general discussion of the aims of step 1, let's look at a detailed breakdown:
Objective: Clearly articulate the business challenge and translate it into a well-defined machine learning problem.
Key Tasks:
- Stakeholder Interviews: Conduct comprehensive discussions with business users, domain experts, and decision-makers
- Problem Statement Formulation: Write clear, specific problem statements that avoid ambiguity
- Business Impact Assessment: Quantify the potential value and cost of solving (or not solving) the problem
- Current State Analysis: Document existing processes, tools, and decision-making approaches
- Root Cause Investigation: Ensure ML is addressing the actual problem, not just symptoms
- Scope Boundary Definition: Clearly define what is and isn't included in the project scope
- Feasibility Assessment: Evaluate technical and business feasibility before committing resources
Critical Questions to Ask:
- What specific business decision or process are we trying to improve?
- How is this problem currently being solved, and what are the limitations?
- What would "success" look like from a business perspective?
- Are we solving the right problem, or should we be addressing something upstream?
- Do we have stakeholder buy-in and sufficient resources to see this through?
- What are the consequences of inaction or delayed implementation?
Objective: Determine the most appropriate machine learning approach based on available data and desired outcomes.
Key Tasks:
- Supervised Learning Assessment: Evaluate if you have labeled data for classification or regression problems
- Unsupervised Learning Consideration: Determine if pattern discovery, clustering, or dimensionality reduction is needed
- Reinforcement Learning Evaluation: Assess if the problem involves sequential decision-making with feedback
- Semi-Supervised Options: Consider hybrid approaches when labeled data is limited
- Transfer Learning Opportunities: Identify if pre-trained models or domain knowledge can be leveraged
- Online vs Batch Learning: Decide if the model needs to learn continuously from streaming data
- Active Learning Potential: Evaluate if strategic data labeling can improve efficiency
Critical Questions to Ask:
- Do we have sufficient labeled examples for supervised learning?
- Are we trying to discover hidden patterns or predict specific outcomes?
- Does our problem involve sequential decision-making with delayed rewards?
- Can we leverage existing models or knowledge from related domains?
- How frequently will we need to retrain or update our model?
- What's our strategy for acquiring more labeled data if needed?
Objective: Establish clear, measurable criteria for evaluating model and business success.
Key Tasks:
- Business Metrics Identification: Define how success will be measured in business terms (revenue, cost savings, efficiency gains)
- Technical Metrics Selection: Choose appropriate ML metrics (accuracy, precision, recall, F1, AUC, RMSE, MAE)
- Baseline Establishment: Determine current performance levels and minimum acceptable improvements
- Metric Prioritization: Rank metrics by importance when trade-offs are necessary
- Success Threshold Definition: Set specific, achievable targets for each metric
- Measurement Framework: Establish how and when metrics will be calculated and reported
- Long-term vs Short-term Goals: Balance immediate wins with sustainable long-term performance
Critical Questions to Ask:
- What business outcomes will demonstrate that our ML solution is successful?
- Which technical metrics best correlate with business value in our use case?
- What's our current baseline performance, and what improvement would be meaningful?
- How do we handle conflicting objectives (e.g., accuracy vs. interpretability)?
- What constitutes "good enough" performance to justify deployment?
- How will we measure success over time as conditions change?
Objective: Define operational requirements and constraints that will shape model design and deployment decisions.
Key Tasks:
- Latency Requirements: Specify acceptable response times for predictions (real-time, near real-time, batch)
- Accuracy Thresholds: Establish minimum performance levels across different metrics
- Scalability Needs: Define expected volume of predictions and growth projections
- Resource Constraints: Document computational, memory, and storage limitations
- Interpretability Requirements: Determine level of model explainability needed for business acceptance
- Compliance & Regulatory: Identify legal, ethical, and regulatory constraints
- Integration Constraints: Assess existing system limitations and integration requirements
- Budget & Timeline: Establish project constraints and resource allocation
Critical Questions to Ask:
- What's the maximum acceptable latency for predictions in our use case?
- Are there hard accuracy requirements we cannot compromise on?
- How many predictions per second/day do we need to support?
- What computational resources are available for training and inference?
- Do regulatory requirements limit our choice of algorithms or data usage?
- How interpretable does our model need to be for business stakeholders?
- What's our budget and timeline for this project?
Objective: Evaluate data assets and identify gaps between current state and modeling needs.
Key Tasks:
- Data Inventory: Catalog all available internal and external data sources
- Data Quality Preliminary Assessment: Evaluate completeness, accuracy, and consistency of key datasets
- Feature Brainstorming: Identify potential predictive variables based on domain knowledge
- Data Gap Analysis: Determine what additional data might be needed for success
- Data Access & Permissions: Ensure legal and technical ability to access required data
- Historical Data Availability: Assess depth and breadth of historical data for training
- Real-time Data Feasibility: Evaluate ability to obtain features at prediction time
Critical Questions to Ask:
- Do we have enough relevant, high-quality data to build a reliable model?
- What are our most promising data sources and potential features?
- Are there critical data gaps that could undermine the project?
- Can we legally and ethically use all the data we've identified?
- How far back does our historical data go, and is it representative?
- Will all the features we want to use be available when making real predictions?
Objective: Identify potential project risks and develop strategies to address them proactively.
Key Tasks:
- Technical Risk Identification: Assess risks related to data quality, model performance, and technical implementation
- Business Risk Evaluation: Consider risks to business operations, reputation, and strategic objectives
- Ethical & Bias Risk Analysis: Evaluate potential for algorithmic bias and unfair outcomes
- Regulatory & Compliance Risk: Assess legal and regulatory risks associated with the ML solution
- Resource Risk Assessment: Consider risks related to timeline, budget, and personnel availability
- Mitigation Strategy Development: Create specific action plans for high-probability, high-impact risks
- Contingency Planning: Develop alternative approaches if primary strategy fails
Critical Questions to Ask:
- What could go wrong with this project, and how likely are these scenarios?
- Are there ethical concerns or potential biases we need to address?
- What happens if our model doesn't achieve the required performance?
- Do we have regulatory or legal risks that could derail the project?
- Are there alternative approaches if our primary strategy doesn't work?
- How will we monitor and respond to risks as they emerge?
Objective: Develop a realistic project plan with appropriate resource allocation and timeline.
Key Tasks:
- Phase & Milestone Definition: Break the project into manageable phases with clear deliverables
- Resource Requirements: Determine personnel, computational, and financial resource needs
- Timeline Development: Create realistic timelines with appropriate buffers for each phase
- Team Assembly: Identify required skills and assemble appropriate team members
- Tool & Infrastructure Planning: Determine required tools, platforms, and infrastructure
- Stakeholder Communication Plan: Establish regular reporting and review processes
- Change Management Strategy: Plan for organizational adoption and change management
Critical Questions to Ask:
- Do we have the right team with appropriate skills for this project?
- Is our timeline realistic given the scope and complexity of the problem?
- What tools and infrastructure do we need to be successful?
- How will we keep stakeholders engaged and informed throughout the project?
- What organizational changes will be needed to adopt our ML solution?
- How will we handle scope creep and changing requirements?
Objective: Ensure all stakeholders understand and agree on project objectives, approach, and expectations.
Key Tasks:
- Requirements Documentation: Create comprehensive documentation of all requirements and constraints
- Stakeholder Review Sessions: Conduct formal reviews with all key stakeholders
- Expectation Management: Ensure realistic expectations about outcomes, timeline, and limitations
- Success Criteria Validation: Confirm all parties agree on how success will be measured
- Resource Commitment: Secure formal commitment of required resources and support
- Communication Protocol: Establish ongoing communication and reporting processes
- Project Charter Approval: Obtain formal sign-off to proceed with the ML project
Critical Questions to Ask:
- Do all stakeholders have a shared understanding of project goals and approach?
- Are expectations realistic and aligned with what's technically feasible?
- Have we secured the necessary resources and organizational support?
- Is there clear agreement on success criteria and evaluation methods?
- Are we ready to commit to this project and move forward with data collection?
- What are our criteria for stopping or pivoting if things don't go as planned?
Critical Transition Point: At this stage, you should have a well-defined problem with clear success criteria, appropriate learning paradigm, realistic constraints, and stakeholder buy-in. This foundation is crucial because changes to requirements after data collection and model development begins can be extremely costly. The clarity achieved here will guide all subsequent decisions in the ML lifecycle.
Summary of Step 1
In short, the requirements stage involves defining the business problem clearly, determining the appropriate machine learning approach (supervised, unsupervised, or reinforcement learning), establishing success metrics and performance benchmarks, and identifying constraints such as latency, accuracy requirements, and resource limitations. To formulate an effective problem statement for machine learning, you should specify the business objective in measurable terms, define what constitutes success with concrete metrics, identify the target variable or outcome you want to predict or optimize, describe the available data sources and any known limitations, establish the acceptable trade-offs between different types of errors (such as false positives versus false negatives), and outline operational constraints including deployment requirements, computational resources, and timeline expectations. A well-crafted problem statement serves as the foundation for all subsequent decisions in the machine learning pipeline, ensuring that technical efforts align with business value and that the final solution addresses the actual problem rather than just demonstrating technical capability. This is a team document that should result from many meetings and possibly the input of many parties. It is a proposal for what to do and will guide the project through the remaining steps in the process. Having a requirements document that is satisfactory and approved by management is critically important for you to deliver what is expected and the success of your project will be measured by what was agreed to in this document.
How to move forward? Brainstorm on your own and with your team about the problem statement and then the requirements, and once you have a draft of them both put them into ChatGPT or your favorite chatbot (as of this writing Claude Opus 4 is better at coding tasks) and explain your project to the LLM. Then at the end of the prompt ask it what kind of questions you should be asking to expand your document, and what other considerations exist for the question you are trying to answer.
Tip
Again, one good way to proceed to steps 2-7 is to take your final problem statement and requirements document, upload it to ChatGPT, and copy and paste in this entire wiki page (context windows are more than enough nowadays) with the following prompt:
ChatGPT Prompt:
"Hello, today we will be generating a research plan for answering the problem posed in the uploaded requirements document.
Please apply the following process (Shift+Enter, then paste in a copy of this wiki, then Shift+Enter) to that document to generate a detailed plan while paying attention to what tasks are required and which are optional given this general description of the data we have:
**(list the columns of your data)"**
This prompt is so powerful I'm repeating it here twice.
Remember to use Shift+Enter to create new lines between segments of your question before pressing Enter to submit your prompt. This helps the LLM to distinguish different parts of your query.
What will come out is a detailed plan for the ML project. After that comes out you can start asking for code snippets one sub-step at a time to do the steps 2-7 in order according to the plan it generated.
The Data phase comes next, and is aimed at finding and preparing the right data to answer the question posed with the problem statement. The task can be roughly divided into the following sections (do each in order):
Objective: Gather comprehensive, relevant datasets that align with your problem definition and business objectives.
Key Tasks:
- Identify and catalog all available data sources (internal databases, APIs, public datasets, third-party providers)
- Establish data access permissions and legal compliance frameworks
- Set up data ingestion pipelines and storage infrastructure
- Document data lineage and provenance for reproducibility
Critical Questions to Ask:
- What data do we actually need versus what's available?
- Are there legal, privacy, or ethical constraints on data usage?
- How fresh does the data need to be, and can we maintain that freshness?
- What are the costs associated with acquiring and storing this data?
- Do we have sufficient volume for our modeling approach?
Objective: Evaluate the reliability, completeness, and suitability of collected data.
Key Tasks:
- Conduct comprehensive data profiling and quality audits (sanity checks, for instance, like are human ages all positive and <115?)
- Identify data integrity issues, inconsistencies, and anomalies
- Assess completeness rates across all variables
- Validate data against business rules and domain knowledge
- Document data quality metrics and establish data quality monitoring processes
Critical Questions to Ask:
- What percentage of our data is missing, and is it missing at random?
- Are there systematic biases in our data collection process?
- How representative is our sample of the target population?
- What data quality thresholds are acceptable for our use case?
- Can we trust the source systems and data generation processes?
Objective: Understand data distributions, relationships, patterns, and anomalies to inform preprocessing and modeling decisions.
Key Tasks:
- Generate descriptive statistics for all variables
- Create visualizations to understand distributions and relationships
- Identify outliers, skewness, and unusual patterns
- Analyze correlations between features (columns in the table, also known as X) and with target variables (also known as Y)
- Investigate temporal patterns and seasonality in time-series data
- Examine class distributions for classification problems
Critical Questions to Ask:
- What story is the data telling us about our problem domain?
- Are there unexpected patterns that challenge our assumptions?
- Which features show the strongest relationships with our target variable?
- Are there obvious data leakage issues (when information that wouldn't be available at prediction time in the real world accidentally gets included in your training data) or unrealistic correlations?
- What domain expertise do we need to properly interpret these patterns?
Objective: Transform raw data into a format suitable for machine learning algorithms while preserving important information.
Key Tasks:
- Missing Value Treatment: Implement appropriate strategies (deletion, imputation, or indicator variables) based on missingness patterns
- Duplicate Removal: Identify and handle exact and near-duplicate records
- Outlier Management: Decide whether to remove, transform, or keep outliers based on domain context
- Feature Scaling: Normalize or standardize numerical features, especially when they span vastly different ranges
- Categorical Encoding: Apply appropriate encoding techniques (one-hot, label, target, or embeddings)
- Basic Feature Creation: Apply simple transformations like log scaling or binning
- Data Type Optimization: Ensure appropriate data types for memory efficiency
Critical Questions to Ask:
- What's the most appropriate way to handle missing data without introducing bias?
- Should outliers be treated as errors or valuable edge cases?
- Which scaling method best preserves the information we need?
- Are we creating any features that could lead to data leakage?
- How do we balance feature complexity with model interpretability?
The quality of your data fundamentally determines the ceiling of your model's performance. Investing time in this phase pays dividends throughout the entire ML lifecycle. The unseen data that will arrive during deployment will test every assumption and decision made during this phase, so thorough preparation is crucial for long-term success.
Objective: Create appropriate train/validation/test splits that enable unbiased model evaluation and proper hyperparameter tuning.
Key Tasks:
- Training Set (60-70%): Used for model training and parameter learning
- Validation Set (15-20%): Used for hyperparameter tuning and model selection
- Test Set (15-20%): Used for final, unbiased performance evaluation
- Implement proper stratification for classification problems to maintain class balance
- Use time-based splits for temporal data to prevent data leakage
- Consider cross-validation strategies for small datasets
- Apply group-based splits for hierarchical or clustered data
Critical Questions to Ask:
- Is our split strategy appropriate for our data's temporal or hierarchical structure?
- Are we maintaining representativeness across all splits?
- Have we avoided any form of data leakage between sets?
- Is our test set large enough to provide reliable performance estimates?
- Should we consider specialized splitting strategies for our specific domain?
Summary of Step 2
In short, the data phase involves systematically collecting, exploring, and preparing your datasets to ensure they can effectively support your machine learning objectives. This begins with identifying and acquiring relevant data sources while ensuring legal compliance and data quality, followed by comprehensive exploratory data analysis to understand distributions, patterns, relationships, and potential issues in your data. The preprocessing stage handles missing values, removes duplicates, manages outliers, and applies appropriate scaling and encoding techniques to transform raw data into a format suitable for machine learning algorithms. Critical data quality assessment throughout this phase helps identify biases, inconsistencies, and gaps that could undermine model performance. The data phase concludes with proper documentation of all transformations and decisions made, establishing a reproducible pipeline that can be applied to new data during deployment. Data quality fundamentally determines the ceiling of your model's performance - no amount of sophisticated modeling can compensate for poor, biased, or inadequate data. This phase requires close collaboration between data scientists, domain experts, and business stakeholders to ensure that the processed data accurately represents the problem you're trying to solve and that all preprocessing decisions align with both technical requirements and business constraints. The deliverable from this phase should be a clean, well-documented dataset with clear train/validation/test splits, comprehensive data dictionaries, and detailed documentation of all preprocessing steps and assumptions.
How to move forward? Start by conducting a thorough data audit to catalog all available sources and assess their quality, completeness, and relevance to your problem statement. Work closely with domain experts to understand the business context behind each data field and identify potential data quality issues or biases. Create comprehensive visualizations and statistical summaries during exploratory data analysis, and don't rush the preprocessing phase - take time to understand the implications of each transformation decision. Document everything meticulously, as these decisions will need to be replicated exactly when processing new data in production. Consider putting your data exploration findings and preprocessing approach into an LLM prompt, asking it to identify potential blind spots, suggest additional quality checks you might have missed, highlight preprocessing decisions that could introduce bias, and recommend domain-specific considerations for your particular type of data and problem.
Objective: Create sophisticated features that capture complex patterns and domain-specific insights to enhance model performance.
Key Tasks:
- Mathematical Transformations: Apply polynomial features, logarithmic, exponential, and trigonometric transformations
- Interaction Features: Generate feature combinations and cross-products to capture synergistic effects
- Time-Based Features: Extract temporal patterns, seasonality indicators, lag features, and rolling statistics
- Aggregation Features: Create summary statistics grouped by categorical variables or time windows
- Domain-Specific Features: Leverage business knowledge to create meaningful composite indicators
- Text Features: Generate n-grams, TF-IDF scores, sentiment scores, or embedding representations
- Geospatial Features: Calculate distances, create location clusters, or extract geographic patterns
Critical Questions to Ask:
- Which feature combinations might reveal hidden relationships in our data?
- Are we capturing the right temporal patterns for our time-sensitive problem?
- How can domain expertise guide our feature creation process?
- Are we generating features that will be available at prediction time?
- What's the computational cost versus benefit of complex feature engineering?
Objective: Quantify the predictive power and relevance of all features to identify the most valuable inputs for modeling.
Key Tasks:
- Correlation Analysis: Build correlation matrices to identify linear relationships and multicollinearity
- Mutual Information Scoring: Measure non-linear dependencies between features and target variables
- Statistical Tests: Apply chi-square tests, ANOVA, or other appropriate statistical measures
- Tree-Based Importance: Use Random Forest, XGBoost, or other ensemble methods to rank feature importance
- Permutation Importance: Measure performance drop when features are randomly shuffled
- SHAP Values: Calculate feature contributions for model interpretability
- Variance Analysis: Identify low-variance features that provide little discriminative power
Critical Questions to Ask:
- Which features consistently rank high across different importance metrics?
- Are highly correlated features providing redundant information?
- Do our importance rankings align with domain expertise and business intuition?
- Are there surprising features that show high importance but low business relevance?
- How stable are our importance rankings across different data samples?
Objective: Optimize the feature set by removing irrelevant, redundant, or noisy features to improve model performance and interpretability.
Key Tasks:
- Filter Methods: Use statistical tests and correlation thresholds to eliminate weak features
- Wrapper Methods: Apply recursive feature elimination (RFE) with cross-validation (Recursive Feature Elimination (RFE) is a method used in machine learning to select the most important features from a dataset by iteratively removing the least significant ones until a specified number of features is reached. It helps improve model performance by reducing dimensionality and eliminating irrelevant data)
- Embedded Methods: Leverage regularization techniques (L1/L2) for automatic feature selection
- Principal Component Analysis: Reduce dimensionality while preserving variance
- Univariate Selection: Select features based on individual statistical significance
- Variance Thresholding: Remove features with near-zero variance
- Custom Business Rules: Apply domain-specific constraints on feature inclusion
Critical Questions to Ask:
- What's the optimal number of features for our specific algorithm and dataset size?
- Are we losing critical information through our dimensionality reduction approach?
- How does feature selection impact model interpretability versus performance?
- Should we use different feature sets for different models in our ensemble?
- Can we establish clear business justification for our selected features?
Objective: Apply final scaling and normalization to selected features, ensuring optimal conditions for model training.
Key Tasks:
- Re-scale Selected Features: Apply standardization, normalization, or robust scaling based on algorithm requirements
- Handle Categorical Features: Ensure proper encoding and scaling for categorical variables
- Pipeline Integration: Create reproducible preprocessing pipelines that can be applied to new data
- Validation Set Alignment: Ensure scaling parameters from training data are properly applied to validation and test sets
- Feature Distribution Analysis: Verify that scaled features maintain expected distributions
Critical Questions to Ask:
- Do our scaling choices align with the assumptions of our planned algorithms?
- Are we applying the same scaling transformations consistently across all data splits?
- How will our scaling approach work with new, unseen data during deployment?
- Should different feature types receive different scaling treatments?
- Are there any features that shouldn't be scaled due to interpretability requirements?
Objective: Establish comprehensive documentation and version control for reproducible ML workflows.
Key Tasks:
- Create detailed data dictionaries and schema documentation
- Document all preprocessing steps and transformations applied
- Record feature engineering logic and business rationale
- Implement data versioning and lineage tracking
- Establish data governance policies and access controls
- Create reproducible data preparation pipelines
- Document feature selection criteria and importance scores
Critical Questions to Ask:
- Can someone else reproduce our entire feature engineering process exactly?
- How will we track changes in our feature sets over time?
- What happens when new data sources or features become available?
- How do we ensure data privacy and security throughout the process?
- What metadata do we need to capture for future model updates and feature evolution?
Objective: Ensure feature-engineered data is ready for model development and meets all quality and business requirements.
Key Tasks:
- Conduct comprehensive data quality checks on final feature set
- Validate feature engineering logic with domain experts and stakeholders
- Verify that data splits maintain statistical properties and business relevance
- Confirm alignment between engineered features and business objectives
- Test preprocessing pipelines on sample data
- Document assumptions, limitations, and potential risks for downstream phases
- Establish baseline performance expectations
Critical Questions to Ask:
- Are we confident our engineered features can effectively solve our business problem?
- Have we introduced any biases through our feature engineering choices?
- Do our final features make intuitive sense from a domain perspective?
- What are the key limitations or blind spots in our feature-engineered dataset?
- Are we ready to invest time and resources in model development with this feature set?
- How will our feature engineering approach scale to production data volumes?
Critical Transition Point: At this stage, you should have a clean, well-documented, feature-rich dataset with clear train/validation/test splits. Your features should be justified both statistically and from a business perspective. The recursive feature elimination process mentioned here sets the foundation for iterative model improvement in the next phase, where you'll refine your feature set based on actual model performance.
Summary of Step 3
In short, the feature creation and data postprocessing phase transforms your clean data into an optimized feature set that maximizes model performance while maintaining business interpretability. This involves advanced feature engineering through mathematical transformations, interaction terms, time-based features, and domain-specific calculations that capture complex patterns and relationships in your data. Statistical and model-based feature importance analysis helps identify the most predictive variables using correlation matrices, mutual information scores, and tree-based importance rankings. The feature selection process systematically eliminates redundant, irrelevant, or noisy features to improve model performance and reduce computational complexity while preserving the most valuable predictive signals. This phase also includes establishing proper data splitting strategies with appropriate train/validation/test divisions that prevent data leakage and enable unbiased model evaluation. Final scaling and normalization ensure that selected features are in optimal formats for your chosen algorithms. The feature engineering process requires balancing statistical significance with business intuition - features that test well statistically should also make sense from a domain perspective and be available at prediction time in production. This phase bridges the gap between raw data and model-ready inputs, and the quality of feature engineering often has more impact on final model performance than algorithm selection. The deliverable should be a curated, well-documented feature set with clear business justification for each feature, comprehensive preprocessing pipelines that can be reproduced in production, and properly stratified data splits ready for model training.
How to move forward? Begin with domain expert collaboration to brainstorm potential features that capture business logic and relationships, then systematically create and test these features using both statistical measures and business intuition. Don't be afraid to create many features initially - the selection process will help you narrow down to the most valuable ones. Pay careful attention to temporal aspects and ensure no future information leaks into your training features. Test your feature engineering pipeline on sample data to ensure it's reproducible and efficient. Consider describing your feature engineering approach and feature importance findings to an LLM, asking it to suggest additional feature combinations you might have missed, identify potential data leakage risks in your feature creation process, recommend domain-specific features relevant to your problem type, and highlight any features that might be difficult to obtain or compute in a production environment.
Objective: Choose appropriate algorithms based on problem type, data characteristics, and business requirements.
Key Tasks:
- Problem Type Alignment: Match algorithms to classification, regression, clustering, or other specific problem types
- Data Size Considerations: Select algorithms that scale appropriately with your dataset size and dimensionality
- Interpretability Requirements: Balance model complexity with explainability needs based on business context
- Computational Constraints: Consider training time, inference speed, and resource requirements
- Baseline Model Establishment: Start with simple, interpretable models as performance benchmarks
- Algorithm Diversity: Select multiple algorithm families to explore different modeling approaches
Critical Questions to Ask:
- What level of interpretability does our business use case require?
- Do we have sufficient data for complex models, or should we stick to simpler approaches?
- What are our computational and time constraints for training and inference?
- Are there specific algorithms that work well in our domain based on literature or experience?
- How important is model performance versus training speed and resource usage?
Objective: Train multiple candidate models with full feature sets and establish baseline performance metrics.
Key Tasks:
- Linear Models: Train logistic regression, linear regression, or regularized variants (Ridge, Lasso, Elastic Net)
- Tree-Based Methods: Implement decision trees, random forests, gradient boosting (XGBoost, LightGBM, CatBoost)
- Neural Networks: Develop feedforward networks, deep learning models as appropriate
- Ensemble Methods: Create bagging, boosting, and stacking combinations
- Cross-Validation: Implement robust validation strategies to assess generalization
- Performance Metrics: Calculate appropriate metrics for your problem type (accuracy, precision, recall, F1, AUC, RMSE, MAE)
- Training Monitoring: Track training progress, convergence, and potential overfitting
Critical Questions to Ask:
- Which algorithms show the most promise on our validation set?
- Are we seeing signs of overfitting or underfitting in any models?
- How consistent are our performance metrics across different cross-validation folds?
- Do our results align with domain expectations and business logic?
- Which models offer the best trade-off between performance and complexity?
Objective: Leverage trained models to understand feature contributions and identify the most predictive variables.
Key Tasks:
- Tree-Based Importance: Extract feature importance scores from random forests and gradient boosting models
- Coefficient Analysis: Analyze linear model coefficients and regularization paths
- Permutation Importance: Measure performance drop when features are randomly shuffled
- SHAP Values: Calculate Shapley values for detailed feature contribution analysis
- Partial Dependence Plots: Understand individual feature effects on predictions
- Feature Interaction Detection: Identify synergistic effects between features
- Stability Analysis: Assess feature importance consistency across different model runs
Critical Questions to Ask:
- Which features consistently rank as important across different algorithms?
- Are there surprising features that show high importance but weren't expected?
- Do our feature importance rankings make business sense and align with domain expertise?
- Are there features that are important in some models but not others?
- How stable are our importance rankings when we retrain models?
Objective: Systematically eliminate less important features to optimize model performance and reduce complexity.
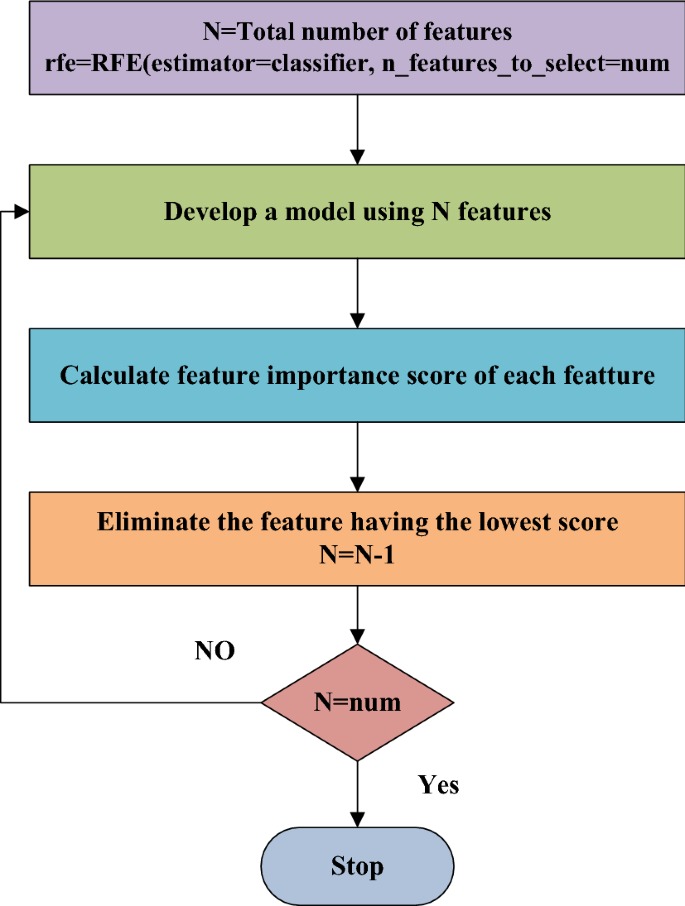
Image 15: Recursive Feature Elimination Process
Image Credit: Article at Springer
Key Tasks:
- RFE with Cross-Validation: Implement systematic feature elimination with performance validation
- Elimination Strategy: Remove features in batches (typically 10-20% at a time) based on importance scores
- Performance Tracking: Monitor model performance at each elimination step
- Optimal Feature Set Identification: Find the point where performance plateaus or begins to decline
- Algorithm-Specific RFE: Apply RFE separately for different algorithm families
- Feature Set Comparison: Compare performance across different feature subset sizes
- Final Feature Set Selection: Choose optimal feature set based on performance-complexity trade-off
Critical Questions to Ask:
- At what point does removing features start to hurt model performance?
- Are we achieving better generalization with fewer features?
- Do different algorithms prefer different optimal feature sets?
- How does feature reduction impact model interpretability and business acceptance?
- Are we maintaining the most business-critical features regardless of statistical importance?
Objective: Fine-tune model parameters to achieve optimal performance on validation data.
Key Tasks:
- Grid Search: Systematic exploration of parameter combinations for simpler parameter spaces
- Random Search: Efficient sampling of hyperparameter space for higher-dimensional problems
- Bayesian Optimization: Intelligent parameter search using prior results to guide exploration
- Learning Rate Scheduling: Optimize training dynamics for neural networks and gradient boosting
- Regularization Tuning: Find optimal balance between bias and variance
- Cross-Validation Integration: Ensure hyperparameter optimization doesn't overfit to validation set
- Automated ML Tools: Leverage AutoML platforms for systematic hyperparameter exploration
Critical Questions to Ask:
- Are we searching over the right hyperparameter ranges?
- How do we balance computational cost with thoroughness of hyperparameter search?
- Are our hyperparameter choices generalizing well to unseen data?
- Should we use different hyperparameters for different feature sets?
- Are we avoiding hyperparameter overfitting through proper validation strategies?
Objective: Combine multiple models to achieve better performance than any single model.
Key Tasks:
- Voting Ensembles: Combine predictions through majority voting or averaging
- Stacking: Train meta-models to optimally combine base model predictions
- Blending: Weighted combination of different model types based on validation performance
- Bagging Variations: Create diverse models through different training subsets or feature sets
- Diversity Optimization: Ensure ensemble components make different types of errors
- Ensemble Validation: Assess ensemble performance and individual component contributions
- Computational Efficiency: Balance ensemble complexity with inference speed requirements
Critical Questions to Ask:
- Are our ensemble components sufficiently diverse to provide complementary strengths?
- Does our ensemble significantly outperform our best individual model?
- How does ensemble complexity impact interpretability and deployment feasibility?
- Are we properly validating ensemble performance to avoid overfitting?
- What's the computational cost versus performance benefit of our ensemble approach?
Objective: Conduct comprehensive evaluation of final model candidates to ensure robust performance.
Key Tasks:
- Hold-Out Test Evaluation: Assess final model performance on untouched test set
- Cross-Validation Analysis: Examine performance consistency across different data splits
- Learning Curve Analysis: Understand how performance scales with training data size
- Error Analysis: Investigate prediction errors and failure modes
- Bias-Variance Decomposition: Understand sources of model error
- Confidence Intervals: Establish statistical significance of performance differences
- Business Metric Alignment: Ensure model performance translates to business value
Critical Questions to Ask:
- How confident are we in our model's generalization to unseen data?
- Are there specific data segments where our model performs poorly?
- Do our performance metrics align with business success criteria?
- What are the practical implications of our model's error rates?
- Are we ready to move to deployment, or do we need further refinement?
Transition to Deployment: At this stage, you should have a well-validated model with optimized features and hyperparameters. The recursive feature elimination process has helped you identify the most predictive features for your specific algorithm, and your ensemble approach has maximized performance. You're now ready to move into model deployment and monitoring phases.
Summary of Step 4
In short, the model selection and training phase involves systematically choosing, training, and optimizing machine learning algorithms to achieve the best performance on your prepared feature set. This begins with selecting appropriate algorithms based on your problem type, data characteristics, and business requirements, typically training multiple candidates including linear models, tree-based methods, and neural networks to explore different modeling approaches. Initial training with your full feature set establishes baseline performance and enables model-based feature importance analysis that reveals which variables truly drive predictions for each algorithm. Recursive feature elimination then systematically removes less important features while monitoring performance, helping you find the optimal balance between model complexity and predictive power. Hyperparameter optimization fine-tunes each model's configuration to maximize performance, while ensemble methods combine multiple models to achieve better results than any single approach. Throughout this phase, rigorous cross-validation and hold-out testing ensure that performance improvements are genuine and will generalize to unseen data. The iterative nature of this phase means you'll often cycle between feature selection, model training, and hyperparameter tuning as you discover what works best for your specific problem. Success depends not just on achieving high performance metrics, but on finding models that are robust, interpretable enough for business acceptance, and computationally feasible for your deployment constraints. The deliverable should be one or more validated models with optimized hyperparameters, a refined feature set proven to work well with your chosen algorithms, and comprehensive performance documentation that demonstrates readiness for deployment.
How to move forward? Start with simple, interpretable baseline models to establish performance benchmarks, then systematically explore more complex approaches while carefully tracking what improves performance and what doesn't. Don't get caught up in chasing marginal performance gains at the expense of interpretability or deployment feasibility. Pay close attention to your validation strategy - ensure you're not overfitting to your validation set through excessive hyperparameter tuning. Document all modeling decisions and their business rationale. Consider sharing your modeling approach and results with an LLM, asking it to suggest alternative algorithms you might not have considered for your problem type, identify potential overfitting risks in your training and validation approach, recommend ensemble strategies that could improve your results, and highlight any gaps between your model performance and deployment requirements that need to be addressed.
Objective: Systematically optimize model parameters to achieve peak performance while avoiding overfitting to validation data.
Key Tasks:
- Parameter Space Definition: Map out all tunable hyperparameters and their reasonable ranges for each algorithm
- Grid Search Implementation: Exhaustive search over discrete parameter combinations for smaller parameter spaces
- Random Search Execution: Efficient sampling approach for high-dimensional parameter spaces
- Bayesian Optimization: Intelligent parameter search using Gaussian processes to guide exploration
- Evolutionary Algorithms: Apply genetic algorithms or particle swarm optimization for complex parameter landscapes
- Multi-Objective Optimization: Balance competing objectives like accuracy, interpretability, and computational efficiency
- Early Stopping Integration: Implement dynamic training termination to prevent overfitting in iterative algorithms
- Nested Cross-Validation: Use proper validation strategies to avoid hyperparameter overfitting
Critical Questions to Ask:
- Are we searching over the right hyperparameter ranges based on problem characteristics?
- How do we balance computational cost with thoroughness of hyperparameter exploration?
- Are we using appropriate validation strategies to prevent hyperparameter overfitting?
- Should we use different hyperparameter sets for different data subsets or time periods?
- How stable are our optimal hyperparameters across different random seeds or data splits?
- Are we considering the interaction effects between different hyperparameters?
Objective: Comprehensively assess model performance using multiple metrics that align with business objectives and technical requirements.
Key Tasks:
- Classification Metrics: Calculate accuracy, precision, recall, F1-score, AUC-ROC, AUC-PR, and confusion matrices
- Regression Metrics: Compute RMSE, MAE, MAPE, R-squared, and residual analysis
- Ranking Metrics: Apply NDCG, MAP, and MRR for information retrieval and recommendation problems
- Business-Specific Metrics: Develop custom metrics that directly measure business value and ROI
- Threshold Optimization: Find optimal decision thresholds for classification problems based on business costs
- Calibration Assessment: Evaluate probability calibration for models that output confidence scores
- Temporal Stability: Assess performance consistency across different time periods
- Segmented Analysis: Evaluate performance across different data segments, demographics, or business units
Critical Questions to Ask:
- Which metrics best capture the business value we're trying to optimize?
- Are our models well-calibrated, or do they over/under-estimate confidence?
- How does performance vary across different segments of our data?
- What's the optimal decision threshold given our business cost structure?
- Are there temporal patterns in model performance that we need to address?
- How do our technical metrics translate to actual business impact?
Objective: Rigorously compare model performance using statistical methods to ensure differences are significant and meaningful.
Key Tasks:
- Cross-Validation Comparison: Use k-fold or time-series cross-validation to compare model performance distributions
- Statistical Significance Testing: Apply paired t-tests, Wilcoxon signed-rank tests, or McNemar's test for model comparison
- Confidence Interval Estimation: Calculate confidence intervals for performance metrics using bootstrapping
- Effect Size Analysis: Assess practical significance beyond statistical significance
- Multiple Comparison Correction: Apply Bonferroni or FDR correction when comparing many models
- Non-Parametric Tests: Use rank-based tests when performance distributions are non-normal
- Bayesian Model Comparison: Apply Bayesian methods to quantify model uncertainty and comparison confidence
- Performance Stability Analysis: Evaluate consistency of model rankings across different validation schemes
Critical Questions to Ask:
- Are the performance differences between our models statistically significant?
- Is the magnitude of improvement practically meaningful for our business case?
- How confident are we in our model rankings given the uncertainty in our estimates?
- Are our comparison methods appropriate for our data structure and problem type?
- How sensitive are our conclusions to different validation strategies or random seeds?
- Do we have sufficient data to detect meaningful differences between models?
Objective: Understand how models make decisions and ensure predictions align with domain knowledge and business logic.
Key Tasks:
- Feature Importance Analysis: Calculate and visualize global feature importance using multiple methods
- SHAP Value Computation: Generate Shapley values for both global and local feature explanations
- LIME Implementation: Create local interpretable model-agnostic explanations for individual predictions
- Partial Dependence Plots: Visualize individual feature effects on model predictions
- Feature Interaction Detection: Identify and quantify interactions between different features
- Decision Tree Surrogate Models: Create interpretable approximations of complex models
- Counterfactual Explanations: Generate "what-if" scenarios to understand decision boundaries
- Model Behavior Documentation: Create comprehensive documentation of model decision patterns
Critical Questions to Ask:
- Do our model's learned patterns align with domain expertise and business intuition?
- Can we explain individual predictions in terms that business stakeholders understand?
- Are there unexpected feature relationships that require further investigation?
- How consistent are our explanations across different explanation methods?
- Are there any concerning patterns that suggest model bias or overfitting?
- Can we provide sufficient explanation to meet regulatory or business requirements?
Objective: Identify and quantify potential biases in model predictions to ensure fair and ethical outcomes.
Key Tasks:
- Demographic Parity Analysis: Assess whether predictions are independent of protected attributes
- Equalized Odds Evaluation: Check if true positive and false positive rates are equal across groups
- Individual Fairness Testing: Verify that similar individuals receive similar predictions
- Counterfactual Fairness: Assess predictions in hypothetical worlds where sensitive attributes differ
- Intersectional Bias Analysis: Examine bias across combinations of protected characteristics
- Historical Bias Detection: Identify biases inherited from training data or past decisions
- Fairness Metric Trade-offs: Understand tensions between different fairness criteria
- Bias Mitigation Strategies: Implement pre-processing, in-processing, or post-processing bias reduction
Critical Questions to Ask:
- Are our models making fair predictions across different demographic groups?
- What trade-offs exist between model performance and fairness metrics?
- Are we perpetuating or amplifying historical biases present in our training data?
- How do we balance individual fairness with group fairness requirements?
- Are there regulatory or legal requirements for fairness that we must meet?
- What's our strategy for monitoring and maintaining fairness over time?
Objective: Validate model behavior under unusual conditions and ensure robustness to data variations and adversarial inputs.
Key Tasks:
- Outlier Response Testing: Evaluate model behavior on extreme or unusual input values
- Data Distribution Shift Analysis: Test model performance when input distributions change
- Adversarial Example Generation: Create inputs designed to fool the model and assess vulnerabilities
- Stress Testing: Evaluate model performance under high-volume or high-frequency scenarios
- Input Validation Testing: Assess model responses to malformed, missing, or corrupted inputs
- Boundary Condition Analysis: Test model behavior at the edges of its training data range
- Sensitivity Analysis: Measure how small input changes affect model predictions
- Robustness Benchmarking: Compare model stability against established robustness benchmarks
Critical Questions to Ask:
- How does our model behave when inputs fall outside the training data distribution?
- Are there specific input patterns that cause our model to fail or behave unexpectedly?
- How robust is our model to small perturbations or noisy inputs?
- What happens when we encounter completely novel scenarios not seen in training?
- Are there security vulnerabilities that could be exploited by malicious actors?
- How gracefully does our model degrade when faced with challenging inputs?
Objective: Ensure model predictions and behavior align with business rules, domain expertise, and practical requirements.
Key Tasks:
- Domain Expert Review: Conduct structured reviews with subject matter experts
- Business Rule Compliance: Verify model predictions don't violate known business constraints
- Sanity Check Implementation: Create automated tests for obviously incorrect predictions
- Edge Case Scenario Planning: Work with business users to identify critical edge cases
- Prediction Reasonableness Assessment: Evaluate whether predictions pass common-sense tests
- Historical Consistency Validation: Compare model predictions with known historical outcomes
- Cross-Domain Validation: Test model behavior across different business contexts or regions
- Stakeholder Acceptance Testing: Obtain formal validation from business stakeholders
Critical Questions to Ask:
- Do our model predictions make intuitive sense to domain experts?
- Are there business rules or constraints that our model consistently violates?
- How do our predictions compare to human expert judgment on the same cases?
- Are there scenarios where we should override model predictions with business logic?
- What level of explanation do business users need to trust and act on model predictions?
- Are our models capturing the nuances and complexities of the business domain?
Objective: Select the optimal model based on comprehensive evaluation and document all validation findings.
Key Tasks:
- Multi-Criteria Decision Analysis: Balance performance, interpretability, fairness, and operational requirements
- Model Selection Justification: Document the rationale for final model choice
- Performance Benchmark Documentation: Create comprehensive performance reports across all evaluation dimensions
- Validation Summary: Compile findings from all validation activities into executive summary
- Risk Assessment Documentation: Document identified risks and mitigation strategies
- Deployment Readiness Checklist: Verify all validation requirements have been met
- Model Card Creation: Generate standardized documentation following model card frameworks
- Stakeholder Sign-off: Obtain formal approval from business and technical stakeholders
Critical Questions to Ask:
- Which model provides the best overall balance of our competing requirements?
- Have we thoroughly documented our model's capabilities and limitations?
- Are all stakeholders comfortable with the model's performance and behavior?
- What are the key risks and assumptions that need to be monitored in production?
- Is our validation documentation sufficient for regulatory or audit requirements?
- Are we confident this model is ready for production deployment?
Critical Transition Point: At this stage, you should have a thoroughly validated model with optimized hyperparameters, comprehensive performance documentation, and stakeholder approval. All validation activities should confirm that the model meets technical performance requirements, business logic expectations, and ethical standards. You should have clear documentation of model capabilities, limitations, and monitoring requirements that will guide the deployment and maintenance phases.
Summary of Step 5
In short, the hyperparameter tuning, evaluation and validation phase involves systematically optimizing model parameters and rigorously assessing model performance to ensure it meets technical, business, and ethical requirements before deployment. This begins with comprehensive hyperparameter optimization using grid search, random search, or Bayesian optimization with proper cross-validation to avoid overfitting to validation data. Model evaluation goes beyond simple accuracy metrics to include business-relevant measures, statistical significance testing between models, and performance analysis across different data segments and time periods. Critical validation activities include interpretability analysis using SHAP values and feature importance to ensure model decisions align with domain knowledge, bias detection and fairness assessment to identify potential discrimination across demographic groups, and robustness testing to evaluate model behavior on edge cases and adversarial inputs. Domain validation with business experts ensures predictions make intuitive sense and comply with business rules, while comprehensive documentation captures all findings in model cards and performance reports. This phase requires balancing multiple competing objectives - performance versus interpretability, accuracy versus fairness, and complexity versus operational feasibility. The validation process should be thorough enough to build confidence among stakeholders while identifying potential risks and limitations that need monitoring in production. The deliverable should be a fully validated model with optimized hyperparameters, comprehensive performance documentation across all evaluation dimensions, clear understanding of model capabilities and limitations, and formal stakeholder approval for production deployment.
How to move forward? Begin with a systematic hyperparameter optimization strategy that balances thoroughness with computational efficiency, ensuring you use proper nested cross-validation to avoid overfitting. Don't focus solely on technical metrics - invest significant time in interpretability analysis and domain validation to build stakeholder trust and identify potential issues. Conduct thorough bias and fairness testing, especially if your model affects people's lives or opportunities. Test your model extensively on edge cases and unusual scenarios that might occur in production. Document everything comprehensively and obtain formal sign-off from both technical and business stakeholders. Consider describing your validation approach and findings to an LLM, asking it to identify validation gaps you might have missed, suggest additional fairness or robustness tests relevant to your domain, recommend ways to better communicate model limitations to stakeholders, and highlight potential production monitoring requirements based on your validation findings.
Objective: Design and plan the optimal deployment architecture that meets performance, scalability, and business requirements.
Key Tasks:
- Deployment Pattern Selection: Choose between real-time serving, batch processing, or hybrid approaches based on business needs
- Infrastructure Architecture Design: Plan compute, storage, and networking requirements for production deployment
- Scalability Planning: Design for expected load patterns and growth projections
- High Availability Design: Implement redundancy and failover mechanisms to ensure system reliability
- Multi-Environment Strategy: Plan development, staging, and production environments with appropriate promotion processes
- Cloud vs On-Premise Decision: Evaluate deployment options based on security, cost, and operational requirements
- Microservices vs Monolithic Architecture: Choose appropriate service architecture for your organizational context
- Container Strategy: Plan containerization approach using Docker, Kubernetes, or similar technologies
Critical Questions to Ask:
- What are our latency requirements and expected traffic patterns?
- Do we need real-time predictions, batch processing, or both?
- What are our availability requirements and acceptable downtime?
- How will we handle traffic spikes and scaling requirements?
- What security and compliance constraints affect our deployment options?
- How does our deployment strategy align with existing organizational infrastructure?
Objective: Implement the technical infrastructure required to serve model predictions reliably and efficiently.
Key Tasks:
- Model Serialization & Storage: Package models using appropriate formats (pickle, ONNX, TensorFlow SavedModel, MLflow)
- API Development: Create RESTful APIs or gRPC services for model serving
- Load Balancing Configuration: Implement load balancers to distribute traffic across multiple model instances
- Caching Strategy: Implement intelligent caching for frequently requested predictions
- Database Integration: Set up databases for logging predictions, storing results, and managing model metadata
- Message Queue Setup: Implement asynchronous processing using systems like RabbitMQ, Apache Kafka, or cloud equivalents
- Container Orchestration: Deploy using Kubernetes, Docker Swarm, or cloud container services
- Serverless Options: Consider Function-as-a-Service platforms for event-driven or intermittent workloads
Critical Questions to Ask:
- What's the most appropriate model serving framework for our technology stack?
- How will we handle concurrent requests and manage resource allocation?
- What caching strategies will optimize performance without compromising freshness?
- How will we manage model versions and enable rollbacks if needed?
- What backup and disaster recovery procedures do we need?
- How will our serving infrastructure integrate with existing systems?
Objective: Seamlessly integrate ML predictions into existing business processes and technical systems.
Key Tasks:
- API Integration: Connect model predictions to downstream applications and business processes
- Database Integration: Integrate with existing data warehouses, operational databases, and data lakes
- ETL Pipeline Integration: Incorporate model predictions into existing extract, transform, load processes
- Business Process Integration: Embed predictions into decision-making workflows and user interfaces
- Legacy System Compatibility: Ensure compatibility with existing enterprise systems and data formats
- Authentication & Authorization: Implement proper security controls for API access and data protection
- Data Pipeline Integration: Connect real-time and batch data flows to model serving endpoints
- Workflow Management: Integrate with existing scheduling and workflow management systems
Critical Questions to Ask:
- How will model predictions fit into existing business workflows and decision processes?
- What changes are needed in downstream systems to consume model predictions?
- How will we handle authentication and authorization across integrated systems?
- Are there data format or protocol compatibility issues we need to address?
- What's our strategy for gradually rolling out ML integration across different business units?
- How will we maintain data consistency across integrated systems?
Objective: Ensure deployed models meet security standards and regulatory compliance requirements.
Key Tasks:
- Data Encryption: Implement encryption for data in transit and at rest
- Access Control: Set up role-based access control and API key management
- Audit Logging: Implement comprehensive logging for all model access and predictions
- Privacy Protection: Implement data anonymization and privacy-preserving techniques where required
- Regulatory Compliance: Ensure deployment meets GDPR, HIPAA, SOX, or other relevant regulations
- Vulnerability Assessment: Conduct security testing and vulnerability assessments
- Network Security: Implement firewalls, VPNs, and network segmentation as appropriate
- Compliance Documentation: Create necessary documentation for regulatory audits and compliance verification
Critical Questions to Ask:
- What security and compliance requirements apply to our ML deployment?
- How will we protect sensitive data throughout the prediction pipeline?
- What audit trails and logging capabilities do we need for compliance?
- Are there specific regulatory requirements for ML model transparency or explainability?
- How will we handle data subject requests (e.g., right to explanation, data deletion)?
- What security testing and monitoring procedures do we need to implement?
Objective: Optimize system performance and implement scaling strategies to handle varying loads efficiently.
Key Tasks:
- Performance Profiling: Identify bottlenecks in the prediction pipeline
- Model Optimization: Implement model compression, quantization, or distillation techniques
- Hardware Optimization: Optimize for specific hardware (GPUs, TPUs, specialized chips)
- Auto-Scaling Configuration: Set up automatic scaling based on load patterns and performance metrics
- Edge Computing: Deploy models closer to data sources or users for reduced latency
- Batch Processing Optimization: Optimize batch prediction pipelines for throughput and resource efficiency
- Memory Management: Implement efficient memory usage and garbage collection strategies
- Prediction Caching: Implement intelligent caching strategies for frequently requested predictions
Critical Questions to Ask:
- Where are the performance bottlenecks in our prediction pipeline?
- How can we optimize our models for faster inference without sacrificing accuracy?
- What auto-scaling strategies will handle our expected load patterns most efficiently?
- Are there opportunities to deploy models closer to users or data sources?
- How will we balance cost optimization with performance requirements?
- What performance benchmarks should we establish and monitor?
Objective: Implement robust model versioning and automated deployment processes to enable safe, reliable model updates.
Key Tasks:
- Version Control Setup: Implement comprehensive versioning for models, code, and configurations
- CI/CD Pipeline Development: Create automated testing and deployment pipelines for model updates
- A/B Testing Framework: Implement capability to test new models against existing ones with live traffic
- Blue-Green Deployment: Set up parallel environments for zero-downtime deployments
- Canary Deployments: Implement gradual rollout strategies for new model versions
- Rollback Procedures: Create automated rollback capabilities for failed deployments
- Model Registry: Implement centralized model storage and metadata management
- Deployment Automation: Automate model packaging, testing, and deployment processes
Critical Questions to Ask:
- How will we safely deploy new model versions without disrupting production?
- What testing procedures need to be automated in our deployment pipeline?
- How will we handle rollbacks if a new model performs poorly?
- What approval processes are needed for deploying models to production?
- How will we track and manage different model versions across environments?
- What safeguards will prevent accidentally deploying untested or problematic models?
Objective: Implement comprehensive monitoring and alerting systems to track model performance and system health in production.
Key Tasks:
- Performance Monitoring: Track prediction latency, throughput, and resource utilization
- Model Drift Detection: Monitor for changes in input data distributions and model performance
- Prediction Quality Monitoring: Track prediction accuracy and business metric alignment over time
- System Health Monitoring: Monitor infrastructure health, availability, and error rates
- Alert Configuration: Set up intelligent alerting for performance degradation and system issues
- Dashboard Creation: Build real-time dashboards for operational monitoring and business stakeholders
- Log Aggregation: Implement centralized logging and log analysis capabilities
- Custom Metrics Tracking: Monitor business-specific metrics and KPIs related to model outcomes
Critical Questions to Ask:
- What are the most important metrics to monitor for our specific use case?
- How quickly do we need to detect and respond to model performance issues?
- What alerting thresholds will balance sensitivity with false alarm rates?
- How will we distinguish between normal variation and problematic model drift?
- What monitoring information do different stakeholders need access to?
- How will our monitoring strategy evolve as we deploy more models?
Objective: Create comprehensive documentation and ensure smooth handover to operational teams for ongoing management.
Key Tasks:
- Operational Documentation: Create detailed runbooks for system operation and troubleshooting
- API Documentation: Provide comprehensive documentation for all model APIs and endpoints
- Architecture Documentation: Document system architecture, dependencies, and integration points
- Monitoring Playbooks: Create procedures for responding to alerts and performance issues
- Maintenance Procedures: Document routine maintenance tasks and update procedures
- Training Materials: Develop training for operational teams on model management and troubleshooting
- Knowledge Transfer Sessions: Conduct formal handover sessions with operational and business teams
- Support Processes: Establish ongoing support processes and escalation procedures
Critical Questions to Ask:
- Do operational teams have sufficient documentation to manage the system independently?
- Are all integration points and dependencies clearly documented?
- What training do operational teams need to effectively manage the deployed models?
- How will we handle ongoing support and troubleshooting requests?
- What processes are in place for updating documentation as the system evolves?
- Are there clear escalation procedures for complex technical issues?
Objective: Conduct final validation in production environment and execute controlled go-live process.
Key Tasks:
- Production Testing: Execute comprehensive testing in the production environment
- Shadow Mode Deployment: Run new system alongside existing processes to validate behavior
- Limited Rollout: Begin with limited user groups or geographic regions
- Performance Validation: Confirm system meets all performance and reliability requirements
- Business Process Validation: Verify integration with business processes works as expected
- Stakeholder Sign-off: Obtain formal approval from business and technical stakeholders
- Go-Live Execution: Execute planned rollout to full production usage
- Post-Deployment Monitoring: Intensively monitor system performance immediately after go-live
Critical Questions to Ask:
- Have we thoroughly tested all functionality in the production environment?
- Are all stakeholders confident the system is ready for full production use?
- What's our rollback plan if serious issues emerge during go-live?
- How will we manage the transition from existing processes to the new ML-enabled system?
- What support resources are available during the critical go-live period?
- How will we measure success in the first weeks and months after deployment?
Critical Transition Point: At this stage, you should have a fully deployed, integrated, and monitored ML system running in production. The model should be seamlessly integrated into business processes, with robust monitoring and alerting in place to ensure ongoing reliability. Operational teams should be trained and equipped to manage the system, with clear documentation and support processes. You're now ready to transition into the ongoing maintenance and optimization phase of the ML lifecycle.
Summary of Step 6
In short, the deployment and integration phase involves transitioning your validated model from development into a production environment where it can deliver business value through reliable, scalable, and secure model serving. This begins with designing appropriate deployment architecture that meets your latency, scalability, and availability requirements, whether through real-time APIs, batch processing pipelines, or hybrid approaches. The technical implementation includes setting up model serving infrastructure with proper load balancing, caching, and container orchestration, while ensuring seamless integration with existing business systems, databases, and workflows. Security and compliance considerations are critical, requiring proper encryption, access controls, audit logging, and adherence to regulatory requirements like GDPR or HIPAA. Performance optimization involves implementing auto-scaling, model compression, and intelligent caching strategies to handle varying loads efficiently. Robust model versioning and CI/CD pipelines enable safe deployment of model updates through techniques like A/B testing, canary deployments, and automated rollback capabilities. Comprehensive monitoring and alerting systems track both technical performance metrics and business outcomes, with drift detection to identify when models need retraining. The phase concludes with thorough documentation, operational team training, and controlled go-live processes that ensure smooth transition from development to production operations. Success in this phase requires close collaboration between data science, engineering, and operations teams to balance technical performance with operational reliability and business requirements.
How to move forward? Start by clearly defining your deployment requirements including latency, throughput, availability, and security needs, then design your architecture accordingly rather than trying to retrofit requirements later. Invest heavily in automation for testing, deployment, and monitoring - manual processes become bottlenecks and sources of error at scale. Plan for gradual rollouts and always have rollback strategies ready before deploying to production. Don't underestimate the importance of comprehensive monitoring and alerting - you need to know about problems before your users do. Ensure operational teams are properly trained and have clear documentation before go-live. Consider describing your deployment architecture and requirements to an LLM, asking it to identify potential single points of failure in your design, suggest monitoring metrics you might have overlooked, recommend security best practices for your specific deployment pattern, and highlight operational challenges that commonly arise with your type of ML system in production environments.
Objective: Systematically track model performance over time to detect degradation and identify optimization opportunities.
Key Tasks:
- Performance Trend Analysis: Track accuracy, precision, recall, and business metrics over time to identify gradual degradation
- Real-time Performance Dashboards: Maintain live dashboards showing current model performance against historical baselines
- Business Impact Measurement: Monitor how model predictions translate to actual business outcomes and ROI
- Comparative Analysis: Benchmark current model performance against original validation results and business expectations
- Segment-Specific Monitoring: Track performance across different user groups, geographic regions, or business units
- Prediction Distribution Analysis: Monitor changes in prediction patterns and confidence distributions
- Error Pattern Investigation: Analyze prediction errors to identify systematic issues or emerging failure modes
- Performance Attribution: Understand whether performance changes are due to model, data, or environmental factors
Critical Questions to Ask:
- Is our model performance declining over time, and if so, at what rate?
- Are there specific segments or scenarios where performance is particularly problematic?
- How do current business outcomes compare to our original projections?
- Are we seeing new types of errors that weren't present during initial validation?
- What external factors might be influencing our model's performance?
- How sensitive is our business to different types of performance degradation?
Objective: Identify and respond to changes in input data characteristics that may affect model performance.
Key Tasks:
- Statistical Drift Detection: Implement tests like Kolmogorov-Smirnov, Chi-square, or Population Stability Index to detect distribution changes
- Feature Drift Monitoring: Track individual feature distributions and identify which specific inputs are changing
- Covariate Shift Detection: Monitor changes in the relationship between features and target variables
- Concept Drift Identification: Detect when the underlying relationships your model learned have fundamentally changed
- Drift Severity Assessment: Quantify the magnitude and business impact of detected drift
- Automated Drift Alerts: Set up intelligent alerting systems that trigger when drift exceeds acceptable thresholds
- Root Cause Analysis: Investigate the business or technical reasons behind significant data changes
- Drift Documentation: Maintain records of drift events and their resolutions for pattern recognition
Critical Questions to Ask:
- What level of data drift is acceptable before model retraining becomes necessary?
- Are we detecting drift early enough to take corrective action before business impact?
- What are the underlying causes of the drift we're observing?
- How can we distinguish between normal variation and problematic drift?
- Should we adjust our drift detection thresholds based on business seasonality?
- What automated responses should trigger when different types of drift are detected?
Objective: Implement systematic processes for updating models to maintain performance and adapt to changing conditions.
Key Tasks:
- Retraining Schedule Planning: Establish regular retraining intervals based on data drift patterns and business cycles
- Trigger-Based Retraining: Implement automated retraining when performance or drift thresholds are exceeded
- Incremental Learning: Implement online learning approaches that can adapt to new data without full retraining
- Feature Engineering Updates: Modify feature engineering pipelines to address new data patterns or business requirements
- Hyperparameter Re-optimization: Re-tune model parameters when retraining with significantly different data
- Model Architecture Evolution: Evaluate whether new algorithms or architectures might perform better on current data
- Transfer Learning Application: Leverage pre-trained models or transfer learning to improve retraining efficiency
- Validation Strategy Updates: Adapt validation approaches to account for temporal changes and new data patterns
Critical Questions to Ask:
- How frequently should we retrain our models to maintain optimal performance?
- What performance degradation threshold should trigger automatic retraining?
- Are there seasonal patterns that should influence our retraining schedule?
- How can we balance retraining costs with performance benefits?
- Should we retrain the entire model or focus on specific components?
- How do we validate that retrained models are actually better than existing ones?
Objective: Safely test model improvements and new versions through controlled experiments before full deployment.
Key Tasks:
- Experimental Design: Create statistically valid A/B tests for comparing model versions
- Traffic Splitting: Implement sophisticated traffic routing to ensure fair comparison between model versions
- Champion-Challenger Framework: Establish ongoing testing of new models against current production versions
- Multi-Armed Bandit Testing: Implement dynamic allocation strategies that optimize for both learning and performance
- Statistical Significance Testing: Apply proper statistical methods to determine when results are conclusive
- Business Metric Focus: Design experiments that measure impact on key business outcomes, not just technical metrics
- Experiment Duration Planning: Determine appropriate test lengths to account for seasonality and statistical power
- Rollback Procedures: Maintain ability to quickly revert to previous model versions if experiments show negative results
Critical Questions to Ask:
- How can we design experiments that accurately measure business impact?
- What sample sizes and test durations do we need for statistically significant results?
- How do we handle seasonal effects and external factors in our experiments?
- What safeguards prevent experiments from causing significant business harm?
- How do we balance the desire for rapid iteration with the need for rigorous testing?
- Are we testing the right metrics to capture true business value?
Objective: Ensure ongoing compliance with regulatory requirements and maintain proper governance over model lifecycle.
Key Tasks:
- Audit Trail Maintenance: Keep comprehensive records of all model changes, decisions, and performance metrics
- Regulatory Compliance Monitoring: Ensure ongoing adherence to GDPR, CCPA, financial regulations, or industry-specific requirements
- Model Risk Management: Implement frameworks for assessing and managing model-related risks
- Documentation Updates: Maintain current model cards, technical documentation, and business justifications
- Approval Workflow Management: Ensure proper review and approval processes for model updates and changes
- Bias Monitoring: Continuously monitor for algorithmic bias and fairness issues across different populations
- Ethics Review Process: Regular evaluation of model use cases against ethical guidelines and societal impact
- Third-Party Audit Preparation: Maintain documentation and processes to support external audits and reviews
Critical Questions to Ask:
- Are we maintaining sufficient documentation to support regulatory audits?
- How do we ensure ongoing compliance as regulations evolve?
- What governance processes are needed for different types of model changes?
- Are we adequately monitoring and addressing potential bias issues?
- How do we balance innovation speed with governance requirements?
- What training do team members need to maintain proper governance practices?
Objective: Continuously improve the technical infrastructure supporting model operations for efficiency and reliability.
Key Tasks:
- Cost Optimization: Monitor and optimize infrastructure costs through right-sizing, auto-scaling, and resource management
- Performance Tuning: Continuously optimize system performance, latency, and throughput
- Capacity Planning: Forecast infrastructure needs based on usage growth and model complexity trends
- Technology Stack Evolution: Evaluate and implement new tools and technologies that improve operations
- Disaster Recovery Testing: Regularly test backup and recovery procedures to ensure business continuity
- Security Updates: Maintain current security patches and implement evolving security best practices
- Monitoring Enhancement: Continuously improve monitoring capabilities and alert effectiveness
- Process Automation: Identify and automate repetitive operational tasks to reduce human error and improve efficiency
Critical Questions to Ask:
- Are we operating our infrastructure as efficiently and cost-effectively as possible?
- What bottlenecks or limitations might constrain our future growth?
- How can we improve system reliability and reduce downtime?
- Are there new technologies that could significantly improve our operations?
- How well-prepared are we for disaster scenarios or major system failures?
- What operational tasks should be automated to improve efficiency and reliability?
Objective: Capture institutional knowledge and develop team capabilities to support long-term model lifecycle management.
Key Tasks:
- Lessons Learned Documentation: Systematically capture insights from model performance, failures, and successes
- Best Practices Development: Codify organizational best practices for model development and operations
- Team Training Programs: Develop ongoing training to keep team skills current with evolving technologies
- Knowledge Sharing Sessions: Regular sessions to share insights across different model teams and projects
- Cross-Training Implementation: Ensure team members can support multiple models and systems
- External Learning Integration: Stay current with industry developments and research that could benefit operations
- Mentorship Programs: Establish programs to develop junior team members and preserve institutional knowledge
- Community Engagement: Participate in external communities and conferences to learn from industry peers
Critical Questions to Ask:
- How do we capture and preserve critical knowledge as team members change?
- What skills gaps exist in our team that could impact model operations?
- Are we learning effectively from our successes and failures?
- How do we stay current with rapidly evolving ML technologies and practices?
- What knowledge sharing mechanisms work best for our organization?
- How do we balance specialization with the need for cross-functional capabilities?
Objective: Manage the end-of-life process for models that are no longer effective or relevant.
Key Tasks:
- Retirement Criteria Definition: Establish clear criteria for when models should be retired or replaced
- Impact Assessment: Evaluate the business and technical impact of retiring specific models
- Transition Planning: Develop plans for migrating to new models or alternative solutions
- Data Archival: Properly archive model artifacts, training data, and performance history
- Dependency Management: Identify and manage systems or processes that depend on models being retired
- Communication Planning: Inform stakeholders about model retirement timelines and impacts
- Resource Reallocation: Plan for redeployment of computational and human resources
- Legacy System Maintenance: Determine what level of support to maintain for deprecated models during transition periods
Critical Questions to Ask:
- What criteria should trigger model retirement decisions?
- How do we balance the cost of maintaining old models with the risk of retiring them too early?
- What transition period is needed to safely migrate dependent systems?
- How do we preserve important insights and learnings from retired models?
- What ongoing obligations do we have for models that affect historical decisions?
- How do we communicate model retirement plans to affected stakeholders?
Objective: Manage the overall portfolio of ML models and plan for future development and optimization.
Key Tasks:
- Model Portfolio Assessment: Regularly evaluate the performance and business value of all deployed models
- Resource Allocation Planning: Optimize allocation of development and operational resources across the model portfolio
- Technology Roadmap Development: Plan adoption of new technologies and methodologies across the ML pipeline
- Business Alignment Reviews: Ensure ML initiatives continue to align with evolving business strategy and priorities
- ROI Analysis: Conduct regular analysis of return on investment for ML initiatives
- Competitive Analysis: Monitor industry developments and competitive ML capabilities
- Innovation Pipeline Management: Balance maintenance of existing models with development of new capabilities
- Risk Portfolio Management: Assess and manage risks across the entire portfolio of ML applications
Critical Questions to Ask:
- Which models in our portfolio provide the highest business value and should receive priority investment?
- Are we allocating our resources optimally across development, maintenance, and innovation?
- How do our ML capabilities compare to industry benchmarks and competitors?
- What emerging technologies or methodologies should we be planning to adopt?
- Are our ML initiatives properly aligned with current business strategy and priorities?
- How do we balance the desire for innovation with the need for reliable operations?
Critical Success Factors: This final phase represents the longest portion of the ML lifecycle, often lasting years after initial deployment. Success requires establishing sustainable processes, maintaining team expertise, and continuously adapting to changing business and technical conditions. The goal is not just to keep models running, but to continuously improve their business value while managing risks and costs effectively. Organizations that excel in this phase treat ML as a core business capability requiring ongoing investment and strategic management.
Summary of Step 7
In short, the model maintenance and lifecycle management phase represents the longest and most critical portion of the ML lifecycle, focused on ensuring deployed models continue delivering business value over time through systematic monitoring, updates, and optimization. This involves continuous performance monitoring to detect degradation and measure business impact, combined with data drift detection to identify when changing input patterns threaten model effectiveness. Systematic retraining strategies maintain model performance through scheduled updates, trigger-based retraining when thresholds are exceeded, and A/B testing to safely validate improvements before full deployment. Governance and compliance management ensures ongoing adherence to regulatory requirements while maintaining proper audit trails and addressing evolving bias and fairness concerns. Infrastructure optimization focuses on cost management, performance tuning, and capacity planning to support growing demands efficiently. Knowledge management preserves institutional learning and develops team capabilities to handle evolving technologies and responsibilities. Eventually, model retirement and lifecycle transition processes manage the end-of-life for outdated models while ensuring smooth migration to newer solutions. Strategic portfolio management balances resources across maintenance, optimization, and innovation while ensuring ML initiatives remain aligned with business objectives. Success in this phase requires treating ML as a core business capability that needs ongoing investment, not a one-time technical implementation, with sustainable processes that can adapt to changing business and technical conditions over years of operation.
How to move forward? Establish robust monitoring and alerting systems from day one of production deployment, as problems caught early are much easier and cheaper to fix than those discovered after significant business impact. Invest in automation for routine maintenance tasks like drift detection, performance monitoring, and basic retraining workflows to reduce operational burden and human error. Don't underestimate the importance of maintaining detailed documentation and institutional knowledge - teams change over time, and undocumented tribal knowledge becomes a major risk. Plan for model retirement and replacement from the beginning rather than trying to keep models running indefinitely. Balance the desire for cutting-edge techniques with the need for reliable, maintainable solutions. Consider describing your maintenance strategy and current challenges to an LLM, asking it to identify potential operational risks you might have overlooked, suggest automation opportunities for your specific ML pipeline, recommend governance frameworks appropriate for your industry and regulatory environment, and highlight emerging best practices for long-term ML operations that could benefit your organization.
Successfully implementing this ML lifecycle requires a systematic, iterative approach that balances methodical planning with adaptive execution. The key is to treat each phase as both a distinct milestone and part of a continuous improvement cycle. Start with smaller, well-defined problems to build organizational capability before tackling complex, high-stakes projects. Each phase should produce concrete deliverables that can be reviewed, validated, and built upon, creating a clear trail of decisions and learnings that inform future projects.
Begin with thorough preparation: The requirements and data phases (Steps 1-3) deserve significant time investment - rushing through problem definition and data preparation to get to "the fun modeling part" is the most common cause of ML project failure. Spend 40-50% of your total project time on these foundational phases. The clarity achieved here will save exponentially more time later and dramatically increase your chances of delivering business value.
Embrace iteration: While presented linearly, this lifecycle is inherently iterative. Discoveries in later phases often require revisiting earlier decisions. Build flexibility into your timeline and processes to accommodate this reality. Plan for multiple cycles through phases 4-5 as you refine your approach based on validation results.
Modern LLMs like Claude, GPT-4, or specialized coding models can significantly accelerate each phase of the ML lifecycle when used strategically. The key is understanding their strengths and limitations, then crafting prompts that extract maximum value while avoiding common pitfalls.
Requirements & Data Phases (Steps 1-3): Use LLMs as intelligent brainstorming partners and assumption challengers. They excel at helping you think through edge cases, identify potential biases, and suggest domain-specific considerations you might miss. For data work, they can help with exploratory analysis code, data cleaning strategies, and feature engineering ideas.
Modeling Phase (Steps 4-5): LLMs are particularly valuable for algorithm selection guidance, hyperparameter optimization strategies, and code implementation. They can suggest appropriate evaluation metrics for your specific problem type and help interpret model results. However, be cautious about blindly following their recommendations - always validate suggestions against your domain knowledge and data characteristics.
Deployment & Maintenance (Steps 6-7): LLMs can assist with infrastructure design patterns, monitoring strategies, and operational best practices. They're excellent for generating deployment documentation, suggesting testing strategies, and helping troubleshoot production issues.
Context-Rich Prompting: Always provide comprehensive context about your specific problem, data characteristics, constraints, and business requirements. Generic ML advice is rarely as valuable as guidance tailored to your situation.
Example Context Template:
"I'm working on a [problem type] for [industry/domain] with [data characteristics].
Our constraints include [technical/business constraints].
We've discovered [key findings from previous phases].
Our stakeholders prioritize [business objectives].
Given this context, [specific question]."
Progressive Refinement: Start with broad questions to explore the solution space, then progressively narrow down to specific implementation details. Use follow-up questions to dive deeper into promising directions.
Assumption Validation: Explicitly ask LLMs to challenge your assumptions and identify potential blind spots. Phrases like "What might I be overlooking?" or "What assumptions am I making that could be problematic?" often yield valuable insights.
Implementation-Focused Queries: When seeking coding help, be specific about your tech stack, data format, and expected outputs. Request both the code and the reasoning behind design choices.
Example Implementation Prompt:
"I need to implement [specific functionality] using [tech stack] for [data format/size].
The output should [specific requirements].
Please provide code that handles [edge cases] and follows [specific patterns/standards].
Explain your design choices and highlight any assumptions."
Modular Design: Structure your code with clear separation between data processing, feature engineering, modeling, and evaluation components. This modularity facilitates testing, debugging, and reuse across projects.
Version Control Everything: Use Git not just for code, but also for tracking changes to data processing scripts, configuration files, and documentation. Consider using tools like DVC (Data Version Control) for managing datasets and model artifacts.
Configuration Management: Externalize all parameters, file paths, and settings into configuration files. This makes experimentation easier and reduces the risk of hardcoded values causing production issues.
Reproducibility by Design: Set random seeds, document dependency versions, and create reproducible environments using tools like Docker, conda environments, or virtual environments. Future you (and your colleagues) will thank you.
Start Simple: Begin with well-established tools and libraries rather than the latest experimental frameworks. Pandas, scikit-learn, and matplotlib provide a solid foundation for most projects. Add complexity only when clearly justified by your specific requirements.
Cloud vs Local: For initial development, local environments often provide faster iteration cycles. Move to cloud resources when you need more computational power, collaboration features, or production-scale infrastructure. Major cloud providers (AWS, GCP, Azure) offer ML-specific services that can accelerate development.
Documentation and Collaboration: Invest in tools that facilitate collaboration and knowledge sharing. Jupyter notebooks are excellent for exploration and presentation, but consider transitioning to modular Python scripts for production code. Use tools like MLflow or Weights & Biases for experiment tracking.
Test-Driven Development for ML: Write tests for your data processing functions, feature engineering logic, and model evaluation code. While testing ML models themselves is challenging, you can and should test the code that supports them.
Data Quality Checks: Implement automated data quality checks that run whenever new data is processed. These should validate data schemas, check for expected ranges, and flag unusual patterns.
Model Validation Beyond Accuracy: Implement comprehensive validation that checks model behavior on edge cases, evaluates fairness across different groups, and validates that model predictions align with business logic.
Regular Check-ins: Establish regular review meetings with business stakeholders throughout the project, not just at major milestones. This prevents misalignment and ensures you're building what's actually needed.
Visualization-Heavy Communication: Invest time in creating clear, compelling visualizations of your data insights and model results. Non-technical stakeholders understand pictures better than statistics.
Manage Expectations Proactively: ML projects are inherently uncertain. Communicate this uncertainty honestly while maintaining confidence in your systematic approach.
Cross-Functional Collaboration: Successful ML projects require close collaboration between data scientists, software engineers, domain experts, and business stakeholders. Plan for this collaboration rather than treating it as an afterthought.
Knowledge Transfer: Document not just what you did, but why you made specific choices. This context is crucial for team members who inherit the project or need to make similar decisions in the future.
The "Shiny Object" Trap: Resist the urge to use the latest, most complex algorithms without justification. Simple, well-understood models often outperform complex ones and are much easier to maintain and explain.
Data Leakage: Be paranoid about data leakage. When in doubt, ask: "Would this information be available at prediction time in the real world?" If not, don't use it.
Optimization Myopia: Don't optimize solely for technical metrics. Always validate that technical improvements translate to business value.
Deployment Afterthought: Plan for deployment from the beginning. Models that work in notebooks but can't be deployed are academic exercises, not business solutions.
Success in ML projects isn't just about achieving good model performance - it's about delivering sustained business value. Establish both technical and business metrics from the start, and track them throughout the project lifecycle. Create feedback loops that capture learnings from each project and apply them to future initiatives.
Remember that ML is as much about the process as the destination. A systematic, well-documented approach that delivers modest improvements consistently is far more valuable than heroic efforts that achieve spectacular results once but can't be replicated or maintained.
The ML lifecycle presented here provides a framework, not a rigid prescription. Adapt it to your organization's needs, constraints, and culture. The goal is to build sustainable ML capabilities that create lasting business value, not just impressive demos. With careful planning, systematic execution, and judicious use of modern AI tools to augment human expertise, you can dramatically increase your chances of ML project success.
- Models of Machine Learning at Oak Tree Technologies
- Importance of Requirements Gathering for Business Analysts
- Importance of Requirements Gathering in Software Development
- ML | Understanding Data Processing
- Building Robust ML Pipelines: Focus on Data Preprocessing and Feature Engineering
- Feature Engineering for Machine Learning
- Model Selection at Schinema
- Model Selection at ProjectPro
- K-Fold Cross Validation at Medium
- Cross-Validation at Data Aspirant
- Real-Time ML Operational Deployment Pipeline
- Best Practices to Deploying your ML Model at Medium
- Monitoring Workflow for ML Systems at nannyML
- Testing in Production, the safe Way at Medium