Worst-case witness size for stateless validation #9378
Comments
|
It looks like I will need to split this into several stages. Data receipts can become quite tricky to figure out in which witnesses they belong inside, or how many of them can clump up at one place. I will write more details about them in a future comment. For now, let me list for action receipts how large they can become based on gas and other runtime limits. Network Message Sizes
The table above shows that function call actions can become the largest per gas unit. A chunk filled with function calls could be up to 358MB large, just for storing the actions. This is true today, before we even start talking about changes that would be necessary for stateless validation. |
|
The data dependency rabbit hole looks a bit too deep to reach a conclusion just yet. I will ignore them for now and just look at other boundaries we can figure out. |
Accessed state size per actionTo understand how much state an action receipt may access in the worst case, we have to consider two parts.
ValuesObservations:
Number of trie nodes accessedObservations:
ResultsI've done all the analysis in the spreadsheet I also used for calculating how large receipts themselves are. Here is the summary. Note that the first row (action receipt) is always necessary, so the touched trie nodes for a account creation transaction will be
* empty action receipt needs to access data receipts, these calculations are still ongoing Conclusion
|
Suggestion to enforce ~45MB witness size per chunkHere is an idea how to limit the worst-case sizes. We could add additional chunk space limits. Today, it's already limited by gas, by compute costs (in case of known-to-be-undercharged parameters), and by the size of transactions. We can add more conditions. Specifically, I would like to add a limit for:
For this to work, we need good congestion control. If the delayed receipts queue gets too long, this itself could blow up the witness size. Let's say we can keep the queue length per shard below 10MB, then we have used 3 * 10MB = 30MB of witness size so far. The remaining 15MB come from assumption around how we enforce the limit. Note on enforcing (soft-)limitsTo avoid re-execution, we might want to make these soft limits. (The last applied receipt is allowed to go beyond, we just don't execute another one.) That's how we are currently handling all existing limits. But that means the real limit is the soft limit + the largest possible size of single receipt application. If we do nothing, this completely blows up the limits back to the 100s of MBs territory. To limit the effect of the last receipt that goes above the soft limit, I suggest we also add per-receipt limits to network bandwidth and witness size. Going above the limit will result in an error, which is observable by users as a new failure mode. But the hypothesis is that we can set the limit high enough that normal usage will not hit them. Ballpark numbers:
Hard limit?The obvious alternative would be to just make these hard limits. As in, the receipt that breaches the limit is reverted and will only be applied in the next chunk. In this design, the per-receipt limit would be the same as the per chunk limit. Single receipts that go above the chunk limit will never execute successfully, so we will also need to make them explicitly fail which again introduces a new failure mode for receipt execution. Still, enforcing hard limits could bring down the worst-case witness size from ~45MB to ~30MB if we just take all the suggested numbers used so far. |
@jakmeier , Is this already handled with local congestion control? Or are you suggesting us to do global congestion control as well? |
|
Sounds like this needs NEP? |
|
|
@robin-near, when we are loading trie in memory, how much do we have to pay attention on TTN? Can we completely get rid of it? In other words, can we cross out the following statement by Jakob?
|
|
Trie node access would be pretty cheap, yeah. But writes are not completely free (coz they gotta go to disk), so probably keep that. Not sure about the empty receipts part - what does that mean? |
Access may be cheap but this issue here is specifically about witness size in the worst case. (hard limits we can proof, not practical usage patterns) Even if it's served from memory, you still have to upload and download over the network, potentially archive it and so on.
With stateless validation, my assumption here is/was that each trie node involved in the state transition needs to be in the witness. (Assuming pre-ZK implementation) An empty receipt, as in a receipt with no actions, is still a receipt that is stored and loaded from the trie. But because it's empty, it's particularly cheap in terms of gas costs. In other words, many empty receipts may be included in a single chunk. Does that make sense? |
|
Oh sorry I was answering Yoon's question without looking at the context. For the greater state witness size issue I don't have any useful comment at this moment. |
AFAIU the cost of touching a single Trie node is I'm currently trying to construct a contract that generates the largest storage proof possible, and for now I think the most efficient option is to read large values. Cost of reading one value byte is only So far I was able to construct a receipt which generates 24MB of storage proof by reading large values. It's only half of the theoretical maxium, but I guess other costs get in the way. |
…tion (#11069) During receipt execution we record all touched nodes from the pre-state trie. Those recorded nodes form the storage proof that is sent to validators, and validators use it to execute the receipts and validate the results. In #9378 it's stated that in a worst case scenario a single receipt can generate hundreds of megabytes of storage proof. That would cause problems, as it'd cause the `ChunkStateWitness` to also be hundreds of megabytes in size, and there would be problems with sending this much data over the network. Because of that we need to limit the size of the storage proof. We plan to have two limits: * per-chunk soft limit - once a chunk has more than X MB of storage proof we stop processing new receipts, and move the remaining ones to the delayed receipt queue. This has been implemented in #10703 * per-receipt hard limit - once a receipt generates more than X MB of storage proof we fail the receipt, similarly to what happens when a receipt goes over the allowed gas limit. This one is implemented in this PR. Most of the hard-limit code is straightforward - we need to track the size of recorded storage and fail the receipt if it goes over the limit. But there is one ugly problem: #10890. Because of the way current `TrieUpdate` works we don't record all of the storage proof in real time. There are some corner cases (deleting one of two children of a branch) in which some nodes are not recorded until we do `finalize()` at the end of the chunk. This means that we can't really use `Trie::recorded_storage_size()` to limit the size, as it isn't fully accurate. If we do that, a malicious actor could prepare receipts which seem to have only 1MB of storage proof during execution, but actually record 10MB during `finalize()`. There is a long discussion in #10890 along with some possible solution ideas, please read that if you need more context. This PR implements Idea 1 from #10890. Instead of using `Trie::recorded_storage_size()` we'll use `Trie::recorded_storage_size_upper_bound()`, which estimates the upper bound of recorded storage size by assuming that every trie removal records additional 2000 bytes: ```rust /// Size of the recorded state proof plus some additional size added to cover removals. /// An upper-bound estimation of the true recorded size after finalization. /// See #10890 and #11000 for details. pub fn recorded_storage_size_upper_bound(&self) -> usize { // Charge 2000 bytes for every removal let removals_size = self.removal_counter.saturating_mul(2000); self.recorded_storage_size().saturating_add(removals_size) } ``` As long as the upper bound is below the limit we can be sure that the real recorded size is also below the limit. It's a rough estimation, which often exaggerates the actual recorded size (even by 20+ times), but it could be a good-enough/MVP solution for now. Doing it in a better way would require a lot of refactoring in the Trie code. We're now [moving fast](https://near.zulipchat.com/#narrow/stream/407237-core.2Fstateless-validation/topic/Faster.20decision.20making), so I decided to go with this solution for now. The upper bound calculation has been added in a previous PR along with the metrics to see if using such a rough estimation is viable: #11000 I set up a mainnet node with shadow validation to gather some data about the size distribution with mainnet traffic: [Metrics link](https://nearinc.grafana.net/d/edbl9ztm5h1q8b/stateless-validation?orgId=1&var-chain_id=mainnet&var-shard_id=All&var-node_id=ci-b20a9aef-mainnet-rpc-europe-west4-01-84346caf&from=1713225600000&to=1713272400000) 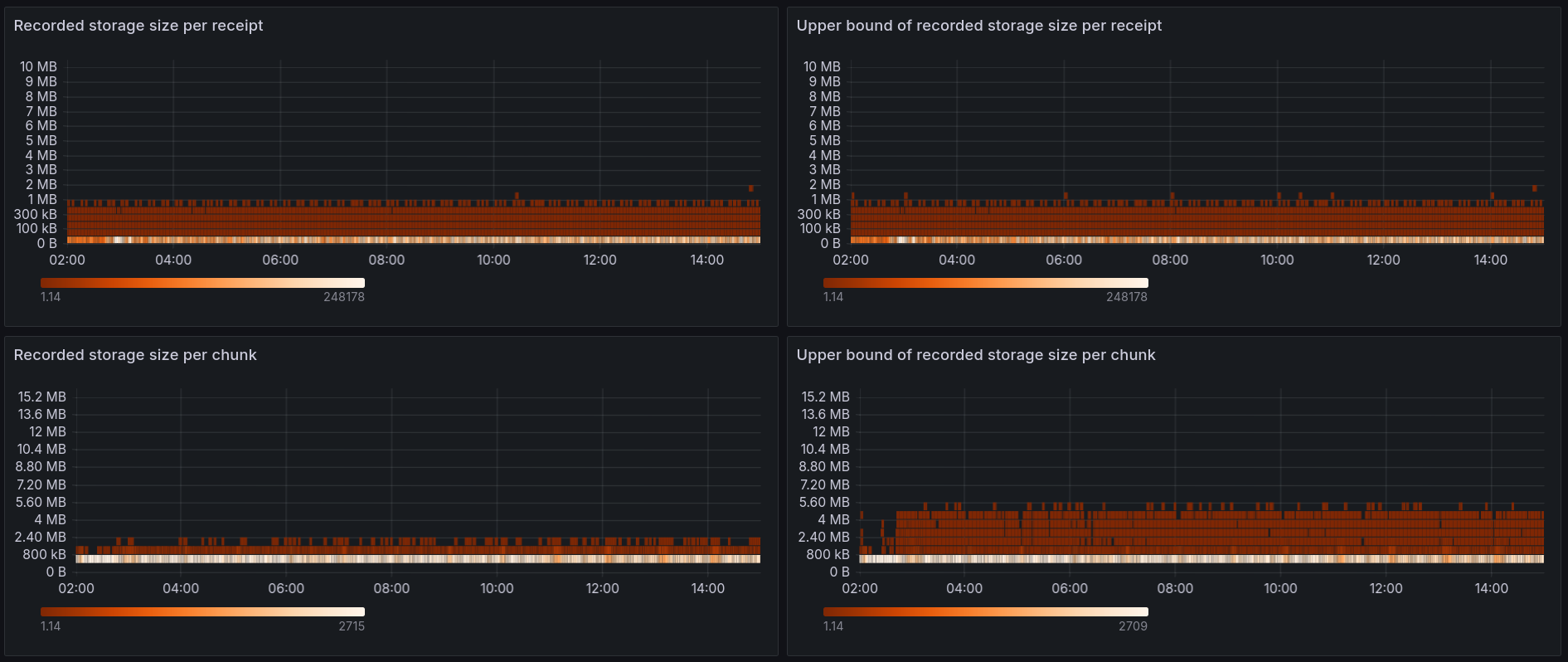  The metrics show that: * For all receipts both the recorded size and the upper bound estimate are below 2MB * Overwhelming majority of receipts generate < 50KB of storage proof * For all chunks the upper bound estimate is below 6MB * For 99% of chunks the upper bound estimate is below 3MB Based on this I believe that we can: * Set the hard per-receipt limit to 4MB. All receipts were below 2MB, but it's good to have a bit of a safety margin here. This is a hard limit, so it might break existing contracts if they turn out to generate more storage proof than the limit. * Set the soft per-chunk limit to 3MB. 99% of chunks will not be affected by this limit. For the 1% that hit the limit they'll execute fewer receipts, with the rest of the receipts put into the delayed receipt queue. This slightly lowers throughput of a single chunk, but it's not a big slowdown, by ~1%. Having a 4MB per-receipt hard limit and a 3MB per-chunk soft limit would give us a hard guarantee that for all chunks the total storage proof size is below 7MB. It's worth noting that gas usage already limits the storage proof size quite effectively. For 98% of chunks the storage proof size is already below 2MB, so the limit isn't really needed for typical mainnet traffic. The limit matters mostly for stopping malicious actors that'd try to DoS the network by generating large storage proofs. Fixes: #11019
@jancionear Yes, you are correct for cases where we actually charge But I am not up to speed with all stateless validation changes. If you reintroduce the TTN cost for state reads as part of stateless validation, indeed that changes the calculations completely. |
With stateless validation we always walk down the trie, even when using flat storage, because we have to record the touched nodes and place them in the storage proof: fn lookup_from_flat_storage(
&self,
key: &[u8],
) -> Result<Option<OptimizedValueRef>, StorageError> {
let flat_storage_chunk_view = self.flat_storage_chunk_view.as_ref().unwrap();
let value = flat_storage_chunk_view.get_value(key)?;
if self.recorder.is_some() {
// If recording, we need to look up in the trie as well to record the trie nodes,
// as they are needed to prove the value. Also, it's important that this lookup
// is done even if the key was not found, because intermediate trie nodes may be
// needed to prove the non-existence of the key.
let value_ref_from_trie =
self.lookup_from_state_column(NibbleSlice::new(key), false)?;
debug_assert_eq!(
&value_ref_from_trie,
&value.as_ref().map(|value| value.to_value_ref())
);
}
Ok(value.map(OptimizedValueRef::from_flat_value))
}I thought that because of this we also charge for all TTN on the read path, but now I see that we actually don't charge gas for the trie read, Now the math much more sense to me, if we don't charge for TTN then there could be severe undercharging. 👍 👍 |
Goals
Background
If we want to move to stateless validation, we need to understand the witness sizes involved.
This issue is about finding out hard limits that are never exceeded even when maliciously crafted transactions are sent in a perfectly corrupted order.
Why should NEAR One work on this
In the world of stateless validation, understanding and limiting state witness size is the key as time to deliver a state witness over the network is critical part of stateless validation. We need to make sure state witness stays within reasonable limit so block processing time stays similar to what we have now and does not overload validator nodes.
One known problem is that a contract could be 4MB in size but a call to it might only consume 2.5 Tgas in execution cost. In other words, we can fit 400 x 4 MB = 1.6GB of WASM contract code in a single chunk.
Adding a gas cost that scales with the real contract code size would be a way to limit this.
What needs to be accomplished
Task list
Tasks
The text was updated successfully, but these errors were encountered: