Add metric for recorded storage proof size, also calculate adjusted size based on number of trie removals #11000
Conversation
Codecov ReportAll modified and coverable lines are covered by tests ✅
Additional details and impacted files@@ Coverage Diff @@
## master #11000 +/- ##
==========================================
- Coverage 71.33% 71.31% -0.02%
==========================================
Files 760 758 -2
Lines 152288 152602 +314
Branches 152288 152602 +314
==========================================
+ Hits 108640 108834 +194
- Misses 39176 39309 +133
+ Partials 4472 4459 -13
Flags with carried forward coverage won't be shown. Click here to find out more. ☔ View full report in Codecov by Sentry. |
| @@ -313,6 +338,40 @@ fn buckets_for_compute() -> Option<Vec<f64>> { | |||
| ]) | |||
| } | |||
|
|
|||
| fn buckets_for_storage_proof_size() -> Vec<f64> { | |||
There was a problem hiding this comment.
nit: I would consider exponential_buckets here and below to minimise number of code lines
There was a problem hiding this comment.
I would recommend decreasing the range and step size. Currently most "interesting" values are in the range 1MB - 16MB, so having more granular step would be nice there. Anything below 100KB is pretty much the same and can be classified as "very small", the same for anything above 16MB.
So I would start with 100KB and have multiplier of something like 1.2-1.5, up to you.
There was a problem hiding this comment.
I would recommend decreasing the range and step size. Currently most "interesting" values are in the range 1MB - 16MB, so having more granular step would be nice there. Anything below 100KB is pretty much the same and can be classified as "very small", the same for anything above 16MB. So I would start with 100KB and have multiplier of something like 1.2-1.5, up to you.
Ok, I can remove the smaller buckets in the chunk-level metrics, but I'll keep them in the receipt-level ones, receipts should consume much less than 1MB (although you never know x.x)
| @@ -1436,6 +1439,21 @@ impl Runtime { | |||
| let node_counter_after = state_update.trie().get_trie_nodes_count(); | |||
| tracing::trace!(target: "runtime", ?node_counter_before, ?node_counter_after); | |||
|
|
|||
| let recorded_storage_diff = state_update | |||
There was a problem hiding this comment.
I would also measure total adjusted storage size (+ total, + measure diff?) because this is our target metric, estimating how much data can be sent over network.
There was a problem hiding this comment.
Good idea, added chunk-level metrics. One measures the real recorded size (post finalization), the other records our upper bound estimation (pre-finalization). There's also a third metric to measure the difference between them.
👍, upper_bound better reflects what's going on, changed it do that. |
| @@ -313,6 +338,40 @@ fn buckets_for_compute() -> Option<Vec<f64>> { | |||
| ]) | |||
| } | |||
|
|
|||
| fn buckets_for_storage_proof_size() -> Vec<f64> { | |||
There was a problem hiding this comment.
I would recommend decreasing the range and step size. Currently most "interesting" values are in the range 1MB - 16MB, so having more granular step would be nice there. Anything below 100KB is pretty much the same and can be classified as "very small", the same for anything above 16MB.
So I would start with 100KB and have multiplier of something like 1.2-1.5, up to you.
In #11000 I added some metrics for the size of receipt/chunk storage proofs, along with upper bound estimation of those sizes. The buckets chosen in the PR weren't that good, as I didn't know what sort of values to expect. I have spent some time looking at the data and I'd like to adjust the buckets to better fit the data distribution. * Most receipts generate < 100KB of storage proof, so for receipt-level sizes I'd like to use a few small buckets and then some more big buckets to catch the big outliers. * Chunk level proofs are usually within 2-6MB, so I changed the metric to use buckets between 0 and 15MB with 500KB increases * The ratio for receipts was sometimes extremely high. I think it was due to small receipts (a receipt which writes little, but removes two nodes could easily shoot up to 50x ratio). Small receipts don't matter for the hard per receipt limit, so I excluded them from the metric to keep the values reasonable. You can see how the new metrics look like here: https://nearinc.grafana.net/d/edbl9ztm5h1q8b/stateless-validation?orgId=1&var-chain_id=mainnet&var-shard_id=All&var-node_id=ci-b20a9aef-mainnet-rpc-europe-west4-01-84346caf&from=now-15m&to=now
…tion (#11069) During receipt execution we record all touched nodes from the pre-state trie. Those recorded nodes form the storage proof that is sent to validators, and validators use it to execute the receipts and validate the results. In #9378 it's stated that in a worst case scenario a single receipt can generate hundreds of megabytes of storage proof. That would cause problems, as it'd cause the `ChunkStateWitness` to also be hundreds of megabytes in size, and there would be problems with sending this much data over the network. Because of that we need to limit the size of the storage proof. We plan to have two limits: * per-chunk soft limit - once a chunk has more than X MB of storage proof we stop processing new receipts, and move the remaining ones to the delayed receipt queue. This has been implemented in #10703 * per-receipt hard limit - once a receipt generates more than X MB of storage proof we fail the receipt, similarly to what happens when a receipt goes over the allowed gas limit. This one is implemented in this PR. Most of the hard-limit code is straightforward - we need to track the size of recorded storage and fail the receipt if it goes over the limit. But there is one ugly problem: #10890. Because of the way current `TrieUpdate` works we don't record all of the storage proof in real time. There are some corner cases (deleting one of two children of a branch) in which some nodes are not recorded until we do `finalize()` at the end of the chunk. This means that we can't really use `Trie::recorded_storage_size()` to limit the size, as it isn't fully accurate. If we do that, a malicious actor could prepare receipts which seem to have only 1MB of storage proof during execution, but actually record 10MB during `finalize()`. There is a long discussion in #10890 along with some possible solution ideas, please read that if you need more context. This PR implements Idea 1 from #10890. Instead of using `Trie::recorded_storage_size()` we'll use `Trie::recorded_storage_size_upper_bound()`, which estimates the upper bound of recorded storage size by assuming that every trie removal records additional 2000 bytes: ```rust /// Size of the recorded state proof plus some additional size added to cover removals. /// An upper-bound estimation of the true recorded size after finalization. /// See #10890 and #11000 for details. pub fn recorded_storage_size_upper_bound(&self) -> usize { // Charge 2000 bytes for every removal let removals_size = self.removal_counter.saturating_mul(2000); self.recorded_storage_size().saturating_add(removals_size) } ``` As long as the upper bound is below the limit we can be sure that the real recorded size is also below the limit. It's a rough estimation, which often exaggerates the actual recorded size (even by 20+ times), but it could be a good-enough/MVP solution for now. Doing it in a better way would require a lot of refactoring in the Trie code. We're now [moving fast](https://near.zulipchat.com/#narrow/stream/407237-core.2Fstateless-validation/topic/Faster.20decision.20making), so I decided to go with this solution for now. The upper bound calculation has been added in a previous PR along with the metrics to see if using such a rough estimation is viable: #11000 I set up a mainnet node with shadow validation to gather some data about the size distribution with mainnet traffic: [Metrics link](https://nearinc.grafana.net/d/edbl9ztm5h1q8b/stateless-validation?orgId=1&var-chain_id=mainnet&var-shard_id=All&var-node_id=ci-b20a9aef-mainnet-rpc-europe-west4-01-84346caf&from=1713225600000&to=1713272400000) 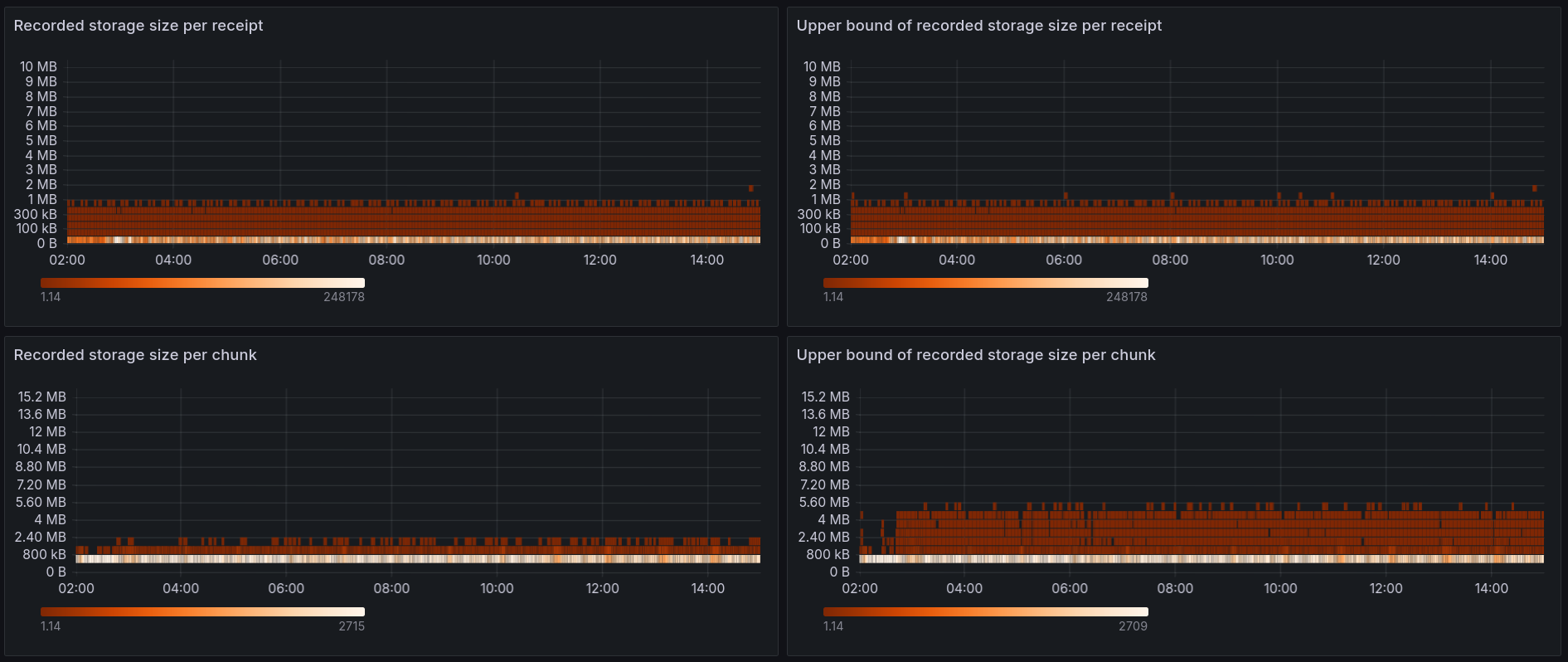  The metrics show that: * For all receipts both the recorded size and the upper bound estimate are below 2MB * Overwhelming majority of receipts generate < 50KB of storage proof * For all chunks the upper bound estimate is below 6MB * For 99% of chunks the upper bound estimate is below 3MB Based on this I believe that we can: * Set the hard per-receipt limit to 4MB. All receipts were below 2MB, but it's good to have a bit of a safety margin here. This is a hard limit, so it might break existing contracts if they turn out to generate more storage proof than the limit. * Set the soft per-chunk limit to 3MB. 99% of chunks will not be affected by this limit. For the 1% that hit the limit they'll execute fewer receipts, with the rest of the receipts put into the delayed receipt queue. This slightly lowers throughput of a single chunk, but it's not a big slowdown, by ~1%. Having a 4MB per-receipt hard limit and a 3MB per-chunk soft limit would give us a hard guarantee that for all chunks the total storage proof size is below 7MB. It's worth noting that gas usage already limits the storage proof size quite effectively. For 98% of chunks the storage proof size is already below 2MB, so the limit isn't really needed for typical mainnet traffic. The limit matters mostly for stopping malicious actors that'd try to DoS the network by generating large storage proofs. Fixes: #11019
In #10890 we considered adding extra 2000 bytes to the storage proof size for every removal operation on the trie (Idea 1). This PR implements the logic of recording the number of removals and calculating the adjusted storage proof size. It's not used in the soft witness size limit for now, as we have to evaluate how viable of a solution it is. There are concerns that charging 2000 bytes extra would cause the throughput to drop.
To evaluate the impact of adjusting the size calculation like this, the PR adds three new metrics.
near_receipt_recorded_size- a histogram of how much storage proof is recorded when processing a receipt. Apart from [stateless_validation][witness size soft limit] Count nodes needed for key updates in state witness size limit #10890, it'll help us estimate what the hard per-receipt storage proof size limit should be.near_receipt_adjusted_recorded_size- a histogram of adjusted storage proof size calculated when processing a receiptnear_receipt_adjusted_recorded_size_ratio- ratio of adjusted size to non-adjusted size. It'll allow us to evaluate how much the adjustment affects the final size. The hope is that contracts rarely delete things, so the effect will be small (a few percent), but it might turn out that this assumption is false and the adjusted size is e.g 2x higher that the non-adjusted one. In that case we'd have to reevaluate whether it's a viable solution.I'd like to run code from this branch on shadow validation nodes to gather data from mainnet traffic.