[stateless_validation] Add a soft size limit for state witness #10703
Conversation
|
Couple questions/comments.
|
| @@ -12,6 +12,9 @@ pessimistic_gas_price_inflation: { | |||
| denominator: 100, | |||
| } | |||
|
|
|||
| # Stateless validation config | |||
| state_witness_size_soft_limit: 1_000_000_000_000 | |||
There was a problem hiding this comment.
why are we using the old(?) value here?
There was a problem hiding this comment.
My understanding is that the runtime config is the one controlling the behavior; if we use the new value here it would break the existing runtime.
There was a problem hiding this comment.
Correct, this is the base parameter, applied to all versions starting at genesis up to the protocol version at which the parameter is overridden. Given that the parameter is an usize, I would perhaps look at making it 0xFFFF_FFFF_FFFF_FFFF, much like its done for RuntimeFeesConfig::test, so that there's no way in the world this limit is reached. Admittedly 10¹² is already huge enough to cover our bases, but the round number kinda makes one think that this is a proper parameter value, which can be slightly confusing to those who don't know the background behind this parameter.
There was a problem hiding this comment.
Right, make sense, will change to 0xFFFF_FFFF_FFFF_FFFF. The idea of 10^12 was to effectively have infinity 😅
There was a problem hiding this comment.
for some reason parsing 0xFFFF_FFFF_FFFF_FFFF did not work so I used 999_999_999_999_999 instead.
| } | ||
|
|
||
| pub fn recorded_storage(&mut self) -> PartialStorage { | ||
| let mut nodes: Vec<_> = self.recorded.drain().map(|(_key, value)| value).collect(); | ||
| nodes.sort(); | ||
| PartialStorage { nodes: PartialState::TrieValues(nodes) } | ||
| } | ||
|
|
||
| pub fn recorded_storage_size(&self) -> usize { | ||
| debug_assert!(self.size == self.recorded.values().map(|v| v.len()).sum::<usize>()); |
There was a problem hiding this comment.
This debug assert might be kinda expensive... If we are testing 1000 receipts and have 10000 recorded values then... might be kinda slow. What about we assert it at the very end of generating a state witness instead of every time?
There was a problem hiding this comment.
Conversely the debug assert expression gets evaluated in "development" builds only. While it is ideal to not have those be much slower than the release builds, there's already some precedent to debug asserts being slow enough to no longer give an accurate view of the release build performance, so if it is hard to move this elsewhere, then it is probably quite alright to leave it here...
There was a problem hiding this comment.
Yes, the reason why I had this as a part of debug_assert was because of the performance cost. This function is called once after every contract execution. Hopefully this shouldn't slow down things too much.
| @@ -12,6 +12,9 @@ pessimistic_gas_price_inflation: { | |||
| denominator: 100, | |||
| } | |||
|
|
|||
| # Stateless validation config | |||
| state_witness_size_soft_limit: 1_000_000_000_000 | |||
There was a problem hiding this comment.
Correct, this is the base parameter, applied to all versions starting at genesis up to the protocol version at which the parameter is overridden. Given that the parameter is an usize, I would perhaps look at making it 0xFFFF_FFFF_FFFF_FFFF, much like its done for RuntimeFeesConfig::test, so that there's no way in the world this limit is reached. Admittedly 10¹² is already huge enough to cover our bases, but the round number kinda makes one think that this is a proper parameter value, which can be slightly confusing to those who don't know the background behind this parameter.
| "max_locals_per_contract": 1000000, | ||
| "account_id_validity_rules_version": 1, | ||
| "yield_timeout_length_in_blocks": 200, | ||
| "max_yield_payload_size": 1024 |
There was a problem hiding this comment.
fwiw this seems to be missing the newly added state witness limits, so there's a change missing to a part of the code base here. Should be pretty easy to follow the thread from the test that generates this. test_runtime_config_view would be it.
There was a problem hiding this comment.
Thanks for the pointer!
core/parameters/src/cost.rs
Outdated
| @@ -359,6 +359,9 @@ pub struct RuntimeFeesConfig { | |||
|
|
|||
| /// Pessimistic gas price inflation ratio. | |||
| pub pessimistic_gas_price_inflation_ratio: Rational32, | |||
|
|
|||
| /// The maximum size of the state witness after which we defer execution of any new receipts. | |||
| pub state_witness_size_soft_limit: usize, | |||
There was a problem hiding this comment.
Is there a reason this is not a part of the LimitConfig? It is a limit after all.
If its because LimitConfig itself is a part of vm::Config, then I think we might want to "just" move the LimitConfig such that it is no longer as specific to VM. On the other hand, it doesn't matter either way: we can easily change the place of the parameter in the future so long as we take care to keep the RuntimeConfigView backwards compatible.
There was a problem hiding this comment.
Alternatively you could move it to RuntimeConfig proper.
There was a problem hiding this comment.
In the future, I anticipate more stateless validation related configs like state witness hard_limit for individual contracts etc. to come in. I personally wasn't sure whether I should create a new struct like StatelessValidationConfig in RuntimeConfig or just put it in RuntimeFeesConfig.
Yes, I don't like vm::Config for this as it seems specific to VMs and state_witness_size_soft_limit is technically used outside the VM.
Not too sure what do do here, but like you suggested, let me try to move this to RuntimeConfig proper.
| } | ||
|
|
||
| pub fn recorded_storage(&mut self) -> PartialStorage { | ||
| let mut nodes: Vec<_> = self.recorded.drain().map(|(_key, value)| value).collect(); | ||
| nodes.sort(); | ||
| PartialStorage { nodes: PartialState::TrieValues(nodes) } | ||
| } | ||
|
|
||
| pub fn recorded_storage_size(&self) -> usize { | ||
| debug_assert!(self.size == self.recorded.values().map(|v| v.len()).sum::<usize>()); |
There was a problem hiding this comment.
Conversely the debug assert expression gets evaluated in "development" builds only. While it is ideal to not have those be much slower than the release builds, there's already some precedent to debug asserts being slow enough to no longer give an accurate view of the release build performance, so if it is hard to move this elsewhere, then it is probably quite alright to leave it here...
runtime/runtime/src/lib.rs
Outdated
| @@ -1458,7 +1459,11 @@ impl Runtime { | |||
| _ = prefetcher.prefetch_receipts_data(&local_receipts); | |||
| } | |||
| for receipt in local_receipts.iter() { | |||
| if total_compute_usage < compute_limit { | |||
| if total_compute_usage >= compute_limit | |||
| || state_update.trie.recorded_storage_size() >= state_witness_size_limit | |||
There was a problem hiding this comment.
You've added a protocol feature for this as well, so might as well gate the check based on whether that feature is enabled (this at the very least avoids calling into the storage size accounting code if the feature isn't enabled.)
I'm honestly not sure about the numbers right now. This PR forms a basis that we can use to later fine tune the size limit. I remembering having heard that 16 MB is a good enough size to begin with from github issues or zulip conversations. I'll follow up with @pugachAG.
Block processing time (or rather chunk processing time) should be unaffected. The main reason to have this in place here is to avoid on the network delays in transmitting the state witness.
In a world with stateless validation, it's crucial to have this limit otherwise we can have massive stalls and delays if the state witness isn't able to propagate from the chunk proposer/producer to the validators. It's better to have the chain progressing than completely stalled :) As for the issue with delayed receipts and incoming transactions, size limits for that would be handled in separate tasks. This PR is just for the touched trie nodes in state witness. The past conversation with @pugachAG was that we'll introduce a soft limit here and a hard limit per receipt/contract call and see if that's good enough to begin with. |
| } | ||
|
|
||
| pub fn record(&mut self, hash: &CryptoHash, node: Arc<[u8]>) { | ||
| self.recorded.insert(*hash, node); | ||
| match self.recorded.insert(*hash, node.clone()) { |
There was a problem hiding this comment.
nit: it is pretty weird to see clone() here when node is already owned, in my understanding it is only needed for the debug_assert_eq! below which is of very questionable value. I suggest replacing this with if self.recorded.insert(*hash, node).is_none() { ... }
There was a problem hiding this comment.
I removed the debug_assert check... Didn't have it before, not totally worth having now
runtime/runtime/src/lib.rs
Outdated
| @@ -1450,6 +1450,9 @@ impl Runtime { | |||
| // TODO(#8859): Introduce a dedicated `compute_limit` for the chunk. | |||
| // For now compute limit always matches the gas limit. | |||
| let compute_limit = apply_state.gas_limit.unwrap_or(Gas::max_value()); | |||
| let check_state_witness_size_limit = | |||
There was a problem hiding this comment.
nit: I would use single Option param here:
let state_witness_size_limit = if checked_feature!("stable", StateWitnessSizeLimit, protocol_version) Some(apply_state.config.fees.state_witness_size_soft_limit) else None
then you check the limit with is_some_and
|
regarding the exact limit: we are still working on figuring out what that value should be and it can take several weeks, so I suggest to merge this as it is with 16MB and then we can update the value later |
|
Actually I just realised that |
Discussed offline and now using |
Runtime config check related tests are not supposed to run on nightly and statelessnet. Originally broken in #10703
| pub fn record(&mut self, hash: &CryptoHash, node: Arc<[u8]>) { | ||
| self.recorded.insert(*hash, node); | ||
| let size = node.len(); | ||
| if self.recorded.insert(*hash, node).is_none() { | ||
| self.size += size; | ||
| } | ||
| } |
There was a problem hiding this comment.
Is it possible to call record() again with the same hash, but different node?
If yes, then the new node might have a different size from the previous one and self.size should be adjusted.
There was a problem hiding this comment.
After talking with Anton he said that each node hash is unique, so it can't happen. There's no problem.
For stateless validation we need to record all trie reads performed when applying a chunk in order to prepare a `PartialState` that will be included in `ChunkStateWitness` Initially it was only necessary to record trie reads when producing a chunk. Validators could read all the values from the provided `PartialState` without recording anything. A recent change (near#10703) introduced a soft limit on the size of `PartialState`. When applying a chunk we watch how much state was recorded, and once the amount of state exceeds the soft limit we stop applying the receipts in this chunk. This needs to be done on both the chunk producer and chunk validator - if the chunk validator doesn't record reads and enforce the limit, it will produce a different result of chunk application, which would lead to validation failure. This means that state should be recorded in all cases when a statelessly validated chunk is applied. Let's remove the configuration option that controls whether trie reads should be recorded (`record_storage`) and just record the reads on every chunk application (when `statelessnet_protocol` feature is enabled). Refs: [zulip conversation](https://near.zulipchat.com/#narrow/stream/407237-core.2Fstateless-validation/topic/State.20witness.20size.20limit/near/428313518)
For stateless validation we need to record all trie reads performed when applying a chunk in order to prepare a `PartialState` that will be included in `ChunkStateWitness` Initially it was only necessary to record trie reads when producing a chunk. Validators could read all the values from the provided `PartialState` without recording anything. A recent change (#10703) introduced a soft limit on the size of `PartialState`. When applying a chunk we watch how much state was recorded, and once the amount of state exceeds the soft limit we stop applying the receipts in this chunk. This needs to be done on both the chunk producer and chunk validator - if the chunk validator doesn't record reads and enforce the limit, it will produce a different result of chunk application, which would lead to validation failure. This means that state should be recorded in all cases when a statelessly validated chunk is applied. Let's remove the configuration option that controls whether trie reads should be recorded (`record_storage`) and just record the reads on every chunk application (when `statelessnet_protocol` feature is enabled). Refs: [zulip conversation](https://near.zulipchat.com/#narrow/stream/407237-core.2Fstateless-validation/topic/State.20witness.20size.20limit/near/428313518)
For stateless validation we need to record all trie reads performed when applying a chunk in order to prepare a `PartialState` that will be included in `ChunkStateWitness` Initially it was only necessary to record trie reads when producing a chunk. Validators could read all the values from the provided `PartialState` without recording anything. A recent change (near#10703) introduced a soft limit on the size of `PartialState`. When applying a chunk we watch how much state was recorded, and once the amount of state exceeds the soft limit we stop applying the receipts in this chunk. This needs to be done on both the chunk producer and chunk validator - if the chunk validator doesn't record reads and enforce the limit, it will produce a different result of chunk application, which would lead to validation failure. This means that state should be recorded in all cases when a statelessly validated chunk is applied. Let's remove the configuration option that controls whether trie reads should be recorded (`record_storage`) and just record the reads on every chunk application (when `statelessnet_protocol` feature is enabled). Refs: [zulip conversation](https://near.zulipchat.com/#narrow/stream/407237-core.2Fstateless-validation/topic/State.20witness.20size.20limit/near/428313518)
…tion (#11069) During receipt execution we record all touched nodes from the pre-state trie. Those recorded nodes form the storage proof that is sent to validators, and validators use it to execute the receipts and validate the results. In #9378 it's stated that in a worst case scenario a single receipt can generate hundreds of megabytes of storage proof. That would cause problems, as it'd cause the `ChunkStateWitness` to also be hundreds of megabytes in size, and there would be problems with sending this much data over the network. Because of that we need to limit the size of the storage proof. We plan to have two limits: * per-chunk soft limit - once a chunk has more than X MB of storage proof we stop processing new receipts, and move the remaining ones to the delayed receipt queue. This has been implemented in #10703 * per-receipt hard limit - once a receipt generates more than X MB of storage proof we fail the receipt, similarly to what happens when a receipt goes over the allowed gas limit. This one is implemented in this PR. Most of the hard-limit code is straightforward - we need to track the size of recorded storage and fail the receipt if it goes over the limit. But there is one ugly problem: #10890. Because of the way current `TrieUpdate` works we don't record all of the storage proof in real time. There are some corner cases (deleting one of two children of a branch) in which some nodes are not recorded until we do `finalize()` at the end of the chunk. This means that we can't really use `Trie::recorded_storage_size()` to limit the size, as it isn't fully accurate. If we do that, a malicious actor could prepare receipts which seem to have only 1MB of storage proof during execution, but actually record 10MB during `finalize()`. There is a long discussion in #10890 along with some possible solution ideas, please read that if you need more context. This PR implements Idea 1 from #10890. Instead of using `Trie::recorded_storage_size()` we'll use `Trie::recorded_storage_size_upper_bound()`, which estimates the upper bound of recorded storage size by assuming that every trie removal records additional 2000 bytes: ```rust /// Size of the recorded state proof plus some additional size added to cover removals. /// An upper-bound estimation of the true recorded size after finalization. /// See #10890 and #11000 for details. pub fn recorded_storage_size_upper_bound(&self) -> usize { // Charge 2000 bytes for every removal let removals_size = self.removal_counter.saturating_mul(2000); self.recorded_storage_size().saturating_add(removals_size) } ``` As long as the upper bound is below the limit we can be sure that the real recorded size is also below the limit. It's a rough estimation, which often exaggerates the actual recorded size (even by 20+ times), but it could be a good-enough/MVP solution for now. Doing it in a better way would require a lot of refactoring in the Trie code. We're now [moving fast](https://near.zulipchat.com/#narrow/stream/407237-core.2Fstateless-validation/topic/Faster.20decision.20making), so I decided to go with this solution for now. The upper bound calculation has been added in a previous PR along with the metrics to see if using such a rough estimation is viable: #11000 I set up a mainnet node with shadow validation to gather some data about the size distribution with mainnet traffic: [Metrics link](https://nearinc.grafana.net/d/edbl9ztm5h1q8b/stateless-validation?orgId=1&var-chain_id=mainnet&var-shard_id=All&var-node_id=ci-b20a9aef-mainnet-rpc-europe-west4-01-84346caf&from=1713225600000&to=1713272400000) 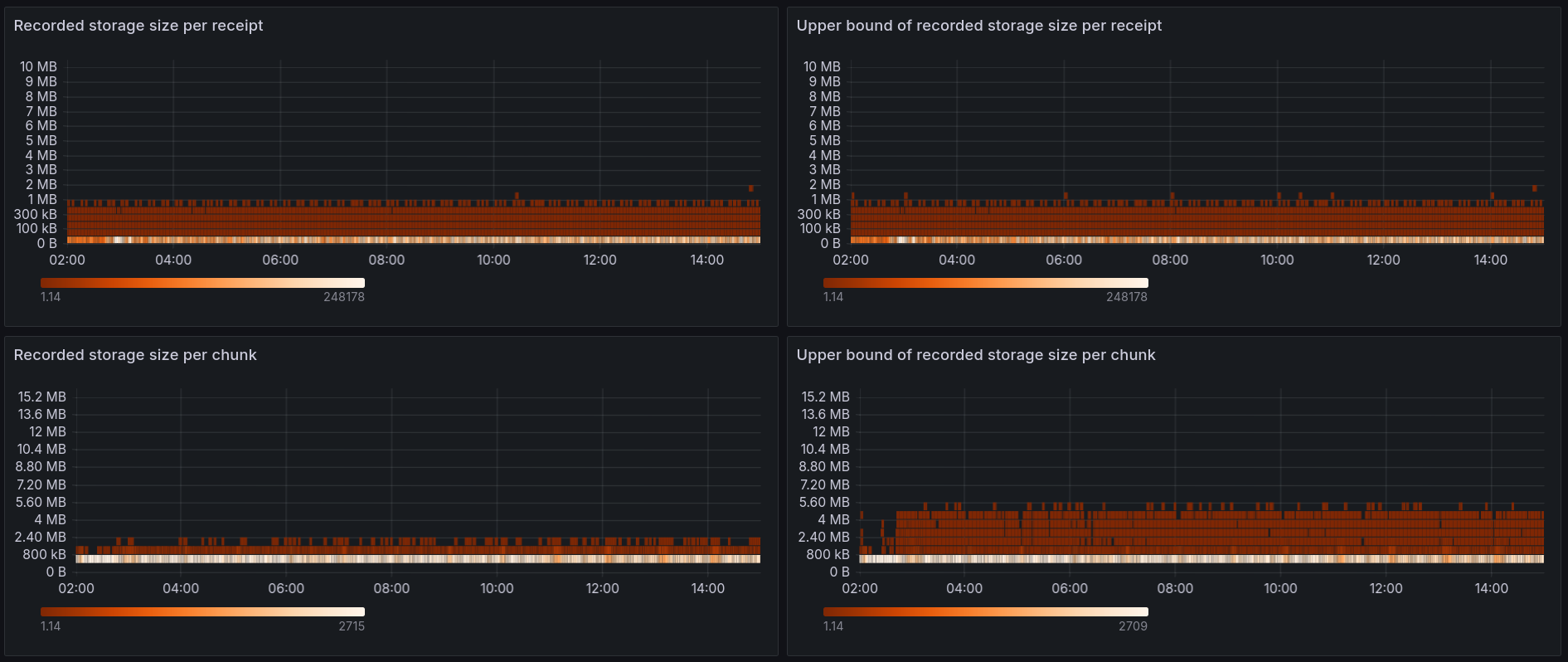  The metrics show that: * For all receipts both the recorded size and the upper bound estimate are below 2MB * Overwhelming majority of receipts generate < 50KB of storage proof * For all chunks the upper bound estimate is below 6MB * For 99% of chunks the upper bound estimate is below 3MB Based on this I believe that we can: * Set the hard per-receipt limit to 4MB. All receipts were below 2MB, but it's good to have a bit of a safety margin here. This is a hard limit, so it might break existing contracts if they turn out to generate more storage proof than the limit. * Set the soft per-chunk limit to 3MB. 99% of chunks will not be affected by this limit. For the 1% that hit the limit they'll execute fewer receipts, with the rest of the receipts put into the delayed receipt queue. This slightly lowers throughput of a single chunk, but it's not a big slowdown, by ~1%. Having a 4MB per-receipt hard limit and a 3MB per-chunk soft limit would give us a hard guarantee that for all chunks the total storage proof size is below 7MB. It's worth noting that gas usage already limits the storage proof size quite effectively. For 98% of chunks the storage proof size is already below 2MB, so the limit isn't really needed for typical mainnet traffic. The limit matters mostly for stopping malicious actors that'd try to DoS the network by generating large storage proofs. Fixes: #11019
This PR adds a new runtime config
state_witness_size_soft_limitwith size about 16 MB to begin with along with an implementation to enforce it in runtime.This is the first step of #10259
What is state witness size soft limit?
In order to limit the size of the state witness, as a first step, we are adding a limit to the max size of the state witness partial trie or proof. In runtime, we record all the trie nodes touched by the chunk execution and include these in the state witness. With the limit in place, if the size of the state witness exceeds 16 MB, then we would stop applying receipts further and push all receipts into the delayed queue.
The reason we call this a soft limit is that we stop the execution of the receipts AFTER the size of the state witness has exceeded 16 MB.
We are including this as part of a new protocol version 83
Future steps