Added preemption to recovery server #1644
Conversation
Signed-off-by: Aitor Miguel Blanco <aitormibl@gmail.com>
Codecov Report
@@ Coverage Diff @@
## master #1644 +/- ##
==========================================
- Coverage 38.85% 38.58% -0.27%
==========================================
Files 229 229
Lines 11986 12002 +16
Branches 5245 5251 +6
==========================================
- Hits 4657 4631 -26
- Misses 3815 3865 +50
+ Partials 3514 3506 -8
Continue to review full report at Codecov.
|

There was a problem hiding this comment.
Great, I love small changes that do big things!
I think we can simplify this more by instead of sending a null goal (just the current pose) so that it immediately returns success, we should instead send all BTActionNodes the proper preemption signal and the servers should handle it. For the case of recoveries, that is just completing the server and returning.
| { | ||
| } | ||
|
|
||
| void on_tick() override |
There was a problem hiding this comment.
Since these are static parameters in the xml, do we need to run these in on_tick?
There was a problem hiding this comment.
We would need them there if we want to send a new goal as preemption behaviour (the null goal I made), to reset the goal whenever we enter the node.
However, if I change this to simply cancel the recovery, it can stay in the constructor.
| @@ -173,12 +173,14 @@ class Recovery : public nav2_core::Recovery | |||
| // TODO(orduno) #868 Enable preempting a Recovery on-the-fly without stopping | |||
| // Check if the navigation goal has been updated | ||
| if (config().blackboard->get<bool>("goal_preempted")) { | ||
| config().blackboard->set("goal_preempted", false); | ||
| on_goal_preempted(); |
There was a problem hiding this comment.
In general, can't recovery behaviors, while being preempted, be thought of as being cancelled? Since the preemption of the navigation request should effectively stop all recoveries, the difference between a cancellation and a preemption isn't really anything.
If that's true, then I think we can directly cancel or preempt the goal at this point. What you did instead looks like sending a new null goal that will immediately success in its current pose. I think using the goal_handle_ to preempt it is the right answer in this case (also, the action node is used for all servers including planning and recovery so this might call other non-recovery action servers). Then we can remove the on_goal_preempted methods from each implementation. Their respective recovery server implementations just need to handle the cancellation cleanly.
There was a problem hiding this comment.
My idea with this was to allow all action nodes to do something on preemption.
I think it also makes sense since the BtNavigator does not know which node is being executed at the moment, and if the preemption flag is not cleared after the preemption is processed, the recovery behaviours would be cancelled when executed after a preemption is done, no matter on which node.
I thought of this as a simple solution where whatever node is being executed, it is notified of the preemption and clears the preemption flag. Then the on_goal_preempted call can be overriten on each specific action node to trigger a different behavior if necessary.
What do you think?
There was a problem hiding this comment.
allow all action nodes to do something on preemption
I think that sounds OK as long as there's actually a node that needs it. But I don't think that should be misconstrued with actually doing the preemption. If we're being asked to preempt or cancel, we should preempt or cancel, but then a separate method to also do something before or after sounds OK.
You could also just have the BT Action Node just preempt or cancel the servers running. You effectively do that by just setting a null goal that returns immediately, but really it should be dealt with in the server instance itself. That code also impacts the controller and planner and isn't rational for those cases.
The BT Action node is the interface for the BT to the action servers, if the navigation request was preempted or cancelled, the respective implementations should handle and communicate that to their servers. For the recoveries, that means push along the preempt / cancellation request for it to handle (which they should then just immediately return). For the controller, probably nothing needs to change on preemption (cancel should stop). For the planner cancel should stop, but unclear if the preemption should stop as well, I'm leaning towards "yes" but that's a topic for another PR.
There was a problem hiding this comment.
But I don't think that should be misconstrued with actually doing the preemption
Maybe we can then change the call from on_goal_preempted to on_navigation_goal_preempted or something like that? I understand that it is quite confusing to talk about preemption of the server instances (local to each server's behaviour) and the navigation goal (a global goal).
That code also impacts the controller and planner and isn't rational for those cases.
I believe that by using a similar structure as we do with on_tick or on_wait_for_result, we should not affect any node that does not define a specific behaviour for on_goal_preempted, except from the extra management of the preemption flag. This shouldn't add too much overhead, but could it be an issue?
if the navigation request was preempted or cancelled, the respective implementations should handle and communicate that to their servers.
The existing implementation handles the cancel on the halt function of the BT Action Node, effectively sending a cancel request to their respective servers. The problem with the halt is that it recursively stops the activity of all nodes in the tree. The reason to not do a similar thing on a preemption is that as you mention, the preemption shouldn't affect all nodes equally.
The intention of adding a new function when a navigation preemption is recieved is to allow the nodes to do something about it. This is at the moment only interesting for the recoveries, but it opens new chances for other action nodes to change their behaviour when the global goal changes.
For the recoveries, that means push along the preempt / cancellation request for it to handle (which they should then just immediately return)
If I understand you correctly, you would like to have the action servers handle the global goal preemption on their own. To do so, we would need to add a new callback on the action server to handle the preemptions. I could do that by subclassing the action server to a recovery server maybe, but I believe it won't make much sense to add that callback on the Simple Action Server.
There was a problem hiding this comment.
I think all these functions make things more confusing. This should be relatively simple. You have a behavior tree spinning and when you call a cancel or preempt at least 1 BT node is active (probably multiple, the controller which is always running basically and potentially then a recovery or planner or something). My understanding of this at the moment is that if you hit cancel, all of the BT action Node derived classes (spin, wait, backup, planner, controller) will stop (via a async_cancel_goal in halt).
So when the parent navigation attempt requests a preemption, what its asking for is to stop what you're doing and start proceeding to the next goal smoothly. That means the controller should keep going for the short period of time until the new plan is handed to it. that means the planner, if its doing something, should immediately stop and be given a new goal to compute (that could be done via a preemption, also done for you, no changes required here) and the recoveries should never be immediately recalled until at that point a planner or controller failure has occurred. That is the only behavior change required.
Therefore, I think the on_preemption() for the recoveries BT nodes should do an async cancel and the planner should be given a new goal with the new goal flag. So I think the function you've made, if you would like to keep that to implement preemption for servers, should have an implementation of cancels for the recoveries, preempt with the updated goal for the planners, and nothing (?) for the controllers. In that way, you should probably make a BT-specific recoveries node that derives from the BTActionNode that the recovery actions implement, so that there's not code duplication with 3+ identical on_preemption()s.
You shouldn't touch halt that is correct. You also shouldn't need to change anything in the simple action server. You just need to check for preemption as well as cancel and then stop processing (which seems to be laid out for you as well here)
The major issue with what you proposed is that its a little hacky and could fail if some message gets delayed (since the new rotation angle is 0 when sent but then maybe moved 10 degrees with a tolerance of 4 degrees, so it'll start spinning back or something silly). Its also not really a general solution to just terminating all recoveries when a new navigation request comes in, which I think is expected behavior.
There was a problem hiding this comment.
Or perhaps if there’s some “one-shot” solution in BT.CPP we could add in a new virtual method like halt for our needs. I don’t recall from our discussions if that would actually just solve everything. I think Davide would be open to it if its named well & has some other use for other people.
I think we’ve gotten really in the weeds here- I think the key is figuring out what we want each of the nodes to do (action ones and others). The control flow and non-action make this tricky. Maybe there’s a way to simplify that. I forget now what the current behavior even is for preemption and what’s specifically wrong with it 😅
There was a problem hiding this comment.
Is it correct to say that the only thing right now that’s not acting properly on preemption is the recoveries? Or also planner? Mhm... ok so all action nodes... and even the throttle decorator since it should let it replan immediately...
This preemption thing is a pain.
What would happen if we sent a new command to a BT that was currently running without halting between? Would that have a similar behavior we’re looking for?
There was a problem hiding this comment.
This issue kind of addresses our problem: BehaviorTree/BehaviorTree.CPP#106
There it's mentioned that the CoroActionNode is useful for preemptions, however, I do not see any methods in other nodes able to act differently with this kind of node, meaning that for us it's the same.
We mainly want to be able to stop all recoveries when a new goal is sent. For the other nodes, I believe it is okay the way it is (planner and controller work as expected atm if the proper behaviour tree is built). This means that we have a tree of the shape:
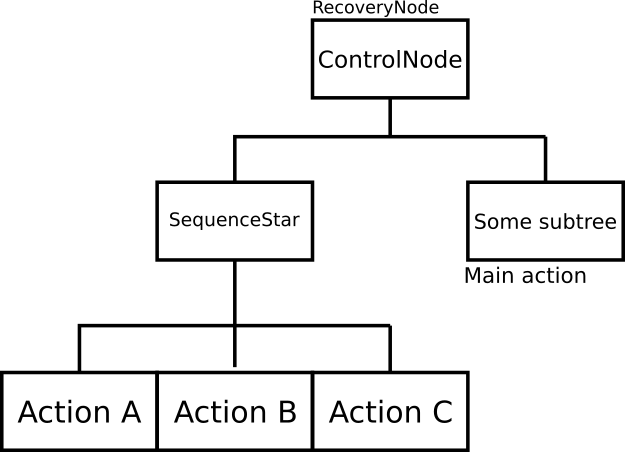
We have a root node (RecoveryNode) that switches between two behaviours: SequenceStar and a main action.
We want to be able to cancel actions a, b and c no matter which of them is running and make the parent node return success, so the main action can start running.
To recap on what we talked so far:
- We thought of using an ActionNode-specific method that we can call on preemption of the global goal, but there is a problem with the tree: Even if we stop the running action node, it's parent node is not stopped, it just jumps to the next action.
- We thought of resetting the whole tree by somehow halting it without stopping the controller, but that implementation would fail if more than one controller is in use.
- We discussed modifying the recovery control node to halt its second child on preemption. I.e., halt the recovery behaviour branch.
- We also thought of using the blackboard to trigger the necessary actions, but that is discarded since there is no way of knowing how many nodes are running at the same time.
- We cannot force a success with a decorator to the SequenceStar output since we want to be able to percive an error on the recovery actions (this could be useful if possible, as we could simply return failure from action nodes a, b or c and that would stop the recovery).
Maybe @facontidavide knows how we can fix this on a way that makes sense.
There was a problem hiding this comment.
If we had a halt counterpart in the tree node, couldn't we override it for control flow nodes and mess with the internal state to return success / failure? We could set a flag and next time it's ticked, we just return some value set by the flag. Its not ideal, but it could work (?) though it doesn't set the state immediately, its only after its reticked in the new preempted goal request.
Please look over my comment on that ticket and make sure it makes sense to you / is correct
There was a problem hiding this comment.
I'm not sure I understand how that would work, but would we need to override the control nodes that we want to use then?
Please look over my comment on that ticket and make sure it makes sense to you / is correct
Thanks for commenting, I agree with your description, specially what you mentioned about adding the communication child to parent (I believe that would be something useful for the behavior tree itself and not just us). Let's continue this discussion in that thread, I'm sure Davide will know what can be done.
| @@ -173,12 +173,14 @@ class Recovery : public nav2_core::Recovery | |||
| // TODO(orduno) #868 Enable preempting a Recovery on-the-fly without stopping | |||
| if (action_server_->is_preempt_requested()) { | |||
| RCLCPP_ERROR( | |||
| node_->get_logger(), "Received a preemption request for %s," | |||
| " however feature is currently not implemented. Aborting and stopping.", | |||
| node_->get_logger(), "Received a preemption request for %s,", | |||
There was a problem hiding this comment.
This can be an info now (or even a debug after you get it working)
There was a problem hiding this comment.
Sorry, I missed that one. Do you think is better an info or debug?
This reverts commit 0cec123.
Signed-off-by: Aitor Miguel Blanco <aitormibl@gmail.com>
| @@ -0,0 +1,76 @@ | |||
| #ifndef NAV2_BEHAVIOR_TREE__GOAL_UPDATED_CONDITION_HPP_ | |||
There was a problem hiding this comment.
I am missing the copyright here, because I don't really know what I am supposed to write :)
Any ideas?
There was a problem hiding this comment.
Copy paste from another file and just change to your name
(literally)
|
So, I created a node that checks when the goal changes in the blackboard, and I updated the behavior trees to check if the goal has changed and react on a tick. |
|
@gimait we may want to close this PR and open a new one. We have alot of off topic discussion on this one now and I wouldn't want to be the person a year or two from now looking over this PR to understand how to implement preemptions 😆 Can you close this and open a new one? Please also post a picture of the new BT in this PR using the BT image tool in tools (you'll also need to add your new node to the list in the script). We'll need to update some documentation as well but that should be simple (readmes, navigation website). |
There was a problem hiding this comment.
See comments - but also do in a new PR to clean up this one. Its great to button this one up! thanks for all your patience and hard work. This was a hard one and we started down the wrong track.
- Documentation: we need to update images to show the new BT using the tool. Also update any descriptions in the readmes of the specific BT XMLs we have here to include this. I think it owuld be useful to explicitly explain how we implement the ability to do preemption of the recoveries and do replanning on a new goal
- Linting errors, see CI and comment
- Update navigation website, there's a plugins tab that this new BT node should be added to and add you as the author!
- Show a gif or something of the replanning being called right after a preemption and the recoveries exiting (you could remove all over recoveries and just have the wait recovery be stupid long, like 100 seconds. Then set the replanning rate for the planner to 0.001 seconds. Send a new goal in rviz and then just show that immediately the robot starts replanning. That would prove that the recovery was instantily preempted from its 100s sleep and the planner also replanned).
| @@ -0,0 +1,76 @@ | |||
| #ifndef NAV2_BEHAVIOR_TREE__GOAL_UPDATED_CONDITION_HPP_ | |||
| #define NAV2_BEHAVIOR_TREE__GOAL_UPDATED_CONDITION_HPP_ | |||
There was a problem hiding this comment.
I think this guard is wrong, check with ament_cpplint and ament_uncrustify. I'm sure they're complaining and will give you the exact header guard to use.
There was a problem hiding this comment.
hmm I think uncrustify wasn't complaining on this one, I run it through and it only complaint about the copyright, but I'll check it again. If you say it because of the HPP, I also thought maybe it should be called NAV2_BEHAVIOR_TREE__GOAL_UPDATED_CONDITION_CPP_, but then all other plugins are using HPP instead of CPP on the guard (even when they are cpp files). Is that what you saw?
There was a problem hiding this comment.
Just see what it says when you fix the copyright and work from there. Maybe I'm mistaken.
|
|
||
| void initialize() | ||
| { | ||
| goal_ = config().blackboard->get<geometry_msgs::msg::PoseStamped>("goal"); |
There was a problem hiding this comment.
You can add this stuff to the constructor and remove the initialize function and the variable.
There was a problem hiding this comment.
I can remove the function and add the logic in the tick, but I think this initialization needs to be here (in the tick). I think the blackboard goal might not be set when the constructor is called (i.e., when we build the tree).
There was a problem hiding this comment.
And now that I see it, I'm also missing to set back to false the initialized_ variable to false if the node in halt. I just realized that the goal needs to be updated in the first tick of the condition, otherwise if the goal changed between restarts of this node, this one will succeed on the first tick!
There was a problem hiding this comment.
If you set goal to a bogus value, then the first goal that comes in will trigger the updated condition. I think that would be fine, wouldn't it? Then the comparison for is current would be that there's a new goal and therefore replan.
I think the goal_ could actually be constructed as default so that it is always out of date on startup causing the updated condition to be true on the first tick.
Does that make sense / correct?
There was a problem hiding this comment.
The thing is, how do you know if you are in the first tick? What we are checking is wether the goal has changed, meaning that return success means "goal has changed" and failure means "goal has not changed".
What I thought is:
1st tick: A flag tells that is the first tick, so we check the goal (and a return could be here straight away)
2nd and from there on: The flag is gone, so we just check the value in the blackboard, if it changes, return success, else failure.
The reason behind this is how the parent ReactiveFallback node works. That node will halt all children and return success when one of its children returns success. This means that this new condition node needs to return failure in each tick, except from when the goal changes. This also means that we need to reset the current goal any time we enter the parent control node, so we don't return success in the first tick. I think first tick should always be initialization and return failure.
What do you think? Maybe I don't understand what you mean.
There was a problem hiding this comment.
If this is the first iteration, lets game out the 2 things this does:
- you're not going to be entering a recovery state by default. So the case of recovery being killed won't happen (also even if it was killed because that was default behavior, its not like that matters).
- the planner you want to plan when you have start up, so the mismatch of the default constructor goal and the goal actually passed by the BT navigator will cause the planner to plan.
Isn't that what we want? For subsequent calls, you're updating the goal_ param with the new blackboard param, correct, so then in the future the goal_ is the same and it won't replan. Once a new goal comes in, it'll again mismatch and cause a replan.
Your 1st tick I think right now wouldn't actually cause the planner to plan at all. You set the goal_ to the initial request goal and then you check if they're the same, which they now are. That would make this return false that there is no new goal and then wouldn't navigate or plan ever until a new preempted goal was requested.
You could test this by just running this code and sending the first goal and seeing if the robot actually tries to plan on the initial goal sent.
There was a problem hiding this comment.
We should continue this in the new PR.
| <Spin spin_dist="1.57"/> | ||
| <Wait wait_duration="5"/> | ||
| </SequenceStar> | ||
| <ReactiveFallback name="RecoveryFallback"> |
There was a problem hiding this comment.
Please show images of the new BTs for any BTs you change with the tool. You'll also need to update those images in the readme files / anywhere else the BT images are displayed. Also look over the readmes for descriptions of these BTs and update them with this new logic flow.
There was a problem hiding this comment.
Okay, I'll include the documentation changes in the new pr.
| isGoalUpdated() | ||
| { | ||
| auto current_goal = config().blackboard->get<geometry_msgs::msg::PoseStamped>("goal"); | ||
| if (goal_ != current_goal) { |
There was a problem hiding this comment.
This was clever. I thought about setting a flag and required a new BT node in the root. This gets around that. Good idea.
There was a problem hiding this comment.
I couldn't think on other way to check if there if the goal was preempted in more than one place. Thanks!
|
Thank you for your comments and help @SteveMacenski, I'm very happy with this solution and I wouldn't have been able to make it here without your help. |
|
Awesome |
Signed-off-by: Aitor Miguel Blanco aitormibl@gmail.com
Basic Info
Description of contribution in a few bullet points
Description of documentation updates required from your changes
Future work that may be required in bullet points
This could be fixed with a new control node able to stop the action sequence when a preemption happens.