Internet Archive
The Internet Archive is a free online digital library. Anyone with a free account can upload materials to the Internet Archive via a drag/drop interface or an API. It supports all kinds of digital materials, so it can accept a wide range of file formats, but its metadata model is not tailored to books.
They also host the WayBack Machine, which archives snapshots of web pages. Anyone can submit URLs to be archived, whether or not they have an account. The archived webpages are transformed to WARC and can then be publicly accessed as HTML.
- Preferred metadata format: Custom form
- Other supported formats: N/A
- File transfer: browser upload or API
- Content files: PDF (and many others)
- Chapter support: No
The Internet Archive, a 501(c)(3) non-profit, is a digital library of internet sites and other cultural artifacts in digital form that provides free access. Contains 475 billion web pages, 28 million books and texts, 14 million audio recordings (including 220,000 live concerts), 6 million videos (including 2 million Television News programs), 3.5 million images, 580,000 software programs. Has newly launched an Internet Archive Scholar search engine. For books, see Archive-It.
When a dynamic page contains forms, JavaScript, or other elements that require interaction with the originating host, the archived version in the WayBack Machine will not contain the original site’s functionality.
Free (some features require a free account).
WayBack Machine crawls are contributed from various sources, some imported from third parties and others generated internally by the Archive. The frequency of snapshot captures varies per website.
The Internet Archive has datacentres in three Californian cities: San Francisco, Redwood City, and Richmond. To prevent losing the data in case of e.g. a natural disaster, the Archive attempts to create copies of (parts of) the collection at more distant locations, currently including the Bibliotheca Alexandrina in Egypt and a facility in Amsterdam.
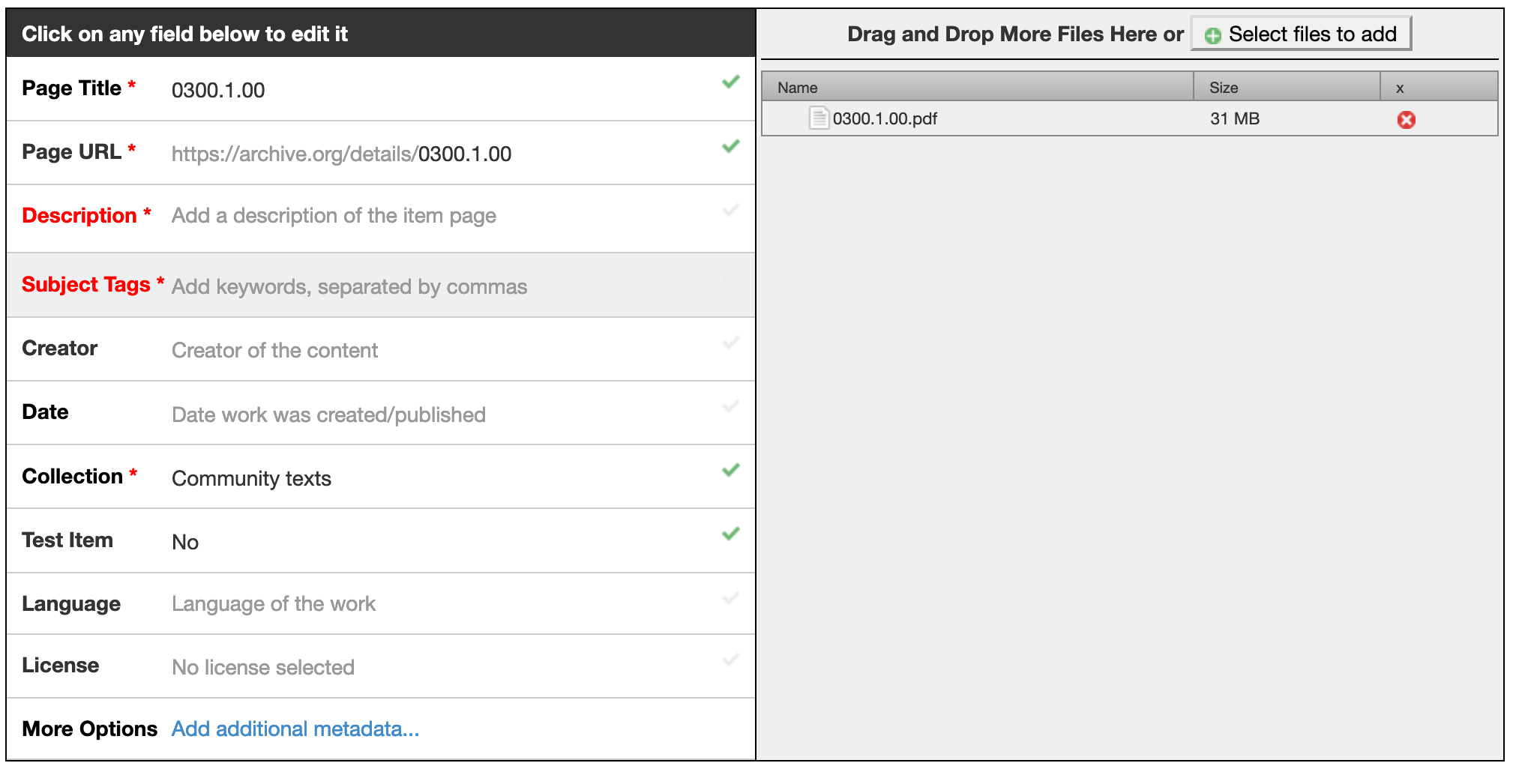
The Internet Archive has a variety of well-documented APIs for interacting with its range of services. The most relevant for our purposes are the Item Files API and the Item Metadata API. An "Item" is IA terminology for a logical grouping of content (this may be only one file, or several). A single Item has its own IA webpage and everything within it shares the same overall metadata; the Thoth concept of a Work could be mapped to the IA concept of an Item (it may have Publication files in several different formats in the same way that an Item can have multiple related files). In addition to the Item-level metadata, File-level metadata can also be supplied.
The documentation suggests that the preferred way of interacting with both of these APIs is to use the IA-provided internetarchive Python library, and/or their ia command-line tool. (The command-line tool is supplied alongside the Python library, and can be used to easily configure it, as well as allowing standalone interaction with both APIs.) In order to write data to the IA, a (free) account is required. After creating an account and installing the Python library, it was simple to upload a small file with very basic metadata to a new Item. The Item was publicly accessible and the file could be freely redownloaded from it. The Python library was later integrated into the Thoth Dissemination Service and used to create the Thoth Archiving Network collection.
Internet Archive metadata is retrieved in JSON format; as an example, the metadata for this Thoth Archiving Network Item can be viewed in the browser. The documentation states an aim to be "metadata agnostic", i.e. their data model is not constrained to fit any specific metadata standard. While there is a set of standard fields (some of which are mandatory and specific to the IA, e.g. "uploader" indicating who uploaded the Item to the Archive), the user can define any custom field and add it to their Item or File metadata. This is helpful in that it allows us to retain all of the rich metadata available in Thoth on uploading, although it is not clear how the lack of a uniform standard for these additional fields might affect discoverability. While the Archive is set up for all media types, it does contain book-related fields such as isbn, issn, oclc in its standard set.
Open Library is a project of the Internet Archive, can be accessed using an IA account, and pulls through much of its data from the IA. It is (/aims to be) an openly editable universal library catalogue. It is therefore metadata-only, however, the catalogue pages for some of the books listed allow "reading" and/or "borrowing" of the electronic book file via the link with the IA (which also allows these features). The range of metadata that can be submitted is therefore more tailored to book objects than that of the IA (although still not as rich as Thoth's).
The Open Library APIs appear to be largely read-only, therefore not of use to us in uploading metadata. There is an Open Library Python library (as well as libraries in other programming languages), which confusingly appears to be able to write data to the Open Library via API endpoints which are not listed in the main documentation. The FAQ page suggests that bulk uploading of metadata is best done by contacting them directly.
OBP were given write access to the OL API in 2018, for an account "OBPBot", but ultimately this was never used. This confirms that the API can be used for writing as well as reading, but only for users with an existing relationship with the OL.
The exact relationship between IA and OL records is not clear. Various OBP titles can be found on both platforms, but are not always linked. For example, the PDF of Rudy's "Image, Knife and Gluepot" was self-uploaded to IA by OBP (https://archive.org/details/9781783745180), but the OL page for it does not have the text available (https://openlibrary.org/works/OL20927428W). The OL page appears to have been created by a bot importing publicly-available MARC records. Some titles where the ebook is available at OL appear to have been coincidentally uploaded from a scan of a print edition by a third party (e.g. https://archive.org/details/timetraveldialog0000carr, https://openlibrary.org/works/OL20930536W). When adding/editing an OL page, there appears to be no option to add an IA identifier to link to existing IA Items.
These are two additional projects of the Internet Archive, which appear to be based around a separate API. Fatcat is an openly editable scholarly article catalogue, and Internet Archive Scholar is a fulltext search index of scholarly articles. IA Scholar pulls through files from partner collections (e.g. WayBack Machine) and metadata from Fatcat. The Fatcat API is read-write (writing is restricted to registered accounts - this can be via an IA account) and based on HTTP requests with JSON bodies. The documentation does not mention any existing/official client libraries (although some appear to have been created by third parties). These projects may become of interest if they later broaden to include monographs.