Merge from apache/spark #1
Merged
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…DataFrame.toPandas ## What changes were proposed in this pull request? Integrate Apache Arrow with Spark to increase performance of `DataFrame.toPandas`. This has been done by using Arrow to convert data partitions on the executor JVM to Arrow payload byte arrays where they are then served to the Python process. The Python DataFrame can then collect the Arrow payloads where they are combined and converted to a Pandas DataFrame. All non-complex data types are currently supported, otherwise an `UnsupportedOperation` exception is thrown. Additions to Spark include a Scala package private method `Dataset.toArrowPayloadBytes` that will convert data partitions in the executor JVM to `ArrowPayload`s as byte arrays so they can be easily served. A package private class/object `ArrowConverters` that provide data type mappings and conversion routines. In Python, a public method `DataFrame.collectAsArrow` is added to collect Arrow payloads and an optional flag in `toPandas(useArrow=False)` to enable using Arrow (uses the old conversion by default). ## How was this patch tested? Added a new test suite `ArrowConvertersSuite` that will run tests on conversion of Datasets to Arrow payloads for supported types. The suite will generate a Dataset and matching Arrow JSON data, then the dataset is converted to an Arrow payload and finally validated against the JSON data. This will ensure that the schema and data has been converted correctly. Added PySpark tests to verify the `toPandas` method is producing equal DataFrames with and without pyarrow. A roundtrip test to ensure the pandas DataFrame produced by pyspark is equal to a one made directly with pandas. Author: Bryan Cutler <cutlerb@gmail.com> Author: Li Jin <ice.xelloss@gmail.com> Author: Li Jin <li.jin@twosigma.com> Author: Wes McKinney <wes.mckinney@twosigma.com> Closes #15821 from BryanCutler/wip-toPandas_with_arrow-SPARK-13534.
## What changes were proposed in this pull request? Turn tracking of TaskMetrics._updatedBlockStatuses off by default. As far as I can see its not used by anything and it uses a lot of memory when caching and processing a lot of blocks. In my case it was taking 5GB of a 10GB heap and I even went up to 50GB heap and the job still ran out of memory. With this change in place the same job easily runs in less then 10GB of heap. We leave the api there as well as a config to turn it back on just in case anyone is using it. TaskMetrics is exposed via SparkListenerTaskEnd so if users are relying on it they can turn it back on. ## How was this patch tested? Ran unit tests that were modified and manually tested on a couple of jobs (with and without caching). Clicked through the UI and didn't see anything missing. Ran my very large hive query job with 200,000 small tasks, 1000 executors, cached 6+TB of data this runs fine now whereas without this change it would go into full gcs and eventually die. Author: Thomas Graves <tgraves@thirteenroutine.corp.gq1.yahoo.com> Author: Tom Graves <tgraves@yahoo-inc.com> Closes #18162 from tgravescs/SPARK-20923.
## What changes were proposed in this pull request? Currently the validation of sampling fraction in dataset is incomplete. As an improvement, validate sampling fraction in logical operator level: 1) if with replacement: fraction should be nonnegative 2) else: fraction should be on interval [0, 1] Also add test cases for the validation. ## How was this patch tested? integration tests gatorsmile cloud-fan Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Wang Gengliang <ltnwgl@gmail.com> Closes #18387 from gengliangwang/sample_ratio_validate.
…d StateStoreProviders when query is restarted ## What changes were proposed in this pull request? StateStoreProvider instances are loaded on-demand in a executor when a query is started. When a query is restarted, the loaded provider instance will get reused. Now, there is a non-trivial chance, that the task of the previous query run is still running, while the tasks of the restarted run has started. So for a stateful partition, there may be two concurrent tasks related to the same stateful partition, and there for using the same provider instance. This can lead to inconsistent results and possibly random failures, as state store implementations are not designed to be thread-safe. To fix this, I have introduced a `StateStoreProviderId`, that unique identifies a provider loaded in an executor. It has the query run id in it, thus making sure that restarted queries will force the executor to load a new provider instance, thus avoiding two concurrent tasks (from two different runs) from reusing the same provider instance. Additional minor bug fixes - All state stores related to query run is marked as deactivated in the `StateStoreCoordinator` so that the executors can unload them and clear resources. - Moved the code that determined the checkpoint directory of a state store from implementation-specific code (`HDFSBackedStateStoreProvider`) to non-specific code (StateStoreId), so that implementation do not accidentally get it wrong. - Also added store name to the path, to support multiple stores per sql operator partition. *Note:* This change does not address the scenario where two tasks of the same run (e.g. speculative tasks) are concurrently running in the same executor. The chance of this very small, because ideally speculative tasks should never run in the same executor. ## How was this patch tested? Existing unit tests + new unit test. Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #18355 from tdas/SPARK-21145.
…uite ## What changes were proposed in this pull request? Current ColumnarBatchSuite has very simple test cases for `Array` and `Struct`. This pr wants to add some test suites for complicated cases in ColumnVector. Author: jinxing <jinxing6042@126.com> Closes #18327 from jinxing64/SPARK-21047.
…or,the cores left will not be allocated, so it should not to check in every schedule ## What changes were proposed in this pull request? If we start an app with the param --total-executor-cores=4 and spark.executor.cores=3, the cores left is always 1, so it will try to allocate executors in the function org.apache.spark.deploy.master.startExecutorsOnWorkers in every schedule. Another question is, is it will be better to allocate another executor with 1 core for the cores left. ## How was this patch tested? unit test Author: 10129659 <chen.yanshan@zte.com.cn> Closes #18322 from eatoncys/leftcores.
## What changes were proposed in this pull request?
It looks we missed specifying the Pandas version. This PR proposes to fix it. For the current state, it should be Pandas 0.13.0 given my test. This PR propose to fix it as 0.13.0.
Running the codes below:
```python
from pyspark.sql.types import *
schema = StructType().add("a", IntegerType()).add("b", StringType())\
.add("c", BooleanType()).add("d", FloatType())
data = [
(1, "foo", True, 3.0,), (2, "foo", True, 5.0),
(3, "bar", False, -1.0), (4, "bar", False, 6.0),
]
spark.createDataFrame(data, schema).toPandas().dtypes
```
prints ...
**With Pandas 0.13.0** - released, 2014-01
```
a int32
b object
c bool
d float32
dtype: object
```
**With Pandas 0.12.0** - - released, 2013-06
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../spark/python/pyspark/sql/dataframe.py", line 1734, in toPandas
pdf[f] = pdf[f].astype(t, copy=False)
TypeError: astype() got an unexpected keyword argument 'copy'
```
without `copy`
```
a int32
b object
c bool
d float32
dtype: object
```
**With Pandas 0.11.0** - released, 2013-03
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../spark/python/pyspark/sql/dataframe.py", line 1734, in toPandas
pdf[f] = pdf[f].astype(t, copy=False)
TypeError: astype() got an unexpected keyword argument 'copy'
```
without `copy`
```
a int32
b object
c bool
d float32
dtype: object
```
**With Pandas 0.10.0** - released, 2012-12
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../spark/python/pyspark/sql/dataframe.py", line 1734, in toPandas
pdf[f] = pdf[f].astype(t, copy=False)
TypeError: astype() got an unexpected keyword argument 'copy'
```
without `copy`
```
a int64 # <- this should be 'int32'
b object
c bool
d float64 # <- this should be 'float32'
```
## How was this patch tested?
Manually tested with Pandas from 0.10.0 to 0.13.0.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes #18403 from HyukjinKwon/SPARK-21193.
…chema have the duplicate columns
## What changes were proposed in this pull request?
The current master outputs unexpected results when the data schema and partition schema have the duplicate columns:
```
withTempPath { dir =>
val basePath = dir.getCanonicalPath
spark.range(0, 3).toDF("foo").write.parquet(new Path(basePath, "foo=1").toString)
spark.range(0, 3).toDF("foo").write.parquet(new Path(basePath, "foo=a").toString)
spark.read.parquet(basePath).show()
}
+---+
|foo|
+---+
| 1|
| 1|
| a|
| a|
| 1|
| a|
+---+
```
This patch added code to print a warning when the duplication found.
## How was this patch tested?
Manually checked.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes #18375 from maropu/SPARK-21144-3.
## What changes were proposed in this pull request?
Extend `setJobDescription` to SparkR API.
## How was this patch tested?
It looks difficult to add a test. Manually tested as below:
```r
df <- createDataFrame(iris)
count(df)
setJobDescription("This is an example job.")
count(df)
```
prints ...

Author: hyukjinkwon <gurwls223@gmail.com>
Closes #18382 from HyukjinKwon/SPARK-21149.
{kind=link}
… conf in LogicalPlan ## What changes were proposed in this pull request? After wiring `SQLConf` in logical plan ([PR 18299](#18299)), we can remove the need of passing `conf` into `def stats` and `def computeStats`. ## How was this patch tested? Covered by existing tests, plus some modified existing tests. Author: wangzhenhua <wangzhenhua@huawei.com> Author: Zhenhua Wang <wzh_zju@163.com> Closes #18391 from wzhfy/removeConf.
## What changes were proposed in this pull request? We are explicitly calling release on the byteBuf's used to encode the string to Base64 to suppress the memory leak error message reported by netty. This is to make it less confusing for the user. ### Changes proposed in this fix By explicitly invoking release on the byteBuf's we are decrement the internal reference counts for the wrappedByteBuf's. Now, when the GC kicks in, these would be reclaimed as before, just that netty wouldn't report any memory leak error messages as the internal ref. counts are now 0. ## How was this patch tested? Ran a few spark-applications and examined the logs. The error message no longer appears. Original PR was opened against branch-2.1 => #18392 Author: Dhruve Ashar <dhruveashar@gmail.com> Closes #18407 from dhruve/master.
…cross StreamingQuery restarts ## What changes were proposed in this pull request? If the SQL conf for StateStore provider class is changed between restarts (i.e. query started with providerClass1 and attempted to restart using providerClass2), then the query will fail in a unpredictable way as files saved by one provider class cannot be used by the newer one. Ideally, the provider class used to start the query should be used to restart the query, and the configuration in the session where it is being restarted should be ignored. This PR saves the provider class config to OffsetSeqLog, in the same way # shuffle partitions is saved and recovered. ## How was this patch tested? new unit tests Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #18402 from tdas/SPARK-21192.
## What changes were proposed in this pull request? * Following the first few examples in this file, the remaining methods should also be methods of `df.na` not `df`. * Filled in some missing parentheses ## How was this patch tested? N/A Author: Ong Ming Yang <me@ongmingyang.com> Closes #18398 from ongmingyang/master.
… Analyzer ## What changes were proposed in this pull request? Currently we do a lot of validations for subquery in the Analyzer. We should move them to CheckAnalysis which is the framework to catch and report Analysis errors. This was mentioned as a review comment in SPARK-18874. ## How was this patch tested? Exists tests + A few tests added to SQLQueryTestSuite. Author: Dilip Biswal <dbiswal@us.ibm.com> Closes #17713 from dilipbiswal/subquery_checkanalysis.
…rom Alias and AttributeReference ## What changes were proposed in this pull request? `isTableSample` and `isGenerated ` were introduced for SQL Generation respectively by #11148 and #11050 Since SQL Generation is removed, we do not need to keep `isTableSample`. ## How was this patch tested? The existing test cases Author: Xiao Li <gatorsmile@gmail.com> Closes #18379 from gatorsmile/CleanSample.
… string in DataStreamReader
## What changes were proposed in this pull request?
This pr supported a DDL-formatted string in `DataStreamReader.schema`.
This fix could make users easily define a schema without importing the type classes.
For example,
```scala
scala> spark.readStream.schema("col0 INT, col1 DOUBLE").load("/tmp/abc").printSchema()
root
|-- col0: integer (nullable = true)
|-- col1: double (nullable = true)
```
## How was this patch tested?
Added tests in `DataStreamReaderWriterSuite`.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes #18373 from HyukjinKwon/SPARK-20431.
… in read path ## What changes were proposed in this pull request? This PR is to revert some code changes in the read path of #14377. The original fix is #17830 When merging this PR, please give the credit to gaborfeher ## How was this patch tested? Added a test case to OracleIntegrationSuite.scala Author: Gabor Feher <gabor.feher@lynxanalytics.com> Author: gatorsmile <gatorsmile@gmail.com> Closes #18408 from gatorsmile/OracleType.
…uster mode. Monitoring for standalone cluster mode is not implemented (see SPARK-11033), but the same scheduler implementation is used, and if it tries to connect to the launcher it will fail. So fix the scheduler so it only tries that in client mode; cluster mode applications will be correctly launched and will work, but monitoring through the launcher handle will not be available. Tested by running a cluster mode app with "SparkLauncher.startApplication". Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #18397 from vanzin/SPARK-21159.
…n leaving incomplete comment in PRs
## What changes were proposed in this pull request?
Recently, Jenkins tests were unstable due to unknown reasons as below:
```
/home/jenkins/workspace/SparkPullRequestBuilder/dev/lint-r ; process was terminated by signal 9
test_result_code, test_result_note = run_tests(tests_timeout)
File "./dev/run-tests-jenkins.py", line 140, in run_tests
test_result_note = ' * This patch **fails %s**.' % failure_note_by_errcode[test_result_code]
KeyError: -9
```
```
Traceback (most recent call last):
File "./dev/run-tests-jenkins.py", line 226, in <module>
main()
File "./dev/run-tests-jenkins.py", line 213, in main
test_result_code, test_result_note = run_tests(tests_timeout)
File "./dev/run-tests-jenkins.py", line 140, in run_tests
test_result_note = ' * This patch **fails %s**.' % failure_note_by_errcode[test_result_code]
KeyError: -10
```
This exception looks causing failing to update the comments in the PR. For example:


these comment just remain.
This always requires, for both reviewers and the author, a overhead to click and check the logs, which I believe are not really useful.
This PR proposes to leave the code in the PR comment messages and let update the comments.
## How was this patch tested?
Jenkins tests below, I manually gave the error code to test this.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes #18399 from HyukjinKwon/jenkins-print-errors.
{kind=link}
{kind=link}
### What changes were proposed in this pull request?
```SQL
CREATE TABLE `tab1`
(`custom_fields` ARRAY<STRUCT<`id`: BIGINT, `value`: STRING>>)
USING parquet
INSERT INTO `tab1`
SELECT ARRAY(named_struct('id', 1, 'value', 'a'), named_struct('id', 2, 'value', 'b'))
SELECT custom_fields.id, custom_fields.value FROM tab1
```
The above query always return the last struct of the array, because the rule `SimplifyCasts` incorrectly rewrites the query. The underlying cause is we always use the same `GenericInternalRow` object when doing the cast.
### How was this patch tested?
Author: gatorsmile <gatorsmile@gmail.com>
Closes #18412 from gatorsmile/castStruct.
… of individual partitions ## What changes were proposed in this pull request? Storage URI of a partitioned table may or may not point to a directory under which individual partitions are stored. In fact, individual partitions may be located in totally unrelated directories. Before this change, ANALYZE TABLE table COMPUTE STATISTICS command calculated total size of a table by adding up sizes of files found under table's storage URI. This calculation could produce 0 if partitions are stored elsewhere. This change uses storage URIs of individual partitions to calculate the sizes of all partitions of a table and adds these up to produce the total size of a table. CC: wzhfy ## How was this patch tested? Added unit test. Ran ANALYZE TABLE xxx COMPUTE STATISTICS on a partitioned Hive table and verified that sizeInBytes is calculated correctly. Before this change, the size would be zero. Author: Masha Basmanova <mbasmanova@fb.com> Closes #18309 from mbasmanova/mbasmanova-analyze-part-table.
## What changes were proposed in this pull request? Builds failed due to the recent [merge](b449a1d). This is because [PR#18309](#18309) needed update after [this patch](b803b66) was merged. ## How was this patch tested? N/A Author: Zhenhua Wang <wzh_zju@163.com> Closes #18415 from wzhfy/hotfixStats.
…daemon to prevent a leak ## What changes were proposed in this pull request? `mcfork` in R looks opening a pipe ahead but the existing logic does not properly close it when it is executed hot. This leads to the failure of more forking due to the limit for number of files open. This hot execution looks particularly for `gapply`/`gapplyCollect`. For unknown reason, this happens more easily in CentOS and could be reproduced in Mac too. All the details are described in https://issues.apache.org/jira/browse/SPARK-21093 This PR proposes simply to terminate R's worker processes in the parent of R's daemon to prevent a leak. ## How was this patch tested? I ran the codes below on both CentOS and Mac with that configuration disabled/enabled. ```r df <- createDataFrame(list(list(1L, 1, "1", 0.1)), c("a", "b", "c", "d")) collect(gapply(df, "a", function(key, x) { x }, schema(df))) collect(gapply(df, "a", function(key, x) { x }, schema(df))) ... # 30 times ``` Also, now it passes R tests on CentOS as below: ``` SparkSQL functions: Spark package found in SPARK_HOME: .../spark .............................................................................................................................................................. .............................................................................................................................................................. .............................................................................................................................................................. .............................................................................................................................................................. .............................................................................................................................................................. .................................................................................................................................... ``` Author: hyukjinkwon <gurwls223@gmail.com> Closes #18320 from HyukjinKwon/SPARK-21093.
## What changes were proposed in this pull request?
Time windowing in Spark currently performs an Expand + Filter, because there is no way to guarantee the amount of windows a timestamp will fall in, in the general case. However, for tumbling windows, a record is guaranteed to fall into a single bucket. In this case, doubling the number of records with Expand is wasteful, and can be improved by using a simple Projection instead.
Benchmarks show that we get an order of magnitude performance improvement after this patch.
## How was this patch tested?
Existing unit tests. Benchmarked using the following code:
```scala
import org.apache.spark.sql.functions._
spark.time {
spark.range(numRecords)
.select(from_unixtime((current_timestamp().cast("long") * 1000 + 'id / 1000) / 1000) as 'time)
.select(window('time, "10 seconds"))
.count()
}
```
Setup:
- 1 c3.2xlarge worker (8 cores)

1 B rows ran in 287 seconds after this optimization. I didn't wait for it to finish without the optimization. Shows about 5x improvement for large number of records.
Author: Burak Yavuz <brkyvz@gmail.com>
Closes #18364 from brkyvz/opt-tumble.
{kind=link}
…andle external shuffle service unavailable situation ## What changes were proposed in this pull request? Currently we are running into an issue with Yarn work preserving enabled + external shuffle service. In the work preserving enabled scenario, the failure of NM will not lead to the exit of executors, so executors can still accept and run the tasks. The problem here is when NM is failed, external shuffle service is actually inaccessible, so reduce tasks will always complain about the “Fetch failure”, and the failure of reduce stage will make the parent stage (map stage) rerun. The tricky thing here is Spark scheduler is not aware of the unavailability of external shuffle service, and will reschedule the map tasks on the executor where NM is failed, and again reduce stage will be failed with “Fetch failure”, and after 4 retries, the job is failed. This could also apply to other cluster manager with external shuffle service. So here the main problem is that we should avoid assigning tasks to those bad executors (where shuffle service is unavailable). Current Spark's blacklist mechanism could blacklist executors/nodes by failure tasks, but it doesn't handle this specific fetch failure scenario. So here propose to improve the current application blacklist mechanism to handle fetch failure issue (especially with external shuffle service unavailable issue), to blacklist the executors/nodes where shuffle fetch is unavailable. ## How was this patch tested? Unit test and small cluster verification. Author: jerryshao <sshao@hortonworks.com> Closes #17113 from jerryshao/SPARK-13669.
…utionId ## What changes were proposed in this pull request? in #18064, to work around the nested sql execution id issue, we introduced several internal methods in `Dataset`, like `collectInternal`, `countInternal`, `showInternal`, etc., to avoid nested execution id. However, this approach has poor expansibility. When we hit other nested execution id cases, we may need to add more internal methods in `Dataset`. Our goal is to ignore the nested execution id in some cases, and we can have a better approach to achieve this goal, by introducing `SQLExecution.ignoreNestedExecutionId`. Whenever we find a place which needs to ignore the nested execution, we can just wrap the action with `SQLExecution.ignoreNestedExecutionId`, and this is more expansible than the previous approach. The idea comes from https://github.com/apache/spark/pull/17540/files#diff-ab49028253e599e6e74cc4f4dcb2e3a8R57 by rdblue ## How was this patch tested? existing tests. Author: Wenchen Fan <wenchen@databricks.com> Closes #18419 from cloud-fan/follow.
codegen info of query plan can be very long.
In debugging console / web page, it would be more readable if the subtrees and corresponding codegen are split into sequence.
Example:
```java
codegenStringSeq(sql("select 1").queryExecution.executedPlan)
```
The example will return Seq[(String, String)] of length 1, containing the subtree as string and the corresponding generated code.
The subtree as string:
> (*Project [1 AS 1#0]
> +- Scan OneRowRelation[]
The generated code:
```java
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIterator(references);
/* 003 */ }
/* 004 */
/* 005 */ final class GeneratedIterator extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 006 */ private Object[] references;
/* 007 */ private scala.collection.Iterator[] inputs;
/* 008 */ private scala.collection.Iterator inputadapter_input;
/* 009 */ private UnsafeRow project_result;
/* 010 */ private org.apache.spark.sql.catalyst.expressions.codegen.BufferHolder project_holder;
/* 011 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter project_rowWriter;
/* 012 */
/* 013 */ public GeneratedIterator(Object[] references) {
/* 014 */ this.references = references;
/* 015 */ }
/* 016 */
/* 017 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 018 */ partitionIndex = index;
/* 019 */ this.inputs = inputs;
/* 020 */ inputadapter_input = inputs[0];
/* 021 */ project_result = new UnsafeRow(1);
/* 022 */ project_holder = new org.apache.spark.sql.catalyst.expressions.codegen.BufferHolder(project_result, 0);
/* 023 */ project_rowWriter = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(project_holder, 1);
/* 024 */
/* 025 */ }
/* 026 */
/* 027 */ protected void processNext() throws java.io.IOException {
/* 028 */ while (inputadapter_input.hasNext() && !stopEarly()) {
/* 029 */ InternalRow inputadapter_row = (InternalRow) inputadapter_input.next();
/* 030 */ project_rowWriter.write(0, 1);
/* 031 */ append(project_result);
/* 032 */ if (shouldStop()) return;
/* 033 */ }
/* 034 */ }
/* 035 */
/* 036 */ }
```
## What changes were proposed in this pull request?
add method codegenToSeq: split codegen info of query plan into sequence
## How was this patch tested?
unit test
cloud-fan gatorsmile
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: Wang Gengliang <ltnwgl@gmail.com>
Closes #18409 from gengliangwang/codegen.
## What changes were proposed in this pull request? This PR proposes to close stale PRs, mostly the same instances with #18017 I believe the author in #14807 removed his account. Closes #7075 Closes #8927 Closes #9202 Closes #9366 Closes #10861 Closes #11420 Closes #12356 Closes #13028 Closes #13506 Closes #14191 Closes #14198 Closes #14330 Closes #14807 Closes #15839 Closes #16225 Closes #16685 Closes #16692 Closes #16995 Closes #17181 Closes #17211 Closes #17235 Closes #17237 Closes #17248 Closes #17341 Closes #17708 Closes #17716 Closes #17721 Closes #17937 Added: Closes #14739 Closes #17139 Closes #17445 Closes #18042 Closes #18359 Added: Closes #16450 Closes #16525 Closes #17738 Added: Closes #16458 Closes #16508 Closes #17714 Added: Closes #17830 Closes #14742 ## How was this patch tested? N/A Author: hyukjinkwon <gurwls223@gmail.com> Closes #18417 from HyukjinKwon/close-stale-pr.
…e global
## What changes were proposed in this pull request?
The issue happens in `ExternalMapToCatalyst`. For example, the following codes create `ExternalMapToCatalyst` to convert Scala Map to catalyst map format.
val data = Seq.tabulate(10)(i => NestedData(1, Map("key" -> InnerData("name", i + 100))))
val ds = spark.createDataset(data)
The `valueConverter` in `ExternalMapToCatalyst` looks like:
if (isnull(lambdavariable(ExternalMapToCatalyst_value52, ExternalMapToCatalyst_value_isNull52, ObjectType(class org.apache.spark.sql.InnerData), true))) null else named_struct(name, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(lambdavariable(ExternalMapToCatalyst_value52, ExternalMapToCatalyst_value_isNull52, ObjectType(class org.apache.spark.sql.InnerData), true)).name, true), value, assertnotnull(lambdavariable(ExternalMapToCatalyst_value52, ExternalMapToCatalyst_value_isNull52, ObjectType(class org.apache.spark.sql.InnerData), true)).value)
There is a `CreateNamedStruct` expression (`named_struct`) to create a row of `InnerData.name` and `InnerData.value` that are referred by `ExternalMapToCatalyst_value52`.
Because `ExternalMapToCatalyst_value52` are local variable, when `CreateNamedStruct` splits expressions to individual functions, the local variable can't be accessed anymore.
## How was this patch tested?
Jenkins tests.
Author: Liang-Chi Hsieh <viirya@gmail.com>
Closes #18418 from viirya/SPARK-19104.
## What changes were proposed in this pull request? Add metric on number of running tasks to status bar on Jobs / Active Jobs. ## How was this patch tested? Run a long running (1 minute) query in spark-shell and use localhost:4040 web UI to observe progress. See jira for screen snapshot. Author: Eric Vandenberg <ericvandenberg@fb.com> Closes #18369 from ericvandenbergfb/runningTasks.
## What changes were proposed in this pull request? Update the Quickstart and RDD programming guides to mention pip. ## How was this patch tested? Built docs locally. Author: Holden Karau <holden@us.ibm.com> Closes #18698 from holdenk/SPARK-21434-add-pyspark-pip-documentation.
…own.
Executors run a thread pool with daemon threads to run tasks. This means
that those threads remain active when the JVM is shutting down, meaning
those tasks are affected by code that runs in shutdown hooks.
So if a shutdown hook messes with something that the task is using (e.g.
an HDFS connection), the task will fail and will report that failure to
the driver. That will make the driver mark the task as failed regardless
of what caused the executor to shut down. So, for example, if YARN pre-empted
that executor, the driver would consider that task failed when it should
instead ignore the failure.
This change avoids reporting failures to the driver when shutdown hooks
are executing; this fixes the YARN preemption accounting, and doesn't really
change things much for other scenarios, other than reporting a more generic
error ("Executor lost") when the executor shuts down unexpectedly - which
is arguably more correct.
Tested with a hacky app running on spark-shell that tried to cause failures
only when shutdown hooks were running, verified that preemption didn't cause
the app to fail because of task failures exceeding the threshold.
Author: Marcelo Vanzin <vanzin@cloudera.com>
Closes #18594 from vanzin/SPARK-20904.
## What changes were proposed in this pull request? When the code that is generated is greater than 64k, then Janino compile will fail and CodeGenerator.scala will log the entire code at Error level. SPARK-20871 suggests only logging the code at Debug level. Since, the code is already logged at debug level, this Pull Request proposes not including the formatted code in the Error logging and exception message at all. When an exception occurs, the code will be logged at Info level but truncated if it is more than 1000 lines long. ## How was this patch tested? Existing tests were run. An extra test test case was added to CodeFormatterSuite to test the new maxLines parameter, Author: pj.fanning <pj.fanning@workday.com> Closes #18658 from pjfanning/SPARK-20871.
## What changes were proposed in this pull request? This patch removes the `****` string from test names in FlatMapGroupsWithStateSuite. `***` is a common string developers grep for when using Scala test (because it immediately shows the failing test cases). The existence of the `****` in test names disrupts that workflow. ## How was this patch tested? N/A - test only change. Author: Reynold Xin <rxin@databricks.com> Closes #18715 from rxin/FlatMapGroupsWithStateStar.
…ent after executing peristent ## What changes were proposed in this pull request? This PR avoids to reuse unpersistent dataset among test cases by making dataset unpersistent at the end of each test case. In `DatasetCacheSuite`, the test case `"get storage level"` does not make dataset unpersisit after make the dataset persisitent. The same dataset will be made persistent by the test case `"persist and then rebind right encoder when join 2 datasets"` Thus, we run these test cases, the second case does not perform to make dataset persistent. This is because in When we run only the second case, it performs to make dataset persistent. It is not good to change behavior of the second test suite. The first test case should correctly make dataset unpersistent. ``` Testing started at 17:52 ... 01:52:15.053 WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 01:52:48.595 WARN org.apache.spark.sql.execution.CacheManager: Asked to cache already cached data. 01:52:48.692 WARN org.apache.spark.sql.execution.CacheManager: Asked to cache already cached data. 01:52:50.864 WARN org.apache.spark.storage.RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s. 01:52:50.864 WARN org.apache.spark.storage.RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s. 01:52:50.868 WARN org.apache.spark.storage.BlockManager: Block rdd_8_1 replicated to only 0 peer(s) instead of 1 peers 01:52:50.868 WARN org.apache.spark.storage.BlockManager: Block rdd_8_0 replicated to only 0 peer(s) instead of 1 peers ``` After this PR, these messages do not appear ``` Testing started at 18:14 ... 02:15:05.329 WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Process finished with exit code 0 ``` ## How was this patch tested? Used the existing test Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com> Closes #18719 from kiszk/SPARK-21512.
…ash aggregate ## What changes were proposed in this pull request? In #18483 , we fixed the data copy bug when saving into `InternalRow`, and removed all workarounds for this bug in the aggregate code path. However, the object hash aggregate was missed, this PR fixes it. This patch is also a requirement for #17419 , which shows that DataFrame version is slower than RDD version because of this issue. ## How was this patch tested? existing tests Author: Wenchen Fan <wenchen@databricks.com> Closes #18712 from cloud-fan/minor.
## What changes were proposed in this pull request? With supervise enabled for a driver, re-launching it was failing because the driver had the same framework Id. This patch creates a new driver framework id every time we re-launch a driver, but we keep the driver submission id the same since that is the same with the task id the driver was launched with on mesos and retry state and other info within Dispatcher's data structures uses that as a key. We append a "-retry-%4d" string as a suffix to the framework id passed by the dispatcher to the driver and the same value to the app_id created by each driver, except the first time where we dont need the retry suffix. The previous format for the frameworkId was 'DispactherFId-DriverSubmissionId'. We also detect the case where we have multiple spark contexts started from within the same driver and we do set proper names to their corresponding app-ids. The old practice was to unset the framework id passed from the dispatcher after the driver framework was started for the first time and let mesos decide the framework ID for subsequent spark contexts. The decided fId was passed as an appID. This patch affects heavily the history server. Btw we dont have the issues of the standalone case where driver id must be different since the dispatcher will re-launch a driver(mesos task) only if it gets an update that it is dead and this is verified by mesos implicitly. We also dont fix the fine grained mode which is deprecated and of no use. ## How was this patch tested? This task was manually tested on dc/os. Launched a driver, stoped its container and verified the expected behavior. Initial retry of the driver, driver in pending state:  Driver re-launched: 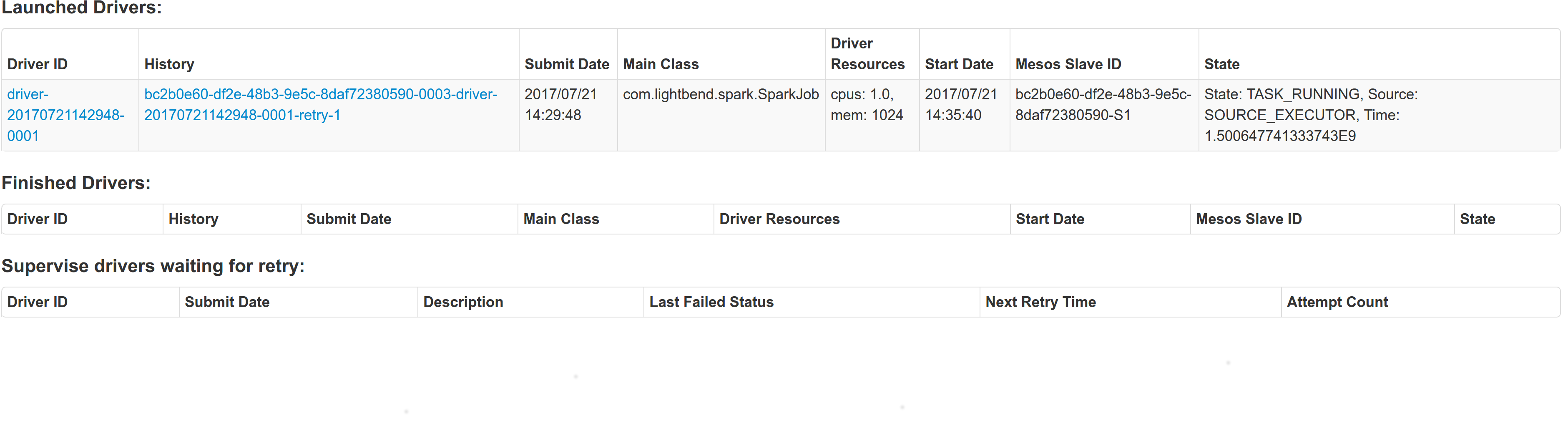 Another re-try:  The resulted entries in history server at the bottom: 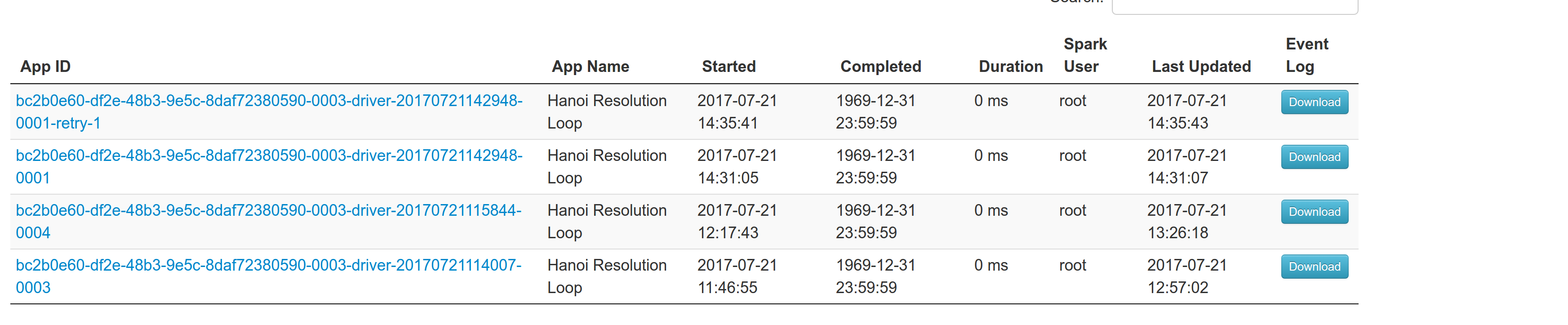 Regarding multiple spark contexts here is the end result regarding the spark history server, for the second spark context we add an increasing number as a suffix:  Author: Stavros Kontopoulos <st.kontopoulos@gmail.com> Closes #18705 from skonto/fix_supervise_flag.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
…must call super.afterEach() ## What changes were proposed in this pull request? This PR ensures to call `super.afterEach()` in overriding `afterEach()` method in `DatasetCacheSuite`. When we override `afterEach()` method in Testsuite, we have to call `super.afterEach()`. This is a follow-up of #18719 and SPARK-21512. ## How was this patch tested? Used the existing test suite Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com> Closes #18721 from kiszk/SPARK-21516.
… KinesisInputDStream builder instead of deprecated KinesisUtils ## What changes were proposed in this pull request? The examples and docs for Spark-Kinesis integrations use the deprecated KinesisUtils. We should update the docs to use the KinesisInputDStream builder to create DStreams. ## How was this patch tested? The patch primarily updates the documents. The patch will also need to make changes to the Spark-Kinesis examples. The examples need to be tested. Author: Yash Sharma <ysharma@atlassian.com> Closes #18071 from yssharma/ysharma/kinesis_docs.
I find a bug about 'quick start',and created a new issues,Sean Owen let me to make a pull request, and I do ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Trueman <lizhaoch@users.noreply.github.com> Author: lizhaoch <lizhaoc@163.com> Closes #18722 from lizhaoch/master.
## What changes were proposed in this pull request? A shuffle service can serves blocks from multiple apps/tasks. Thus the shuffle service can suffers high memory usage when lots of shuffle-reads happen at the same time. In my cluster, OOM always happens on shuffle service. Analyzing heap dump, memory cost by Netty(ChannelOutboundBufferEntry) can be up to 2~3G. It might make sense to reject "open blocks" request when memory usage is high on shuffle service. 93dd0c5 and 85c6ce6 tried to alleviate the memory pressure on shuffle service but cannot solve the root cause. This pr proposes to control currency of shuffle read. ## How was this patch tested? Added unit test. Author: jinxing <jinxing6042@126.com> Closes #18388 from jinxing64/SPARK-21175.
When NodeManagers launching Executors, the `missing` value will exceed the real value when the launch is slow, this can lead to YARN allocates more resource. We add the `numExecutorsRunning` when calculate the `missing` to avoid this. Test by experiment. Author: DjvuLee <lihu@bytedance.com> Closes #18651 from djvulee/YarnAllocate.
inprogress history file in some cases. Add failure handling for EOFException that can be thrown during decompression of an inprogress spark history file, treat same as case where can't parse the last line. ## What changes were proposed in this pull request? Failure handling for case of EOFException thrown within the ReplayListenerBus.replay method to handle the case analogous to json parse fail case. This path can arise in compressed inprogress history files since an incomplete compression block could be read (not flushed by writer on a block boundary). See the stack trace of this occurrence in the jira ticket (https://issues.apache.org/jira/browse/SPARK-21447) ## How was this patch tested? Added a unit test that specifically targets validating the failure handling path appropriately when maybeTruncated is true and false. Author: Eric Vandenberg <ericvandenberg@fb.com> Closes #18673 from ericvandenbergfb/fix_inprogress_compr_history_file.
… .toMap ## What changes were proposed in this pull request? `Traversable.toMap` changed to 'collections.breakOut', that eliminates intermediate tuple collection creation, see [Stack Overflow article](https://stackoverflow.com/questions/1715681/scala-2-8-breakout). ## How was this patch tested? Unit tests run. No performance tests performed yet. Please review http://spark.apache.org/contributing.html before opening a pull request. Author: iurii.ant <sereneant@gmail.com> Closes #18693 from SereneAnt/performance_toMap-breakOut.
### What changes were proposed in this pull request? Like [Hive UDFType](https://hive.apache.org/javadocs/r2.0.1/api/org/apache/hadoop/hive/ql/udf/UDFType.html), we should allow users to add the extra flags for ScalaUDF and JavaUDF too. _stateful_/_impliesOrder_ are not applicable to our Scala UDF. Thus, we only add the following two flags. - deterministic: Certain optimizations should not be applied if UDF is not deterministic. Deterministic UDF returns same result each time it is invoked with a particular input. This determinism just needs to hold within the context of a query. When the deterministic flag is not correctly set, the results could be wrong. For ScalaUDF in Dataset APIs, users can call the following extra APIs for `UserDefinedFunction` to make the corresponding changes. - `nonDeterministic`: Updates UserDefinedFunction to non-deterministic. Also fixed the Java UDF name loss issue. Will submit a separate PR for `distinctLike` for UDAF ### How was this patch tested? Added test cases for both ScalaUDF Author: gatorsmile <gatorsmile@gmail.com> Author: Wenchen Fan <cloud0fan@gmail.com> Closes #17848 from gatorsmile/udfRegister.
…rnal service. There was some code based on the old SASL handler in the new auth client that was incorrectly using the SASL user as the user to authenticate against the external shuffle service. This caused the external service to not be able to find the correct secret to authenticate the connection, failing the connection. In the course of debugging, I found that some log messages from the YARN shuffle service were a little noisy, so I silenced some of them, and also added a couple of new ones that helped find this issue. On top of that, I found that a check in the code that records app secrets was wrong, causing more log spam and also using an O(n) operation instead of an O(1) call. Also added a new integration suite for the YARN shuffle service with auth on, and verified it failed before, and passes now. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #18706 from vanzin/SPARK-21494.
## What changes were proposed in this pull request?
In our production cluster,oom happens when NettyBlockRpcServer receive OpenBlocks message.The reason we observed is below:
When BlockManagerManagedBuffer call ChunkedByteBuffer#toNetty, it will use Unpooled.wrappedBuffer(ByteBuffer... buffers) which use default maxNumComponents=16 in low-level CompositeByteBuf.When our component's number is bigger than 16, it will execute consolidateIfNeeded
int numComponents = this.components.size();
if(numComponents > this.maxNumComponents) {
int capacity = ((CompositeByteBuf.Component)this.components.get(numComponents - 1)).endOffset;
ByteBuf consolidated = this.allocBuffer(capacity);
for(int c = 0; c < numComponents; ++c) {
CompositeByteBuf.Component c1 = (CompositeByteBuf.Component)this.components.get(c);
ByteBuf b = c1.buf;
consolidated.writeBytes(b);
c1.freeIfNecessary();
}
CompositeByteBuf.Component var7 = new CompositeByteBuf.Component(consolidated);
var7.endOffset = var7.length;
this.components.clear();
this.components.add(var7);
}
in CompositeByteBuf which will consume some memory during buffer copy.
We can use another api Unpooled. wrappedBuffer(int maxNumComponents, ByteBuffer... buffers) to avoid this comsuming.
## How was this patch tested?
Test in production cluster.
Author: zhoukang <zhoukang@xiaomi.com>
Closes #18723 from caneGuy/zhoukang/fix-chunkbuffer.
…s wrong temp files ## What changes were proposed in this pull request? jira: https://issues.apache.org/jira/browse/SPARK-21524 ValidatorParamsSuiteHelpers.testFileMove() is generating temp dir in the wrong place and does not delete them. ValidatorParamsSuiteHelpers.testFileMove() is invoked by TrainValidationSplitSuite and crossValidatorSuite. Currently it uses `tempDir` from `TempDirectory`, which unfortunately is never initialized since the `boforeAll()` of `ValidatorParamsSuiteHelpers` is never invoked. In my system, it leaves some temp directories in the assembly folder each time I run the TrainValidationSplitSuite and crossValidatorSuite. ## How was this patch tested? unit test fix Author: Yuhao Yang <yuhao.yang@intel.com> Closes #18728 from hhbyyh/tempDirFix.
## What changes were proposed in this pull request? This change pulls the `LogisticAggregator` class out of LogisticRegression.scala and makes it extend `DifferentiableLossAggregator`. It also changes logistic regression to use the generic `RDDLossFunction` instead of having its own. Other minor changes: * L2Regularization accepts `Option[Int => Double]` for features standard deviation * L2Regularization uses `Vector` type instead of Array * Some tests added to LeastSquaresAggregator ## How was this patch tested? Unit test suites are added. Author: sethah <shendrickson@cloudera.com> Closes #18305 from sethah/SPARK-20988.
…-in functions ## What changes were proposed in this pull request? This generates a documentation for Spark SQL built-in functions. One drawback is, this requires a proper build to generate built-in function list. Once it is built, it only takes few seconds by `sql/create-docs.sh`. Please see https://spark-test.github.io/sparksqldoc/ that I hosted to show the output documentation. There are few more works to be done in order to make the documentation pretty, for example, separating `Arguments:` and `Examples:` but I guess this should be done within `ExpressionDescription` and `ExpressionInfo` rather than manually parsing it. I will fix these in a follow up. This requires `pip install mkdocs` to generate HTMLs from markdown files. ## How was this patch tested? Manually tested: ``` cd docs jekyll build ``` , ``` cd docs jekyll serve ``` and ``` cd sql create-docs.sh ``` Author: hyukjinkwon <gurwls223@gmail.com> Closes #18702 from HyukjinKwon/SPARK-21485.
…ferred. ## What changes were proposed in this pull request? Update the description of `spark.shuffle.maxChunksBeingTransferred` to include that the new coming connections will be closed when the max is hit and client should have retry mechanism. Author: jinxing <jinxing6042@126.com> Closes #18735 from jinxing64/SPARK-21530.
## What changes were proposed in this pull request? This PR ensures that `Unsafe.sizeInBytes` must be a multiple of 8. It it is not satisfied. `Unsafe.hashCode` causes the assertion violation. ## How was this patch tested? Will add test cases Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com> Closes #18503 from kiszk/SPARK-21271.
…e and StructType support. ## What changes were proposed in this pull request? This is a refactoring of `ArrowConverters` and related classes. 1. Refactor `ColumnWriter` as `ArrowWriter`. 2. Add `ArrayType` and `StructType` support. 3. Refactor `ArrowConverters` to skip intermediate `ArrowRecordBatch` creation. ## How was this patch tested? Added some tests and existing tests. Author: Takuya UESHIN <ueshin@databricks.com> Closes #18655 from ueshin/issues/SPARK-21440.
## What changes were proposed in this pull request? Add R-like summary table to GLM summary, which includes feature name (if exist), parameter estimate, standard error, t-stat and p-value. This allows scala users to easily gather these commonly used inference results. srowen yanboliang felixcheung ## How was this patch tested? New tests. One for testing feature Name, and one for testing the summary Table. Author: actuaryzhang <actuaryzhang10@gmail.com> Author: Wayne Zhang <actuaryzhang10@gmail.com> Author: Yanbo Liang <ybliang8@gmail.com> Closes #16630 from actuaryzhang/glmTable.
## What changes were proposed in this pull request? `UnsafeExternalSorter.recordComparator` can be either `KVComparator` or `RowComparator`, and both of them will keep the reference to the input rows they compared last time. After sorting, we return the sorted iterator to upstream operators. However, the upstream operators may take a while to consume up the sorted iterator, and `UnsafeExternalSorter` is registered to `TaskContext` at [here](https://github.com/apache/spark/blob/v2.2.0/core/src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeExternalSorter.java#L159-L161), which means we will keep the `UnsafeExternalSorter` instance and keep the last compared input rows in memory until the sorted iterator is consumed up. Things get worse if we sort within partitions of a dataset and coalesce all partitions into one, as we will keep a lot of input rows in memory and the time to consume up all the sorted iterators is long. This PR takes over #18543 , the idea is that, we do not keep the record comparator instance in `UnsafeExternalSorter`, but a generator of record comparator. close #18543 ## How was this patch tested? N/A Author: Wenchen Fan <wenchen@databricks.com> Closes #18679 from cloud-fan/memory-leak.
## What changes were proposed in this pull request?
This PR contains a tiny update that removes an attribute resolution inconsistency in the Dataset API. The following example is taken from the ticket description:
```
spark.range(1).withColumnRenamed("id", "x").sort(col("id")) // works
spark.range(1).withColumnRenamed("id", "x").sort($"id") // works
spark.range(1).withColumnRenamed("id", "x").sort('id) // works
spark.range(1).withColumnRenamed("id", "x").sort("id") // fails with:
org.apache.spark.sql.AnalysisException: Cannot resolve column name "id" among (x);
```
The above `AnalysisException` happens because the last case calls `Dataset.apply()` to convert strings into columns, which triggers attribute resolution. To make the API consistent between overloaded methods, this PR defers the resolution and constructs columns directly.
Author: aokolnychyi <anton.okolnychyi@sap.com>
Closes #18740 from aokolnychyi/spark-21538.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
20 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.