Tutorial: Empirical Roofline Model
One of the most famous performance models used in HPC is the Roofline model. During courses I was asked often how to derive empirical Roofline models with LIKWID. An empirical Roofline model presents measured values of computational intensity and performance in a Roofline diagram together with the machine limits in order to assess to performance of a loop.
For the empirical Roofline model you need some inputs (measurements, theoretical values) from hardware and the application. This section tells you how to get these numbers.
The first value that is required is the maximum or peak performance of the hardware. In HPC, this is commonly floating-point (FP) performance but it can also be anything else that reflects the maximal amount of "work" the hardware can do per second. For FP performance, you can derive it from the data sheet <num_cores> * <op_width> * <num_ops_per_cycle> * <num_fma> * <cpu_frequency>. Note: If you calculate the FP performance from the data sheet, you get the peak performance. This number may not reflect the achievable FP performance, because you may be limited by some hardware contstraint. For realistic values, you can do some measurements with benchmarks like likwid-bench with the peakflops* kernels, Linpack (HPL) or others. Ensure that you use the same precision (double, single) as the application.
likwid-bench is meant for streaming-access benchmarks but it can be used to perform an FP performance benchmark as well. The idea is that the kernel executes so many FP operations on values in registers that everything else, such as load operations and the loop mechanics, is neglectable. For that, you have to use a stream size that fits into the L1 cache (e.g., 20kB for each core). likwid-bench ships with a few peakflops_* kernels for different vector width and precision (here shown for x86 instruction sets):
| Kernel name | Description |
|---|---|
peakflops |
Double-precision skalar FP operations |
peakflops_sp |
Single-precision skalar FP operations |
peakflops_sse |
Double-precision SSE FP operations |
peakflops_sp_sse |
Single-precision SSE FP operations |
peakflops_avx |
Double-precision AVX FP operations |
peakflops_sp_avx |
Single-precision AVX FP operations |
peakflops_avx_fma |
Double-precision AVX2 fused-multiply-add FP operations |
peakflops_sp_avx_fma |
Single-precision AVX2 fused-multiply-add FP operations |
peakflops_avx512 |
Double-precision AVX512 FP operations |
peakflops_sp_avx512 |
Single-precision AVX512 FP operations |
peakflops_avx512_fma |
Double-precision AVX512 fused-multiply-add FP operations |
peakflops_sp_avx512_fma |
Single-precision AVX512 fused-multiply-add FP operations |
$ likwid-topology
--------------------------------------------------------------------------------
CPU name: Intel(R) Xeon(R) CPU E5-2697 v4 @ 2.30GHz
CPU type: Intel Xeon Broadwell EN/EP/EX processor
CPU stepping: 1
********************************************************************************
Hardware Thread Topology
********************************************************************************
Sockets: 2
Cores per socket: 18
Threads per core: 1
[...]
So we have 2 x 18 hardware threads on this machine (SMT disabled). We use a stream size of 360kB, 10kB for each of the 36 hardware threads so that each vector chunk fits into the L1 cache of one core.
$ likwid-bench -t peakflops -W N:360kB:36
MFlops/s: 164756.12
$ likwid-bench -t peakflops_sse -W N:360kB:36
MFlops/s: 329347.58
$ likwid-bench -t peakflops_avx -W N:360kB:36
MFlops/s: 654908.44
$ likwid-bench -t peakflops_avx_fma -W N:360kB:36
MFlops/s: 1308914.85
If you use above formula, you get:
- scalar:
36 * 1 * 2 * 1 * 2.3GHz = 165600 MFlops/s - SSE:
36 * 2 * 2 * 1 * 2.3GHz = 331200 MFlops/s - AVX:
36 * 4 * 2 * 1 * 2.3GHz = 662400 MFlops/s - AVX (FMA):
36 * 4 * 2 * 2 * 2.3GHz = 1324800 MFlops/s
The bandwidth the Roofline model referes to is commonly the memory bandwidth but you could also use the bandwidth of some other data path. You can calculate the peak based on the data sheet (something like that: <num_sockets> * <num_mem_channels> * <mem_frequency> * <num_mem_controllers> * <data_transfer_unit_size>) or you can measure it. The common way is to measure it with benchmarks like STREAM, TheBandwidthBenchmark or likwid-bench.
Note: It is beneficial for the meaningfulness of the Roofline model to use a benchmark kernel that somehow relates to your application code. This is because memory bandwidth can be a moving target; e.g., on Intel and AMD CPUs, you get more bandwidth if the data traffic is dominated by reads. Hence, the bandwidth ceiling in the Roofline model will be more realistic if you choose a streaming kernel with a read/write ratio similar to the loop you want to analyze. There is nothing wrong, of course, with just using the highest possible bandwidth; this will just make the model a little more optimistic for some loops.
likwid-bench provides various benchmarks to measure the maximal data throughput. The most common ones are load*, copy*, stream* (A[i] = B[i] + scalar * C[i]) and triad* (A[i] = B[i] + C[i] * D[i]). The load* kernel commonly reports the highest bandwidth on x86 CPUs. For proper data placement (i.e., as local as possible to the accessing hardware thread) you should always use -W for the workgroup definitions, which performs proper parallel first-touch placement. With -w, the first thread in the workgroup allocates and initializes the memory, which might not be in the same memory domain as other workgroup threads.
$ likwid-bench -t load -W N:2GB:36
MByte/s: 133156.29
$ likwid-bench -t load_sse -W N:2GB:36
MByte/s: 133145.57
$ likwid-bench -t load_avx -W N:2GB:36
MByte/s: 133228.15
With the peak/maximum performance and data throughput, we are able to construct the roofline itself (i.e., the hardware model).
If you use gnuplot, you can use the following commands:
maxperf = 1308914.85 # MFlops/s
maxband = 133228.15 # MByte/s
roof(x) = maxperf > (x * maxband) ? (x * maxband) : maxperf
plot roof(x) notitle
For the application, we need its arithmetic intensity and its performance. Assuming floating-point performance, you can use likwid-perfctr with the groups MEM_DP and MEM_SP for double and single precision, respectively. It is beneficial to use the Marker API around the application region of interest to get more meaningful measurements.
The only required values in the output of likwid-perfctr -g MEM_* are the FLOP rate (DP [MFLOP/s] or SP [MFLOP/s]) and the Operational intensity from the statistics table in the SUM column.
Disclaimer: The way LIKWID calculates the operational intensity causes that the value differs from manual calculation. This is caused by summing the division of FLOPs and Memory bandwidth of each sockets individually. It should sum up the FLOPs and memory bandwidth of the node first before the division.
For multi-socket systems, it is recommended to measure MEM_DP but calculate the operational intensity manually using xP [MFLOP/s] STAT and Memory bandwidth [MByte/s] STAT, each the SUM value.
$ likwid-perfctr -C E:N:36 -g MEM_DP -m ./a.out
[...]
+----------------------------------------+-------------+-----------+------------+-----------+
| Metric | Sum | Min | Max | Avg |
+----------------------------------------+-------------+-----------+------------+-----------+
| MFLOP/s STAT | 3782.7741 | 103.9862 | 118.6109 | 105.0771 |
| Memory bandwidth [MByte/s] STAT | 12002.4521 | 0.0000 | 6002.4521 | 10.1223 |
| Operational intensity STAT | 0.0666 | 0.0018 | 0.0019 | 0.0019 |
[...]
In order to add the value to the Roofline plot, you add a single dot at x=0.0666 and y=3782.7741.
# add this before the plot command
op_ins = 0.0666
app_perf = 3782.7741
set object circle at first op_ins,app_perf radius char 0.5 fillcolor rgb 'red' fillstyle solid
set label at op_ins,app_perf+30 "Testkernel"
Now you have a complete Roofline plot for your application (or the marked part of it) running on the specific machine. You can reuse the Roofline for all applications (or loops therein) on that machine and just add dots to it. Keep in mind that if more than one loop kernel is measured for a data point, i.e., if the bandwidth and intensity measurement "integrates" over multiple loops, this data point may not be telling you the real story, especially if it comprises memory-bound and core-bound parts. The best strategy is to plot one data point per relevant loop kernel. This also makes it easier to compare with an analytical Roofline model that you may have constructed. Still it can be interesting to look at an "overall" intergrated measurement just to get a qualitative assessment of the application's resource usage.
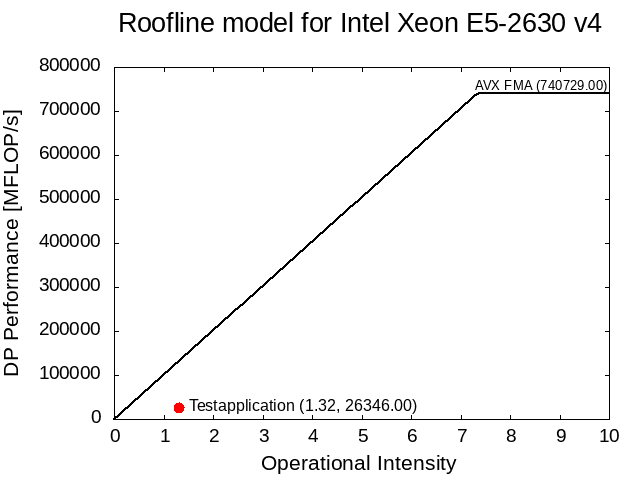
Complete gnuplot script (download):
#!/usr/bin/env gnuplot
# Example gnuplot script for plotting the Roofline model
#
# Author: Thomas Gruber <thomas.roehl@googlemail.com>
# Licence: GPLv3
###############################################################################
# Configure output file
###############################################################################
# Output file (PNG format)
set output 'roofline.png'
###############################################################################
# Set configuration for application
###############################################################################
# Operational intensity
op_ins = 1.32
# Performance value
app_perf = 26346
# The y-axis label
# If you want the model in GFLOP/s, make sure to adjust the y-offsets for the
# labels (application_offset and max_perf_label_offset)
perf_label = 'DP Performance [MFLOP/s]'
# Application name
application = "Testapplication"
application_offset = 2000
###############################################################################
# Set configuration for hardware system
###############################################################################
# Maximum performance
maxperf = 740729 # MFLOP/s, likwid-bench -t peakflops_avx_fma
# Performance label
max_perf_label = "AVX FMA"
max_perf_label_offset = 15000
# Maximum bandwidth
maxband = 100787 # MByte/s, likwid-bench -t load_avx
# System description
sysdef = "Intel Xeon E5-2630 v4"
###############################################################################
# Combine the information to the Roofline model
###############################################################################
# Configure basic plot options
set terminal png enhanced
set ytics font ",14"
set xtics 1 font ",14"
set xrange[0:]
# Set axis labels and title
set xlabel 'Operational Intensity' font ", 16"
set ylabel perf_label font ", 16"
set title sprintf("Roofline model for %s", sysdef) font ", 20"
# Add application dot
set object circle at first op_ins,app_perf radius char 0.5 fillcolor rgb 'red' fillstyle solid
set label 1 at op_ins+0.2,app_perf+application_offset sprintf("%s (%.2f, %.2f)", application, op_ins, app_perf)
# Configure roofline style and label
set style line 1 linetype 1 linecolor rgb 'black' lw 2
set label 2 at (maxperf/maxband)+0.3,maxperf+max_perf_label_offset sprintf("%s (%.2f)", max_perf_label, maxperf) font ",10"
# Plot the Roofline model
roof(x) = maxperf > (x * maxband) ? (x * maxband) : maxperf
plot roof(x) ls 1 notitle