SISR review
[[TOC]]
- 数据: CelebA
- LR-HR图像对:原图像为
$218\times178$ ,中间切出$144\times144$ 的作为HR图像,相应的LR图像通过bicubic(resize$\times4$ )降为$36\times36$ ; - 训练数据集:198547对LR-HR;验证集:2026对LR-HR;测试集:2026对LR-HR
- 网络结构
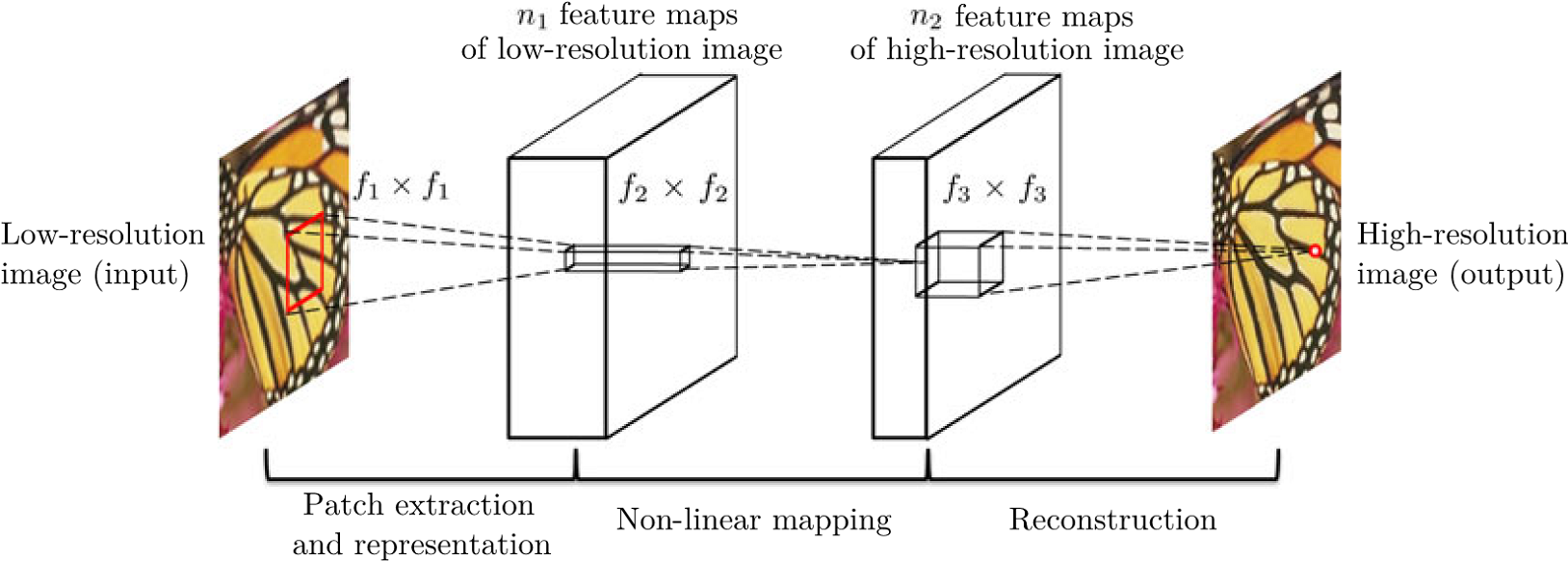
- 输入网络之前进行双三次插值(resize)上采样4倍;
- 论文中只重建YCrCb的Y通道,此处重建了RGB三个通道;
- 属于预上采样框架,上采样方法为bicubic(双三次插值法);
- 三层卷积层,每层输出feature map都为
$144\times144$ ,第一层卷积核为$9\times9\times64$ ,第二层卷积核为$1\times1\times32$ ,第三层卷积核为$5\times5\times3$ 。 - loss:像素级
$l_2$ 损失;
-
预测结果:
1)预测一张
$36\times36$ 到$144\times144$ ($\times4$ )图像,所需时间约0.3-0.4ms;2)PSNR: 25.189 ; SSIM: 0.925 ;
3)模型size:238.5k;
3)图像请参看image/srcnn
-
贡献点:
1)将深度学习应用于SR领域的开山之作
-
训练数据:91-image+Set5
-
LR-HR图像对:LR图像通过bicubic算法获取;
-
⽹络结构
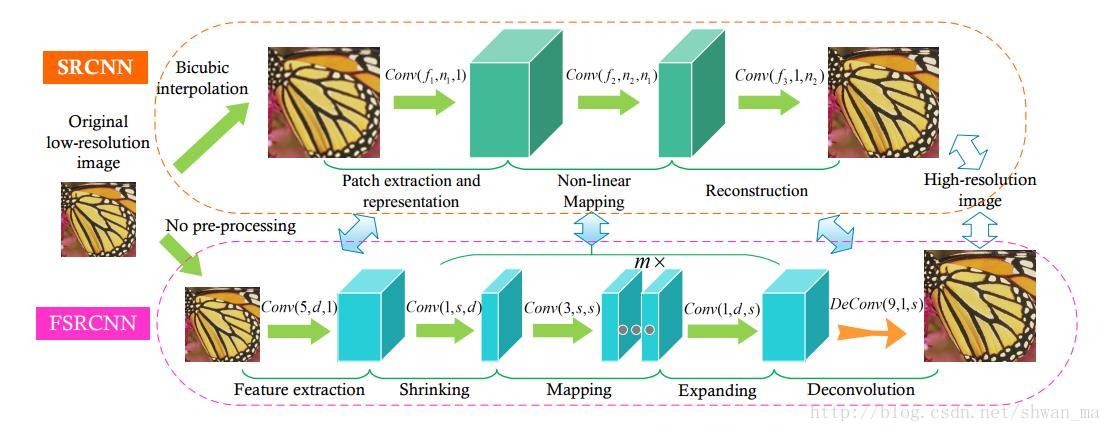
- 后上采样框架,利⽤反卷积直接上采样;
- 只重建Y通道;
- loss:像素级
$l_2$ 损失; - 实验中加反卷积层8层卷积;
-
预测结果
1)预测⼀张
$36\times36$ 到$144\times144$ ($\times4$ )图像,所需时间约0.5ms;2)PSNR:29.88 ;
3)模型size:53.7k;
4)预测图像参看image/fsrcnn
-
贡献点:
1)采⽤反卷积,使得前边⽆需插值,提⾼运算速度
- 网络结构
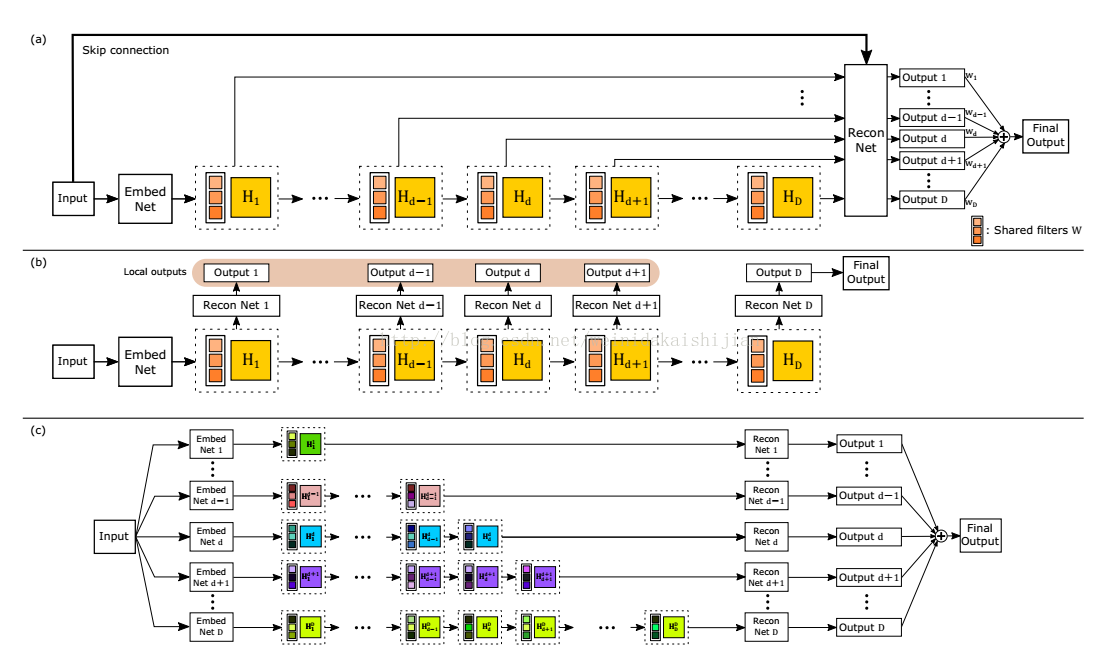
- 预上采样框架,上采样方法bicubic;
- loss:像素级
$l_2$ 损失; - 中间16层递归;
- 图中(a)为DRCN的最终形态;(b)对DRCN加入深度监督,与(a)不同的是重建网络不共享,因此参数量更多;(c)DRCN参数不同享的形态
-
贡献点:
1)只重建高频细节(input直接输入重建网络);
2)引入递归学习,不增加参数量的情况下加深网络,但并不会减少运算时间;
3)引入递归易引起梯度爆炸或梯度弥散,解决方案为:每个递归层的输出都引入监督和全局残差学习
- 训练数据:T91 (2701对LR-HR图像);
- LR-HR图像对:LR图像通过bicubic算法获取;
- ⽹络结构:
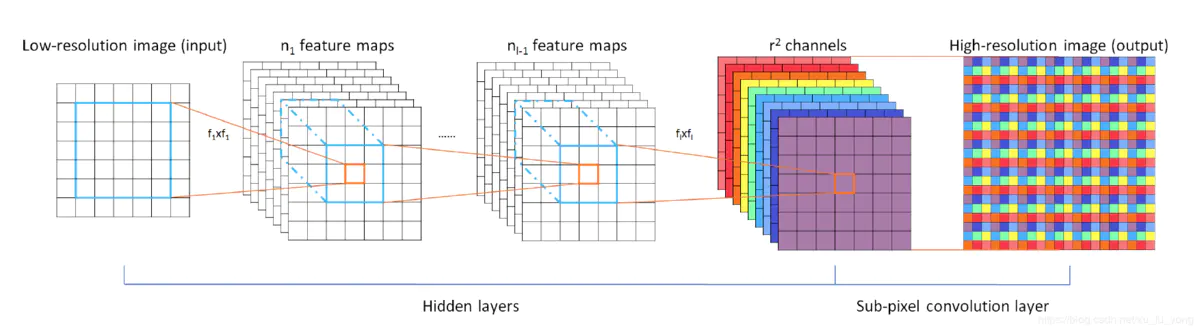
- 后上采样框架,上采样方法亚像素层;
- 只处理Y通道;
- loss:像素级
$l_2$ 损失; - 加上反卷积层共3层卷积;
-
预测结果:
1)预测⼀张
$36\times36$ 到$144\times144$ 图像,所需时间约0.375ms,预测$166\times160$ 到$498\times480$ 所需时间约为30ms,预测$83\times120$ 到$249\times360$ 所需时间约为15ms;2)PSNR:29.962;
3)模型size:90.1k;
4)图像请参看image/espcn
-
贡献点:
1)提出亚像素卷积层
- 训练数据:T91+BSDS200;
- LR-HR图像对:LR图像通过bicubic算法获取;
- ⽹络结构
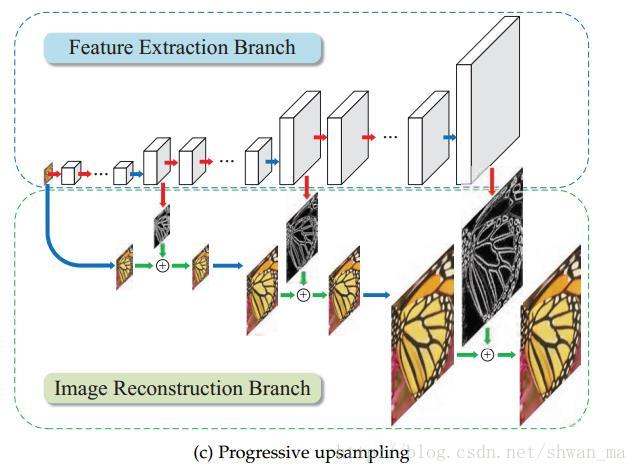
- 渐进式上采样框架,采用反卷积逐渐增大放大倍数,每一级放大都有对应的真值图像,所有与真值图像的loss和作为总的loss;
- 只处理Y通道;
- loss:像素级
$l_1$ 的变形$l_{pixel\_Cha}$ ; - 27层卷积层
-
预测结果:
1)预测⼀张
$36\times36$ 到$144\times144$ 图像,所需时间约1.6ms,预测一张$64\times64$ 到$256\times256$ ,所需时间约2.4ms;2) PSNR:29.685 ;
3)模型size:3.3M;
4)图像请参看image/lapsrn;
-
贡献点:
1)渐进式上采样结构;
2)提出robust Charbonnier损失函数(
$l_1$ loss函数的变形)
- 训练数据: CelebA
- LR-HR图像对:原图像为
$218\times178$ ,中间切出$144\times144$ 的作为HR图像,相应的LR图像通过bicubic(resize)降为$36\times36$ ; - 训练数据集:198547对LR-HR;验证集:2026对LR-HR;测试集:2026对LR-HR
- 网络结构:
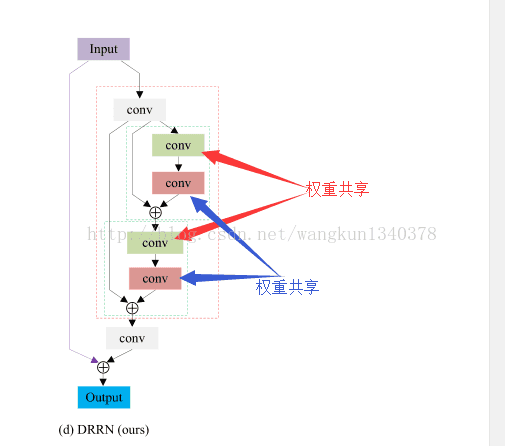
- 属于预上采样框架,输入网络之前进行bicubic上采样;
- 每层输出feature map都为
$144\times144\times128$ ,图中只显示了2个残差递归块,实际上有9个残差递归块(残差模块可以变化,此处实验是U=9); - loss:像素级
$l_2$ 损失;
-
预测结果:
1)预测一张
$36\times36$ 到$144\times144$ 图像,所需时间约2.7ms;2)PSNR:26.809 ;SSIM:0.942 ;
3)模型size:3.5M;
3)预测图像请参看image/drrn_u9,⽣成的sr图像已⽐srcnn清晰很多
-
贡献点:
1)更深的⽹络层次(因为采⽤递归学习,所以搭建更深的⽹络,⽹络参数减少);
2)递归学习;
3)残差学习
- 数据: CelebA
- LR-HR图像对:原图像为
$218\times178$ ,中间切出$144\times144$ 的作为HR图像,相应的LR图像通过bicubic算法降为$36\times36$ ; - 训练数据集:198547对LR-HR;验证集:2026对LR-HR;测试集:2026对LR-HR
- ⽹络结构:
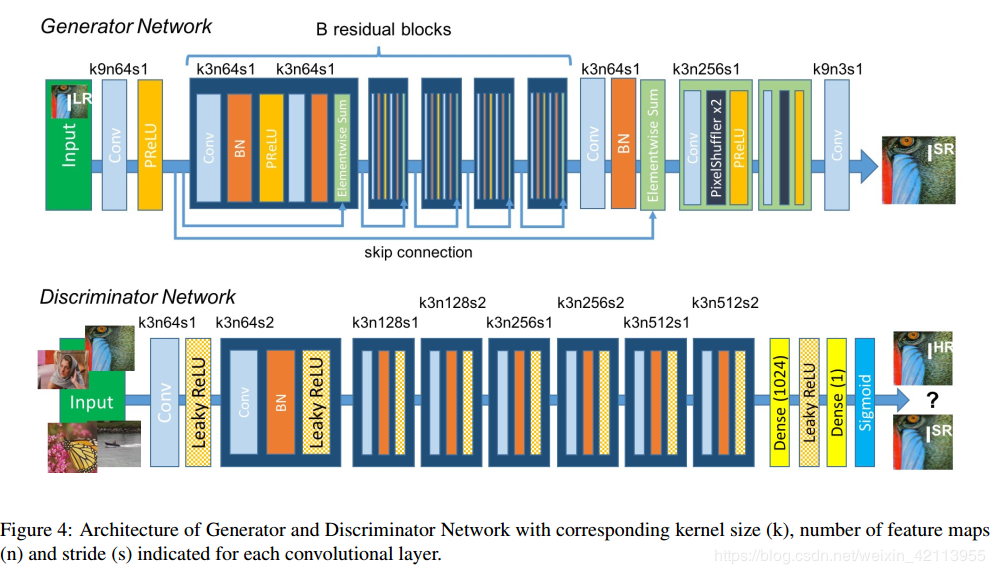
- 属于后上采样框架,输⼊为
$36\times36$ 的LR图像;上采样⽅法为亚像素层,4Xscale采⽤两层亚像素层; - loss:
- 残差块数量为5;
-
预测结果:
1)预测⼀张
$36\times36$ 到$144\times144$ 图像,所需时间约2.58ms;2)PSNR::26.255 ;SSIM:0.925 ;
3)模型size:8.4M;
4)图像请参看image/srgan,⽣成的⾼分图像看起来⽐drrn好⼀些
-
贡献点:
1)提出内容损失函数;
2)多个损失函数联合训练
- 数据: 291图像;
- LR-HR图像对:相应的LR图像通过bicubic算法获得 ;
- 数据增强:裁剪、旋转、降采样;
- ⽹络结构:
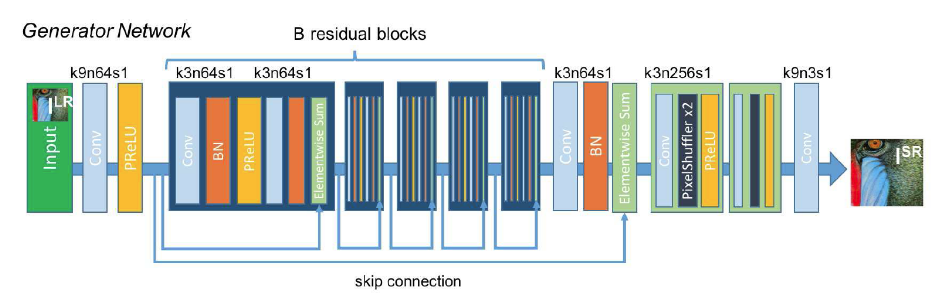
- 属于后上采样框架,输⼊为未上采样的LR图像;上采样⽅法为亚卷积层,4Xscale采⽤2个亚像素层;
- loss:像素级
$l_2$ 损失或者基于vgg_19提取的特征间$l_2$ 损失(内容损失);
-
预测结果:
- 预测⼀张
$36\times36$ 到$144\times144$ 图像,所需时间约2.58ms;
2)模型size:8.4M;
- 预测结果:图像请参看image/srresnet
- 预测⼀张
- 训练数据:比赛提供的DIV2K,它有800张训练图像,100张验证图像,100张测试图像。每张HR图像都是2k分辨率;
- LR-HR图像对:比赛的LR图像是通过Bicubic获取的;
- 网络结构:
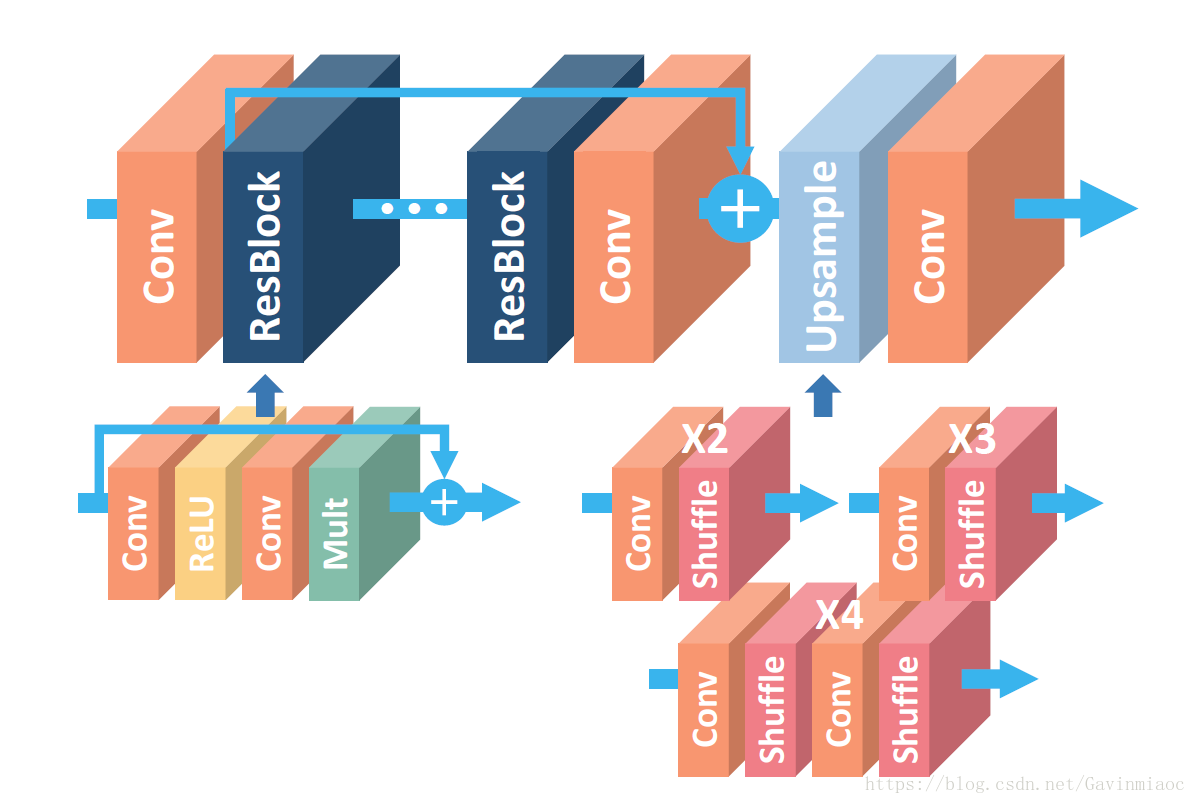
- 属于后上采样框架,上采样用的是亚像素层;
- 预处理:每张图像减去DIV2K的总平均值;
- 在训练
$\times3,\times4$ 模型时,采用$\times2$ 的预训练参数; - loss:损失函数像素级L1损失;
- MDSR网络结构(NTIRE2017第二名,同一篇论文,能同时重建不同上采样倍数的网络结构MDSR):
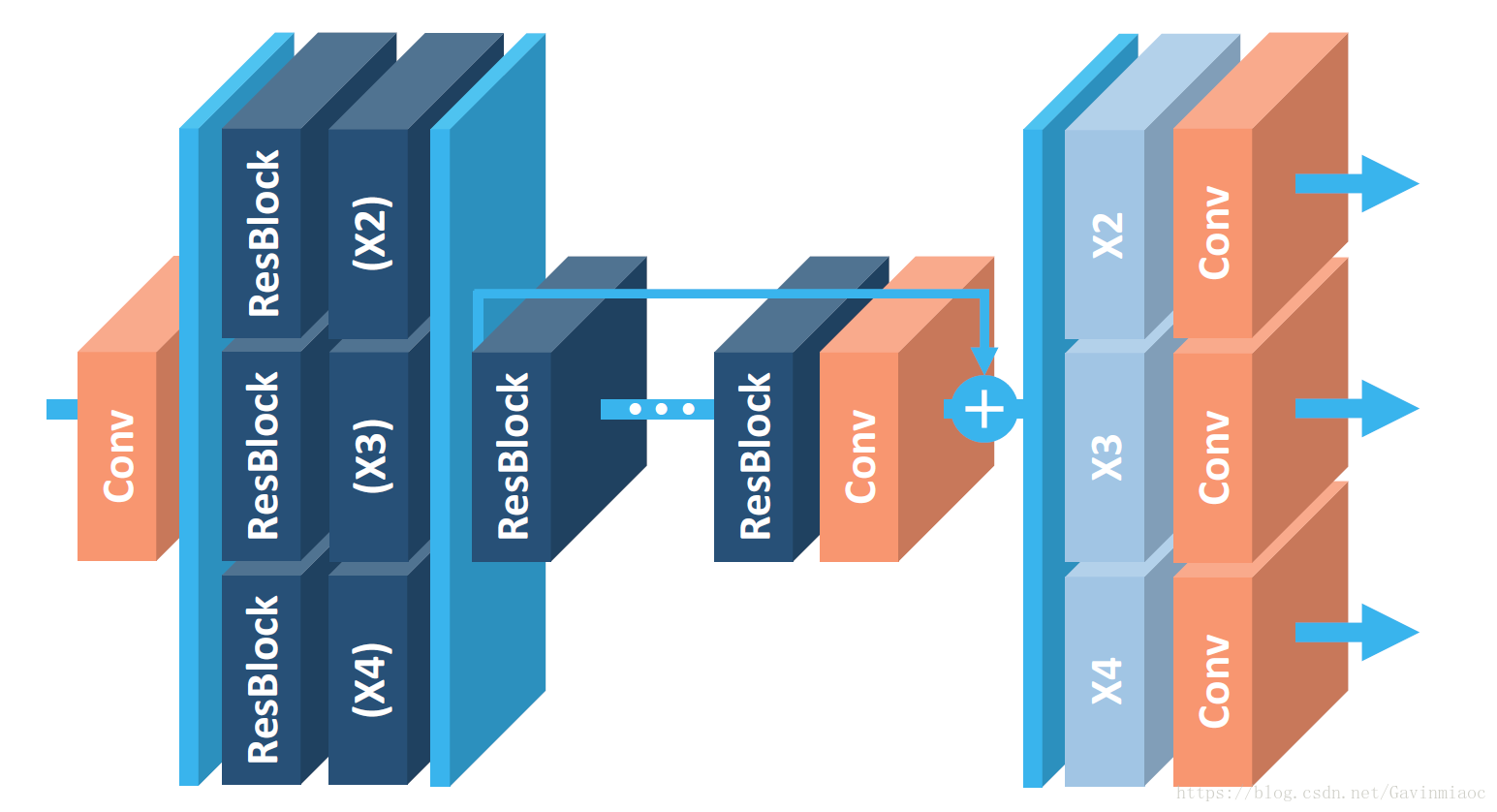
- *2 *3 *4三种的尺度随机混合作为训练集,在更新梯度时,只有对应尺度的那部分参数更新;
- 残差块:
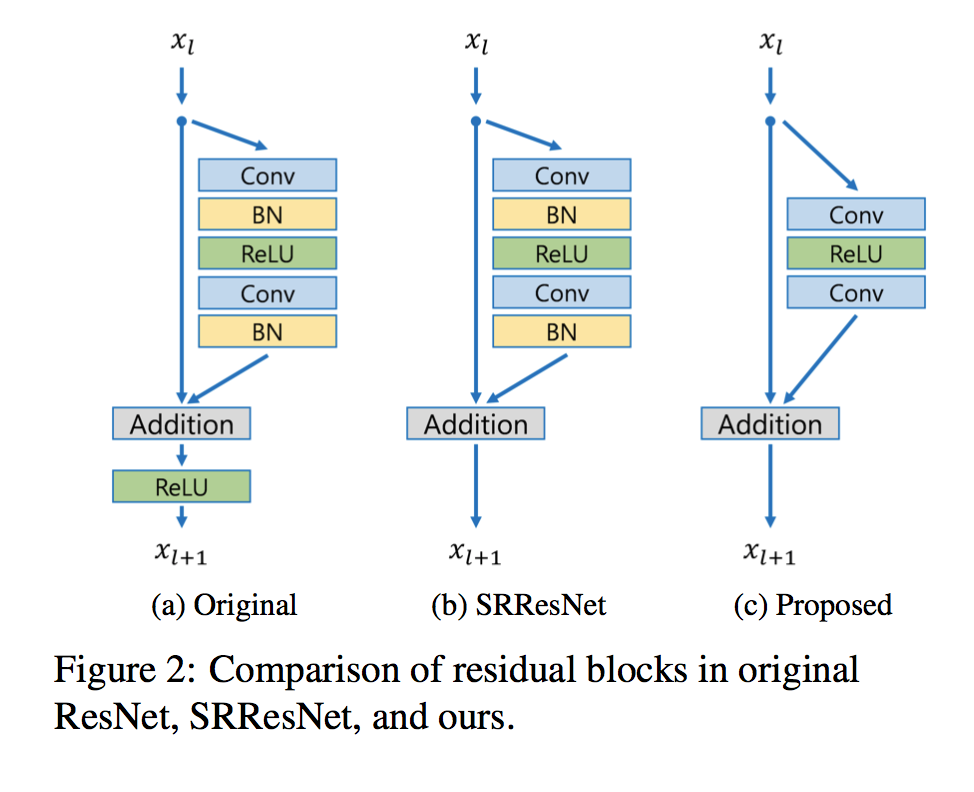
- 值得注意的是,bn层的计算量和一个卷积层几乎持平,移除bn层后训练时可以节约大概40%的空间;
- 太多的残差块会导致训练不稳定,因此作者采取了residual scaling的方法,即残差块在相加前,经过卷积处理的一路乘以一个小数(比如作者用了0.1);这样可以保证训练更加稳定;
- 32个残差块;
-
预测结果:
1)预测⼀张
$339\times510$ 到$1356\times2040$ 图像,所需时间约1.79s;2)PSNR: 29.861;
3)模型size:164.4M;
4)图像请参看image/edsr(树的位置有棋盘效应)
-
贡献点:
1)去掉BN层,可以加深网络结构或增加每层提取的特征数;
2)训练时先训练低倍数的上采样模型,接着用训练低倍数上采样模型得到的参数来初始化高倍数的上采样模型,这样能减少高倍数上采样模型的训练时间,同时训练结果也更好。
-
训练数据: 论文基于MSCOCO训练;
-
LR-HR图像对:相应的LR图像通过bicubic算法获得 ;
-
⽹络结构:

- 属于后上采样框架,上采样方法为最近邻插值;
- RGB三个通道重建;
- loss:像素级
$l_2$ 损失+内容损失(vgg19特征间的$l_2$损失)+纹理损失(vgg_19提取特征,本文最重要的贡献纹理损失)+对抗loss; - 10个残差块;
-
预测结果:
1)预测⼀张
$36\times36$ 到$144\times144$ 图像,所需时间约25.16ms(tensorflow),预测⼀张$72\times72$ 到$288\times288$ 图像,所需时间约71.12ms(tensorflow),预测⼀张$64\times64$ 到$256\times256$ 图像,所需时间约56.36ms (tensorflow),预测⼀张$86\times57$ 到$344\times228$ 图像,所需时间约115.37ms(tensorflow);2)PSNR:31.5;
3)模型size:3.3M;
4)图像请参看image/enhancenet(人脸伪影很严重)
-
贡献点:
1)提出纹理损失函数
- 训练数据: 291图像(随机切出
$31\times31$ HR图像,利用bicubic得到降2、3、4的LR图像,输入为经过bicubic上采样到$31\times31$ 的图像); - ⽹络结构:
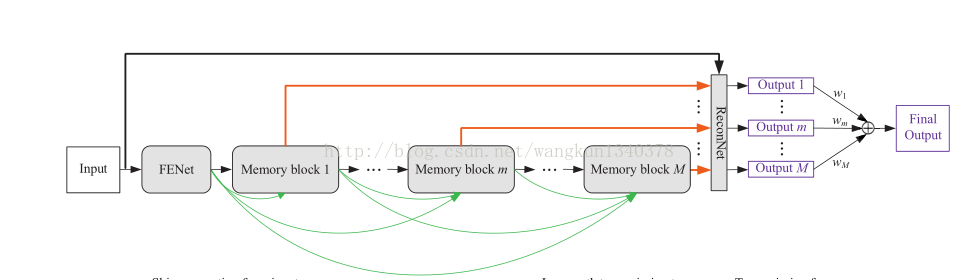
- 属于预上采样框架,输⼊为经过双三次插值的图像;
- PENet只是一些卷积,提取特征后,进入迭代模块,多个block递归堆叠,但是,每个记忆模块(memory block)都参与了最终输出,即都连接到了ReconNet,并且不同的记忆单元之间稠密链接,ReconNet是个卷积核为1X1的卷积层,负责将所有记忆单元的存储信息分别输出,最终所有记忆模块的重建均被输出,所有输出进行加权elementwise相加;
- 只处理Y通道重建;
- 6个memeory模块(每个记忆模块,前边为残差块,后边为门控(BN+relu+conv));
- loss:像素级
$l_2$ 损失;
-
预测结果:
1)未测试,测试图像输入为
$512\times512$ ,cuda不够;2)模型size:11.2M(memory block为递归模块,共享参数);
-
贡献点:
1)提出记忆模块
- 训练数据:DIV2K_train_HR,从每张图像中不重叠的切出
$96\times96$ 的图像作为HR图像,利用Bicubic获得对应的$\times4$ LR图像; - 只处理Y通道;
- 网络结构:
- 属于后上采样框架,上采样方法为反卷积层;
- 文章中针对用于最后重建的输入内容不同,设计了三种结构并做了比较。一是反卷积层只输入最顶层稠密块的输出。二是添加了一个跳跃连接,将最底层卷积层的输出特征和最顶层稠密块的输出特征串联起来,再输入反卷积层。三是添加了稠密跳跃连接,就是把稠密块看成一个整体,第一个卷积层的输出以及每个稠密块的输出,都输入给之后的所有稠密块,像是把在反卷积层之前的整个网络也设计成像稠密块那样的结构。由于这样做,所有的特征都串联起来,这样直接输入反卷积层会产生巨大的计算开销,因此添加了一个核大小为1×1的卷积层来减小特征数量,这个卷积层被称为瓶颈层。最后的结果是越复杂的越好,(c)>(b)>(a)。文章中分析的是,受益于低层特征和高层特征的结合,超分辨率重建的性能得到了提升。像第三种结构把所有深度层的特征都串联起来,得到了最佳的结果,说明不同深度层的特征之间包含的信息是互补的;
- 实验中8个dense模块;
- loss:损失函数为
$l_2$ 损失;
-
预测结果
1)PSNR: 31.48,SSIM:0.8834;
2)
$128\times128$ 到$512\times512$ 运行时间212.86ms ;3)模型size:27.6M;
4)图像请参看image/srdensenet
-
贡献点:
1)将DenseNet思想用于SR领域
DBPN(2018, CVPR,NTIRE2018 x8 Bicubic Downsampling第一名,PIRM2018 1st on Region 2, 3rd on Region 1, and 5th on Region 3, X8)
- 训练数据:DIV2K HR图像,LR图像通过bicubic降采样8倍,从HR图像中切出
$320\times320$ 作为HR图像,从降采样的LR图像中切出$40\times40$ 作为LR图像; - 数据增强:flip(上下翻转)、mirror(水平翻转)、旋转180度;
- 网络结构:
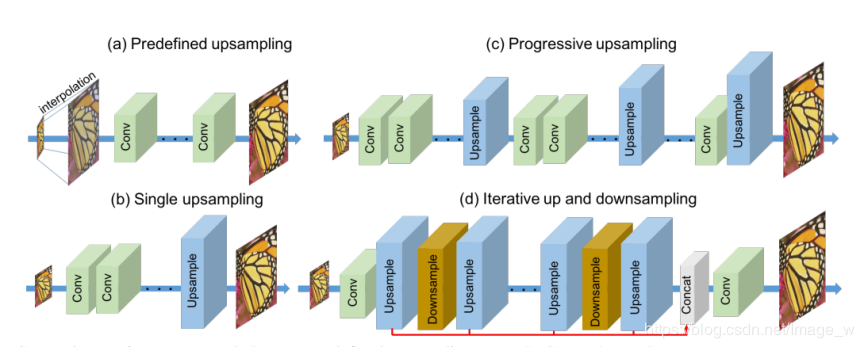
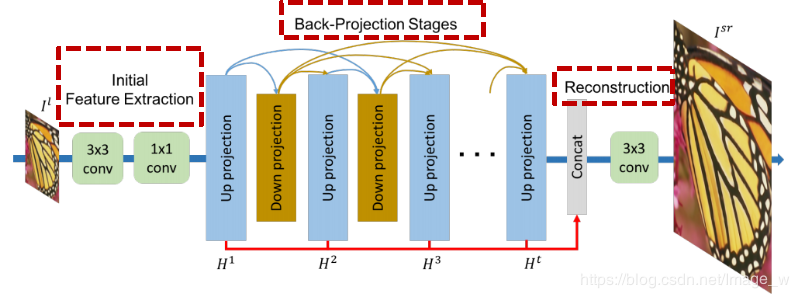
-
迭代式上下采样,上采样方法为反卷积;
-
RGB三个通道重建;
-
本文提出的深度反馈投影网络中有两个重要的模块:上投影单元和下投影单元;
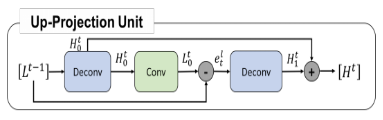
-
6个上下采样块;
-
loss:像素级
$l_1$ 损失;
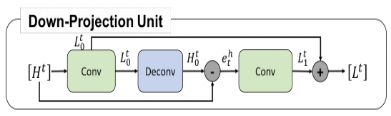
-
预测结果:
1)
$35\times35$ ->$280\times280$ 平均运行时间~7ms;2)模型size:88.5M;
3)图像请参看image/dbpn
-
贡献点:
1)提出了一种迭代上采样和下采样的网络结构,有点类似于传统的迭代算法。直观地看,是为了能够更深地挖掘低分辨率和高分辨率图像直接的相互依赖关系。
- 网络结构:
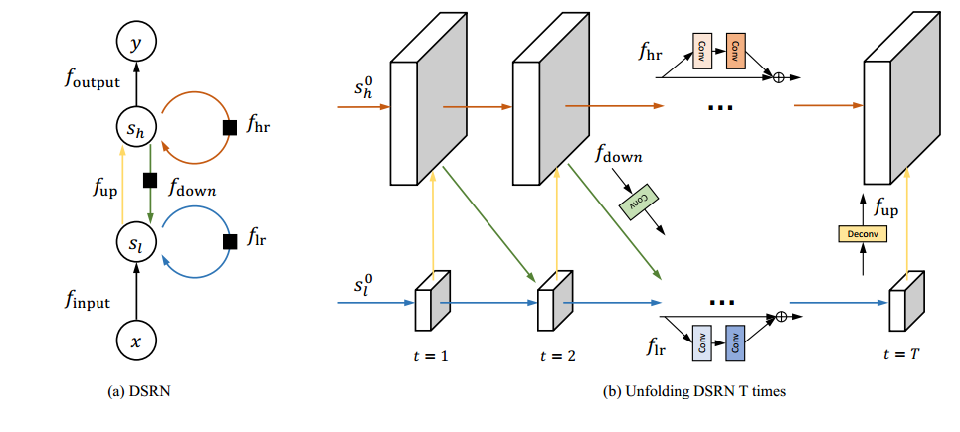
- loss:学习到的是HR图像与bicubic HR图像间的差值;
-
贡献点:
1)HR空间和LR空间同时学习
- 训练数据:DIV2K HR图像经过Bicubic获取
$\times4$ 的LR图像,每次取数据时,随机切出$32\times32$ 的LR图像; - 数据增强:水平镜像、垂直镜像、旋转90度,训练800epoch;
- 网络结构:
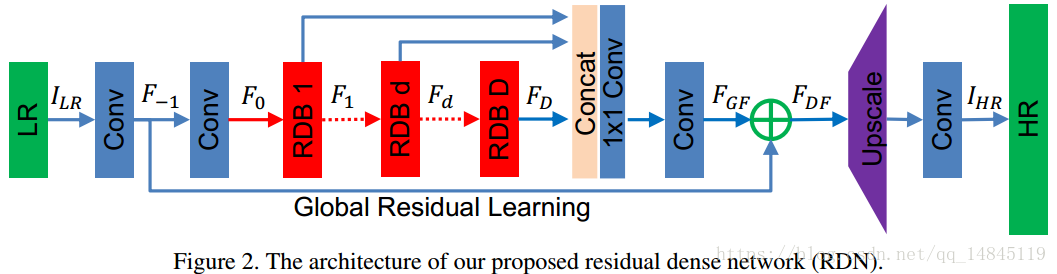
-
redidual dense blocks (RDBs)
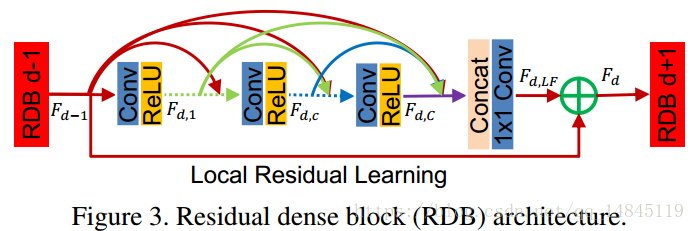
-
属于后上采样框架,上采样方法采用的是亚像素上采样;
-
重建RGB三个通道;
-
16个RDB模块;
-
loss:像素级
$l_1$ 损失;
-
预测结果:
1)
$36\times36$ 到$144\times144$ 小图预测时间~14ms,$480\times320$ 超分$\times4$ 约800ms;2)PSNR:29.95;
3)模型Size:85M;
4)预测图像请参看image/rdn
-
贡献点:
1)将残差和densenet相结合
- 训练数据: DIV2K,
$\times2$ $\times3$ $\times4$ 一起训练; - 网络结构:
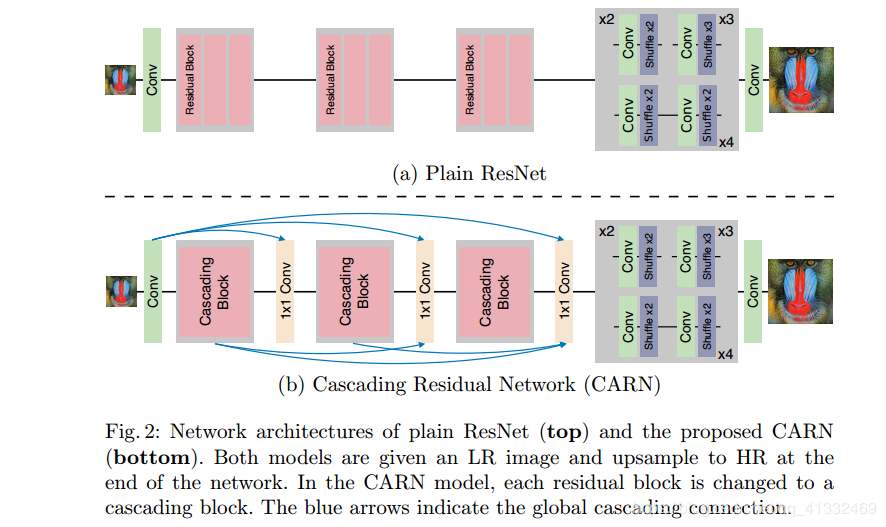
- 属于后上采样框架,上采样方法为亚像素上采样;
- RGB三个通道重建;
- 全局和局部级联连接;
- 中间特征是级联的,且被组合在
$1\times1$ 大小的卷积块; - 使多级表示和快捷连接,让信息传递更高效
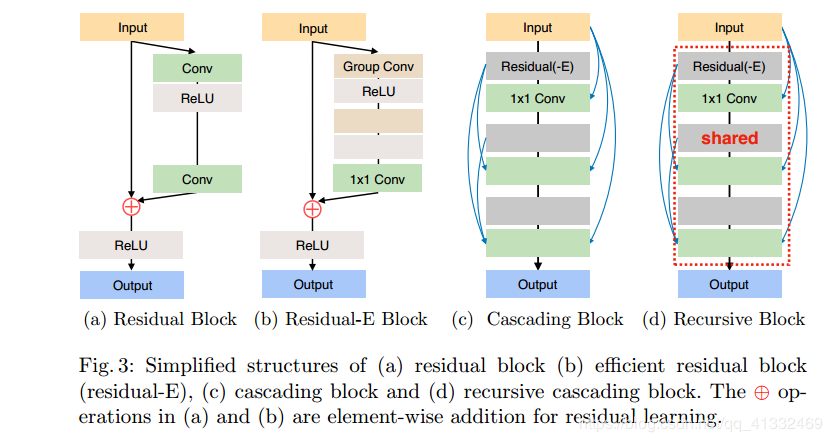
- 利用分组卷积更高效;
- 3个cascading block;
-
预测结果:
1)测试在DIV2K数据,
$\times4$ 预测时间约为100ms;2)模型size: 6.1M;
3)预测图像请参看image/carn
-
贡献点:
1)级联残差
- 训练数据:DIV2k, HR图像从HR中随机截取的
$192\times192$ ,LR从LR图像中随机截取的$48\times48$ ; - 数据增强:水平翻转、垂直翻转、旋转90度
- 网络结构:
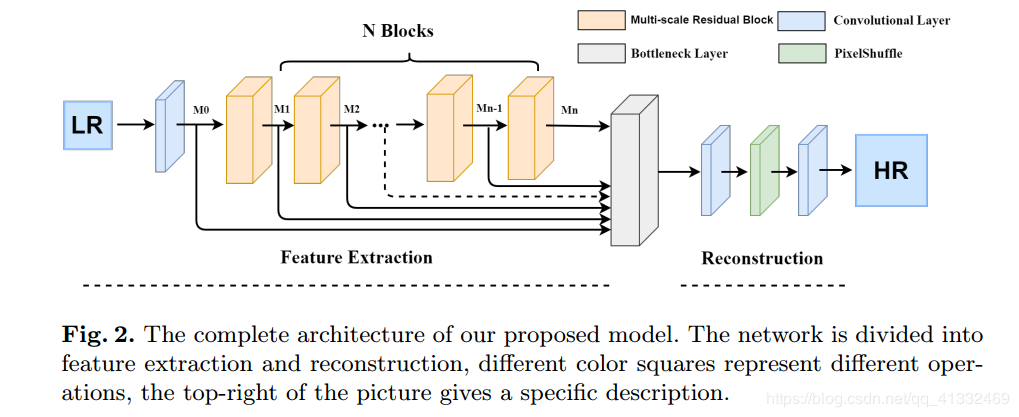
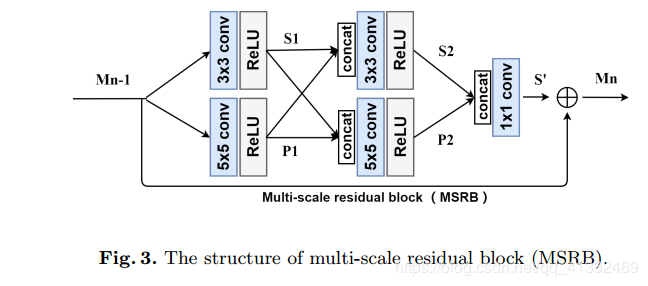
- MSRB结构
- HFFS(1*1卷积,Fig2中的瓶颈层)
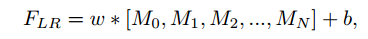
- 重建
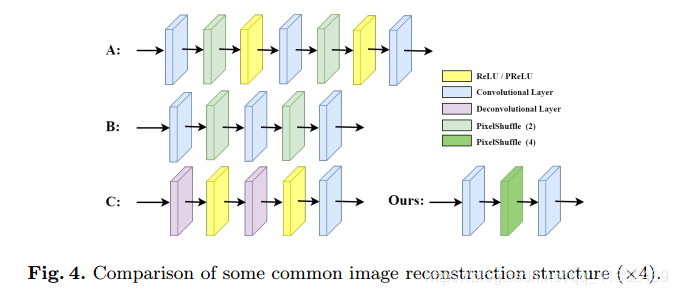
- 属于后上采样框架,上采样方法为亚像素层;
- loss:像素级
$l_1$ loss; - 8个MSRB模块;
- 预测时是将图像拆成四部分预测再拼接的;
-
预测结果:
1)
$\times2$ 的 psnr为38.072,一张图像平均运行时间为410ms;$\times4$ psnr为32.245,预测一张图像平均用时440ms;2)模型Size:
$\times4$ 23.2M;3)结果请参看mage/msrn
-
贡献点:使用多尺度残差块充分提取图像特征:
1)使用MSRB(多尺度残差块)来获取不同尺度的图像特征(局部多尺度特征);
2)将每个MSRB的输出组合起来进行全局特征融合(HFFS(层次特征融合结构)),一个1×1卷积核为瓶颈层); 将局部多尺度特征与全局特征相结合,最大限度地利用LR图像特征,彻底解决特征在传输过程中消失的问题
- 训练数据:DIV2K,从HR图像中随机切出
$192\times192$ 的图像块作为HR图像,对应的LR图像中随机切出$48\times48$ 的图像块作为LR图像;训练数据量为(800*20对LR-HR图像); - 数据增强:水平镜像、垂直镜像、旋转90度,也可以添加噪声;
- 网络结构:
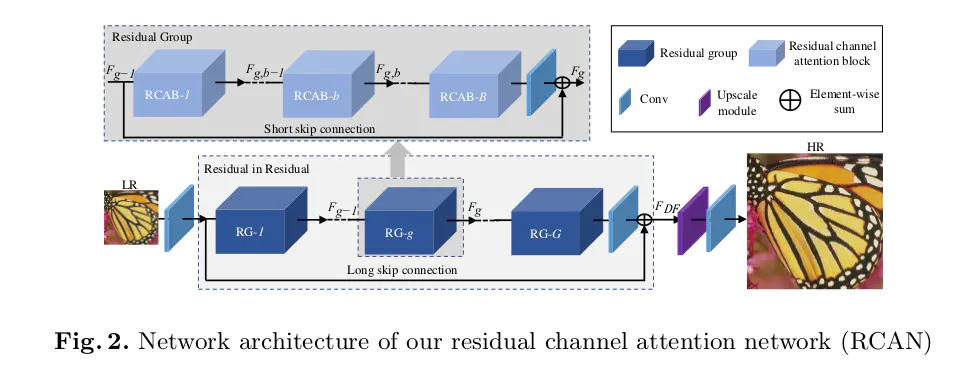
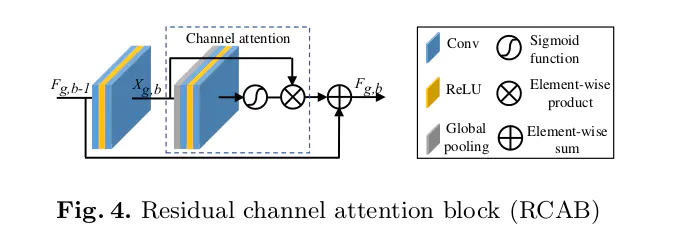
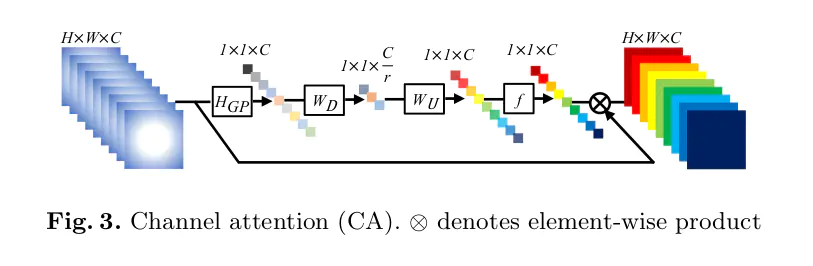
- 属于后上采样框架,上采样方法为亚像素层;
- 输入一个低分辨率图片,先经过一个 3×3 的卷积提取特征 F,然后经过一个 RIR (Residual In Residual)模块;
- RIR模块:包含 10 个 RG(Residual Group)、一个 3×3 的卷积和一个 LSC(Long Skip Connection),最后是一个上采样层和一个 3×3 的卷积层;
- loss:像素级
$l_1$ 损失;
-
预测结果:
1)
$\times2$ :PSNR= 38.274168 SSIM= 0.961445;$\times3$ :PSNR= 34.742155 SSIM= 0.929886;$\times4$ : PSNR= 32.633562 SSIM= 0.900241;$\times8$ : PSNR= 27.307985 SSIM= 0.787769;2)模型size
$\times4$ 59.7M;3)预测图像请参看image/rcan
-
贡献点:
1)采用通道注意力机制;
2)局部残差和全局残差
-
网络结构:
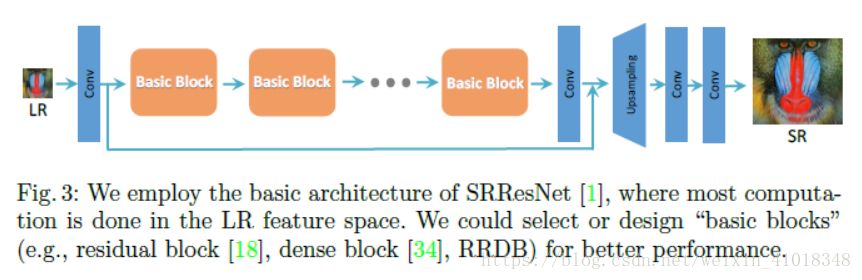
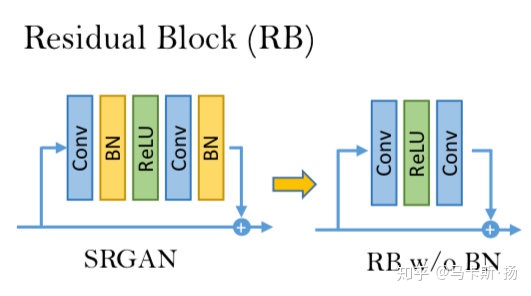
- 对残差块的改进其实就是去掉BN层,文中认为SRGAN之所以产生伪影,就是因为BN层的原因
- 改进的对抗损失函数:

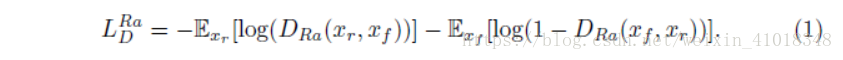
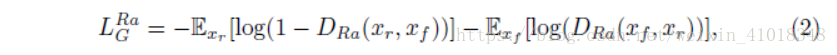
绝对判别器改为相对判别器,相对判别器试图预测真实图像$x_r$比假图像$x_f$更加真实的概率。
-
改进内容损失,在SRGAN通过激活前约束特征而不是激活后,生成器完整的损失函数可以表示为:
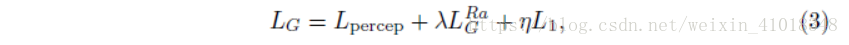
-
属于后上采样框架,上采样方法最近邻插值,最近邻插值后加卷积层;
-
论文中还实验了网络插值法
-
预测结果:
1)
$\times4$ : PSNR为28.42167396487689; SSIM为0.9316604256629943;2)
$\times4$ 模型Size:63.8M;3)预测图像请参见image/esrgan
-
贡献点:基于SRGAN
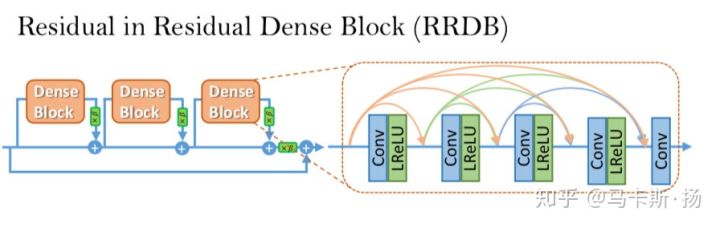
1)改进网络结构,引入Residual-in-Residu Dense Block(RRDB);
2)改进对抗损失和感知(内容)损失;
3)使用激活前的VGG特征来构建感知损失
- 训练数据:DIV2K,从HR中随机切出
$192\times192$ 的图像块作为HR图像,对应的LR图像中随机切出$48\times48$ 的图像块作为LR图像;训练数据量为(800*20对LR-HR图像); - 数据增强:水平镜像、垂直镜像、旋转90度,也可以添加噪声;
- 网络结构:

-
后上采样框架,上采样方法为反卷积;
-
Conv代表卷积层,RNAB代表残差非局部注意力层,RAB代表残差局部注意力层。整个网络简称RNAN网络;
-
残差局部注意力块(residual attention block,RAB)的结构和作用:
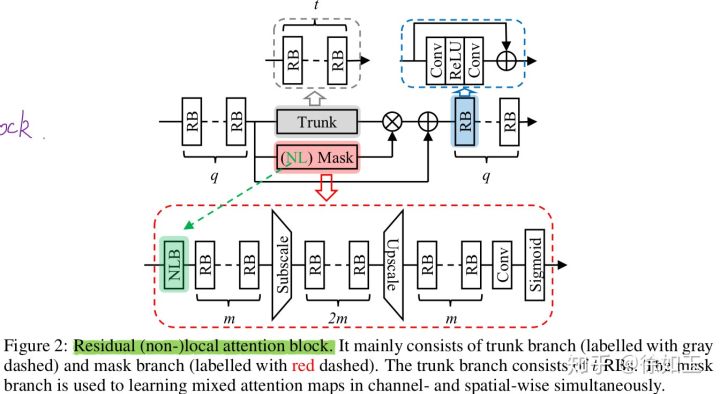
在注意力块的开头和结尾,分别有q个残差块,进行特征学习。残差块采用最简单的三层结构,其中两层Conv层和一层ReLU层,这是因为这种简化的残差块更适合SR这种低层次的计算机视觉任务;
在注意力块的中间分为两个分支,他们分为是trunk分支和mask分支。在trunk分支中,包括t个残差块,进行层次特征的学习。
在mask分支中,包括了局部和非局部两种。局部的mask分支是去除NLB块的,它的主要作用是扩大图像的接受域。局部mask分支首先会经过m个残差块进行层次特征学习,在这m个残差块中每层使用的卷积步长≥2,这样就逐步扩大了图像的接受域,使每层的残差学习的图像块的接受域都比上一层要大,同时也对图像造成了下采样的效果使feature map变小了。然后局部mask分支再经过2m个残差块,在这2m个残差块中进行了deconvolution操作,这样就会使feature map变大,造成了上采样的效果。
-
残差非局部注意力块(residual non-local attention block,RNAB)
RNAB相比于RAB的区别是,RNAB在RAB的mask分支中的开头加入了非局部块(non-local block,NLB)。非局部操作可被定义成:
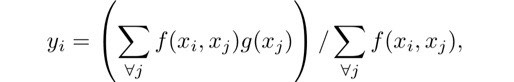
其中,i是输出位置的index,j是所有位置的index,x是输入,y是输出。f函数计算的是两个位置块的关系,g函数是用来表示j位置块的。上式相当于计算了整个图像块的所有位置与位置i的关系。
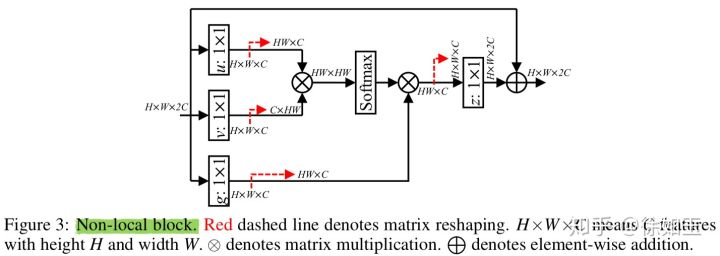
- 在attention块中,两个分支trunk和mask得到的结果进行简单相乘的话,无法适应很深的网络,所以在相乘后和进入attention块之前加一个skip连接实现残差学习,可以加深网络深度;
- 重建RGB三个通道;
- loss:像素级
$L_1$ 损失
-
预测结果:
1)
$\times4$ , PSNR为32.431;2)运行时间约为900ms;
3)
$\times4$ 模型Size:35.4M;4)预测结果请参见image/rnan;
-
贡献点:
1)扩大图像的接受域,使得在处理时能够利用远程依赖;
2)不同的feature map区别对待,因为不同的feature map包含不同的信息
- 训练数据:DIV2K, 从HR中随机切出
$192\times192$ 的图像块作为HR图像,对应的LR图像有很多对应的scale LR; - 网络结构:
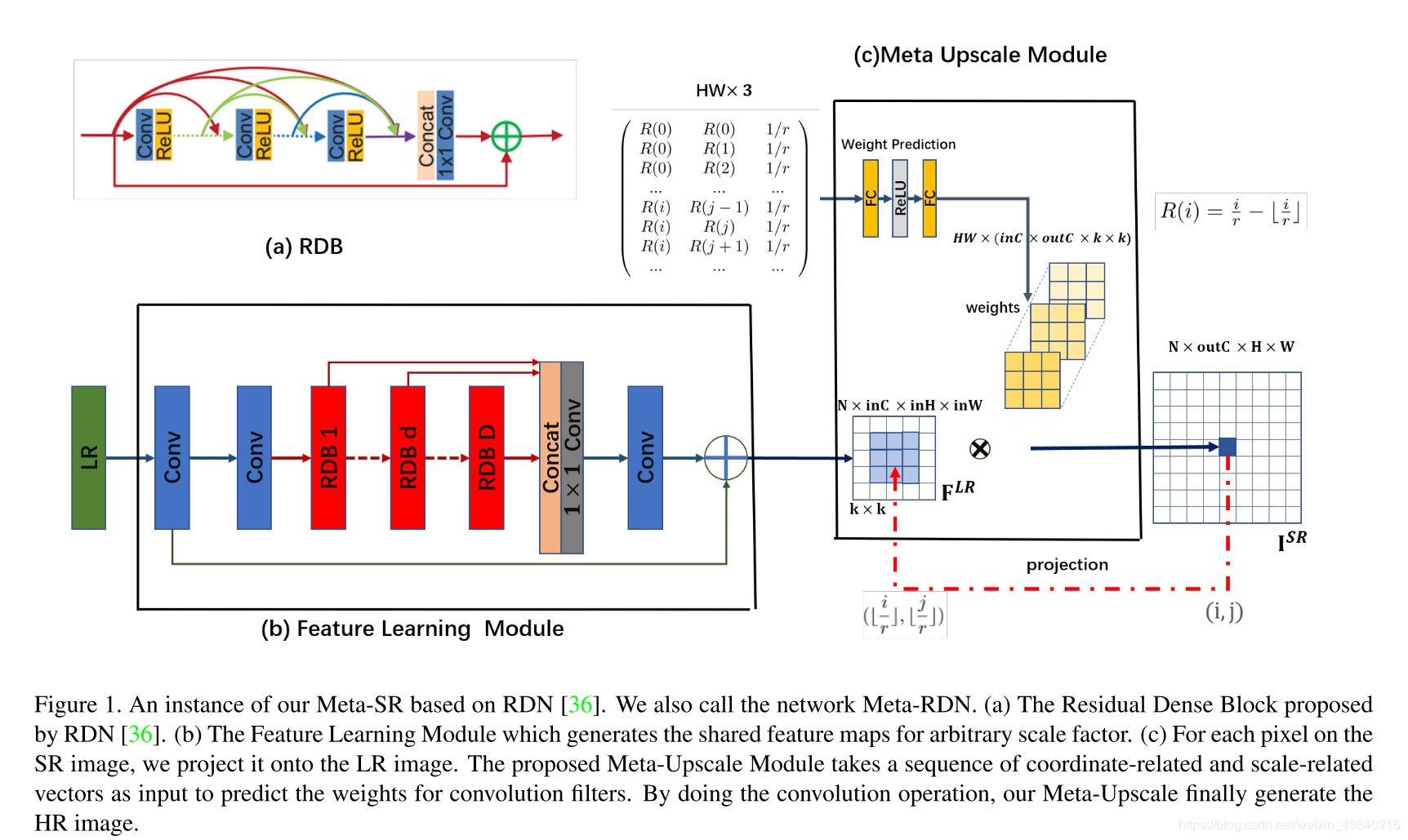
-
Meta-Upscale Module
该模块由3部分组成:
- Location Projection(HR-LR像素位置映射)
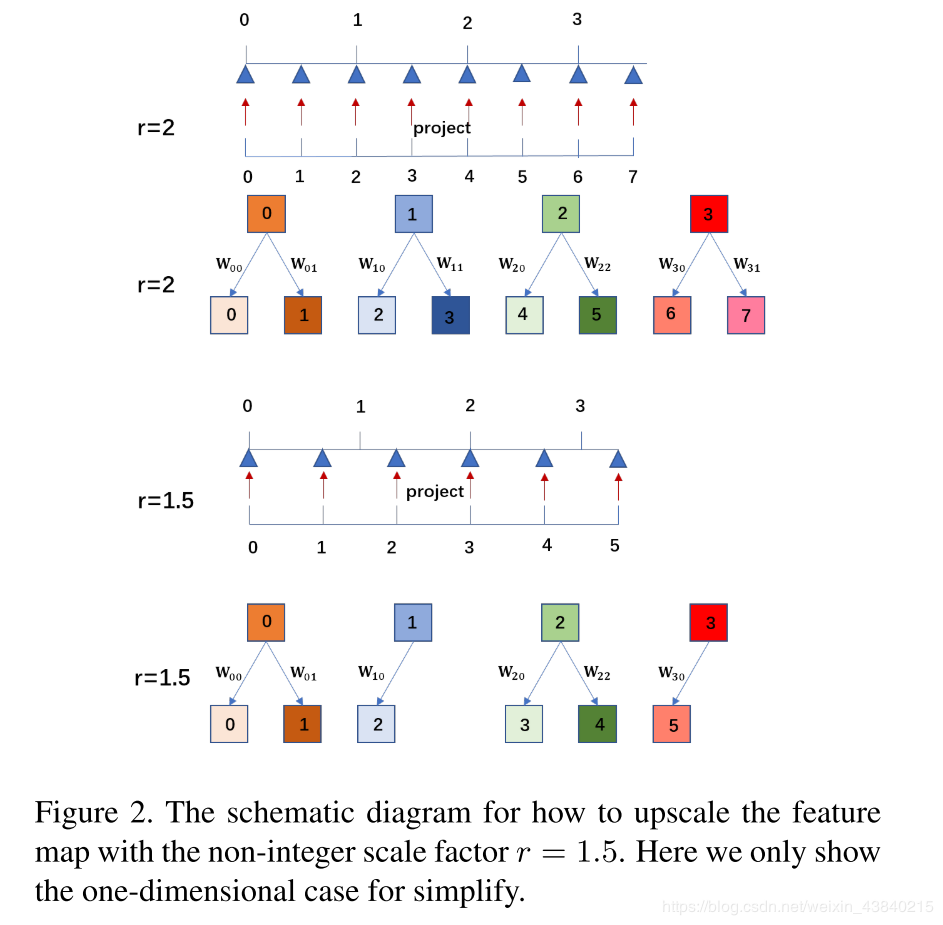
2)Weight Prediction(权重预测):Meta-SR结构图右侧方框中部分,2个FC层,1个Relu激活层。
3)特征映射
- RGB三个通道重建;
-
预测结果:
1)预测一张图像平均耗时~70ms;
2)Set5
$\times1.5$ : PSNR: 29.307 SSIM: 0.88943)模型size:85.6M;
4)预测图像请参见image/metasr
-
贡献点:
1)利用meta-learning,可解决任意放大尺寸的图像超分问题
- 训练数据:DIV2K,从HR中随机切出
$192\times192$ 的图像块作为HR图像,对应的LR图像对应切出$\times$ scale的LR图像; - 数据增强:随机水平翻转、随机垂直翻转、随机旋转90度
- 网络结构:
- 属于后上采样框架,上采样方法为亚像素上采样;
- RGB三个通道重建;
- loss:像素级
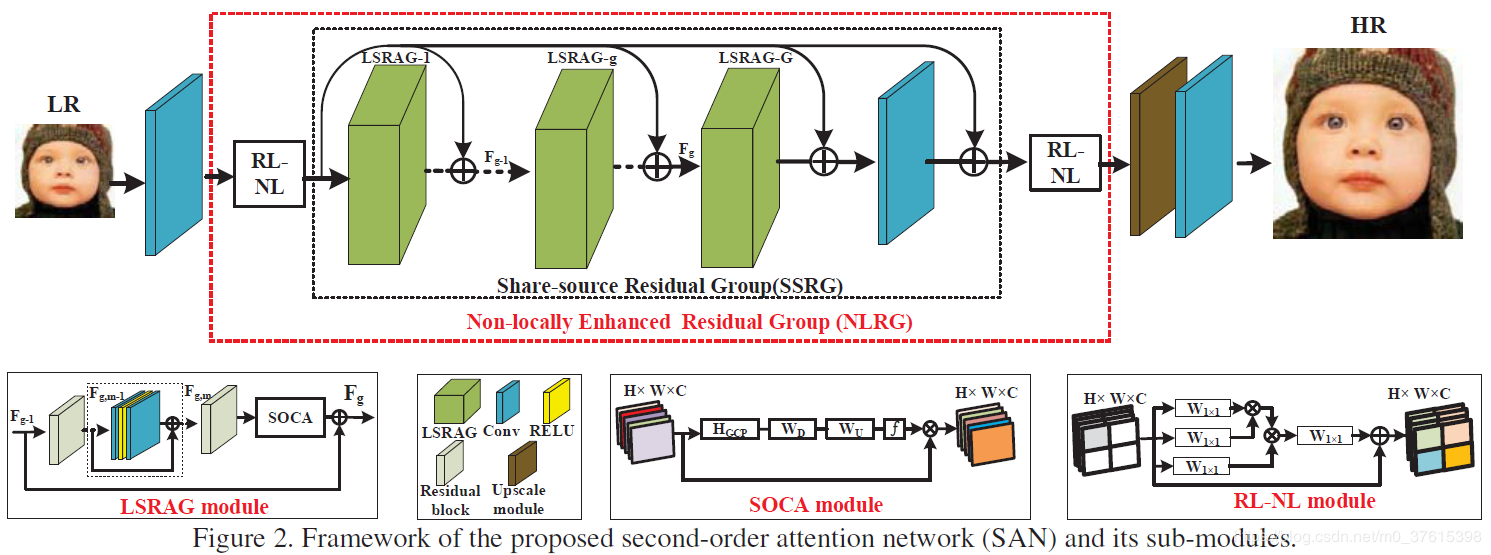
$l_1$ loss; - 总体包括四个部分:浅层特征提取(一个卷基层)、基于非局部增强残差组的深度特征提取(LSRAG)、上采样模块、重建模块;
- RL-NL模块:1)如果特征size很大,所需计算量很大;2)对于low-level的任务来讲,在一定的区域范围内进行non-local操作被证明是有效的。在SAN中,将图像划分为
$k\times k$ (代码中为$2\times2$ ),然后在每个region中进行non-local操作; - SOCA(采用二阶通道注意力机制,使用的是协方差),一阶通道使用的是一阶统计信息(通过全局平均池化);
-
预测结果:
1)Set5
$\times4$ :PSNR为32.635;2)平均每张耗时1.98s;
3)模型size:60.7M;
3)预测结果图参见image/san;
-
贡献点:
1)利用二阶统计信息,提出一个利用attention的新思路;
2)non-local操作非作用于整个图像,而是作用在一个合适的领域内
- 训练数据:DIV2K,未get_patch前,对高分图像取[原图,0.8, 0.7, 0.6, 0.5] (resize)及对应的旋转180度和未旋转的作为高分图像,数据量扩充10倍,再获取相应的
$\times4$ bicubic图像作为LR图像; - 训练时,HR图像通过随机切出
$128\times128$ 做高分,对应的在LR图像中取$32\times32$ 做LR图像; - 数据增强:随机水平镜像、随机垂直镜像、随机旋转90度;
- 网络结构:
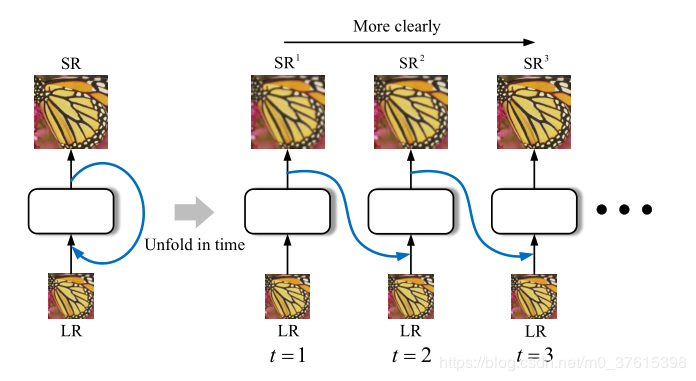
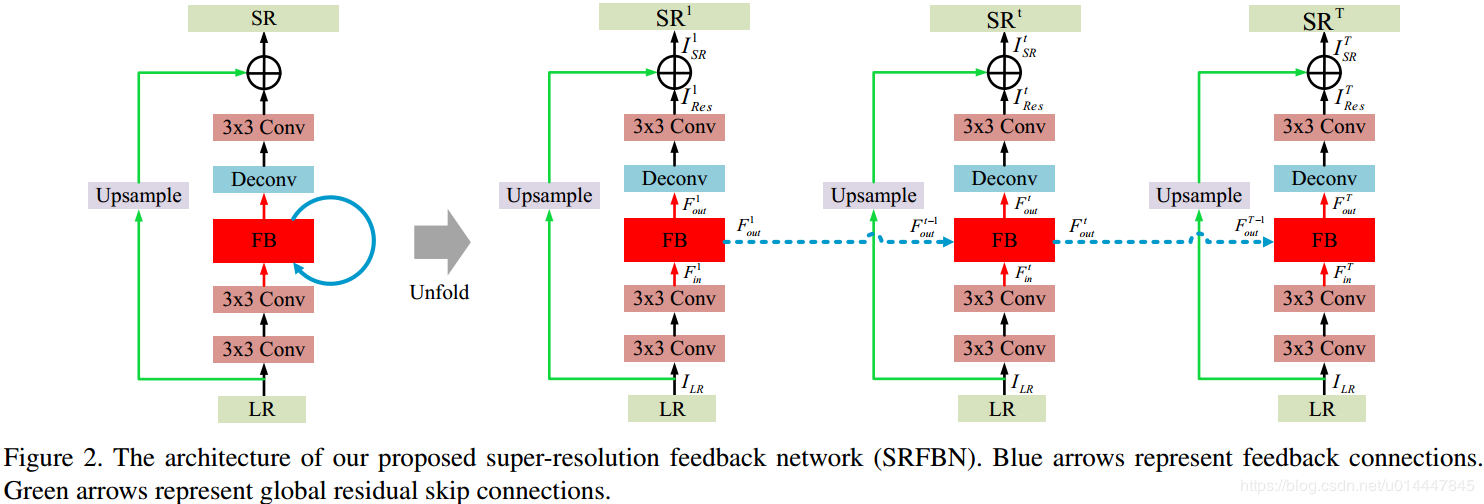
-
回传的好处就在于,不会增加额外的参数,并且多次回传相当于加深了网络,不断地refine生成的SR图像;
-
每个生成的
$SR^t=BI(LR) +I_{res}^{t}$ ; -
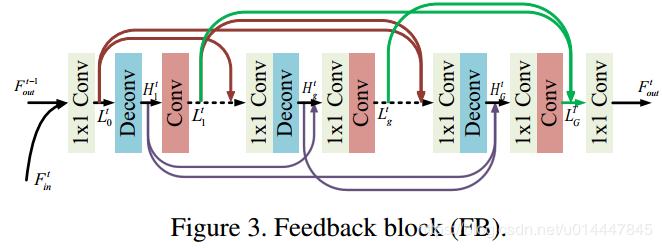
FB为反馈机制模块,其具体结构为
- 每个生成的SR与HR求
$L_1$ 损失,总loss为所有loss的加权和,代码中每个loss权重都为1; - RGB三个通道重建;
-
预测结果:
1)Set5
$\times4$ :PSNR:32.47; SSIM:0.8983;2)平均一张图像运行时间58.425ms;
3)模型size:13.9M;
4)预测结果图参见image/srfbn
-
贡献点:
1)设计Feedback block,利用多次回传机制来提高分辨率的效果,并未引入过多的参数
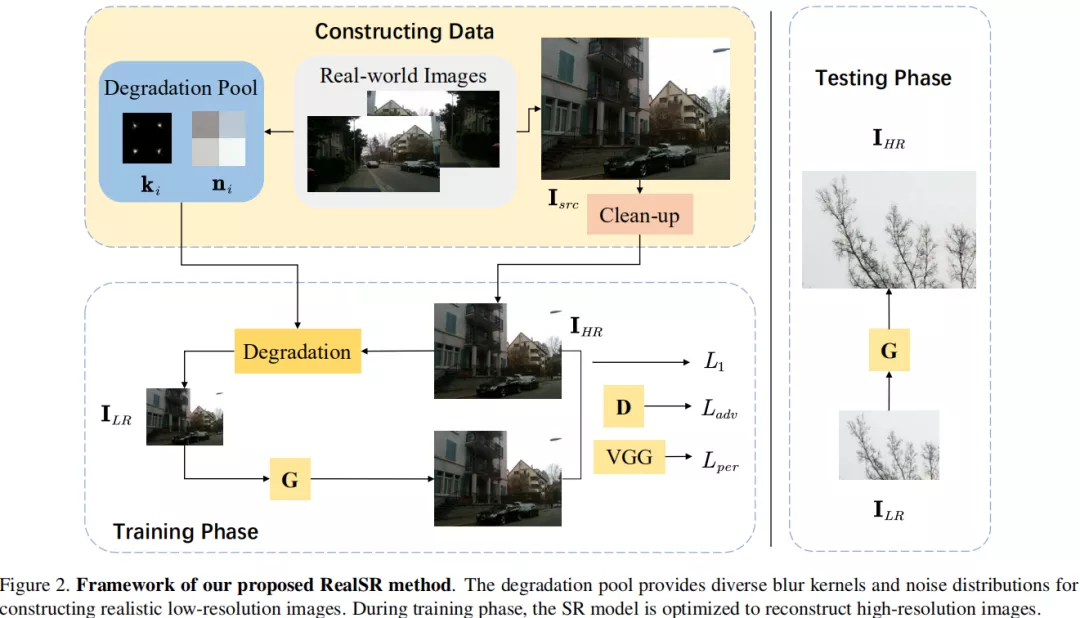
- 训练数据:DF2K(DIV2K+Flickr2K, 人为加入高斯噪声), DPED(iphone3相机拍摄的5614张图像)
- 网络结构:
-
适用于超分的真实降质过程:$
$I_{LR} = (I_{HR}*k)\downarrow+n$ $ ,$k,n$ 分别表示模糊核和噪声; -
计算模糊核,参考KernelGAN,满足的约束条件为:
$arg min||(I_{src}*k)\downarrow _s-I_{src}\downarrow _s||_1+|1-\sum k_{i,j}|+|\sum k_{i,j} \cdot m_{i,j}|+|1-D((I_{src}*k)\downarrow _s)| (4)$ $(I_{src}*k)\downarrow _s$ 表示利用核$k$进行降采样的LR图像,$I_{src}\downarrow _s$ 表示基于理想核进行降采样的LR图像;第二项表示正则化项,第三项为边界惩罚项; -
提取噪声:如果某个块的方差小于设定的阈值,则将其纳入到降质池中,这个规则可以描述为
$\sigma(n_i) \lt v (7)$ ; -
RealSR降质算法:

-
预测结果:
1)DF2K平均一张耗时0.740s, dped平均一张耗时0.579s;
2)模型size:63.8M;
3)预测图像参见image/realsr(远处人脸效果不好);
-
贡献点:
1)提出新的数据制作方案:统计模糊核与真实噪声分布并用于制作训练数据对,确保生成的LR图像具有与源域图像相似的属性;
2)判别器采用块判别器,可以去除伪影
- 训练数据:DIV8K(1500HR图像, 1400做训练, 100做测试),bicubic下采样
$\times16$ 作为LR图像 - 网络结构(基于ESRGAN):
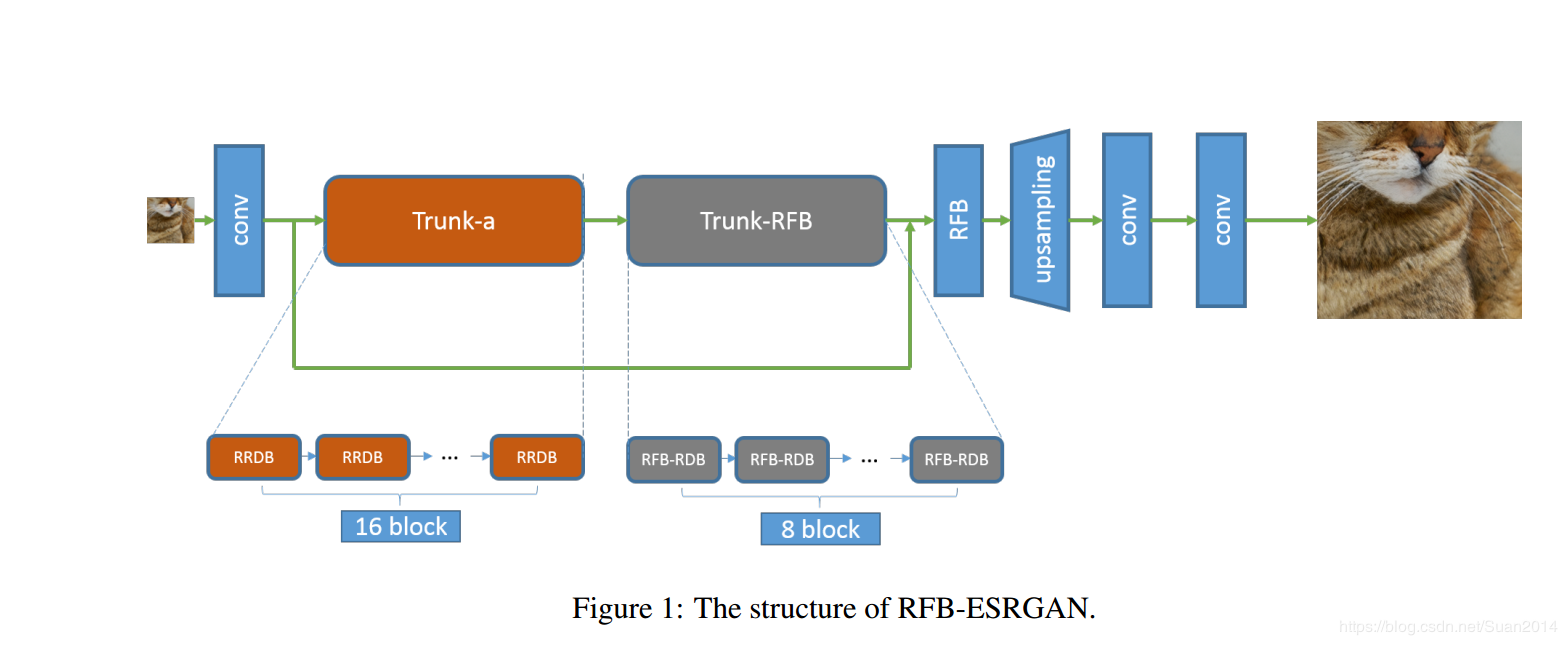
-
RRDB模块
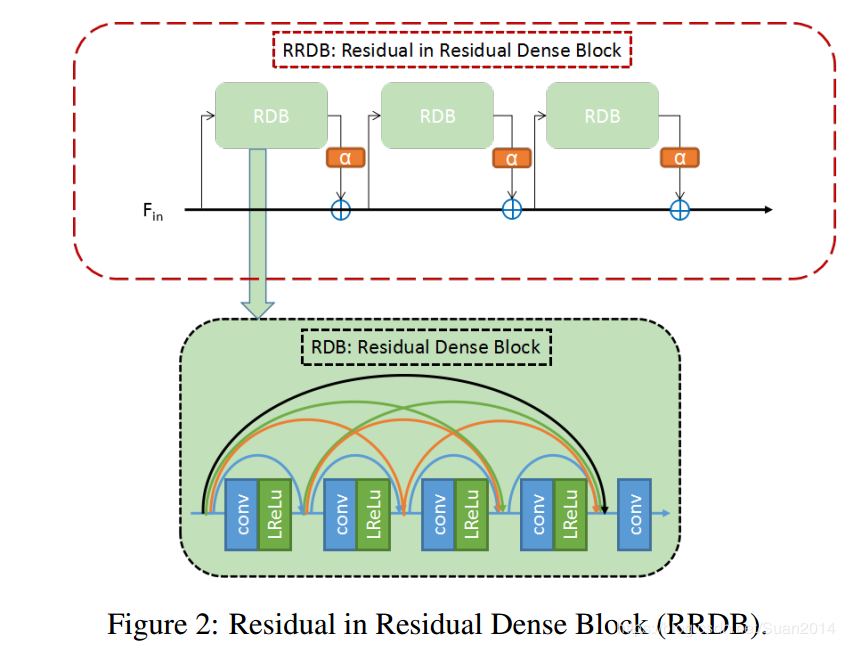
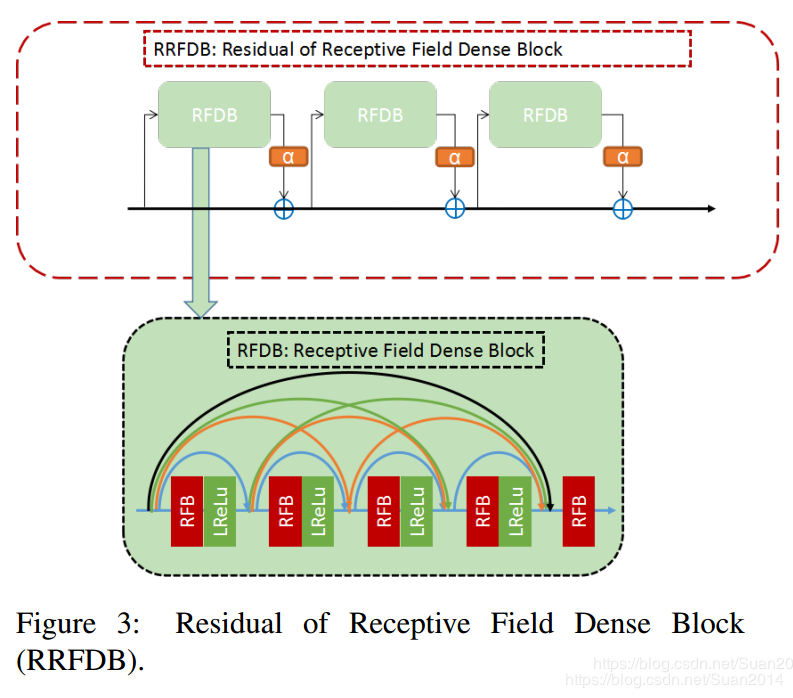
-
RRFDB模块
-
RFB模块
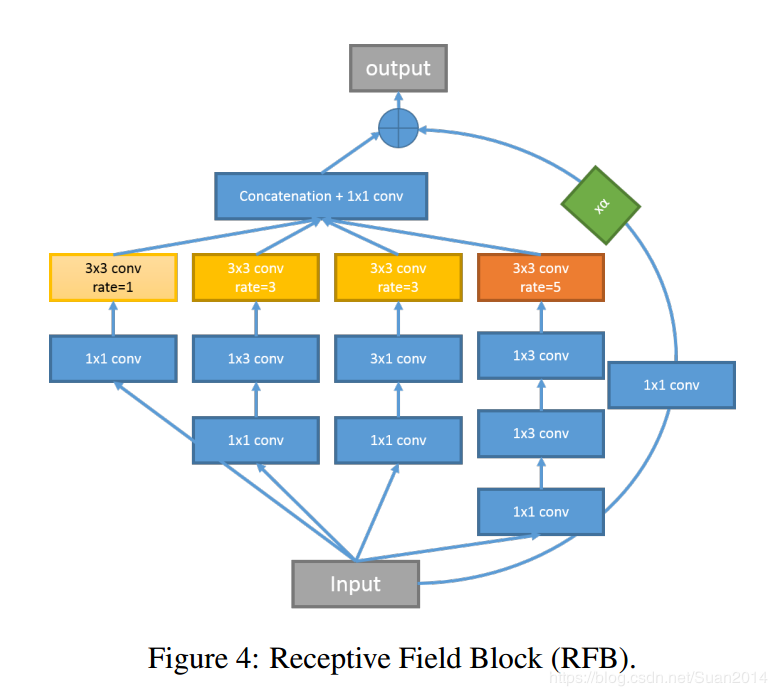
关注不同层次的细节,且减少运算量和参数量;
-
上采样模块
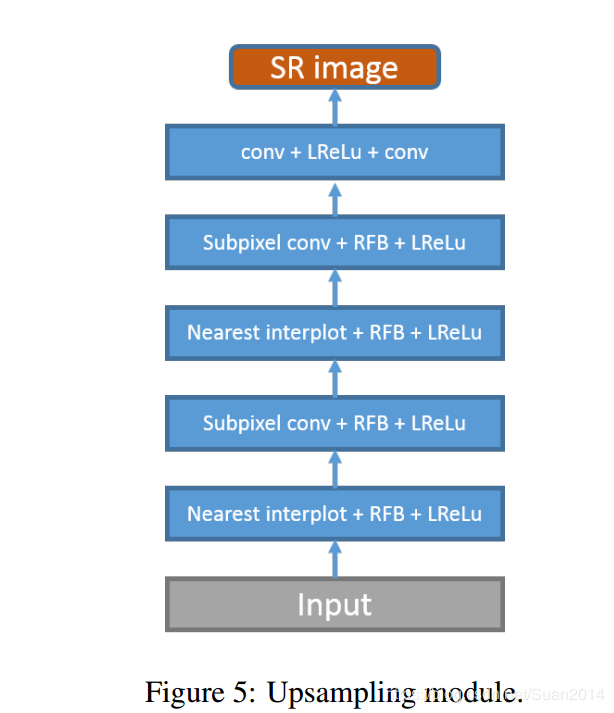
最近邻插值上采样关注空间的特征转换,亚像素层关注depth-to-space转换,两者交替结合效果更好;
-
训练时,先PSNR-oriented训练,将其作为预训练模型,然后添加内容损失和对抗损失进行微调;
-
最终采用网络插值,取在测试集上最好的十个模型进行集成
-
贡献点:
1)为提取多尺度信息并增强特征判别性,采用感受野模块进行超分;
2)不同于多尺度感受野模块中的大卷积核,在感受野模块中采用多个小尺度卷积,这有助于提取细节特征并降低计算复杂度;
3)在上采样阶段交替使用不同的上采样方法以降低计算复杂度,同时具有令人满意的性能;
4)采用10个不同迭代的模型集成以提升模型的鲁棒性并降低单个模型引入的噪声。
-
损失函数:
- 损失函数的设计直接决定网络的学习方向,因此对于模型的最终表现有着举足轻重的作用;
- 目前SR领域的损失函数主要有像素级$l_1$损失、像素级$l_2$损失、感知损失、纹理损失等,每种损失函数使得生成图像的偏重不同,像素级损失函数能够使得图像在像素级别更相似与HR图像,且PSNR指标与像素级损失相关性很强,因此基于像素级损失函数生成的图像具有较高的PSNR值,对于NTIRE此类的比赛具有较好的表现;基于像素级损失函数生成的图像一般视觉感知不佳,因此,当追求视觉感受时,一般采用感知损失函数(基于预训练的分类模型(如VGG-16等)提取SR和HR的特征,计算两个特征向量间的$l_1$或$l_2$损失);基于纹理训练的模型生成的SR图像纹理细节更加逼真;
- 目前算法多同时采用多种损失函数,但是每种损失函数的比重设定需要大量的经验;
- 一张图像中不同图像区域(或像素)的重建难度是不一样的,目前的所有算法对每个像素重建损失设定是一样的,如果使网络更加关注难以重建的区域,重建效果可能更好。
基于上述分析,可能的研究方向如下:
-
提出关注图像某一特性的损失函数;
-
自动学习多种损失函数的权重,使得多种损失函数的结合更有效,生成SR图像的效果更好;
-
根据重建的难易程度,对LR图像的不同区域(或像素)自动分配权重,根据分配权重的位置,可以分为三个方向进行研究:
1)在网络末端分配权重:设计损失函数可以自动根据某项指标(如像素级损失的大小)对难例分配更多权重;
2)在网络前端分配权重:在重建网络之前,对LR图像划分不同的区域,定义每个区域重建的难易程度,对重建难度大的区域计算损失函数时分配更多的权重;
3)在网络中分配权重:在网络中根据提取的特征自动学习每个区域(或每个像素)重建的难易程度,在损失函数计算时,对重建难度大的区域分配更大的权重系数;
-
训练策略:
- 在目标检测、人脸识别等领域,主干网络通常采用在ImageNet上训练的模型初始化参数,这样既可以降低网络的学习难度,又可以将网络从其他领域学习到的知识迁移过来,使得网络表现更优;
- 在网络训练中通常采用adam、SGD等算法优化网络参数,但并不能保证得到参数是最优的;
基于上述分析,可能的研究方向如下:
- 在SR中采用预训练模型:1)如果是上采样倍数比较大的网络,可以先训练低倍放大,然后以此为预训练模型进行微调,逐步增大放大倍数,这样做的思想类似于课程学习(先学习容易的,再逐步增加难度);2)如果得到的SR图像是要应用于某一领域的,可以采用该领域的模型作为预训练模型,相当于采用先验知识;
- 有效地调参:1)在训练较长一段时间后,每次的参数取所有轮参数的均值,可以优化网络效果(借鉴于两年前一篇论文思想),这样可以避免某次epoch偏离最优参数太多带来的影响;2)研究训练好的模型如何有效的进行结合,即网络插值的思想如何应用,会使得效果更好。
-
主干网络:
- 目前大多数基于深度学习的超分辨率模型都是采用普通卷积层,其他类型的卷积层是否更适合超分辨率重建需要进一步实验验证;
- 大多的SISR模型只关注生成图像的质量,而不关注运行时间,因此,重建一张图像可能需要几百毫秒甚至几秒,显然在很多实际应用中,这样的时间消耗是不能接受的;
基于上述分析,可能的研究方向如下:
- 普通的卷积层感受野是规则的
$k\times k$ (其中$k$ 为卷积核尺寸)区域,其几何变换建模能力本质上是有限的,在SR中,每个像素点关联性最强的像素区域并非是规则的,因此,采用可变形卷积自动学习最优的感受野区域可能能获取更好的重建效果;在普通卷积层中,较大的卷积核可以增大感受野,使网络取得更优的性能,但是更大的卷积核通常会导致较多的时间消耗,因此可以采用空洞卷积代替可普通卷积,在相同的计算量下,获取更大的感受野; - 关注轻量级且效果优的网络模型,既能获取较好的重建性能,又能降低时间消耗,这是超分辨率建模的终极目标;
-
注意力机制:
- 不同类型的注意力机制在图像领域及NLP领域都展现了强大的性能;
- 目前基于注意力类型的研究也比较多,不同类型的注意力机制关注重点不一样;
- SR领域重建的过程确实需要对不同像素点或不同的通道分配不同的权重,关注高频信息,忽略已经存在的低频信息;
基于上述分析,可能的研究方向如下:
- 将不同类型的注意力机制运用于SR领域,使得模型关注不同的像素或通道;
- 不同注意力机制的融合能使模型在不同层次关注不同的信息,也许能够使得网络更加有效;
-
正则化层:
- BN层在SR领域效果较差;
- 目前在SR领域还未发现有效的正则化方法;
- 合适的正则化方法可以降低网络的训练难度,使网络表现更优;
基于上述分析,可能的研究方向如下:
- 计算机视觉中正则化层有:BN、LN、IN、GN,这些正则化方法关注不同的正则化区域,BN层被证明不适用于SR领域,其他的正则化方法在SR领域是否有效有待进一步实验;除此之外,提出一种新的适用于SR领域的正则化方法也是值得研究的方向;
-
real-world SR:
- 目前大多数网络训练数据中的LR图像是通过bicubic算法获取的,此时训练的网络其实是bicubic算法的逆过程,学习到的网络在real-world图像中上的表现并不理想;
- 目前对real-world图像超分的研究比较少;
- real-world SR在真实的应用场景中很重要;
基于上述分析,可能的研究方向如下:
- real-world图像超分会受到越来越多的关注,real-world SR研究的重点是构建训练数据集(即LR-HR图像对),现实中获取相应的LR-HR图像对是极其困难的,如何利用获取的real-world HR图像构建real-world LR-HR图像对是极为重要的研究方向;
-
数据增强:
- 在深度学习中,决定模型性能上限的是训练数据,因此,获取能够反应真实分布的训练数据极其重要;
- 在很多领域中,获取的训练数据是有限的,通常多采用某些数据增强手段,增大训练数据量,丰富训练数据类型,使训练数据尽可能地接近真实分布,从而提高网络模型的性能,使得网络模型预测精度更高;
- 目前在SR领域,数据增强多采用水平和垂直镜像、随机裁剪、旋转等传统的数据增强手段;
基于上述分析,可能的研究方向如下:
- 针对SR领域,是否具有其他的数据增强方法,丰富训练数据集,提升网络模型的的性能,是一个值得研究的方向。
| 版本 | 日期 | 书写人 | 修改内容 |
|---|---|---|---|
| v1.0 | 2020年6月19日 | 张月 | 初稿 |
| v1.0 | 2020年6月22日 | 张月 | 修改研究方向 |