distill_at
[[TOC]]
https://blog.csdn.net/qiu931110/article/details/105904211
https://www.yuque.com/lart/gw5mta/uk5843
知识蒸馏的模型压缩方法是在teacher-student框架中,将复杂、学习能力强的网络学到的特征表示“知识蒸馏”出来(将大模型学习出来的知识作为先验),传递给参数量小、学习能力弱的网络。从而得到一个速度快,能力强的网络。
由于蒸馏中软化标签的本质,因此蒸馏也可以被认为是一种正则化的策略。
Hinton提出知识蒸馏基于这样一个观察:一个训练好的模型在测试时,给出的预测结果并不是one-hot形式(某一类为1,其余类全0)的,对于某一张测试图像,即使模型分类正确,在错误的类别上模型仍然会给出一些值较小但非零的概率。
Hinton认为这些小而非零的值包含类与类之间的相似度关系,例如输入一张狗的图像,模型可能在狗的类别上给出0.7的概率,而在猫和狼的类别上给出0.1的概率,这种类间关系是模型在训练过程中基于数据集自动学会的,能够提供比人工标注的one-hot标签更丰富的信息,用一个训好的大模型的输出来监督另一个小模型,其结果比只用人工标签更好。
来自teacher的输出被形象化为知识(knowledge),而从teacher模型提取知识并转移至student,与化学中从混合物中蒸馏出某纯净物的过程相似,所以用teacher监督student的方法,被称作蒸馏(distillation)。
通常可归纳为:学生网络学习教师网络的什么?怎样去学习?
-
学习教师网络的输出
- 学习教师网络的输出作为soft_target
- 结构上,如:多个学生网络交替学习输出。
-
学习教师网络的特征或特征相关关系
- 直接学习教师网络的输出特征:FitNet
- 学习特征时使用的学习方法:学习注意力, 互信息, 特征相似性,有选择的选取特征。
- other

https://arxiv.org/pdf/1503.02531.pdf
使用soft target.让小模型在拟合训练数据的ground truth的同时,也要拟合大模型输出的概率分布。
直接让学生网络模仿教师网络的输出比较困难, 提出hint training 让学生网络的中间层的输出也尽可能的接近。学生网络的guided layer,直接学习对应的教师网络的hint layer特征,然后使用了softtarget 进行训练。


-
使guided layer的输出尽可能的能预测hint layer的输出。
-
教师网络通常比FItnet 宽,hint layer层输出值可能更多, 在guided layer后加回归器使其输出与hint layer的匹配。
训练步骤:
1.教师网络直接训练好,随机初始化整个学生网络,学生网络guied layer末尾跟着一个回归器,并初始化参数。
2.根据公式3,先训练学生网络guied layer的权重Wguided,最小化这个loss。
3.然后根据公式2,根据预训练好的参数,再训练整个学生网络的Ws

ICLR2017 | Paying More Attention to Attention
https://github.com/szagoruyko/attention-transfer
通过得到单通道融合的注意力图, 使用来配准各个阶段的特征。
该论文的问题:
旨在模拟学生和老师模型之间的注意力图,这基于假设:特征图沿通道维度的加和在图像分类任务中可能表示注意力分布 然而,这种假设可能不适合像素级的分割任务,因为不同的通道表示不同类的激活,简单地对通道进行求和就会得到混淆了的注意力图
-
提出从一个网络传递到另一个网络的空间注意力
-
两种空间注意力map: 基于激活的,基于梯度的
-
两种注意力方法在不同框架和数据集下的变化,对卷积网络表现的提升。
-
基于激活的注意力转移比完全激活转移具有更好的改进,并且可以与知识蒸馏结合使用
注意力在许多任务上的有效性。
可视化注意力的问题。
知识蒸馏的问题。
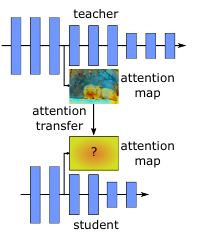
空间注意力map的卷积网络的定义;
怎样从teacher网络将注意力信息迁移到Student网络;
为了定义空间注意力映射函数,使用了隐含假设,隐藏神经元激活的绝对值(当对给定输入进行网络评估时得出的结果)可以用作该神经元重要性的指示。
空间注意力的激活函数:三种,通道绝对值求和,求幂的和,求幂的最大
绝对值求和如下:
隐藏激活数据不仅具有图像层面的空间相关性, 而且能够提高网络性能。在网络不同的层注意力图会关注图像的不同部分。
求和的方法。 高度激活作用的多个神经元的空间位置
将损失放在教师和学生注意力map间, 使用相同的空间分辨率。
注意力特征图的正则化对学生网络的训练很重要。
loss 由交叉熵和 T-S特征激活图间的区别相关的loss组成。
有无激活注意力影响很大, 同时使用注意力和蒸馏效果更好。
对于基于梯度的注意,由于需要复杂的自动微分,将实验限制在没有批量正则化和CIFAR数据集的网络中。
允许学生网络和教师网络在不同的深度层学习,但是要在相同的块的末尾。
两者输出的维度可以不一致,A_T 为bchw, A_S为bc'h'w', 每次批量输入的样本数目需一致。
将教师模型网络层与层之间的映射关系作为学生网络学习的目标,而不是像之前提到的直接对教师模型的中间结果进行学习。通过让学生学习这种获得特征的方法,而不是直接学习特征本身.
不拟合大模型的输出,而是去拟合大模型层与层之间的关系,这才是我要转移和蒸馏的知识! 通过学习教师网络相邻阶段特征各个通道之间的关系。
这个关系是用层与层之间的内积来定义的:假如说甲层有 M 个输出通道,乙层有 N 个输出通道,就构建一个 M*N 的矩阵来表示这两层间的关系,其中 (i, j) 元是甲层第 i 个通道 和 乙层第 j 个通道的内积(因此此方法需要甲乙两层 feature map 的形状相同)。
文中把这个矩阵叫 FSP (flow of solution procedure) 矩阵,其实这也是一种 Gram 矩阵,之前一篇很有名的文章 Neural Style 里也有成功的应用:用 Gram 矩阵来描述图像纹理,从而实现风格转换。
基于对老师模型的结果的”信任”程度来附加蒸馏损失的方案。这通过计算教师模型的预测与真值之间的差异作为其在监督中重要性的依据。
使用蒸馏网络的论文项目:
https://github.com/dkozlov/awesome-knowledge-distillation
注意力机制就是定位感兴趣信息,抑制无用信息,结果通常以概率图或者概率特征向量的形式展示。对感兴趣的区域定位并进行一些变换或者获取权重。
常见的通道注意力机制
空间注意力,通道注意力, 残差注意力机制,多尺度注意力机制,递归注意力机制
STN,Spatial Transformer Networks
完成目标定位和仿射变换调整。通过学习输入的形变,从而完成适合任务的预处理操作,是一种基于空间的Attention模型。输入是C×H×W维的图像,输出是一个空间变换系数,它的大小根据要学习的变换类型而定,如果是仿射变换,则是一个6维向量。
Dynamic Capacity Networks
低性能的子网络(coarse model)用于对全图进行处理,定位感兴趣区域,如下图中的操作fc。高性能的子网络(fine model)则对感兴趣区域进行精细化处理
通过注意力机制学习每个特征通道的的权重,基于特定任务,学习到不同通道的重要性。
SEnet 2017 加入通道注意力机制
SKnet 也使用通道加权结合inception的多分支网络实现了性能提升。
提出轻量通用的模块CBAM。
使用注意力提升特征表达通过:强调重要特征,抑制不重要信息。
按序使用通道和空间注意力模块, so that each of the branches can learn ‘what’ and ‘where’ to attend in the channel and spatial axes 。
从三个方面:深度,宽度,基础元素
inception, ResNet ,WideResNet ,Inception-ResNet , ResNeXt ,PyramidNet ,DenseNet.
注意力在任务上的表现好;
提出的一些注意力模块如:残差注意力网络
提出的通道注意力方法。
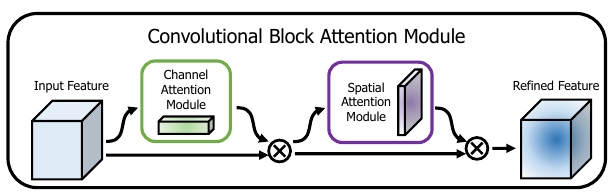
特征图F先经过 通道AT模块 得到M_c , 元素后得到M_c . F = F1 (element-wise multiplication)
F1经过 空间AT模块 得到M_s, 叉乘后得到M_s . F1 = F2
为了计算通道注意力, 将输入特征的空间维度进行了压缩。
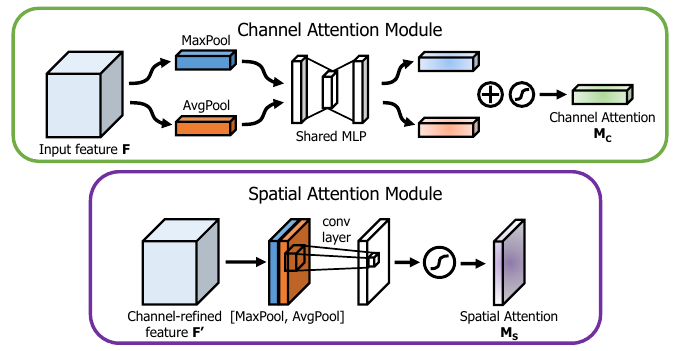
分别经过平均池化和最大池化,经过共享网络MLP(包含一个隐藏层)后相加,得到通道注意力特征图,合并,最后经过一个sigmoid激活函数。
沿着通道方向使用平均池化和最大池化(沿通道的池化操作能够强调区域信息), 然后concatenate。使用一个卷积层去生成空间注意力特征描述子。然后使用一个7*7卷积层和sigmoid函数去生成空间注意力特征图。
残差注意力机制
-
提出一种可堆叠的Residual Attention Module模块,可以通过模块的堆叠使得网络达到比较深的层次。
-
提出一种基于Attention 的残差学习方式,因为直接进行Attention Module的堆叠使得性能下降。
-
一种Bottom-up top-down的前向传播机制,即先降采样再上采样。
在普通的ResNet网络中,增加侧分支,侧分支通过一系列的卷积和池化操作,逐渐提取高层特征并增大模型的感受野,前面已经说过高层特征的激活对应位置能够反映attention的区域,然后再对这种具有attention特征的feature map进行上采样,使其大小回到原始feature map的大小,就将attention对应到原始图片的每一个位置上,这个feature map叫做 attention map,与原来的feature map 进行element-wise product的操作,相当于一个权重器,增强有意义的特征,抑制无意义的信息。# 注意力机制
注意力机制就是定位感兴趣信息,抑制无用信息,结果通常以概率图或者概率特征向量的形式展示。对感兴趣的区域定位并进行一些变换或者获取权重。
常见的通道注意力机制
空间注意力,通道注意力, 残差注意力机制,多尺度注意力机制,递归注意力机制
STN,Spatial Transformer Networks
完成目标定位和仿射变换调整。通过学习输入的形变,从而完成适合任务的预处理操作,是一种基于空间的Attention模型。输入是C×H×W维的图像,输出是一个空间变换系数,它的大小根据要学习的变换类型而定,如果是仿射变换,则是一个6维向量。
Dynamic Capacity Networks
低性能的子网络(coarse model)用于对全图进行处理,定位感兴趣区域,如下图中的操作fc。高性能的子网络(fine model)则对感兴趣区域进行精细化处理
通过注意力机制学习每个特征通道的的权重,基于特定任务,学习到不同通道的重要性。
SEnet 2017 加入通道注意力机制
SKnet 也使用通道加权结合inception的多分支网络实现了性能提升。
提出轻量通用的模块CBAM。
使用注意力提升特征表达通过:强调重要特征,抑制不重要信息。
按序使用通道和空间注意力模块, so that each of the branches can learn ‘what’ and ‘where’ to attend in the channel and spatial axes 。
从三个方面:深度,宽度,基础元素
inception, ResNet ,WideResNet ,Inception-ResNet , ResNeXt ,PyramidNet ,DenseNet.
注意力在任务上的表现好;
提出的一些注意力模块如:残差注意力网络
提出的通道注意力方法。
特征图F先经过 通道AT模块 得到M_c , 元素后得到M_c . F = F1 (element-wise multiplication)
F1经过 空间AT模块 得到M_s, 叉乘后得到M_s . F1 = F2
为了计算通道注意力, 将输入特征的空间维度进行了压缩。 [[TOC]]
分别经过平均池化和最大池化,经过共享网络MLP(包含一个隐藏层)后相加,得到通道注意力特征图,合并,最后经过一个sigmoid激活函数。
沿着通道方向使用平均池化和最大池化(沿通道的池化操作能够强调区域信息), 然后concatenate。使用一个卷积层去生成空间注意力特征描述子。然后使用一个7*7卷积层和sigmoid函数去生成空间注意力特征图。
残差注意力机制
-
提出一种可堆叠的Residual Attention Module模块,可以通过模块的堆叠使得网络达到比较深的层次。
-
提出一种基于Attention 的残差学习方式,因为直接进行Attention Module的堆叠使得性能下降。
-
一种Bottom-up top-down的前向传播机制,即先降采样再上采样。
在普通的ResNet网络中,增加侧分支,侧分支通过一系列的卷积和池化操作,逐渐提取高层特征并增大模型的感受野,前面已经说过高层特征的激活对应位置能够反映attention的区域,然后再对这种具有attention特征的feature map进行上采样,使其大小回到原始feature map的大小,就将attention对应到原始图片的每一个位置上,这个feature map叫做 attention map,与原来的feature map 进行element-wise product的操作,相当于一个权重器,增强有意义的特征,抑制无意义的信息。