deepsort
[[TOC]]
目前主流的目标跟踪算法都是基于Tracking-by-Detecton策略,即基于目标检测的结果来进行目标跟踪,相比与之前分享的Seq-NMS和REPP后处理算法,这种检测+追踪的策略最大的优点就是能实现在线处理(Online)。DeepSORT运用的就是这个策略,deepsort借鉴了sort的思想,在此基础上添加了对外观信息的集成,提取外观信息用的行人重识别网络(ReID),这能让我们跟踪一些长时间被遮挡的目标,大大减少了识别身份的切换(id switchs)。实验显示这种改动能让id swithchs减少45%。下图是yolov5+deepsort对行人检测追踪的demo:
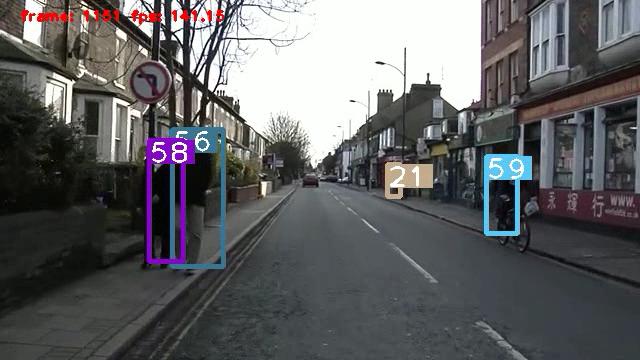
这里就有个问题,视频中不同时刻的同一个人,位置发生了变化,那么是如何关联上的呢?答案就是匈牙利算法(Hungarian Algorithm)和卡尔曼滤波(Kalman Filter)。匈牙利算法可以告诉我们当前帧的某个目标,是否与前一帧的某个目标相同,即进行目标匹配。卡尔曼滤波可以基于目标前一时刻的位置,来预测当前时刻的位置,并且可以比传感器(在目标跟踪中即目标检测器,比如Yolo等)更准确的估计目标的位置。利用匈牙利算法和卡尔曼滤波来将帧间相同目标进行关联的思想最早是出现在Sort算法里面。
匈牙利算法(又叫KM算法)就是用来解决分配问题的一种方法,它基于定理: 如果代价矩阵的某一行或某一列同时加上或减去某个数,则这个新的代价矩阵的最优分配仍然是原代价矩阵的最优分配。
有关该算法的详细流程可以参考如下链接: https://zhuanlan.zhihu.com/p/90835266
在DeepSORT中,匈牙利算法用来将前一帧中的跟踪框tracks与当前帧中的检测框detections进行关联,通过针对外观信息(appearance information)的余弦距离和马氏距离(Mahalanobis distance),或者IOU来计算代价矩阵。在Sort里面代价矩阵是通过IOU来计算的,而在DeepSort里面又添加了马氏距离和余弦距离,关于这一部分的理解可以参考:https://zhuanlan.zhihu.com/p/80764724
sklearn里的linear_assignment()函数以及scipy里的**linear_sum_assignment()**函数也都实现了匈牙利算法。
卡尔曼滤波被广泛应用于无人机、自动驾驶、卫星导航等领域,简单来说,其作用就是基于传感器的测量值来更新预测值,以达到更精确的估计。
在目标跟踪中,需要估计track的以下两个状态:
- **均值(Mean):**表示目标的位置信息,由bbox的中心坐标 (cx, cy),宽高比r,高h,以及各自的速度变化值组成,由8维向量表示为 x = [cx, cy, r, h, vx, vy, vr, vh],各个速度值初始化为0。
- **协方差(Covariance ):**表示目标位置信息的不确定性,由8x8的对角矩阵表示,矩阵中数字越大则表明不确定性越大,可以以任意值初始化。
卡尔曼滤波分为两个阶段:(1) 预测track在下一时刻的位置,(2) 基于detection来更新预测的位置。
有关两阶段所用到的公式及其含义可参考以下链接:
https://zhuanlan.zhihu.com/p/90835266
DeepSORT对每一帧的处理流程如下:
检测器得到bbox → 生成detections → 卡尔曼滤波预测→ 使用匈牙利算法将预测后的tracks和当前帧中的detecions进行匹配(级联匹配和IOU匹配) → 卡尔曼滤波更新
Frame 0:检测器检测到了N个detections,当前没有任何tracks,将这N个detections初始化为tracks
Frame 1:检测器又检测到了M个detections,对于Frame 0中的tracks,先进行预测得到新的tracks,然后使用匈牙利算法将新的tracks与detections进行匹配(开始的时候没有confirmed tracks所以暂不涉及到级联匹配),得到(track, detection)匹配对,最后用每对中的detection更新对应的track
具体流程如下图所示:
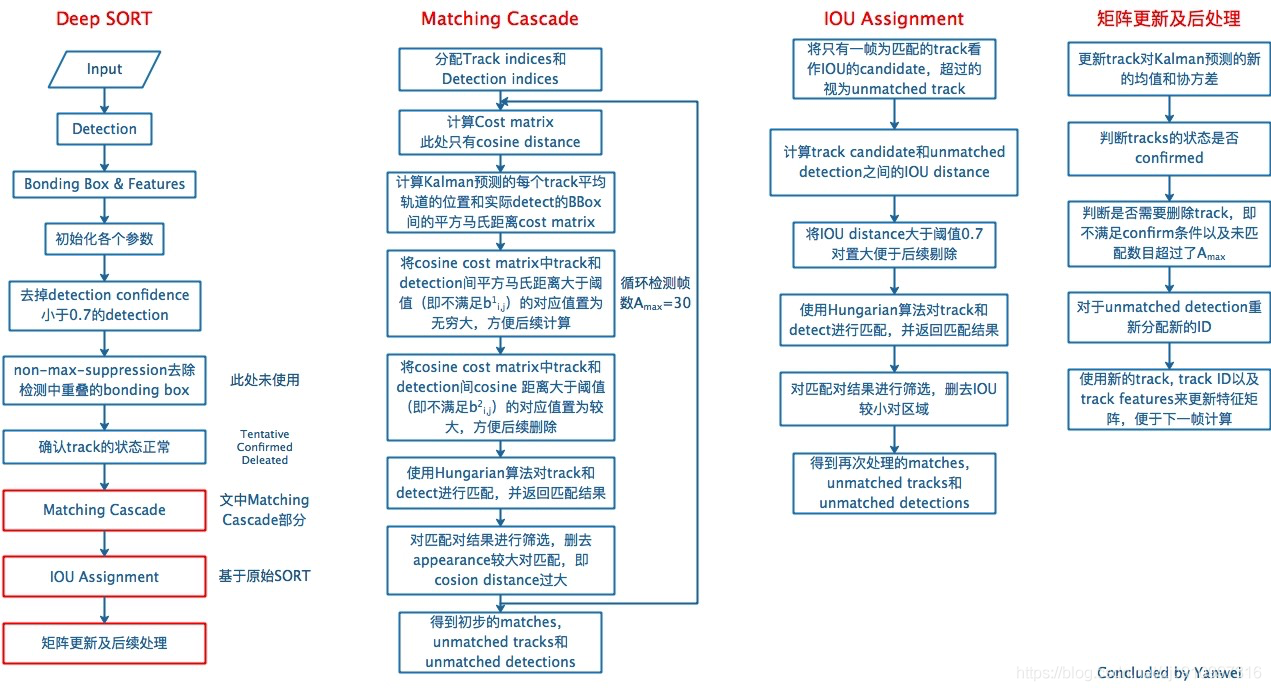
DeepSort算法的代码解读可以参考如下链接: https://blog.csdn.net/sgfmby1994/article/details/98517210
流程里面提到一个东西叫级联匹配(matching cascade),这到底是什么意思呢?在代码里面对每一一个追踪结果(track)都会计算一个叫time_since_update的参数,表示该track自最近一次更新以来的总帧数。这个值越大表示越久没更新了(也就是说前面很多帧都追踪不到该目标了),而级联匹配会从time_since_update值最小的tracks开始进行匹配(对更加频繁出现的目标赋予优先权)。个人理解使用级联匹配的目的就是增强鲁棒性,作者对于该部分的具体解释在论文2.3节中。
论文展示的实验结果如下:
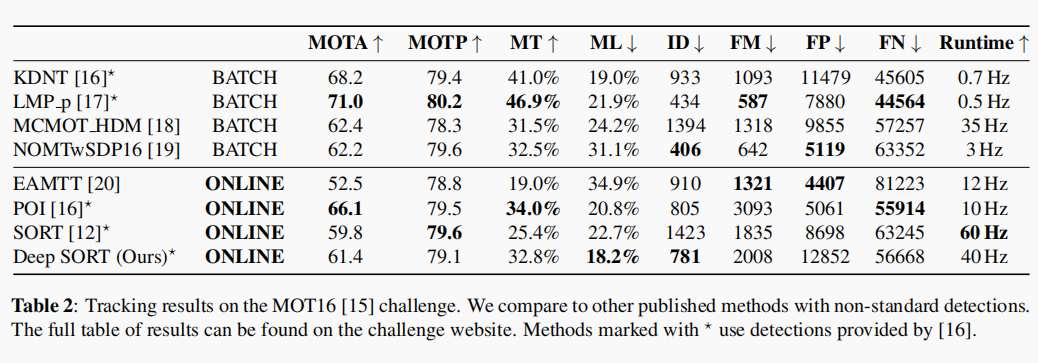

从结果中可以看到deepsort相比于sort,在id swiths上有大幅下降,整体的鲁棒性也提升了。
个人认为对于我们的视频小目标检测项目而言,用deepsort/sort这种基于追踪的后处理是要优于之前介绍的Seq-NMS/REPP,主要是因为方案可以实现在线处理。在github上与yolo+deepsort/sort相关的视频目标追踪开源项目也比较多,这种方案也是目前工业界比较常用的套路。但是目前大多的相关项目都是做的行人追踪,提取的外观特征也是针对人的。如果是要对多类目标(如何人和车)进行检测+追踪的话,单个外观特征提取模型显然是不够的,这样就意味着处理速度会大幅下降。直接放弃引入外观特征信息,即用yolo+sort的方式来做视频目标检测的话,id swiths会比较多,但如果项目需求对于同一目标的追踪(即检测框里id number)没有那么敏感的话,其实是可以尝试的。