Text_Prior_Guided_Scene_Text_Image_Super resolution_2021
paper:http://xxx.itp.ac.cn/pdf/2106.15368v2.pdf
code:https://github.com/mjq11302010044/TPGSR
核心思想:
提出使用文字识别模型对图片中的字符分类信息作为文本先验, 指导SR网络更好的恢复文字的形状纹理。
文本先验指什么?
Text Prior(TP)被定义为由文本识别模型生成的场景文本图像的深层分类表示。文中定义为 CRNN 的分类概率预测,它是一个 |A| 维概率向量的序列,其中 |A| 表示 CRNN 学习到的字符数。
文本先验的可视化结果
从左到右为字符顺序,垂直方向代表字符类别,从z-a。
白色点越亮,代表的这个字符类别的概率越大。

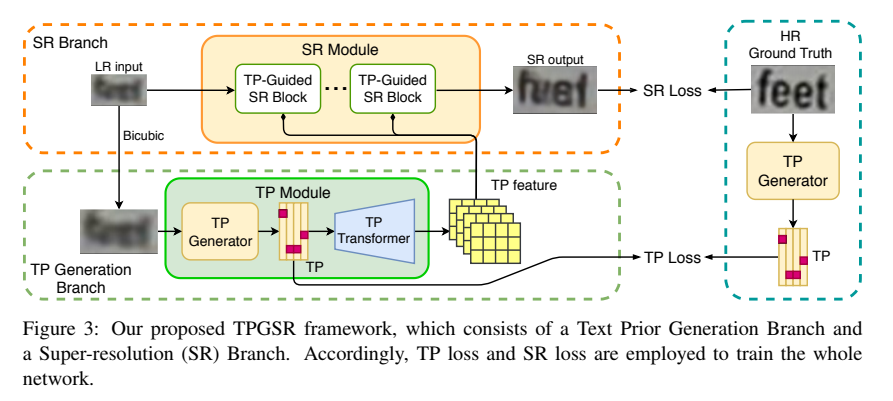
TP Module: 由 TP Generator (CRNN)和TP Transformer(4个反卷积块)组成
-
LR 先经过BIcubic 来匹配TP Generator 需要的输入。
-
生成器生成TP matrix,shape为 (L, |A|) , L为字符串长度,每个字符位置的TP都是一个|A|大小的向量, 即A 为CRNN所使用的字符表中的字符类别数。
-
TP matrix 经过TP Transformer, 恢复空间维度,通道大小为32。
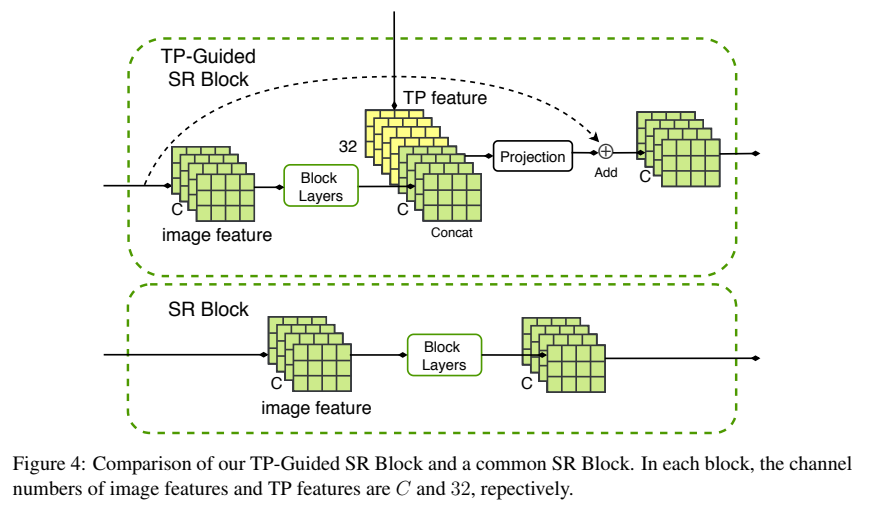
SR Module: n个 TPGuided SR block 组成
- LR 和 TP feature 输入 SR Module。
- image feature 和 TP feature 在通道维度上进行堆叠,堆叠得到C+32个通道。
- 经过一个projection layer (1*1卷积)恢复到C 通道。
- projection layer 的结果与输入的image feature 通过加法进行融合。
下图为TPGuided SR block 和普通的SR block对比。
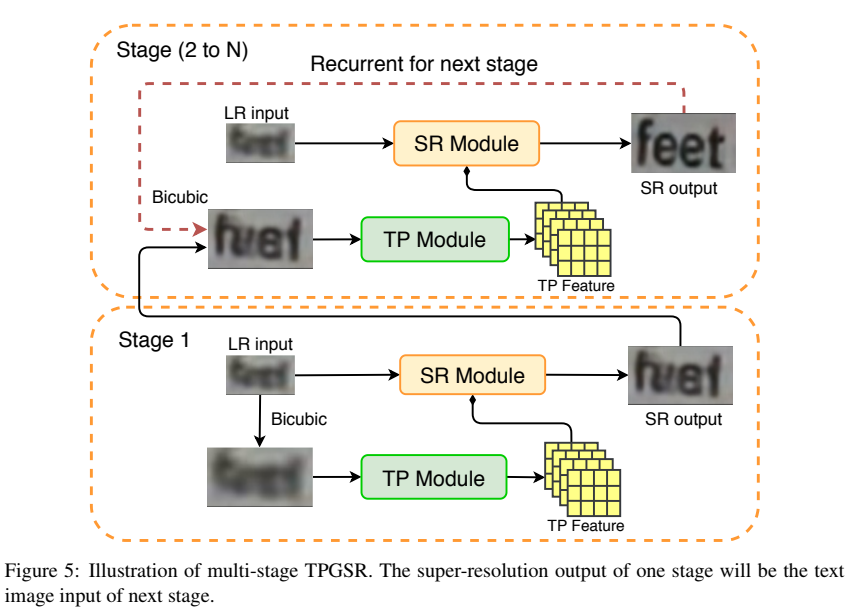
动机:上面的文本先验信息使用的LR 作为输入得到的,如果使用HR作为输入,则该TP feature 会更加准确。
步骤:
第一阶段:LR 的bicubic 结果作为TP Module 的输入
第二阶段 :第一阶段得到的SR 结果输入TP Module 得到的预测结果作为文本先验。
...:上一阶段得到的SR 输入TP Module 得到的预测结果作为文本先验。
- 重建loss
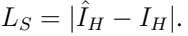
- TP loss
如果TP feature 越正确,文本先验带来的积极作用越大。期望TP feature 与 HR 作为输入得到的TP feature 尽可能的相似。使用L1 范数距离和KL 散度来衡量两个feature的相似度
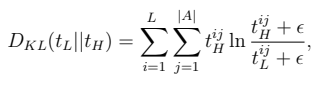
总的loss
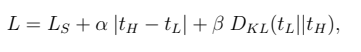
假设有N阶段的训练,总loss为
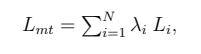
其中 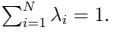
TP Generator使用的CRNN 网络。在SynthText 和MJSynth 合成数据集上进行预训练。使用的alphabet 为0-9 a-z 。先验分为|A| = 37个类别
几个loss权重为1。
SR部分各阶段权重共享,TP部分权重不共享,该设置为实验测试比较后选定的方法。
3-stage TPGSR ,$λ_1 =\frac 14$,
训练集使用:TextZoom.
测试集使用:TextZoom, ICDAR2015 , SVT中的低质图
不同模型在textzoom 验证集上的识别准确率的比较。
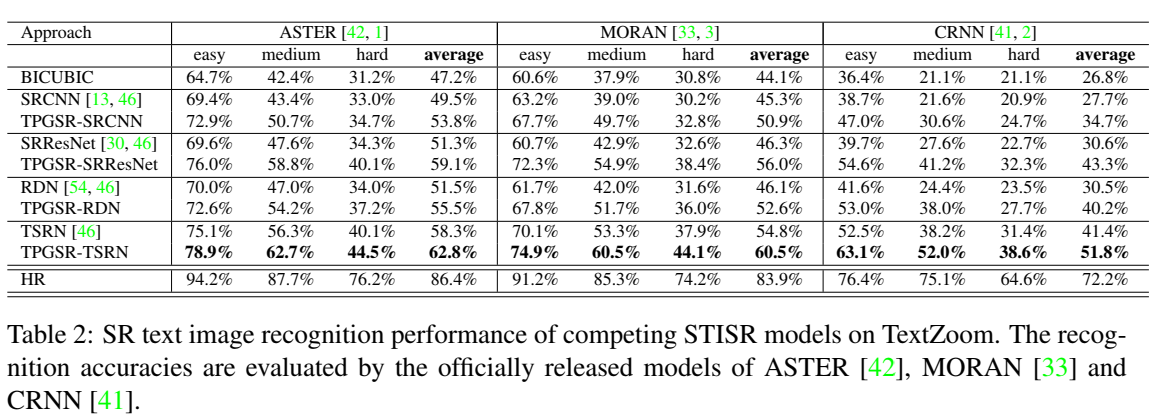
不同模型在textzoom 验证集上的图像质量的比较。
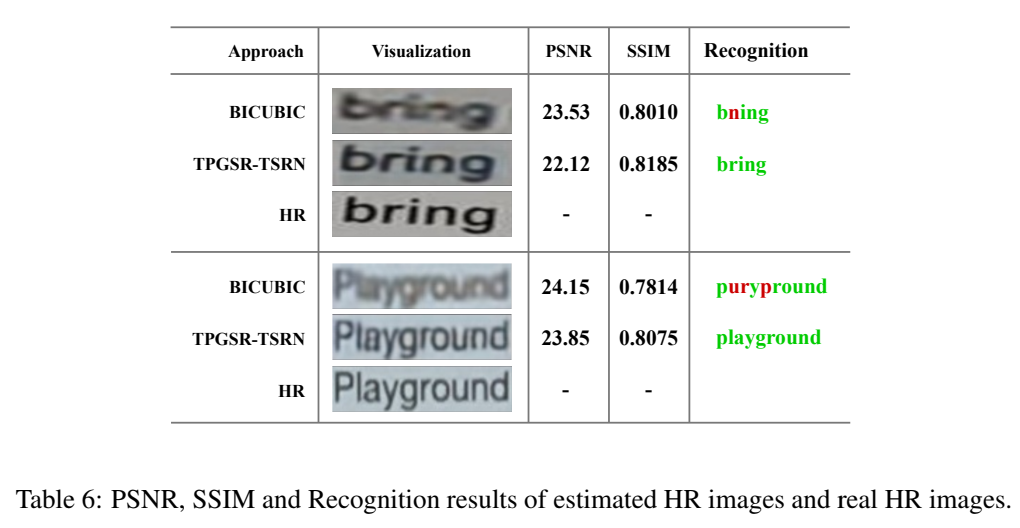
生成的图可视化效果的比较。

1.计算量和表现

引入TP先验和,堆叠多个SRB的计算量和准确率对比。认为TP先验的价值更大。
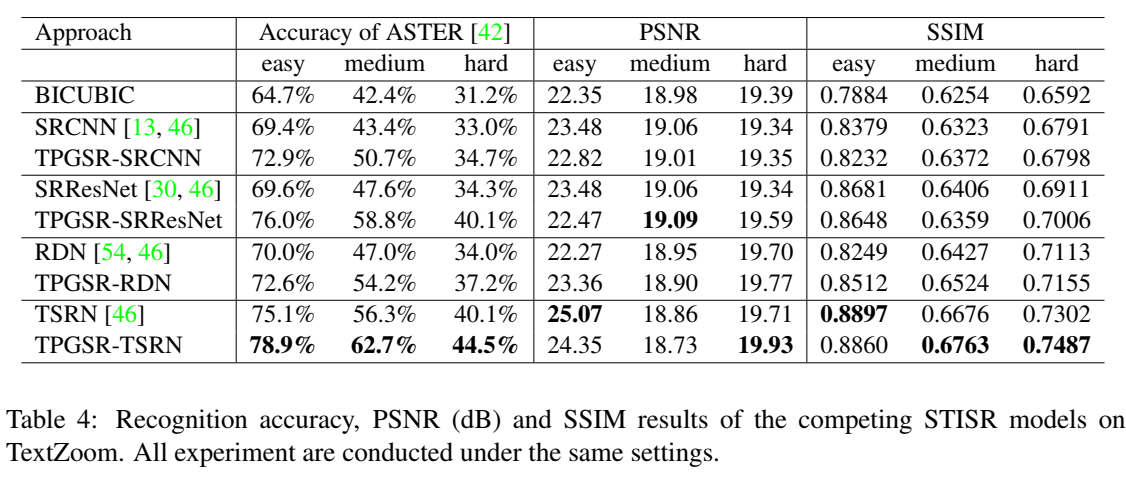
2.关于PSNR 和 SSIM分析
一些客观指标(例如 PSNR 和 SSIM)的更好结果并不总是能保证更准确的场景文本估计,反之亦然。
获得更好的感知质量和更准确的场景文本图像识别结果,比 PSNR 和 SSIM 等指标的细微上升更有价值。
3.分类外的字符
在实现中为分类外字符分配空白标签。 对于此类字符,STISR 结果将主要取决于我们 TPGSR 网络中的 SR 模块。
测试 TPGSR 模型对类别外字符的图像的 SR 性能,从 ICDAR-MLT 数据集中挑选的一些韩语、中文和孟加拉语文本图像。

模型重建的 HR 文本图像显示出比 LR 对应物更清晰的外观和轮廓。给了视觉对比图, 但是没有给出准确率。
4.失败案例分析
-
Tuned TP Generator 通常情况下路棒,但是当先验信息错误时会导致错误的识别。
-
对于旋转的文本,模型带来的好处会减弱。图像质量上的提升会不明显。
-
TP 生成器可能会因输出明显压缩而失败。 在这种情况下,TPGSR 的最终输出将因错误的文本识别而遭受文本失真

5.针对象形文字
中文的测试实验:
我们在 ICPR2018-MTWI 中英文数据集 上使用 CRNN 作为TP Generator 训练多语言识别模型。
字符表包含3965个中英文字符。
通过模糊和下采样 MTWI 文本图像来合成 LR-HR 文本图像对。
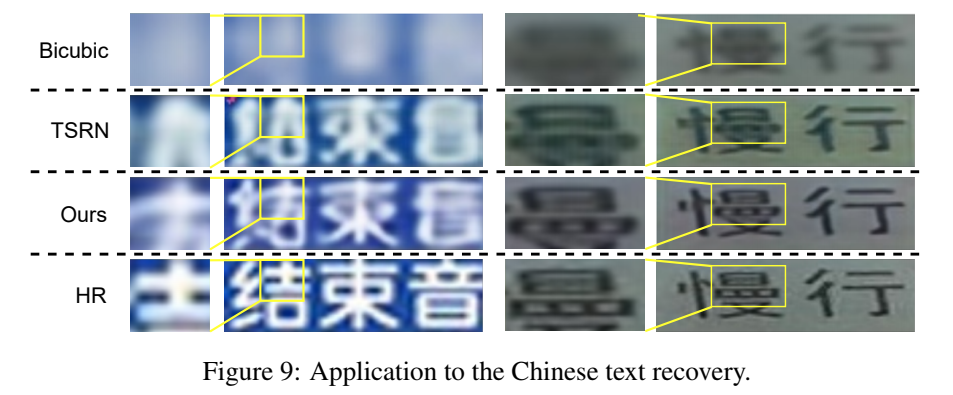
The SR text recognition results are 27.7% (Bicubic), 41.1% (TSRN [46]), 42.7% (TPGSR-TSRN) and 56.1% (HR).
TPGSR 可以更好地恢复样本上的文本笔画。 这个初步实验验证了我们的 TPGSR 框架可以扩展到象形文字