Add BRAVO Reader-Writer Lock #9394
Conversation
c904642 to
494a6c7
Compare
494a6c7 to
871d2fa
Compare
|
Perhaps compare also to #9154 . |
| std::thread list[conf.nthreads]; | ||
|
|
||
| for (int i = 0; i < conf.nthreads; i++) { | ||
| new (&list[i]) std::thread{[](T &mutex) { |
There was a problem hiding this comment.
Why not just:
list[i] = std::thread{...
? std::thread isn't copyable, but it's moveable. What you're doing assumes that ~std::thread() is vacuous when the thread is constructed with the default constructor. That's probably true in this case, but it's better practice to not make such assumptions unless it's really necessary.
There was a problem hiding this comment.
It seems like the only advantage of using a lambda here is that you avoid having to pick a name for the thread function. I think it would be more readable just using a conventional, named function for the thread function.
On the other hand, @SolidWallOfCode smiles and sighs with contentment whenever anyone uses a lambda, so there is that.
|
With my ts::scalable_shared_mutex, with 16 threads, it had worse performance that ts::shared_mutex. So maybe check the performance of this mutex with 16 threads? |
|
ts::scalable_shared_mutex uses the class DenseThreadId ( https://github.com/apache/trafficserver/pull/9154/files#diff-5d4184d5004b8c73554cb88f0bfe7f0c4711c7394c5a15e24daaaff8962d1076R177 ). It provides a thread ID for currently running threads, that's in the range from 0 to one less than the number of currently-running threads. A new thread may reuse the ID of an exited thread. (This could be a performance issue with dynamic threading, but ATS seems to do little of that.) So |
| using time_point = std::chrono::time_point<std::chrono::system_clock>; | ||
|
|
||
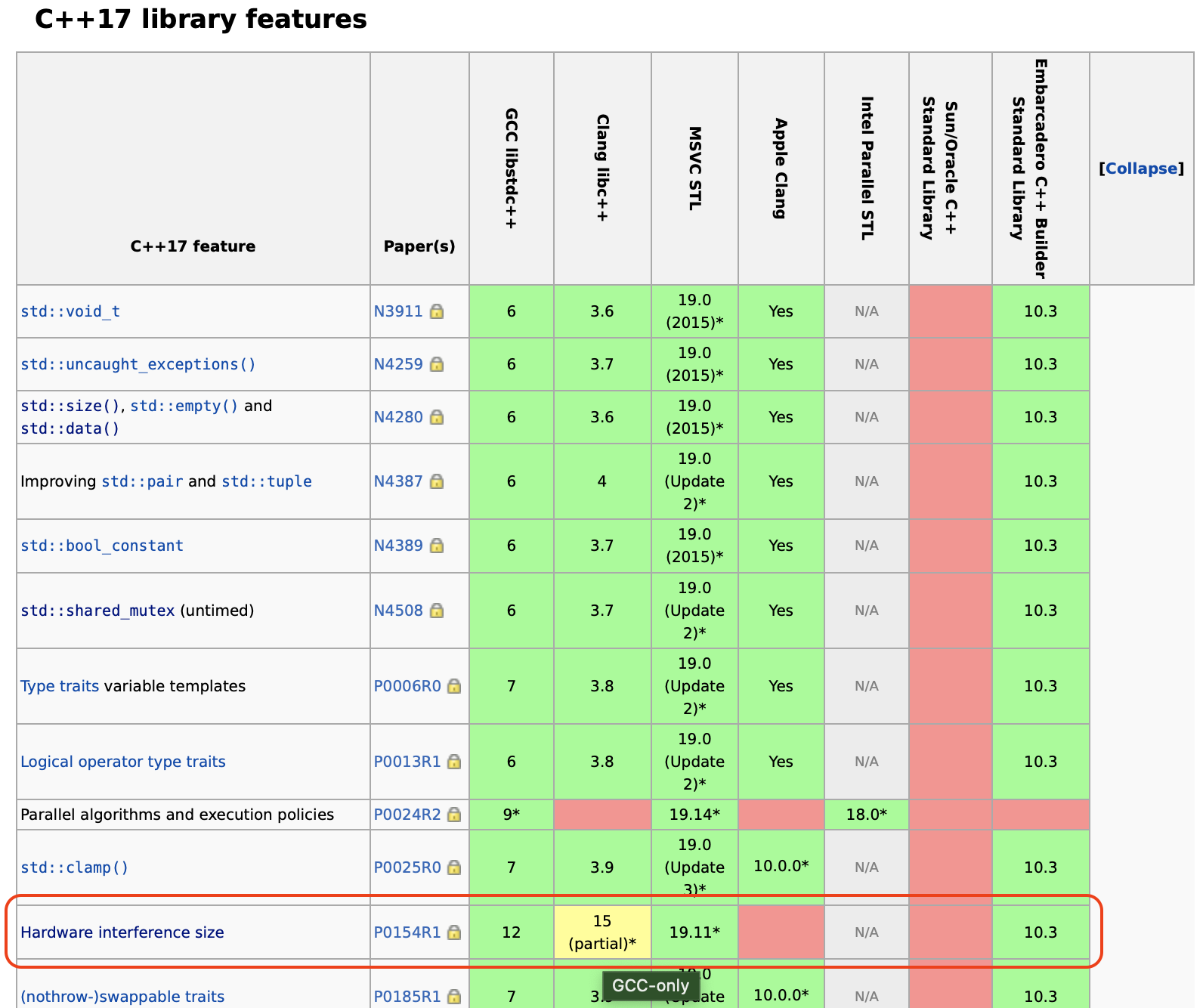
| #ifdef __cpp_lib_hardware_interference_size | ||
| using std::hardware_constructive_interference_size; |
There was a problem hiding this comment.
It seems like this constant is only available in newer versions of gcc and clang. We could maybe get the cache line size out of /proc/cpuinfo when the target is Linux?
wkaras ~
$ grep -e cache_alignment -e processor /proc/cpuinfo | head -n 4
processor : 0
cache_alignment : 64
processor : 1
cache_alignment : 64
wkaras ~
$
There was a problem hiding this comment.
This is C++17 but only available with GCC 😿
https://en.cppreference.com/w/cpp/thread/hardware_destructive_interference_size
Please look at the table and graph above. The benchmark is measured with 1,2,4,8,16,32, and 64 threads. ts::brovo::shared_mutex shows better performance with fewer threads.
IIUC, reducing collision between threads by using the hash function (mix32) is one of the key ideas of BRAVO. |
Signed-off-by: Walt Karas <wkaras@yahooinc.com>
|
Would be good if Apple people looked at this. Maybe @vmamidi or @cmcfarlen . Apple was talking about having thread_local HostDBs. Maybe if HostDB had a faster shared_mutex, that complexity could be avoided. Yahoo has deprioritized exploration of the use of proxy hosts with many cores, so I won't get many brownie points for giving this the attention that it deserves. |
|
Here is a unit test I wrote in a previous effort to build a better shared_mutex: https://github.com/ywkaras/trafficserver/blob/OWMR/src/tscore/unit_tests/test_OneWriterMultiReader.cc . |
|
Microbenchmark with read: 1000, write: 0
read: 1000, write: 1
|
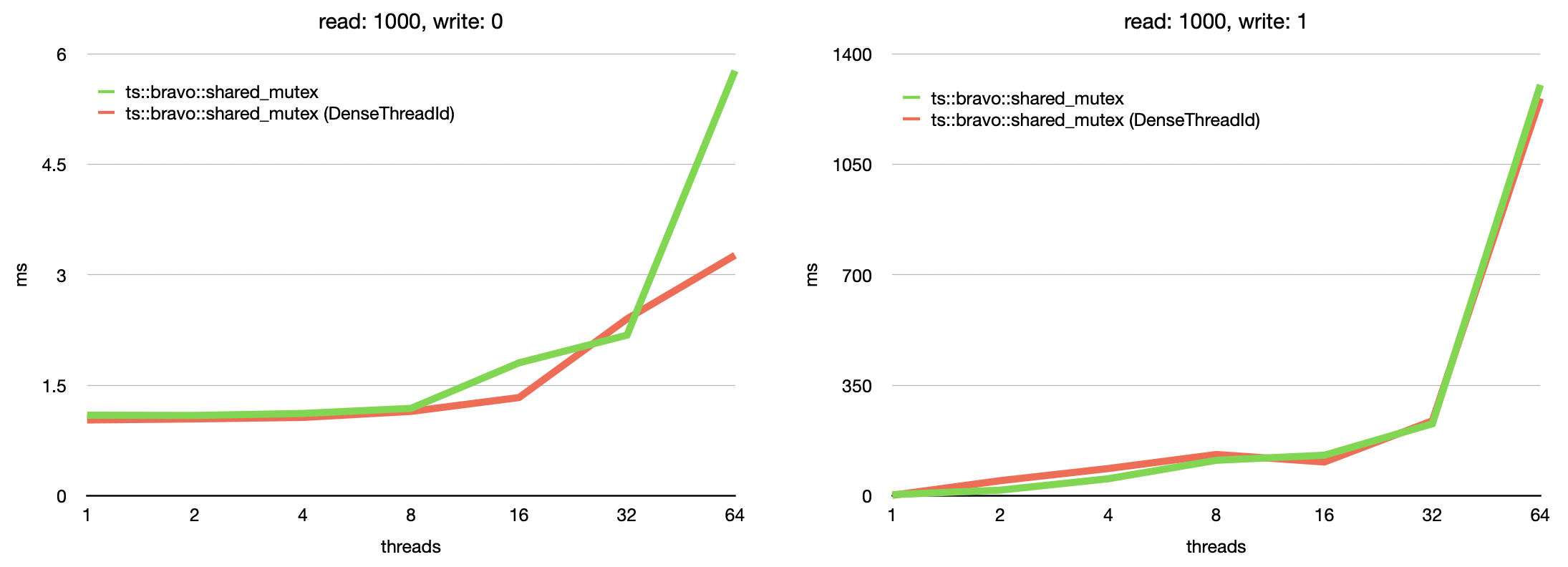
|
It looks like there are still a few areas that need improvement. But, I think the next step is to agree on what testing is needed for verification of proper, logically correct locking. If you think your current logic testing is adequate, I think we should get at least one more reviewer, to break the tie. |
|
A common problem with performance testing is that, since the code is executing to time it only, not to use any results, the optimizer will remove some or all of the code you're actually trying to time. One way to double check is to use 'objdump -d' to disassemble, check if there's clearly too few assembly instructions corresponding to the source code. |
|
For the logic, having more complicated tests is better, but current tests have enough coverage to start testing this reader-writer lock widely. Let's have more eyeballs. For the benchmark, I noticed Catch2 Benchmark provides an option[*1] ( [*1] https://github.com/catchorg/Catch2/blob/v2.13.8/docs/benchmarks.md#the-optimizer |
|
I created a test build replacing all RW locks( |
| struct Mutex { | ||
| std::atomic<bool> read_bias = false; | ||
| std::array<Slot, SLOT_SIZE> readers = {}; |
There was a problem hiding this comment.
It seems unlike the original BRAVO where a global reader table is used, your implementation has a reader table per lock instance. This will increase the per-lock memory footprint, with potential performance benefit. May benchmark the memory usage as well to see whether the trade-off is worthwhile/acceptable.
There was a problem hiding this comment.
Right, I followed the approach of xsync's RBMutex.
https://github.com/puzpuzpuz/xsync/blob/main/rbmutex.go
|
[approve ci centos] |
|
Masaori and I don' t agree as to whether this needs a longer unit test, so I'm bowing out and leaving it to other reviewers to break the tie. |
* asf/master: Fix Via header on H3 connections (apache#9758) Add ssrc and surc log fields for server simple/unavail retry counts. (apache#9694) Term standardization: dead/down server -> down server (apache#9582) Fix a crash caused by a HTTP/2 GET request with a body (apache#9738) Add configuration for UDP poll timeout (apache#9733) Fix quic_no_activity_timeout test (apache#9737) Updates to cmake install to get a running ATS from a fresh install (apache#9735) Make config.proxy.http.no_dns_just_forward_to_parent overridable (apache#9728) Fix a potential crash due to use-after-free on QUIC connections (apache#9715) Doc: Clarify that connect ports can have multiple values (apache#9713) Add BRAVO Reader-Writer Lock (apache#9394) Cleanup: Fix format of doc corruption message (apache#9725) Don't build traffic_quic command (apache#9726) Fix protocol version in request Via header (apache#9716) Fix TS_HTTP_REQUEST_TRANSFORM_HOOK Tunnel Processing (apache#9724)
Abstract
Introduce
ts::bravo::shared_mutexas an alternative to thestd::shared_mutexorpthread_rwlock_t.As we know,
std::shared_mutexorpthread_rwlock_t(almost equivalent on Linux) doesn't scale on a multi-thread application like ATS. BRAVO is a reader-writer lock algorithm published by Dave Dice and Alex Kogan at USENIX 2019[*1]. The algorithm acts as an accelerator layer for the reader lock. Please note that this doesn't accelerate the writer lock, but almost no penalty. This algorithm is useful for read-heavy use cases. For the details of the algorithm, please check the paper.Implementation
The puzpuzpuz/xsync's
RBMutexis an algorithm implementation in go-lang.ts::bravo::shared_mutexfollowed it in C++.Exclusive locking (writer)
ts::bravo::shared_mutexcan be a drop-in replacement.Shared locking (reader)
To handle
ts::bravo::Token, it needsts::bravo::shared_lock, but you can use it likestd::shared_lock.Micro Benchmark
benchmark_shared_mutex.ccis Catch2 based micro benchmark tool. You can adjust threads and the rate of reading and writing.The below numbers are measures on Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz 64 core.
read: 1000, write: 0
read: 1000, write: 1
References
[*1] Dave Dice and Alex Kogan. 2019. BRAVO: Biased Locking for Reader-Writer Locks. In Proceedings of the 2019 USENIX Annual Technical Conference (ATC). USENIX Association, Renton, WA, 315–328.
https://www.usenix.org/conference/atc19/presentation/dice
[*2] xsync - Concurrent data structures for Go
https://github.com/puzpuzpuz/xsync