Synch with apache:master #4
Merged
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
… to avoid OOM ## What changes were proposed in this pull request? Currently SQL tab in the WEBUI doesn't support pagination. Because of that following issues are happening. 1) For large number of executions, SQL page is throwing OOM exception (around 40,000) 2) For large number of executions, loading SQL page is taking time. 3) Difficult to analyse the execution table for large number of execution. [Note: spark.sql.ui.retainedExecutions = 50000] All the tabs, Jobs, Stages etc. supports pagination. So, to make it consistent with other tabs SQL tab also should support pagination. I have followed the similar flow of the pagination code in the Jobs and Stages page for SQL page. Also, this patch doesn't make any behavior change for the SQL tab except the pagination support. ## How was this patch tested? bin/spark-shell --conf spark.sql.ui.retainedExecutions=50000 Run 50,000 sql queries. **Before this PR** 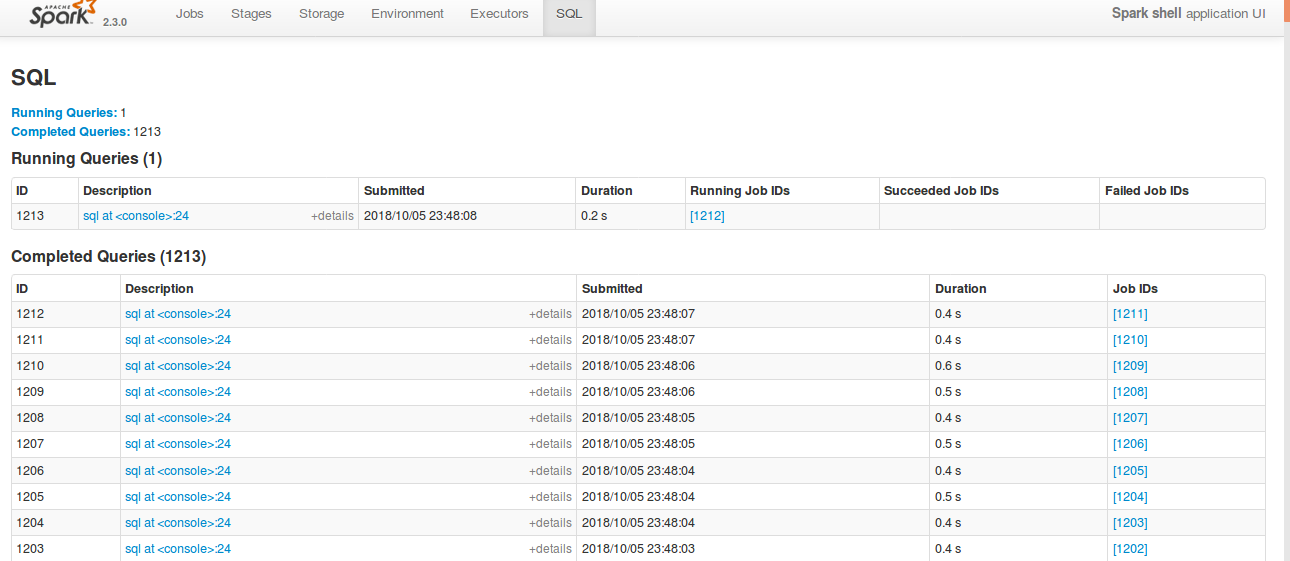 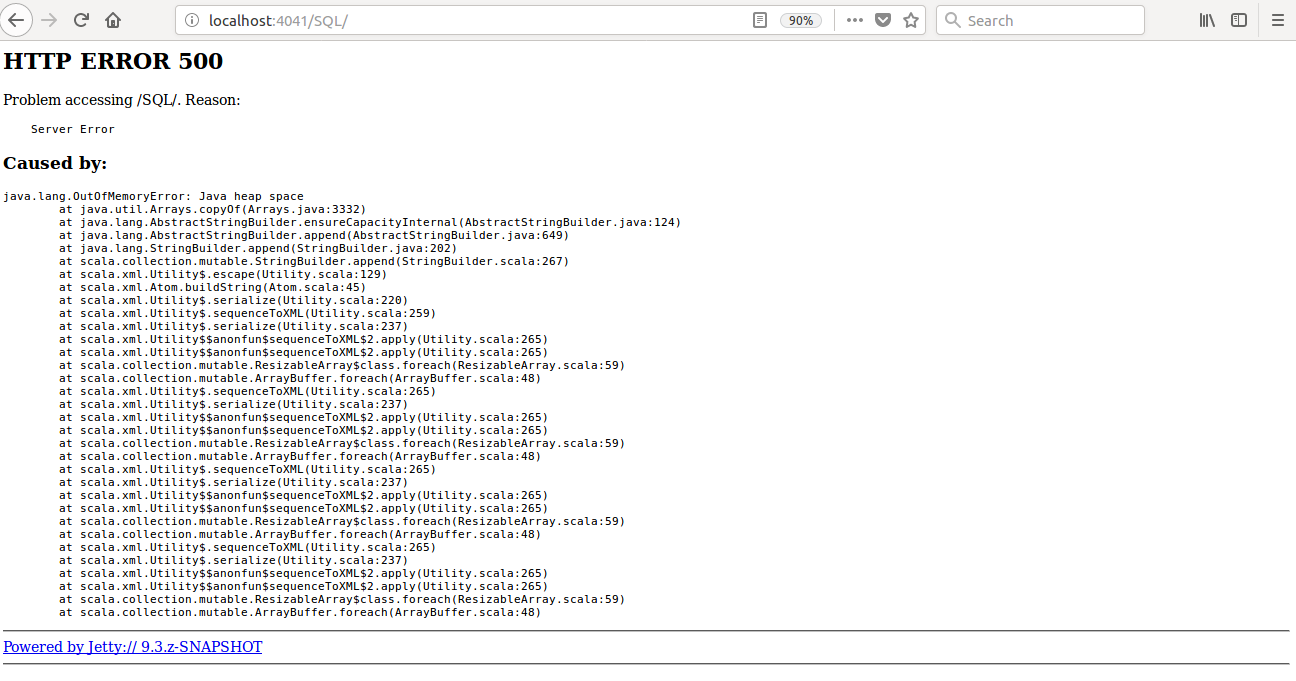 **After this PR** Loading of the page is faster, and OOM issue doesn't happen. 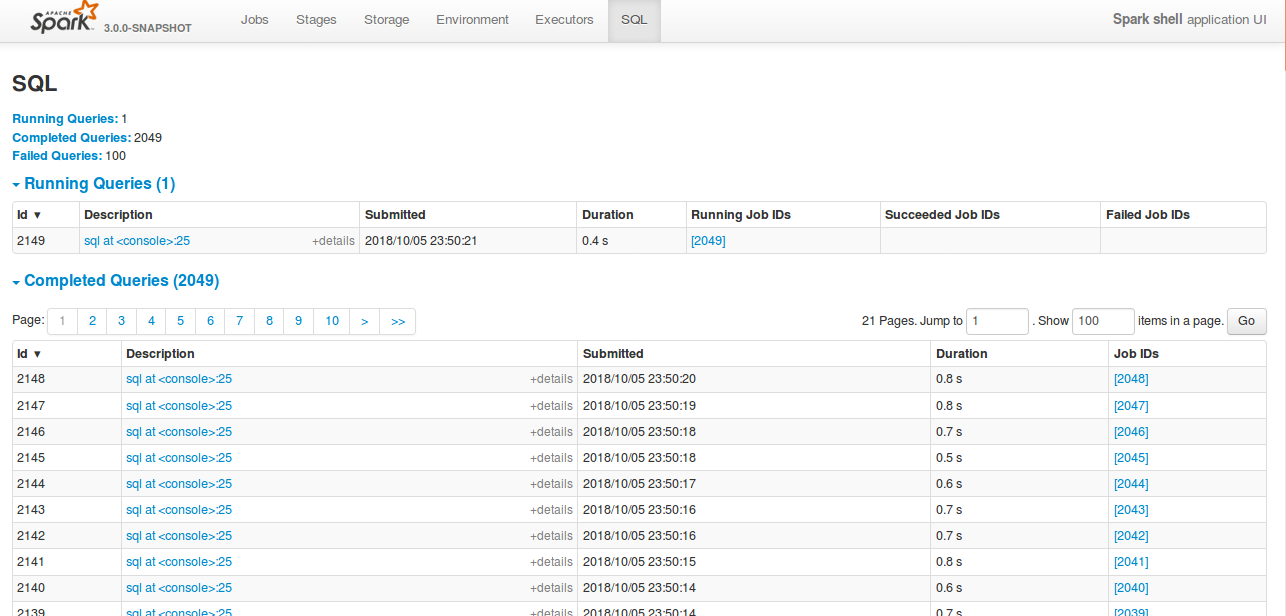 Closes #22645 from shahidki31/SPARK-25566. Authored-by: Shahid <shahidki31@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
…onsSuite ## What changes were proposed in this pull request? After the changes, total execution time of `JsonExpressionsSuite.scala` dropped from 12.5 seconds to 3 seconds. Closes #22657 from MaxGekk/json-timezone-test. Authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
… repository ## What changes were proposed in this pull request? Many companies have their own enterprise GitHub to manage Spark code. To build and test in those repositories with Jenkins need to modify this script. So I suggest to add some environment variables to allow regression testing in enterprise Jenkins instead of default Spark repository in GitHub. ## How was this patch tested? Manually test. Closes #22678 from LantaoJin/SPARK-25685. Lead-authored-by: lajin <lajin@ebay.com> Co-authored-by: LantaoJin <jinlantao@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
…nd start-slave.sh
## What changes were proposed in this pull request?
Currently if we run
```
./sbin/start-master.sh -h
```
We get
```
Usage: ./sbin/start-master.sh [options]
18/10/11 23:38:30 INFO Master: Started daemon with process name: 33907C02TL2JZGTF1
18/10/11 23:38:30 INFO SignalUtils: Registered signal handler for TERM
18/10/11 23:38:30 INFO SignalUtils: Registered signal handler for HUP
18/10/11 23:38:30 INFO SignalUtils: Registered signal handler for INT
Options:
-i HOST, --ip HOST Hostname to listen on (deprecated, please use --host or -h)
-h HOST, --host HOST Hostname to listen on
-p PORT, --port PORT Port to listen on (default: 7077)
--webui-port PORT Port for web UI (default: 8080)
--properties-file FILE Path to a custom Spark properties file.
Default is conf/spark-defaults.conf.
```
We can filter out some useless output.
## How was this patch tested?
Manual test
Closes #22700 from gengliangwang/improveStartScript.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
…tion is throwing Error in the history webui ## What changes were proposed in this pull request? When we enable event log compression and compression codec as 'zstd', we are unable to open the webui of the running application from the history server page. The reason is that, Replay listener was unable to read from the zstd compressed eventlog due to the zstd frame was not finished yet. This causes truncated error while reading the eventLog. So, when we try to open the WebUI from the History server page, it throws "truncated error ", and we never able to open running application in the webui, when we enable zstd compression. In this PR, when the IO excpetion happens, and if it is a running application, we log the error, "Failed to read Spark event log: evetLogDirAppName.inprogress", instead of throwing exception. ## How was this patch tested? Test steps: 1)spark.eventLog.compress = true 2)spark.io.compression.codec = zstd 3)restart history server 4) launch bin/spark-shell 5) run some queries 6) Open history server page 7) click on the application **Before fix:**   **After fix:**   (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Closes #22689 from shahidki31/SPARK-25697. Authored-by: Shahid <shahidki31@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
## What changes were proposed in this pull request? The PR addresses the exception raised on accessing chars out of delimiter string. In particular, the backward slash `\` as the CSV fields delimiter causes the following exception on reading `abc\1`: ```Scala String index out of range: 1 java.lang.StringIndexOutOfBoundsException: String index out of range: 1 at java.lang.String.charAt(String.java:658) ``` because `str.charAt(1)` tries to access a char out of `str` in `CSVUtils.toChar` ## How was this patch tested? Added tests for empty string and string containing the backward slash to `CSVUtilsSuite`. Besides of that I added an end-to-end test to check how the backward slash is handled in reading CSV string with it. Closes #22654 from MaxGekk/csv-slash-delim. Authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request?
- Fixed typo for function outputMode
- OutputMode.Complete(), changed `these is some updates` to `there are some updates`
- Replaced hyphenized list by HTML unordered list tags in comments to fix the Javadoc documentation.
Current render from most recent [Spark API Docs](https://spark.apache.org/docs/2.3.1/api/java/org/apache/spark/sql/streaming/DataStreamWriter.html):
#### outputMode(OutputMode) - List formatted as a prose.

#### outputMode(String) - List formatted as a prose.

#### partitionBy(String*) - List formatted as a prose.

## How was this patch tested?
This PR contains a document patch ergo no functional testing is required.
Closes #22593 from niofire/fix-typo-datastreamwriter.
Authored-by: Mathieu St-Louis <mastloui@microsoft.com>
Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
{kind=link}
{kind=link}
## What changes were proposed in this pull request? Refactor `JoinBenchmark` to use main method. 1. use `spark-submit`: ```console bin/spark-submit --class org.apache.spark.sql.execution.benchmark.JoinBenchmark --jars ./core/target/spark-core_2.11-3.0.0-SNAPSHOT-tests.jar ./sql/catalyst/target/spark-sql_2.11-3.0.0-SNAPSHOT-tests.jar ``` 2. Generate benchmark result: ```console SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "sql/test:runMain org.apache.spark.sql.execution.benchmark.JoinBenchmark" ``` ## How was this patch tested? manual tests Closes #22661 from wangyum/SPARK-25664. Lead-authored-by: Yuming Wang <yumwang@ebay.com> Co-authored-by: Yuming Wang <wgyumg@gmail.com> Co-authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…ction returning Iterable, not Iterator ## What changes were proposed in this pull request? Fix old oversight in API: Java `flatMapValues` needs a `FlatMapFunction` ## How was this patch tested? Existing tests. Closes #22690 from srowen/SPARK-19287. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
…like GPUs ## What changes were proposed in this pull request? This PR adds CLI support for YARN custom resources, e.g. GPUs and any other resources YARN defines. The custom resources are defined with Spark properties, no additional CLI arguments were introduced. The properties can be defined in the following form: **AM resources, client mode:** Format: `spark.yarn.am.resource.<resource-name>` The property name follows the naming convention of YARN AM cores / memory properties: `spark.yarn.am.memory and spark.yarn.am.cores ` **Driver resources, cluster mode:** Format: `spark.yarn.driver.resource.<resource-name>` The property name follows the naming convention of driver cores / memory properties: `spark.driver.memory and spark.driver.cores.` **Executor resources:** Format: `spark.yarn.executor.resource.<resource-name>` The property name follows the naming convention of executor cores / memory properties: `spark.executor.memory / spark.executor.cores`. For the driver resources (cluster mode) and executor resources properties, we use the `yarn` prefix here as custom resource types are specific to YARN, currently. **Validation:** Please note that a validation logic is added to avoid having requested resources defined in 2 ways, for example defining the following configs: ``` "--conf", "spark.driver.memory=2G", "--conf", "spark.yarn.driver.resource.memory=1G" ``` will not start execution and will print an error message. ## How was this patch tested? Unit tests + manual execution with Hadoop2 and Hadoop 3 builds. Testing have been performed on a real cluster with Spark and YARN configured: Cluster and client mode Request Resource Types with lowercase and uppercase units Start Spark job with only requesting standard resources (mem / cpu) Error handling cases: - Request unknown resource type - Request Resource type (either memory / cpu) with duplicate configs at the same time (e.g. with this config: ``` --conf spark.yarn.am.resource.memory=1G \ --conf spark.yarn.driver.resource.memory=2G \ --conf spark.yarn.executor.resource.memory=3G \ ``` ), ResourceTypeValidator handles these cases well, so it is not permitted - Request standard resource (memory / cpu) with the new style configs, e.g. --conf spark.yarn.am.resource.memory=1G, this is not permitted and handled well. An example about how I ran the testcases: ``` cd ~;export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop/; ./spark-2.4.0-SNAPSHOT-bin-custom-spark/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ --driver-memory 1G \ --driver-cores 1 \ --executor-memory 1G \ --executor-cores 1 \ --conf spark.logConf=true \ --conf spark.yarn.executor.resource.gpu=3G \ --verbose \ ./spark-2.4.0-SNAPSHOT-bin-custom-spark/examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar \ 10; ``` Closes #20761 from szyszy/SPARK-20327. Authored-by: Szilard Nemeth <snemeth@cloudera.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
…cation
## What changes were proposed in this pull request?
```Scala
val df1 = Seq(("abc", 1), (null, 3)).toDF("col1", "col2")
df1.write.mode(SaveMode.Overwrite).parquet("/tmp/test1")
val df2 = spark.read.parquet("/tmp/test1")
df2.filter("col1 = 'abc' OR (col1 != 'abc' AND col2 == 3)").show()
```
Before the PR, it returns both rows. After the fix, it returns `Row ("abc", 1))`. This is to fix the bug in NULL handling in BooleanSimplification. This is a bug introduced in Spark 1.6 release.
## How was this patch tested?
Added test cases
Closes #22702 from gatorsmile/fixBooleanSimplify2.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? Currently `Range` reports metrics in batch granularity. This is acceptable, but it's better if we can make it row granularity without performance penalty. Before this PR, the metrics are updated when preparing the batch, which is before we actually consume data. In this PR, the metrics are updated after the data are consumed. There are 2 different cases: 1. The data processing loop has a stop check. The metrics are updated when we need to stop. 2. no stop check. The metrics are updated after the loop. ## How was this patch tested? existing tests and a new benchmark Closes #22698 from cloud-fan/range. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…w exception ## What changes were proposed in this pull request? Avro schema allows recursive reference, e.g. the schema for linked-list in https://avro.apache.org/docs/1.8.2/spec.html#schema_record ``` { "type": "record", "name": "LongList", "aliases": ["LinkedLongs"], // old name for this "fields" : [ {"name": "value", "type": "long"}, // each element has a long {"name": "next", "type": ["null", "LongList"]} // optional next element ] } ``` In current Spark SQL, it is impossible to convert the schema as `StructType` . Run `SchemaConverters.toSqlType(avroSchema)` and we will get stack overflow exception. We should detect the recursive reference and throw exception for it. ## How was this patch tested? New unit test case. Closes #22709 from gengliangwang/avroRecursiveRef. Authored-by: Gengliang Wang <gengliang.wang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…Friendly and remove deprecated options
## What changes were proposed in this pull request?
Currently, if we try run
```
./start-history-server.sh -h
```
We will get such error
```
java.io.FileNotFoundException: File -h does not exist
```
1. This is not User-Friendly. For option `-h` or `--help`, it should be parsed correctly and show the usage of the class/script.
2. We can remove deprecated options for setting event log directory through command line options.
After fix, we can get following output:
```
Usage: ./sbin/start-history-server.sh [options]
Options:
--properties-file FILE Path to a custom Spark properties file.
Default is conf/spark-defaults.conf.
Configuration options can be set by setting the corresponding JVM system property.
History Server options are always available; additional options depend on the provider.
History Server options:
spark.history.ui.port Port where server will listen for connections
(default 18080)
spark.history.acls.enable Whether to enable view acls for all applications
(default false)
spark.history.provider Name of history provider class (defaults to
file system-based provider)
spark.history.retainedApplications Max number of application UIs to keep loaded in memory
(default 50)
FsHistoryProvider options:
spark.history.fs.logDirectory Directory where app logs are stored
(default: file:/tmp/spark-events)
spark.history.fs.updateInterval How often to reload log data from storage
(in seconds, default: 10)
```
## How was this patch tested?
Manual test
Closes #22699 from gengliangwang/refactorSHSUsage.
Authored-by: Gengliang Wang <gengliang.wang@databricks.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…fication rule ## What changes were proposed in this pull request? improve the code comment added in https://github.com/apache/spark/pull/22702/files ## How was this patch tested? N/A Closes #22711 from cloud-fan/minor. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…uite ## What changes were proposed in this pull request? [SPARK-22479](https://github.com/apache/spark/pull/19708/files#diff-5c22ac5160d3c9d81225c5dd86265d27R31) adds a test case which sometimes fails because the used password string `123` matches `41230802`. This PR aims to fix the flakiness. - https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97343/consoleFull ```scala SaveIntoDataSourceCommandSuite: - simpleString is redacted *** FAILED *** "SaveIntoDataSourceCommand .org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider41230802, Map(password -> *********(redacted), url -> *********(redacted), driver -> mydriver), ErrorIfExists +- Range (0, 1, step=1, splits=Some(2)) " contained "123" (SaveIntoDataSourceCommandSuite.scala:42) ``` ## How was this patch tested? Pass the Jenkins with the updated test case Closes #22716 from dongjoon-hyun/SPARK-25726. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…ation
## What changes were proposed in this pull request?
Add `outputOrdering ` to `otherCopyArgs` in InMemoryRelation so that this field will be copied when we doing the tree transformation.
```
val data = Seq(100).toDF("count").cache()
data.queryExecution.optimizedPlan.toJSON
```
The above code can generate the following error:
```
assertion failed: InMemoryRelation fields: output, cacheBuilder, statsOfPlanToCache, outputOrdering, values: List(count#178), CachedRDDBuilder(true,10000,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) Project [value#176 AS count#178]
+- LocalTableScan [value#176]
,None), Statistics(sizeInBytes=12.0 B, hints=none)
java.lang.AssertionError: assertion failed: InMemoryRelation fields: output, cacheBuilder, statsOfPlanToCache, outputOrdering, values: List(count#178), CachedRDDBuilder(true,10000,StorageLevel(disk, memory, deserialized, 1 replicas),*(1) Project [value#176 AS count#178]
+- LocalTableScan [value#176]
,None), Statistics(sizeInBytes=12.0 B, hints=none)
at scala.Predef$.assert(Predef.scala:170)
at org.apache.spark.sql.catalyst.trees.TreeNode.jsonFields(TreeNode.scala:611)
at org.apache.spark.sql.catalyst.trees.TreeNode.org$apache$spark$sql$catalyst$trees$TreeNode$$collectJsonValue$1(TreeNode.scala:599)
at org.apache.spark.sql.catalyst.trees.TreeNode.jsonValue(TreeNode.scala:604)
at org.apache.spark.sql.catalyst.trees.TreeNode.toJSON(TreeNode.scala:590)
```
## How was this patch tested?
Added a test
Closes #22715 from gatorsmile/copyArgs1.
Authored-by: gatorsmile <gatorsmile@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
… principal config ## What changes were proposed in this pull request? Update the next version of Spark from 2.5 to 3.0 ## How was this patch tested? N/A Closes #22717 from gatorsmile/followupSPARK-25372. Authored-by: gatorsmile <gatorsmile@gmail.com> Signed-off-by: hyukjinkwon <gurwls223@apache.org>
…nMemoryRelation ## What changes were proposed in this pull request? The PR addresses [the comment](#22715 (comment)) in the previous one. `outputOrdering` becomes a field of `InMemoryRelation`. ## How was this patch tested? existing UTs Closes #22726 from mgaido91/SPARK-25727_followup. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…valid constraints generation ## What changes were proposed in this pull request? Project logical operator generates valid constraints using two opposite operations. It substracts child constraints from all constraints, than union child constraints again. I think it may be not necessary. Aggregate operator has the same problem with Project. This PR try to remove these two opposite collection operations. ## How was this patch tested? Related unit tests: ProjectEstimationSuite CollapseProjectSuite PushProjectThroughUnionSuite UnsafeProjectionBenchmark GeneratedProjectionSuite CodeGeneratorWithInterpretedFallbackSuite TakeOrderedAndProjectSuite GenerateUnsafeProjectionSuite BucketedRandomProjectionLSHSuite RemoveRedundantAliasAndProjectSuite AggregateBenchmark AggregateOptimizeSuite AggregateEstimationSuite DecimalAggregatesSuite DateFrameAggregateSuite ObjectHashAggregateSuite TwoLevelAggregateHashMapSuite ObjectHashAggregateExecBenchmark SingleLevelAggregateHaspMapSuite TypedImperativeAggregateSuite RewriteDistinctAggregatesSuite HashAggregationQuerySuite HashAggregationQueryWithControlledFallbackSuite TypedImperativeAggregateSuite TwoLevelAggregateHashMapWithVectorizedMapSuite Closes #22706 from SongYadong/generate_constraints. Authored-by: SongYadong <song.yadong1@zte.com.cn> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? This is the work on setting up Secure HDFS interaction with Spark-on-K8S. The architecture is discussed in this community-wide google [doc](https://docs.google.com/document/d/1RBnXD9jMDjGonOdKJ2bA1lN4AAV_1RwpU_ewFuCNWKg) This initiative can be broken down into 4 Stages **STAGE 1** - [x] Detecting `HADOOP_CONF_DIR` environmental variable and using Config Maps to store all Hadoop config files locally, while also setting `HADOOP_CONF_DIR` locally in the driver / executors **STAGE 2** - [x] Grabbing `TGT` from `LTC` or using keytabs+principle and creating a `DT` that will be mounted as a secret or using a pre-populated secret **STAGE 3** - [x] Driver **STAGE 4** - [x] Executor ## How was this patch tested? Locally tested on a single-noded, pseudo-distributed Kerberized Hadoop Cluster - [x] E2E Integration tests #22608 - [ ] Unit tests ## Docs and Error Handling? - [x] Docs - [x] Error Handling ## Contribution Credit kimoonkim skonto Closes #21669 from ifilonenko/secure-hdfs. Lead-authored-by: Ilan Filonenko <if56@cornell.edu> Co-authored-by: Ilan Filonenko <ifilondz@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request? This PR is a follow-up of #22594 . This alternative can avoid the unneeded computation in the hot code path. - For row-based scan, we keep the original way. - For the columnar scan, we just need to update the stats after each batch. ## How was this patch tested? N/A Closes #22731 from gatorsmile/udpateStatsFileScanRDD. Authored-by: gatorsmile <gatorsmile@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request? LOAD DATA INPATH didn't work if the defaultFS included a port for hdfs. Handling this just requires a small change to use the correct URI constructor. ## How was this patch tested? Added a unit test, ran all tests via jenkins Closes #22733 from squito/SPARK-25738. Authored-by: Imran Rashid <irashid@cloudera.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
…ime costs in Jenkins ## What changes were proposed in this pull request? Only test these 4 cases is enough: https://github.com/apache/spark/blob/be2238fb502b0f49a8a1baa6da9bc3e99540b40e/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetWriteSupport.scala#L269-L279 ## How was this patch tested? Manual tests on my local machine. before: ``` - filter pushdown - decimal (13 seconds, 683 milliseconds) ``` after: ``` - filter pushdown - decimal (9 seconds, 713 milliseconds) ``` Closes #22636 from wangyum/SPARK-25629. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: hyukjinkwon <gurwls223@apache.org>
…lumn count ## What changes were proposed in this pull request? AFAIK multi-column count is not widely supported by the mainstream databases(postgres doesn't support), and the SQL standard doesn't define it clearly, as near as I can tell. Since Spark supports it, we should clearly document the current behavior and add tests to verify it. ## How was this patch tested? N/A Closes #22728 from cloud-fan/doc. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: hyukjinkwon <gurwls223@apache.org>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
15 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
No description provided.