Release v4.39.0
v4.39.0
🚨 VRAM consumption 🚨
The Llama, Cohere and the Gemma model both no longer cache the triangular causal mask unless static cache is used. This was reverted by #29753, which fixes the BC issues w.r.t speed , and memory consumption, while still supporting compile and static cache. Small note, fx is not supported for both models, a patch will be brought very soon!
New model addition
Cohere open-source model
Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is designed to work in concert with Cohere's industry-leading Embed and Rerank models to provide best-in-class integration for RAG applications and excel at enterprise use cases. As a model built for companies to implement at scale, Command-R boasts:
- Strong accuracy on RAG and Tool Use
- Low latency, and high throughput
- Longer 128k context and lower pricing
- Strong capabilities across 10 key languages
- Model weights available on HuggingFace for research and evaluation
- Cohere Model Release by @saurabhdash2512 in #29622
LLaVA-NeXT (llava v1.6)
Llava next is the next version of Llava, which includes better support for non padded images, improved reasoning, OCR, and world knowledge. LLaVA-NeXT even exceeds Gemini Pro on several benchmarks.
Compared with LLaVA-1.5, LLaVA-NeXT has several improvements:
- Increasing the input image resolution to 4x more pixels. This allows it to grasp more visual details. It supports three aspect ratios, up to 672x672, 336x1344, 1344x336 resolution.
- Better visual reasoning and OCR capability with an improved visual instruction tuning data mixture.
- Better visual conversation for more scenarios, covering different applications.
- Better world knowledge and logical reasoning.
- Along with performance improvements, LLaVA-NeXT maintains the minimalist design and data efficiency of LLaVA-1.5. It re-uses the pretrained connector of LLaVA-1.5, and still uses less than 1M visual instruction tuning samples. The largest 34B variant finishes training in ~1 day with 32 A100s.*
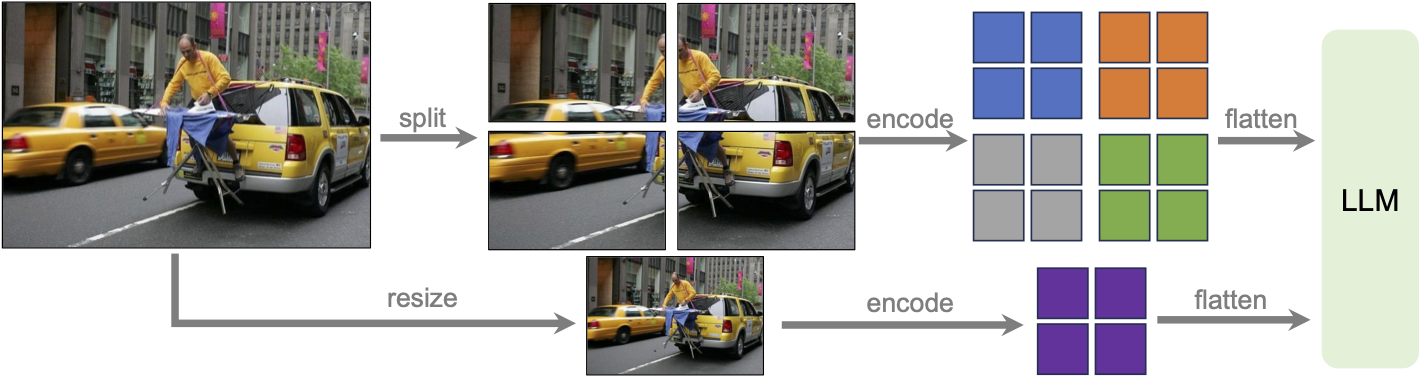
LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
MusicGen Melody
The MusicGen Melody model was proposed in Simple and Controllable Music Generation by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen Melody is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or audio codes, conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec, to recover the audio waveform.
Through an efficient token interleaving pattern, MusicGen does not require a self-supervised semantic representation of the text/audio prompts, thus eliminating the need to cascade multiple models to predict a set of codebooks (e.g. hierarchically or upsampling). Instead, it is able to generate all the codebooks in a single forward pass.
PvT-v2
The PVTv2 model was proposed in PVT v2: Improved Baselines with Pyramid Vision Transformer by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
- Add PvT-v2 Model by @FoamoftheSea in #26812
UDOP
The UDOP model was proposed in Unifying Vision, Text, and Layout for Universal Document Processing by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal. UDOP adopts an encoder-decoder Transformer architecture based on T5 for document AI tasks like document image classification, document parsing and document visual question answering.
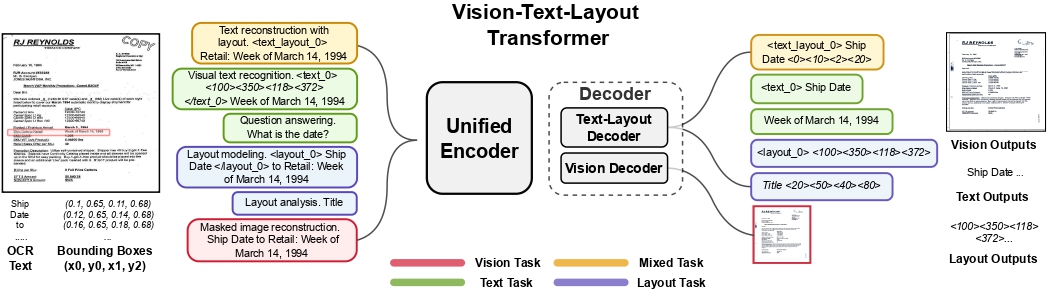
UDOP architecture. Taken from the original paper.
- Add UDOP by @NielsRogge in #22940
Mamba
This model is a new paradigm architecture based on state-space-models, rather than attention like transformer models.
The checkpoints are compatible with the original ones
- [
Add Mamba] Adds support for theMambamodels by @ArthurZucker in #28094
StarCoder2
StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective.
- Starcoder2 model - bis by @RaymondLi0 in #29215
SegGPT
The SegGPT model was proposed in SegGPT: Segmenting Everything In Context by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
- Adding SegGPT by @EduardoPach in #27735
Galore optimizer

With Galore, you can pre-train large models on consumer-type hardwares, making LLM pre-training much more accessible to anyone from the community.
Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
Galore is based on low rank approximation of the gradients and can be used out of the box for any model.
Below is a simple snippet that demonstrates how to pre-train mistralai/Mistral-7B-v0.1 on imdb:
import torch
import datasets
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
import trl
train_dataset = datasets.load_dataset('imdb', split='train')
args = TrainingArguments(
output_dir="./test-galore",
max_steps=100,
per_device_train_batch_size=2,
optim="galore_adamw",
optim_target_modules=["attn", "mlp"]
)
model_id = "mistralai/Mistral-7B-v0.1"
config = AutoConfig.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
max_seq_length=512,
)
trainer.train()Quantization
Quanto integration
Quanto has been integrated with transformers ! You can apply simple quantization algorithms with few lines of code with tiny changes. Quanto is also compatible with torch.compile
Check out the announcement blogpost for more details
Exllama 🤝 AWQ
Exllama and AWQ combined together for faster AWQ inference - check out the relevant documentation section for more details on how to use Exllama + AWQ.
- Exllama kernels support for AWQ models by @IlyasMoutawwakil in #28634
MLX Support
Allow models saved or fine-tuned with Apple’s MLX framework to be loaded in transformers (as long as the model parameters use the same names), and improve tensor interoperability. This leverages MLX's adoption of safetensors as their checkpoint format.
- Add mlx support to BatchEncoding.convert_to_tensors by @Y4hL in #29406
- Add support for metadata format MLX by @alexweberk in #29335
- Typo in mlx tensor support by @pcuenca in #29509
- Experimental loading of MLX files by @pcuenca in #29511
Highligted improvements
Notable memory reduction in Gemma/LLaMa by changing the causal mask buffer type from int64 to boolean.
Remote code improvements
- Allow remote code repo names to contain "." by @Rocketknight1 in #29175
- simplify get_class_in_module and fix for paths containing a dot by @cebtenzzre in #29262
Breaking changes
The PRs below introduced slightly breaking changes that we believed was necessary for the repository; if these seem to impact your usage of transformers, we recommend checking out the PR description to get more insights in how to leverage the new behavior.
- 🚨🚨[Whisper Tok] Update integration test by @sanchit-gandhi in #29368
- 🚨 Fully revert atomic checkpointing 🚨 by @muellerzr in #29370
- [BC 4.37 -> 4.38] for Llama family, memory and speed #29753 (causal mask is no longer a registered buffer)
Fixes and improvements
- FIX [
Gemma] Fix bad rebase with transformers main by @younesbelkada in #29170 - Add training version check for AQLM quantizer. by @BlackSamorez in #29142
- [Gemma] Fix eager attention by @sanchit-gandhi in #29187
- [Mistral, Mixtral] Improve docs by @NielsRogge in #29084
- Fix
torch.compilewithfullgraph=Truewhenattention_maskinput is used by @fxmarty in #29211 - fix(mlflow): check mlflow version to use the synchronous flag by @cchen-dialpad in #29195
- Fix missing translation in README_ru by @strikoder in #29054
- Improve _update_causal_mask performance by @alessandropalla in #29210
- [
Doc] update model doc qwen2 by @ArthurZucker in #29238 - Use torch 2.2 for daily CI (model tests) by @ydshieh in #29208
- Cache
is_vision_availableresult by @bmuskalla in #29280 - Use
DS_DISABLE_NINJA=1by @ydshieh in #29290 - Add
non_device_testpytest mark to filter out non-device tests by @fxmarty in #29213 - Add feature extraction mapping for automatic metadata update by @merveenoyan in #28944
- Generate: v4.38 removals and related updates by @gante in #29171
- Track each row separately for stopping criteria by @zucchini-nlp in #29116
- [docs] Spanish translation of tasks_explained.md by @aaronjimv in #29224
- [i18n-zh] Translated torchscript.md into Chinese by @windsonsea in #29234
- 🌐 [i18n-ZH] Translate chat_templating.md into Chinese by @shibing624 in #28790
- [i18n-vi] Translate README.md to Vietnamese by @hoangsvit in #29229
- [i18n-zh] Translated task/asr.md into Chinese by @windsonsea in #29233
- Fixed Deformable Detr typo when loading cuda kernels for MSDA by @EduardoPach in #29294
- GenerationConfig validate both constraints and force_words_ids by @FredericOdermatt in #29163
- Add generate kwargs to VQA pipeline by @regisss in #29134
- Cleaner Cache
dtypeanddeviceextraction for CUDA graph generation for quantizers compatibility by @BlackSamorez in #29079 - Image Feature Extraction docs by @merveenoyan in #28973
- Fix
attn_implementationdocumentation by @fxmarty in #29295 - [tests] enable benchmark unit tests on XPU by @faaany in #29284
- Use torch 2.2 for deepspeed CI by @ydshieh in #29246
- Add compatibility with skip_memory_metrics for mps device by @SunMarc in #29264
- Token level timestamps for long-form generation in Whisper by @zucchini-nlp in #29148
- Fix a few typos in
GenerationMixin's docstring by @sadra-barikbin in #29277 - [i18n-zh] Translate fsdp.md into Chinese by @windsonsea in #29305
- FIX [
Gemma/CI] Make sure our runners have access to the model by @younesbelkada in #29242 - Remove numpy usage from owlvit by @fxmarty in #29326
- [
require_read_token] fix typo by @ArthurZucker in #29345 - [
T5 and Llama Tokenizer] remove warning by @ArthurZucker in #29346 - [
Llama ROPE] Fix torch export but also slow downs in forward by @ArthurZucker in #29198 - Disable Mixtral
output_router_logitsduring inference by @LeonardoEmili in #29249 - Idefics: generate fix by @gante in #29320
- RoPE loses precision for Llama / Gemma + Gemma logits.float() by @danielhanchen in #29285
- check if position_ids exists before using it by @jiqing-feng in #29306
- [CI] Quantization workflow by @SunMarc in #29046
- Better SDPA unmasking implementation by @fxmarty in #29318
- [i18n-zh] Sync source/zh/index.md by @windsonsea in #29331
- FIX [
CI/starcoder2] Change starcoder2 path to correct one for slow tests by @younesbelkada in #29359 - FIX [
CI]: Fix failing tests for peft integration by @younesbelkada in #29330 - FIX [
CI]require_read_tokenin the llama FA2 test by @younesbelkada in #29361 - Avoid using uncessary
get_values(MODEL_MAPPING)by @ydshieh in #29362 - Patch YOLOS and others by @NielsRogge in #29353
- Fix @require_read_token in tests by @Wauplin in #29367
- Expose
offload_buffersparameter ofacceleratetoPreTrainedModel.from_pretrainedmethod by @notsyncing in #28755 - Fix Base Model Name of LlamaForQuestionAnswering by @lenglaender in #29258
- FIX [
quantization/ESM] Fix ESM 8bit / 4bit with bitsandbytes by @younesbelkada in #29329 - [
Llama + AWQ] fixprepare_inputs_for_generation🫠 by @ArthurZucker in #29381 - [
YOLOS] Fix - return padded annotations by @amyeroberts in #29300 - Support subfolder with
AutoProcessorby @JingyaHuang in #29169 - Fix llama + gemma accelete tests by @SunMarc in #29380
- Fix deprecated arg issue by @muellerzr in #29372
- Correct zero division error in inverse sqrt scheduler by @DavidAfonsoValente in #28982
- [tests] enable automatic speech recognition pipeline tests on XPU by @faaany in #29308
- update path to hub files in the error message by @poedator in #29369
- [Mixtral] Fixes attention masking in the loss by @DesmonDay in #29363
- Workaround for #27758 to avoid ZeroDivisionError by @tleyden in #28756
- Convert SlimSAM checkpoints by @NielsRogge in #28379
- Fix: Fixed the previous tracking URI setting logic to prevent clashes with original MLflow code. by @seanswyi in #29096
- Fix OneFormer
post_process_instance_segmentationfor panoptic tasks by @nickthegroot in #29304 - Fix grad_norm unserializable tensor log failure by @svenschultze in #29212
- Avoid edge case in audio utils by @ylacombe in #28836
- DeformableDETR support bfloat16 by @DonggeunYu in #29232
- [Docs] Spanish Translation -Torchscript md & Trainer md by @njackman-2344 in #29310
- FIX [
Generation] Fix some issues when running the MaxLength criteria on CPU by @younesbelkada in #29317 - Fix max length for BLIP generation by @zucchini-nlp in #29296
- [docs] Update starcoder2 paper link by @xenova in #29418
- [tests] enable test_pipeline_accelerate_top_p on XPU by @faaany in #29309
- [
UdopTokenizer] Fix post merge imports by @ArthurZucker in #29451 - more fix by @ArthurZucker (direct commit on main)
- Revert-commit 0d52f9f by @ArthurZucker in #29455
- [
Udop imports] Processor tests were not run. by @ArthurZucker in #29456 - Generate: inner decoding methods are no longer public by @gante in #29437
- Fix bug with passing capture_* args to neptune callback by @AleksanderWWW in #29041
- Update pytest
import_pathlocation by @loadams in #29154 - Automatic safetensors conversion when lacking these files by @LysandreJik in #29390
- [i18n-zh] Translate add_new_pipeline.md into Chinese by @windsonsea in #29432
- 🌐 [i18n-KO] Translated generation_strategies.md to Korean by @AI4Harmony in #29086
- [FIX]
offload_weight()takes from 3 to 4 positional arguments but 5 were given by @faaany in #29457 - [
Docs/Awq] Add docs on exllamav2 + AWQ by @younesbelkada in #29474 - [
docs] Add starcoder2 docs by @younesbelkada in #29454 - Fix TrainingArguments regression with torch <2.0.0 for dataloader_prefetch_factor by @ringohoffman in #29447
- Generate: add tests for caches with
pad_to_multiple_ofby @gante in #29462 - Generate: get generation mode from the generation config instance 🧼 by @gante in #29441
- Avoid dummy token in PLD to optimize performance by @ofirzaf in #29445
- Fix test failure on DeepSpeed by @muellerzr in #29444
- Generate: torch.compile-ready generation config preparation by @gante in #29443
- added the max_matching_ngram_size to GenerationConfig by @mosheber in #29131
- Fix
TextGenerationPipeline.__call__docstring by @alvarobartt in #29491 - Substantially reduce memory usage in _update_causal_mask for large batches by using .expand instead of .repeat [needs tests+sanity check] by @nqgl in #29413
- Fix: Disable torch.autocast in RotaryEmbedding of Gemma and LLaMa for MPS device by @currybab in #29439
- Enable BLIP for auto VQA by @regisss in #29499
- v4.39 deprecations 🧼 by @gante in #29492
- Revert "Automatic safetensors conversion when lacking these files by @LysandreJik in #2…
- fix: Avoid error when fsdp_config is missing xla_fsdp_v2 by @ashokponkumar in #29480
- Flava multimodal add attention mask by @zucchini-nlp in #29446
- test_generation_config_is_loaded_with_model - fall back to pytorch model for now by @amyeroberts in #29521
- Set
inputsas kwarg inTextClassificationPipelineby @alvarobartt in #29495 - Fix
VisionEncoderDecoderPositional Arg by @nickthegroot in #29497 - Generate: left-padding test, revisited by @gante in #29515
- [tests] add the missing
require_sacremosesdecorator by @faaany in #29504 - fix image-to-text batch incorrect output issue by @sywangyi in #29342
- Typo fix in error message by @clefourrier in #29535
- [tests] use
torch_deviceinstead ofautofor model testing by @faaany in #29531 - StableLM: Fix dropout argument type error by @liangjs in #29236
- Make sliding window size inclusive in eager attention by @jonatanklosko in #29519
- fix typos in FSDP config parsing logic in
TrainingArgumentsby @yundai424 in #29189 - Fix WhisperNoSpeechDetection when input is full silence by @ylacombe in #29065
- [tests] use the correct
n_gpuinTrainerIntegrationTest::test_train_and_eval_dataloadersfor XPU by @faaany in #29307 - Fix eval thread fork bomb by @muellerzr in #29538
- feat: use
warning_advicefor tensorflow warning by @winstxnhdw in #29540 - [
Mamba doc] Post merge updates by @ArthurZucker in #29472 - [
Docs] fixed minor typo by @j-gc in #29555 - Add Fill-in-the-middle training objective example - PyTorch by @tanaymeh in #27464
- Bark model Flash Attention 2 Enabling to pass on check_device_map parameter to super() by @damithsenanayake in #29357
- Make torch xla available on GPU by @yitongh in #29334
- [Docs] Fix FastSpeech2Conformer model doc links by @khipp in #29574
- Don't use a subset in test fetcher if on
mainbranch by @ydshieh in #28816 - fix error: TypeError: Object of type Tensor is not JSON serializable … by @yuanzhoulvpi2017 in #29568
- Add missing localized READMEs to the copies check by @khipp in #29575
- Fixed broken link by @amritgupta98 in #29558
- Tiny improvement for doc by @fzyzcjy in #29581
- Fix Fuyu doc typos by @zucchini-nlp in #29601
- Fix minor typo: softare => software by @DriesVerachtert in #29602
- Stop passing None to compile() in TF examples by @Rocketknight1 in #29597
- Fix typo (determine) by @koayon in #29606
- Implemented add_pooling_layer arg to TFBertModel by @tomigee in #29603
- Update legacy Repository usage in various example files by @Hvanderwilk in #29085
- Set env var to hold Keras at Keras 2 by @Rocketknight1 in #29598
- Update flava tests by @ydshieh in #29611
- Fix typo ; Update quantization.md by @furkanakkurt1335 in #29615
- Add tests for batching support by @zucchini-nlp in #29297
- Fix: handle logging of scalars in Weights & Biases summary by @parambharat in #29612
- Examples: check
max_position_embeddingsin the translation example by @gante in #29600 - [
Gemma] Supports converting directly in half-precision by @younesbelkada in #29529 - [Flash Attention 2] Add flash attention 2 for GPT-J by @bytebarde in #28295
- Core: Fix copies on main by @younesbelkada in #29624
- [Whisper] Deprecate forced ids for v4.39 by @sanchit-gandhi in #29485
- Warn about tool use by @LysandreJik in #29628
- Adds pretrained IDs directly in the tests by @LysandreJik in #29534
- [generate] deprecate forced ids processor by @sanchit-gandhi in #29487
- Fix minor typo: infenrece => inference by @DriesVerachtert in #29621
- [
MaskFormer,Mask2Former] Use einsum where possible by @amyeroberts in #29544 - Llama: allow custom 4d masks by @gante in #29618
- [PyTorch/XLA] Fix extra TPU compilations introduced by recent changes by @alanwaketan in #29158
- [docs] Spanish translate chat_templating.md & yml addition by @njackman-2344 in #29559
- Add support for FSDP+QLoRA and DeepSpeed ZeRO3+QLoRA by @pacman100 in #29587
- [
Mask2Former] Move normalization for numerical stability by @amyeroberts in #29542 - [tests] make
test_trainer_log_level_replicato run on accelerators with more than 2 devices by @faaany in #29609 - Refactor TFP call to just sigmoid() by @Rocketknight1 in #29641
- Fix batching tests for new models (Mamba and SegGPT) by @zucchini-nlp in #29633
- Fix
multi_gpu_data_parallel_forwardforMusicgenTestby @ydshieh in #29632 - [docs] Remove broken ChatML format link from chat_templating.md by @aaronjimv in #29643
- Add newly added PVTv2 model to all README files. by @robinverduijn in #29647
- [
PEFT] Fixsave_pretrainedto make sure adapters weights are also saved on TPU by @shub-kris in #29388 - Fix TPU checkpointing inside Trainer by @shub-kris in #29657
- Add
dataset_revisionargument toRagConfigby @ydshieh in #29610 - Fix PVT v2 tests by @ydshieh in #29660
- Generate: handle
cache_positionupdate ingenerateby @gante in #29467 - Allow apply_chat_template to pass kwargs to the template and support a dict of templates by @Rocketknight1 in #29658
- Inaccurate code example within inline code-documentation by @MysteryManav in #29661
- Extend import utils to cover "editable" torch versions by @bhack in #29000
- Trainer: fail early in the presence of an unsavable
generation_configby @gante in #29675 - Pipeline: use tokenizer pad token at generation time if the model pad token is unset. by @gante in #29614
- [tests] remove deprecated tests for model loading by @faaany in #29450
- Fix AutoformerForPrediction example code by @m-torhan in #29639
- [tests] ensure device-required software is available in the testing environment before testing by @faaany in #29477
- Fix wrong condition used in
filter_modelsby @ydshieh in #29673 - fix: typos by @testwill in #29653
- Rename
gluetonyu-mll/glueby @lhoestq in #29679 - Generate: replace breaks by a loop condition by @gante in #29662
- [FIX] Fix speech2test modeling tests by @ylacombe in #29672
- Revert "Fix wrong condition used in
filter_models" by @ydshieh in #29682 - [docs] Spanish translation of attention.md by @aaronjimv in #29681
- CI / generate: batch size computation compatible with all models by @gante in #29671
- Fix
filter_modelsby @ydshieh in #29710 - FIX [
bnb] Makeunexpected_keysoptional by @younesbelkada in #29420 - Update the pipeline tutorial to include
gradio.Interface.from_pipelineby @abidlabs in #29684 - Use logging.warning instead of warnings.warn in pipeline.call by @tokestermw in #29717
Significant community contributions
The following contributors have made significant changes to the library over the last release:
- @windsonsea
- @hoangsvit
- [i18n-vi] Translate README.md to Vietnamese (#29229)
- @EduardoPach
- @RaymondLi0
- Starcoder2 model - bis (#29215)
- @njackman-2344
- @tanaymeh
- Add Fill-in-the-middle training objective example - PyTorch (#27464)
- @Hvanderwilk
- Update legacy Repository usage in various example files (#29085)
- @FoamoftheSea
- Add PvT-v2 Model (#26812)
- @saurabhdash2512
- Cohere Model Release (#29622)