-
Notifications
You must be signed in to change notification settings - Fork 71
June 29, 2016
This meeting is a hybrid teleconference and IRC chat. Anyone is welcome to join. Here is the info:
- Time: 1:00pm Eastern Daylight Time US (UTC-4)
- Dial-in Number: (641) 715-3570
- Participant Code: 304589#
- International numbers: Conference Call Information
- Web Access: https://www.freeconferencecallhd.com/wp-content/themes/responsive/flashphone/flash-phone.php
- IRC:
- Join the #islandora chat room via Freenode Web IRC (enter a unique nick)
- Or point your IRC client to #islandora on irc.freenode.net
- Melissa Anez 🌟
- Ben Rosner
- Nick Ruest
- Diego Pino
- Alex Garnett
- Mark Baggett
- Mike Nason
- Luke Bainbridge
- Aaron Coburn
- Ed Fugikawa
- Preservation Planning Ontology (talk about potential first steps in working with Archivematica FPR)
- Drupalize the CLAW team
- Let's talk about Docker
- Let's talk about OSGi services
- ... Feel free to add anything else.
Not discussed.
An anonymous donor is offering up three months of Drupalize.me training to help the CLAW team get comfortable in Drupal 8. Luke has used it and says it's a good resources for moving from Drupal 7 to 8. Nick, Ben, and Bryan signed up to take 3/4 spots. Nick volunteered Jared for the 4th spot. Selected July-August-September for the months of membership. Melissa will follow up with the donor to get it going for July.
Stuff is broken. Nick has been putting a lot of work into getting it back up, but no luck so far. Ongoing Issues, including lots of detail about what is breaking. MariaDB issue is particularly frustrating. Works fine on its own, but run with Docker compose, it fails and cascades, causing Drupal docker container to fail. Nick met with Erin and Francis at OR2016 to talk about shared infrastructure; they may have some ideas. Melissa suggests asking the Dev-Ops IG to weigh in Diego asks if there are other members of the Islandora community with experience in Docker who we could ask to help out. Mike suggests Jacob Stanford might have some insights; will mention it and see if he has time. Nick's primary question is how much we can do with this while our resources are spread thin. Current docker/Ansible stuff is all based on the older version; no new microservices, etc. Ben suggests we leave it be until we are ready for a real release, and we can tackle updating it then. Nick says it is open for anyone who wants to pick it up, but otherwise we will leave it be.
Aaron: At Amherst College they are using a lot of OSGi for a service-oriented architecture that's pretty distributed. They has been writing a bunch of code for their own use that they are happy to share. The idea: you have Fedora resources. All that Fedora does is allow CRUD access. You can't do things like resize and imagine, generate a thumbnail, etc. Can't create a graph of an entire PCDM object. Can't get an application-specific compact JSON LD. Amherst has been writing services tied to endpoints that each expose a REST API that can validate RDF (example: hand in an OWL graph with OWL restrictions, it can tell if it's a valid graph). There's a lot more to be done, but great results so far.
Diego: What they have in terms of extensions is cool. Would love input from Archivematica. Likes the idea of dealing with graphs as a whole. Wonders if there is a splitting service: pass a graph and have it split into individual resources.
Aaron: Interesting but the opposite of what he's doing right now. Most of the current work is on READ services. Those are the easier ones to write, so a good place to start. Having a mechanism for Writing content is important.
Diego: Are you passing a graph and ontology side by side or is the ontology stored somewhere?
Aaron: The services takes 4 or 5 arguments. Any RDF graph and any OWL restriction.
Diego: working on something very similar to this. Takes PCDM ontology as a base, creates a new ontology based on PCDM restrictions to create specific use cases. On ingest, it validates against the local restricted ontology. The RDF graph that results is a plain PCDM. Storing the sub-ontologies directly on Fedora 4. We should have conversation about best practices around this.
Aaron: Not storing OWL graphs on Fedora. Storing them as part of OSGi bundles. Views them as static resources that go along with the code, rather than repository resources. But not wedded to that decision.
Diego: How is Marmota going?
Aaron: Not great in OSGi (I had to wrap the JAR files into special bundles), but otherwise quite nice. If modelling Fedora you might have something like DC terms Subject linked to LOC, which is great for Linked Data, but when it comes time to index that resources in Solr, no one cares about URIs. You need a readable label. What do you do? De-referencing at runtime is not a good solution. Needs to be cached. There's something called Linked Data Fragments. LDP needs period refreshing if you're caching, which means you need to store metadata around access/updates/etc to know when to run those refreshes. Marmota is basically java interfaces; you can use it to write a Linked Data Fragment interface. Map of the RDF resources/Metadata Profile.
Diego: When you serialize to MODS. do you also do caching?
Aaron: Not yet. Is does serialize to DC. If you look at how OAI DC serialization is supposed to work, they will accept URIs as values. Here's the code (a 'big blob of xslt'). The MODS xslt does not work at this point.
Nick: Question about metadata profile. What do you do if the properties that have multiple entries, how do you differentiate?
Aaron: We haven't done it yet, but the idea is that if it has a namespace that starts with one of these 2 or 3 things, it's 'digital origin', etc. Looking at namespaces to make the call. Those should be URIs.
Ben: Looks like they will go down the path of making a bunch of utility class and setting up each PDX endpoints as lightweight things that use those utility classes, because there is a lot of duplication in them.
Bryan: open to feedback on what Collection/Object/File services SHOULD do. More requirements are always helpful.
Nick: Along these lines? Or this?
Bryan: More like functionality.
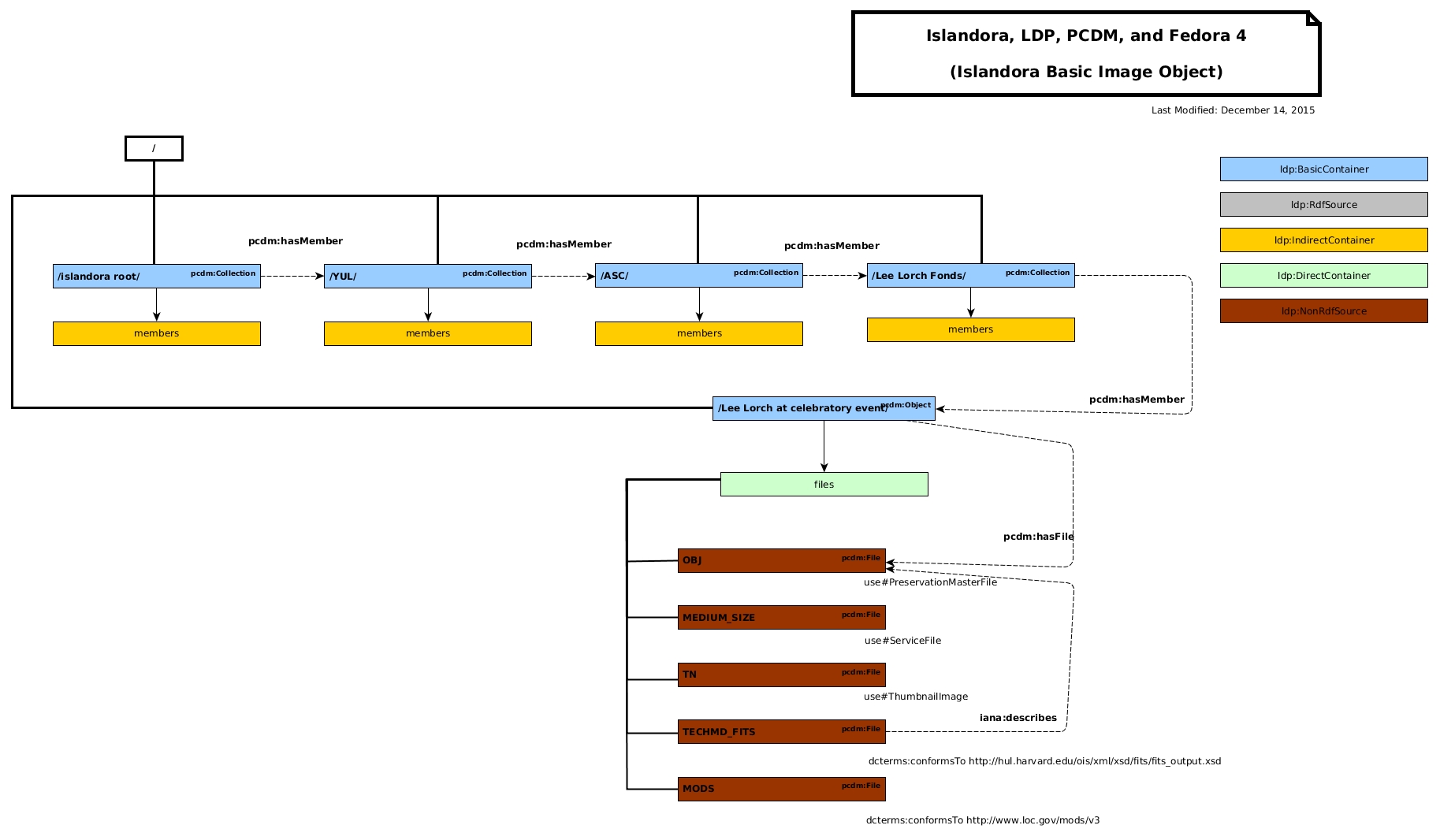
Nick: Let's start with a specific one. Collection services. Next would be need to create a new object. Allow child of an object. For files, we need to decide if we do filesets or not. Looking at PCDM diagram for references. We should avoids "Works" and "Fileset" so as not to confuse Hydra interoperability.
{kind=link}
Ben: So create a direct container called "Files," not "Fileset"
Nick So its just a generic file service that takes in a label and a predicate. Preservation master file, service file, etc.
Bryan: any type of validation or query functionality we need to worry about, or should we just go for the low hanging fruit?
Nick: 🍇
👍 from Ben and Bryan. They feel like 🐥 but must learn by doing, which makes it easier for 🐣 who come along afterwards.
Diego: sharing his Drupal 8 demo
Nick: Has been working on Docker stuff; is back to chipping away at tests. slowly getting test coverage up on chullo. Noticing places in annotations and comments that need to be tweaked.
You may be looking for the islandora-community wiki · new to islandora? · community calendar · interest groups · roadmap