v4.40.0: Llama 3, Idefics 2, Recurrent Gemma, Jamba, DBRX, OLMo, Qwen2MoE, Grounding Dino
New model additions
Llama 3
Llama 3 is supported in this release through the Llama 2 architecture and some fixes in the tokenizers library.
Idefics2

The Idefics2 model was created by the Hugging Face M4 team and authored by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found here.
Idefics2 is an open multimodal model that accepts arbitrary sequences of image and text inputs and produces text outputs. The model can answer questions about images, describe visual content, create stories grounded on multiple images, or simply behave as a pure language model without visual inputs. It improves upon IDEFICS-1, notably on document understanding, OCR, or visual reasoning. Idefics2 is lightweight (8 billion parameters) and treats images in their native aspect ratio and resolution, which allows for varying inference efficiency.
- Add Idefics2 by @amyeroberts in #30253
Recurrent Gemma
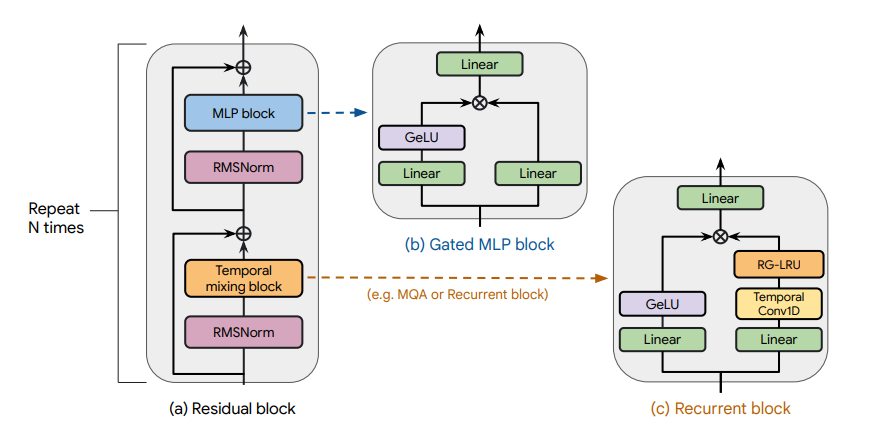
Recurrent Gemma architecture. Taken from the original paper.
The Recurrent Gemma model was proposed in RecurrentGemma: Moving Past Transformers for Efficient Open Language Models by the Griffin, RLHF and Gemma Teams of Google.
The abstract from the paper is the following:
We introduce RecurrentGemma, an open language model which uses Google’s novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
- Add recurrent gemma by @ArthurZucker in #30143
Jamba
Jamba is a pretrained, mixture-of-experts (MoE) generative text model, with 12B active parameters and an overall of 52B parameters across all experts. It supports a 256K context length, and can fit up to 140K tokens on a single 80GB GPU.
As depicted in the diagram below, Jamba’s architecture features a blocks-and-layers approach that allows Jamba to successfully integrate Transformer and Mamba architectures altogether. Each Jamba block contains either an attention or a Mamba layer, followed by a multi-layer perceptron (MLP), producing an overall ratio of one Transformer layer out of every eight total layers.

Jamba introduces the first HybridCache object that allows it to natively support assisted generation, contrastive search, speculative decoding, beam search and all of the awesome features from the generate API!
- Add jamba by @tomeras91 in #29943
DBRX
DBRX is a transformer-based decoder-only large language model (LLM) that was trained using next-token prediction. It uses a fine-grained mixture-of-experts (MoE) architecture with 132B total parameters of which 36B parameters are active on any input.
It was pre-trained on 12T tokens of text and code data. Compared to other open MoE models like Mixtral-8x7B and Grok-1, DBRX is fine-grained, meaning it uses a larger number of smaller experts. DBRX has 16 experts and chooses 4, while Mixtral-8x7B and Grok-1 have 8 experts and choose 2.
This provides 65x more possible combinations of experts and the authors found that this improves model quality. DBRX uses rotary position encodings (RoPE), gated linear units (GLU), and grouped query attention (GQA).
- Add DBRX Model by @abhi-mosaic in #29921
OLMo
The OLMo model was proposed in OLMo: Accelerating the Science of Language Models by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
OLMo is a series of Open Language Models designed to enable the science of language models. The OLMo models are trained on the Dolma dataset. We release all code, checkpoints, logs (coming soon), and details involved in training these models.
- Add OLMo model family by @2015aroras in #29890
Qwen2MoE
Qwen2MoE is the new model series of large language models from the Qwen team. Previously, we released the Qwen series, including Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio, etc.
Model Details
Qwen2MoE is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. Qwen2MoE has the following architectural choices:
Qwen2MoE is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
Qwen2MoE employs Mixture of Experts (MoE) architecture, where the models are upcycled from dense language models. For instance, Qwen1.5-MoE-A2.7B is upcycled from Qwen-1.8B. It has 14.3B parameters in total and 2.7B activated parameters during runtime, while it achieves comparable performance with Qwen1.5-7B, with only 25% of the training resources.
- Add Qwen2MoE by @bozheng-hit in #29377
Grounding Dino
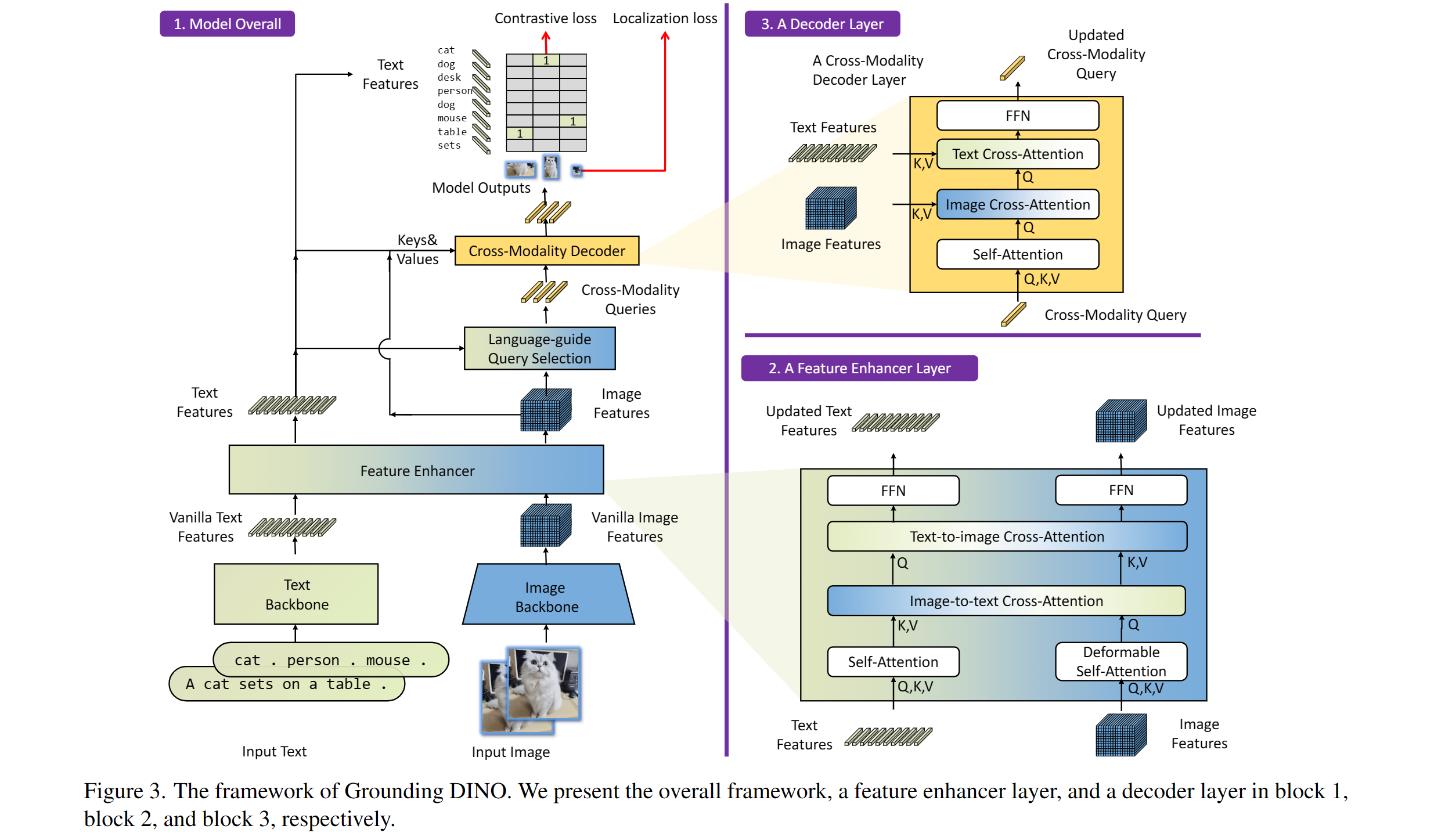
Taken from the original paper.
The Grounding DINO model was proposed in Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
- Adding grounding dino by @EduardoPach in #26087
Static pretrained maps
Static pretrained maps have been removed from the library's internals and are currently deprecated. These used to reflect all the available checkpoints for a given architecture on the Hugging Face Hub, but their presence does not make sense in light of the huge growth of checkpoint shared by the community.
With the objective of lowering the bar of model contributions and reviewing, we first start by removing legacy objects such as this one which do not serve a purpose.
- Remove static pretrained maps from the library's internals by @LysandreJik in #29112
Notable improvements
Processors improvements
Processors are ungoing changes in order to uniformize them and make them clearer to use.
- Separate out kwargs in processor by @amyeroberts in #30193
- [Processor classes] Update docs by @NielsRogge in #29698
SDPA
Push to Hub for pipelines
Pipelines can now be pushed to Hub using a convenient push_to_hub method.
Flash Attention 2 for more models (M2M100, NLLB, GPT2, MusicGen) !
Thanks to the community contribution, Flash Attention 2 has been integrated for more architectures
- Adding Flash Attention 2 Support for GPT2 by @EduardoPach in #29226
- Add Flash Attention 2 support to Musicgen and Musicgen Melody by @ylacombe in #29939
- Add Flash Attention 2 to M2M100 model by @visheratin in #30256
Improvements and bugfixes
- [docs] Remove redundant
-andthefrom custom_tools.md by @windsonsea in #29767 - Fixed typo in quantization_config.py by @kurokiasahi222 in #29766
- OWL-ViT box_predictor inefficiency issue by @RVV-karma in #29712
- Allow
-OOmode fordocstring_decoratorby @matthid in #29689 - fix issue with logit processor during beam search in Flax by @giganttheo in #29636
- Fix docker image build for
Latest PyTorch + TensorFlow [dev]by @ydshieh in #29764 - [
LlavaNext] Fix llava next unsafe imports by @ArthurZucker in #29773 - Cast bfloat16 to float32 for Numpy conversions by @Rocketknight1 in #29755
- Silence deprecations and use the DataLoaderConfig by @muellerzr in #29779
- Add deterministic config to
set_seedby @muellerzr in #29778 - Add support for
torch_dtypein the run_mlm example by @jla524 in #29776 - Generate: remove legacy generation mixin imports by @gante in #29782
- Llama: always convert the causal mask in the SDPA code path by @gante in #29663
- Prepend
bos tokento Blip generations by @zucchini-nlp in #29642 - Change in-place operations to out-of-place in LogitsProcessors by @zucchini-nlp in #29680
- [
quality] update quality check to make sure we check imports 😈 by @ArthurZucker in #29771 - Fix type hint for train_dataset param of Trainer.init() to allow IterableDataset. Issue 29678 by @stevemadere in #29738
- Enable AMD docker build CI by @IlyasMoutawwakil in #29803
- Correct llava mask & fix missing setter for
vocab_sizeby @fxmarty in #29389 - rm input dtype change in CPU by @jiqing-feng in #28631
- Generate: remove unused attributes in
AssistedCandidateGeneratorby @gante in #29787 - replaced concatenation to f-strings to improve readability and unify … by @igeni in #29785
- [
cleanup] vestiges of causal mask by @ArthurZucker in #29806 - Complete security policy with mentions of remote code by @LysandreJik in #29707
- [
SuperPoint] Fix doc example by @amyeroberts in #29816 - [DOCS] Fix typo for llava next docs by @aliencaocao in #29829
- model_summary.md - Restore link to Harvard's Annotated Transformer. by @gamepad-coder in #29702
- Fix the behavior of collecting 'num_input_tokens_seen' by @YouliangHUANG in #29099
- Populate torch_dtype from model to pipeline by @B-Step62 in #28940
- remove quotes in code example by @johko in #29812
- Add warnings if training args differ from checkpoint trainer state by @jonflynng in #29255
- Replace 'decord' with 'av' in VideoClassificationPipeline by @Tyx-main in #29747
- Fix header in IFE task guide by @merveenoyan in #29859
- [docs] Indent ordered list in add_new_model.md by @windsonsea in #29796
- Allow
bos_token_id is Noneduring the generation withinputs_embedsby @LZHgrla in #29772 - Add
cosine_with_min_lrscheduler in Trainer by @liuyanyi in #29341 - Disable AMD memory benchmarks by @IlyasMoutawwakil in #29871
- Set custom_container in build docs workflows by @Wauplin in #29855
- Support
num_attention_heads!=num_key_value_headsin Flax Llama Implementation by @bminixhofer in #29557 - Mamba
slow_forwardgradient fix by @vasqu in #29563 - Fix 29807, sinusoidal positional encodings overwritten by post_init() by @hovnatan in #29813
- Reimplement "Automatic safetensors conversion when lacking these files" by @LysandreJik in #29846
- fix fuyu device_map compatibility by @SunMarc in #29880
- Move
eos_token_idto stopping criteria by @zucchini-nlp in #29459 - add Cambricon MLUs support by @huismiling in #29627
- MixtralSparseMoeBlock: add gate jitter by @lorenzoverardo in #29865
- Fix typo in T5Block error message by @Mingosnake in #29881
- [
make fix-copies] update and help by @ArthurZucker in #29924 - [
GptNeox] don't gather on pkv when using the trainer by @ArthurZucker in #29892 - [
pipeline]. Zero shot add doc warning by @ArthurZucker in #29845 - [doc] fix some typos and add
xputo the testing documentation by @faaany in #29894 - Tests: replace
torch.testing.assert_allclosebytorch.testing.assert_closeby @gante in #29915 - Add beam search visualizer to the doc by @aymeric-roucher in #29876
- Safe import of LRScheduler by @amyeroberts in #29919
- add functions to inspect model and optimizer status to trainer.py by @CKeibel in #29838
- RoPE models: add numerical sanity-check test for RoPE scaling by @gante in #29808
- [
Mamba] from pretrained issue withself.embeddingsby @ArthurZucker in #29851 - [
TokenizationLlama] fix the way we convert tokens to strings to keep leading spaces 🚨 breaking fix by @ArthurZucker in #29453 - Allow GradientAccumulationPlugin to be configured from AcceleratorConfig by @fabianlim in #29589
- [
BC] Fix BC for other libraries by @ArthurZucker in #29934 - Fix doc issue #29758 in DebertaV2Config class by @vinayakkgarg in #29842
- [
LlamaSlowConverter] Slow to Fast better support by @ArthurZucker in #29797 - Update installs in image classification doc by @MariaHei in #29947
- [
StableLm] Add QK normalization and Parallel Residual Support by @jon-tow in #29745 - Mark
test_eager_matches_sdpa_generateflaky for some models by @ydshieh in #29479 - Super tiny fix 12 typos about "with with" by @fzyzcjy in #29926
- Fix rope theta for OpenLlama by @jla524 in #29893
- Add warning message for
run_qa.pyby @jla524 in #29867 - fix: get mlflow version from mlflow-skinny by @clumsy in #29918
- Reset alarm signal when the function is ended by @coldnight in #29706
- Update model card and link of blog post. by @bozheng-hit in #29928
- [
BC] Fix BC for AWQ quant by @TechxGenus in #29965 - Rework tests to compare trainer checkpoint args by @muellerzr in #29883
- Fix FA2 tests by @ylacombe in #29909
- Fix copies main ci by @ArthurZucker in #29979
- [tests] fix the wrong output in
ImageToTextPipelineTests.test_conditional_generation_llavaby @faaany in #29975 - Generate: move misplaced test by @gante in #29902
- [docs] Big model loading by @stevhliu in #29920
- [
generate] fix breaking change for patch by @ArthurZucker in #29976 - Fix 29807 sinusoidal positional encodings in Flaubert, Informer and XLM by @hovnatan in #29904
- [bnb] Fix bug in
_replace_with_bnb_linearby @SunMarc in #29958 - Adding FlaxNoRepeatNGramLogitsProcessor by @giganttheo in #29677
- [Docs] Make an ordered list prettier in add_tensorflow_model.md by @windsonsea in #29949
- Fix
skip_special_tokensforWav2Vec2CTCTokenizer._decodeby @msublee in #29311 - Hard error when ignoring tensors. by @Narsil in #27484)
- Generate: fix logits processors doctests by @gante in #29718
- Fix
remove_columnsintext-classificationexample by @mariosasko in #29351 - Update
tests/utils/tiny_model_summary.jsonby @ydshieh in #29941 - Make EncodecModel.decode ONNX exportable by @fxmarty in #29913
- Fix Swinv2ForImageClassification NaN output by @miguelm-almeida in #29981
- Fix Qwen2Tokenizer by @jklj077 in #29929
- Fix
kwargshandling ingenerate_with_fallbackby @cifkao in #29225 - Fix probability computation in
WhisperNoSpeechDetectionwhen recomputing scores by @cifkao in #29248 - Fix vipllava for generation by @zucchini-nlp in #29874
- [docs] Fix audio file by @stevhliu in #30006
- Superpoint imports fix by @zucchini-nlp in #29898
- [
Main CIs] Fix the red cis by @ArthurZucker in #30022 - Make clearer about zero_init requirements by @muellerzr in #29879
- Enable multi-device for efficientnet by @jla524 in #29989
- Add a converter from mamba_ssm -> huggingface mamba by @byi8220 in #29705
- [
ProcessingIdefics] Attention mask bug with padding by @byi8220 in #29449 - Add
whispertoIMPORTANT_MODELSby @ydshieh in #30046 - skip
test_encode_decode_fast_slow_all_tokensfor now by @ydshieh in #30044 - if output is tuple like facebook/hf-seamless-m4t-medium, waveform is … by @sywangyi in #29722
- Fix mixtral ONNX Exporter Issue. by @AdamLouly in #29858
- [Trainer] Allow passing image processor by @NielsRogge in #29896
- [bnb] Fix offload test by @SunMarc in #30039
- Update quantizer_bnb_4bit.py: In the ValueError string there should be "....you need to set
llm_int8_enable_fp32_cpu_offload=True...." instead of "load_in_8bit_fp32_cpu_offload=True". by @miRx923 in #30013 - [test fetcher] Always include the directly related test files by @ydshieh in #30050
- Fix
torch.fxsymbolic tracing for LLama by @michaelbenayoun in #30047 - Refactor daily CI workflow by @ydshieh in #30012
- Add docstrings and types for MambaCache by @koayon in #30023
- Fix auto tests by @ydshieh in #30067
- Fix whisper kwargs and generation config by @zucchini-nlp in #30018
- doc: Correct spelling mistake by @caiyili in #30107
- [Whisper] Computing features on GPU in batch mode for whisper feature extractor. by @vaibhavagg303 in #29900
- Change log level to warning for num_train_epochs override by @xu-song in #30014
- Make MLFlow version detection more robust and handles mlflow-skinny by @helloworld1 in #29957
- updated examples/pytorch/language-modeling scripts and requirements.txt to require datasets>=2.14.0 by @Patchwork53 in #30120
- [tests] add
require_bitsandbytesmarker by @faaany in #30116 - fixing issue 30034 - adding data format for run_ner.py by @JINO-ROHIT in #30088
- Patch fix - don't use safetensors for TF models by @amyeroberts in #30118
- [#29174] ImportError Fix: Trainer with PyTorch requires accelerate>=0.20.1 Fix by @UtkarshaGupte in #29888
- Accept token in trainer.push_to_hub() by @mapmeld in #30093
- fix learning rate display in trainer when using galore optimizer by @vasqu in #30085
- Fix falcon with SDPA, alibi but no passed mask by @fxmarty in #30123
- Trainer / Core : Do not change init signature order by @younesbelkada in #30126
- Make vitdet jit trace complient by @fxmarty in #30065
- Fix typo at ImportError by @DrAnaximandre in #30090
- Adding
mpsas device forPipelineclass by @fnhirwa in #30080 - Fix failing DeepSpeed model zoo tests by @pacman100 in #30112
- Add datasets.Dataset to Trainer's train_dataset and eval_dataset type hints by @ringohoffman in #30077
- Fix docs Pop2Piano by @zucchini-nlp in #30140
- Revert workaround for TF safetensors loading by @Rocketknight1 in #30128
- [Trainer] Fix default data collator by @NielsRogge in #30142
- [Trainer] Undo #29896 by @NielsRogge in #30129
- Fix slow tests for important models to be compatible with A10 runners by @ydshieh in #29905
- Send headers when converting safetensors by @ydshieh in #30144
- Fix quantization tests by @SunMarc in #29914
- [docs] Fix image segmentation guide by @stevhliu in #30132
- [CI] Fix setup by @SunMarc in #30147
- Fix length related warnings in speculative decoding by @zucchini-nlp in #29585
- Fix and simplify semantic-segmentation example by @qubvel in #30145
- [CI] Quantization workflow fix by @SunMarc in #30158
- [tests] make 2 tests device-agnostic by @faaany in #30008
- Add str to TrainingArguments report_to type hint by @ringohoffman in #30078
- [UDOP] Fix tests by @NielsRogge in #29573
- [UDOP] Improve docs, add resources by @NielsRogge in #29571
- Fix accelerate kwargs for versions <0.28.0 by @vasqu in #30086
- Fix typing annotation in hf_argparser by @xu-song in #30156
- Fixing a bug when MlFlow try to log a torch.tensor by @etiennebonnafoux in #29932
- Fix natten install in docker by @ydshieh in #30161
- FIX / bnb: fix torch compatiblity issue with
itemizeby @younesbelkada in #30162 - Update config class check in auto factory by @Rocketknight1 in #29854
- Fixed typo in comments/documentation for Pipelines documentation by @DamonGuzman in #30170
- Fix Llava chat template examples by @lewtun in #30130
- Guard XLA version imports by @muellerzr in #30167
- chore: remove repetitive words by @hugehope in #30174
- fix: Fixed
ruffconfiguration to avoid deprecated configuration warning by @Sai-Suraj-27 in #30179 - Refactor Cohere Model by @saurabhdash2512 in #30027
- Update output of SuperPointForKeypointDetection by @NielsRogge in #29809
- Falcon: make activation, ffn_hidden_size configurable by @sshleifer in #30134
- Docs PR template by @stevhliu in #30171
- ENH: [
CI] Add new workflow to run slow tests of important models on push main if they are modified by @younesbelkada in #29235 - Fix pipeline logger.warning_once bug by @amyeroberts in #30195
- fix: Replaced deprecated
logger.warnwithlogger.warningby @Sai-Suraj-27 in #30197 - fix typo by @mdeff in #30220
- fix fuyu doctest by @molbap in #30215
- Fix
RecurrentGemmaIntegrationTest.test_2b_sampleby @ydshieh in #30222 - Update modeling_bark.py by @bes-dev in #30221
- Fix/Update for doctest by @ydshieh in #30216
- Fixed config.json download to go to user-supplied cache directory by @ulatekh in #30189
- Add test for parse_json_file and change typing to os.PathLike by @xu-song in #30183
- fix: Replace deprecated
assertEqualswithassertEqualby @Sai-Suraj-27 in #30241 - Set pad_token in run_glue_no_trainer.py #28534 by @JINO-ROHIT in #30234
- fix: Replaced deprecated
typing.Textwithstrby @Sai-Suraj-27 in #30230 - Refactor doctest by @ydshieh in #30210
- fix: Fixed
type annotationfor compatability with python 3.8 by @Sai-Suraj-27 in #30243 - Fix doctest more (for
docs/source/en) by @ydshieh in #30247 - round epoch only in console by @xdedss in #30237
- update github actions packages' version to suppress warnings by @ydshieh in #30249
- [tests] add the missing
require_torch_multi_gpuflag by @faaany in #30250 - [Docs] Update recurrent_gemma.md for some minor nits by @sayakpaul in #30238
- Remove incorrect arg in codellama doctest by @Rocketknight1 in #30257
- Update
ko/_toctree.ymlby @jungnerd in #30062 - More fixes for doctest by @ydshieh in #30265
- FIX: Fix corner-case issue with the important models workflow by @younesbelkada in #30212
- FIX: Fix 8-bit serialization tests by @younesbelkada in #30051
- Allow for str versions of dicts based on typing by @muellerzr in #30227
- Workflow: Update tailscale to release version by @younesbelkada in #30268
- Raise relevent err when wrong type is passed in as the accelerator_config by @muellerzr in #29997
- BLIP - fix pt-tf equivalence test by @amyeroberts in #30258
- fix: Fixed a
raisestatement by @Sai-Suraj-27 in #30275 - Fix test fetcher (doctest) +
Idefics2's doc example by @ydshieh in #30274 - Fix SDPA sliding window compatibility by @fxmarty in #30127
- Fix SpeechT5 forward docstrings by @ylacombe in #30287
- FIX / AWQ: Fix failing exllama test by @younesbelkada in #30288
- Configuring Translation Pipelines documents update #27753 by @UtkarshaGupte in #29986
- Enable fx tracing for Mistral by @zucchini-nlp in #30209
- Fix test
ExamplesTests::test_run_translationby @ydshieh in #30281 - Fix
Fatal Python error: Bus errorinZeroShotAudioClassificationPipelineTestsby @ydshieh in #30283 - FIX: Fix push important models CI by @younesbelkada in #30291
- Add token type ids to CodeGenTokenizer by @st81 in #29265
- Add strategy to store results in evaluation loop by @qubvel in #30267
- Upgrading to tokenizers 0.19.0 by @Narsil in #30289
- Re-enable SDPA's FA2 path by @fxmarty in #30070
- Fix quality Olmo + SDPA by @fxmarty in #30302
- Fix donut token2json multiline by @qubvel in #30300
- Fix all torch pipeline failures except one by @ydshieh in #30290
- Add atol for sliding window test by @fxmarty in #30303
- Fix RecurrentGemma device_map by @SunMarc in #30273
- Revert "Re-enable SDPA's FA2 path by @ArthurZucker in #30070)"
- Do not drop mask with SDPA for more cases by @fxmarty in #30311
- FIX: Fixes unexpected behaviour for Llava / LLama & AWQ Fused modules + revert #30070 at the same time by @younesbelkada in #30317
Significant community contributions
The following contributors have made significant changes to the library over the last release:
- @bozheng-hit
- @EduardoPach
- @2015aroras
- Add OLMo model family (#29890)
- @tomeras91
- Add jamba (#29943)
- @abhi-mosaic
- Add DBRX Model (#29921)